[NLP] TextRank 算法
1 概述:TextRank算法
1.1 TextRank 算法 : 源于 PageRank 算法
感兴趣 PageRank 的朋友,请转阅: [机器学习/Python] PageRank原理与实现 - 博客园/千千寰宇
TextRank算法基于PageRank,用于为文本生成关键字、摘要、计算语句(短语或者词汇)的重要性排名,而PageRank最初是因Google搜索引擎需要对网站网页节点的重要性排序计算而诞生。- 从模型本质上讲,
TextRank与PageRank并无二致,只是应用领域和图模型节点的选择有所不同。
1.2 经典的TextRank 算法
- 基于词图模型的关键词抽取是将对文本的处理转化成网络图的连接分析。
- Text Rank算法是词图模型中应用最为广泛的一种方法,。
- 该算法不同于基于
TF-IDF模型和LDA主题模型的关键词抽取方法- 原始算法无需批量地训练语料, 其核心方法是对文本内的词语关系、句子关系、短语关系进行分析, 擅长独立的单文本的关键词抽取, 实现简单且效果较好。
- Text Rank算法是基于Google公司网页排序Page Rank算法, 将对文本的分析转化到网络图中, 通过分析网络图中各个节点的权重,确定节点的重要性。
其中,节点可以是词汇、短语或者句子。
- 在
Text Rank算法中, 依照网络图的定义构建词图G(V, E), 词语的集合(即 词汇表)为V, 词语和词语之间连接的集合为E, 其计算公式如下:
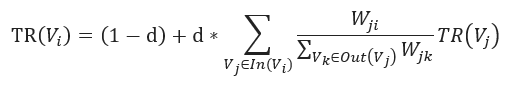
- 阻尼系数
d取值0.85W_ji表示词语V_j到词语V_i的连接权重W_jk: 表示词语V_j到词语V_k的连接权重- 从词语V_j出发指向的所有词语的集合为
Out (V_j)- 所有指向词语V_i的词语集合为
In (V_i)TR(V_i)代表词语i的Text Rank值。
句间连接权重的计算
- 经典的TextRank算法,是基于句子间词汇的共现词频计算当前句子Si与文本内其它句子间的句子相似度,并将句子相似度作为连接权重,计算公式如下。
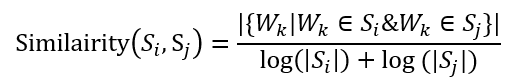
-
分母对数化一定程度上可以避免长句子对摘要生成的影响。
-
Text Rank算法是先将对象文本分词成词语集合V, 然后采用滑动窗口的方式在每个句子内形成词语和词语之间的连接集合E, 再利用公式 (1) 迭代计算每个词语的Text Rank值;
-
当相邻2次运算结果之差小于1个阈值, 或迭代计算次数大于指定次数, 则结束迭代运算;
-
最后, 依据Text Rank值将词语按降序排列, 取top N作为最终的关键词集合。
研究表明, 当阈值设为0.0001情况下, 一般经过20~30次迭代计算即可以收敛。此算法简单且效率较高, 得到了广泛应用。
1.3 局限性
- 由于Text Rank算法完全是基于图关系的一种分析法, 存在以下缺点:
- (1) 每个词语的初始权重取值相同, 这个权重并不能代表词语在该文本中的特殊含义。
- (2) 词语和词语之间的连接仅仅以单个独立的句子内使用滑动窗口来确定, 缺少对上下文的整体考虑。
- (3) 词语和词语之间连接的权重都赋予相同的默认值, 不能区分连接关系的强弱。

本文作者:
千千寰宇
本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!
本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号