[NLP] One-Hot编码
1 One Hot 编码
1.1 定义
One-Hot编码,又称独热编码。从方法性质上讲,它是一种向量表示方法,属于自然语言处理领域中的词袋模型。
独热编码方法使用
N位状态寄存器对N个状态进行编码,每个状态都有独立的寄存位;并且在任意时候,N为状态寄存器中都仅有一位有效状态,该位的状态值则表征了一枚特征数据。
- 由于一条1xN维的特征向量中的仅一位是有效位1,其它为无效位0的这种特质,决定了通过
One-Hot编码得到的特征向量一定是离散、稀疏的一维向量。

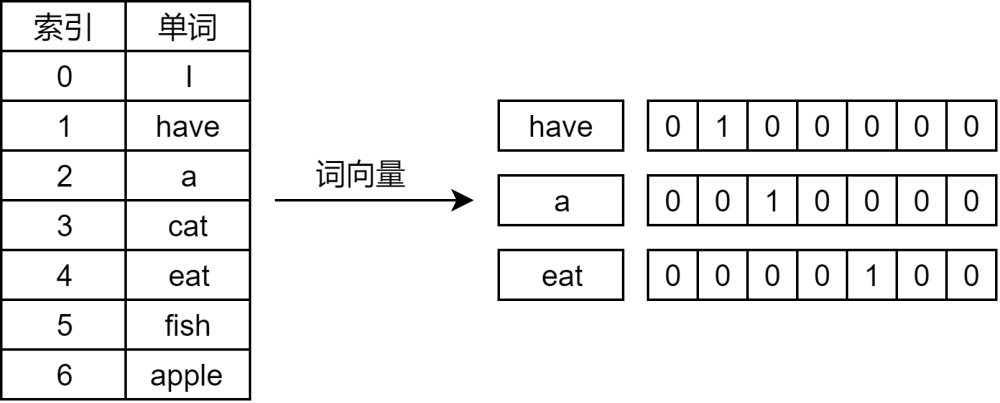
1.2 案例
举例阐述
- 以2019年5月31日的一则报道的新闻内容中的两条句子 “方大特钢公司二号高炉煤气管道发生燃爆事故”,“事故中,一名员工死亡,九名员工受伤”作为一份语料库,经过分词后,得到词汇表
vocabulary:
vocabulary=[ “方大特钢”,”公司”,”二号”,”高炉”,”煤气”,”管道”,”发生”,”燃爆”,”事故”, ”中”,”一”,”名”,”员工”,”死亡”,”九”,”受伤” ]
可见词汇表表长为16。
- 在词汇表基础上进行
one-hot编码,得到如下结果:
| 词汇及对应的One-Hot编码 | 词汇及对应的One-Hot编码 |
|---|---|
| “方大特钢” = [1,0,0,0,0,0,0,0,0,0,0,0,0,0,0] | “公司”=[0,1,0,0,0,0,0,0,0,0,0,0,0,0,0] |
| “二号”= [0,0,1,0,0,0,0,0,0,0,0,0,0,0,0] | “高炉”= [0,0,0,1,0,0,0,0,0,0,0,0,0,0,0] |
| “煤气”= [0,0,0,0,1,0,0,0,0,0,0,0,0,0,0] | “管道”=[0,0,0,0,0,1,0,0,0,0,0,0,0,0,0] |
| “发生”= [0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0] | “燃爆”= [0,0,0,0,0,0,0,1,0,0,0,0,0,0,0] |
| “事故”= [0,0,0,0,0,0,0,0,1,0,0,0,0,0] | “中”= [0,0,0,0,0,0,0,0,0,1,0,0,0,0,0] |
| “一”=[0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0] | “名”=[0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0] |
| “员工”=[0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0] | “死亡”=[0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0] |
| “九”=[0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1] | “受伤”=[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1] |
那么,原新闻的两段文本可以分别向量表示为:
- [1,1,1,1,1,1,1,1,1,0,0,0,0,0,0]
- [0,0,0,0,0,0,0,0,1,1,1,1,1]
- 若词汇表足够大,则: 每句话、每段文本内容都可以用one-hot的词汇编码进行句子向量表示。
1.2 优缺点
优点
- 其一,解决了文本分类等领域中不好直接处理文本数据、离散数据的问题;
- 其二,在一定程度上,起到了扩充特征的作用。
缺点
然而,独热编码方法可不忽视的缺点也赫然存在:
- 其一,“词汇鸿沟”现象。
独热编码假设了词汇与词汇之间相互独立,却忽略了大多数情况下,词汇与词汇之间是相互联系、相互影响的,这种脱离了上下文语义的数学表示必然存在着“词汇鸿沟”这一问题,必然为后续的数据挖掘应用埋下隐患。
- 其二,维数灾难。
随着语料集的扩张,词汇表必然跟着扩张,而跟着随词汇表扩张同样的独热编码的维数大小过长,一定会在进行后续的运算上带来巨大的计算压力,尤其是在基于神经网络的需要海量训练与运算的深度学习领域。

本文作者:
千千寰宇
本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!
本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号