[数据压缩] LZ4压缩算法
0 序
- 续接: [数据压缩/数据归档] 压缩算法综述 - 博客园/千千寰宇,展开研究 LZ4 压缩算法与压缩格式。
- 在不同业务的压缩场景中,选择合适的压缩算法、压缩工具。各种压缩算法及其工具均有其利弊。扬其长、避其短,才能使得我们的选型更有效。
1 概述: LZ4压缩算法
LZ4 压缩算法
LZ4是一种无损数据压缩算法,专注于极致的压缩和解压速度,同时保持合理的压缩比。
LZ4由Yann Collet于 2011 年开发,现在是开源社区广泛使用的压缩技术,尤其在大数据、实时计算和高性能存储场景中备受青睐。
lz4属于lz77系列的压缩算法。
lz77严格意义上来说不是一种算法,而是一种编码理论,它只定义了原理,并没有定义如何实现。
基于lz77编码理论衍生的算法除lz4以外,还有lzss、lzb、lzh等。
- lz4是目前基于综合来看效率最高的压缩算法,更加侧重于压缩解压缩速度;但压缩比并不突出,本质上就是时间换空间。
- 对于 github上给出的lz4性能介绍:
- 每核【压缩速度】大于500MB/s,多核CPU可叠加;
- 它所提供的【解码器】也是极其快速的,每核可达GB/s量级。
- LZ4 的核心优势是“速度优先”,在需要平衡压缩效率和处理延迟的场景中表现突出,尤其适合大数据、实时计算等对吞吐和响应时间要求极高的领域。
LZ4是一种快速的压缩算法,具有高压缩比、高解压缩速度。特别适用于对大量数据进行高效压缩和解压缩的场景。
算法思想
lz77编码思想:它是一种基于字典的算法,它将长字符串(也可以称为匹配项或者短语)编码成短小的标记,用小标记代替字典中的短语。- 也就是说,它通过用小的标记来代替数据中多次重复出现的长字符串来达到数据压缩的目的。
- 其处理的符号不一定是文本字符,也可以是其他任意大小的符号。
- 短语字典维护:lz77使用的是一个前向缓冲区和一个滑动窗口。它首先将数据载入到前向缓冲区,形成一批短语,再由滑动窗口滑动时,变成字典的一部分。
核心特点
-
超高速处理:
- 压缩速度可达 500 MB/s ~ 1 GB/s(单线程),解压速度更是高达 1 GB/s ~ 4 GB/s(取决于数据类型和硬件),是目前速度最快的压缩算法之一。
- 设计上优化了 CPU 缓存利用,减少内存访问开销,适合对延迟敏感的场景。
-
合理的压缩比:
- 压缩比通常在 2:1 ~ 4:1(例如文本、日志数据),虽然不如 ZSTD 或 LZMA 等算法的压缩比高,但在速度上有绝对优势。
- 支持不同压缩级别(1~12 级),级别越高压缩比略高,但速度会下降(默认级别 1 为速度优先)。
-
低内存占用:
- 压缩时内存占用极小(通常仅需几十 MB),适合嵌入式设备、分布式系统等资源受限场景。
算法实现
lz4数据格式
-
lz4实现了2种格式:
lz4_block_format和lz4_frame_formatlz4_frame_format用于特殊场景,如file压缩、pipe压缩和流式压缩;lz4_block_format这里主要介绍 lz4_block_format(一般场景使用格式)
-
压缩块有多个序列组成,一个序列是由一组字面量(非压缩字节),后跟一个匹配副本。每个序列以token开始,字面量和匹配副本的长度是有token以及offset决定的。
literals指没有重复、首次出现的字节流,即不可压缩的部分literals length指不可压缩部分的长度match length指重复项(可以压缩的部分)长度
下图为单个序列的数据格式,一个完整的lz4压缩块是由多个序列组成的。
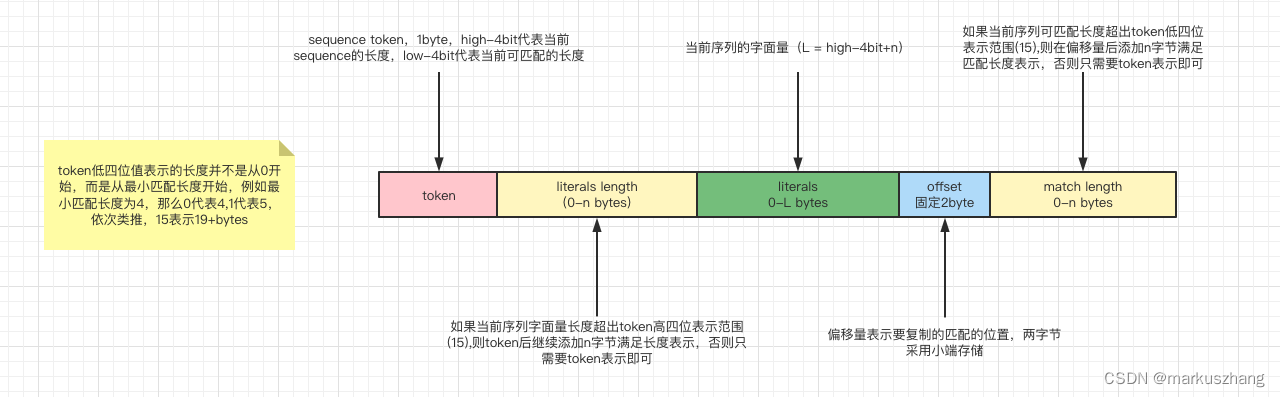
LZ4压缩过程
lz4遵循上面说到的lz77思想理论,通过滑动窗口、hash表、数据编码等操作实现数据压缩。- 压缩过程以至少
4字节为扫描窗口查找匹配,每次移动1字节进行扫描,遇到重复的就进行压缩。
举个例子:给出一个字符串:
abcde_fghabcde_ghxxahcde,描述出此字符串的压缩过程
ps:我们按照6字节扫描窗口,每次1字节来进行扫描
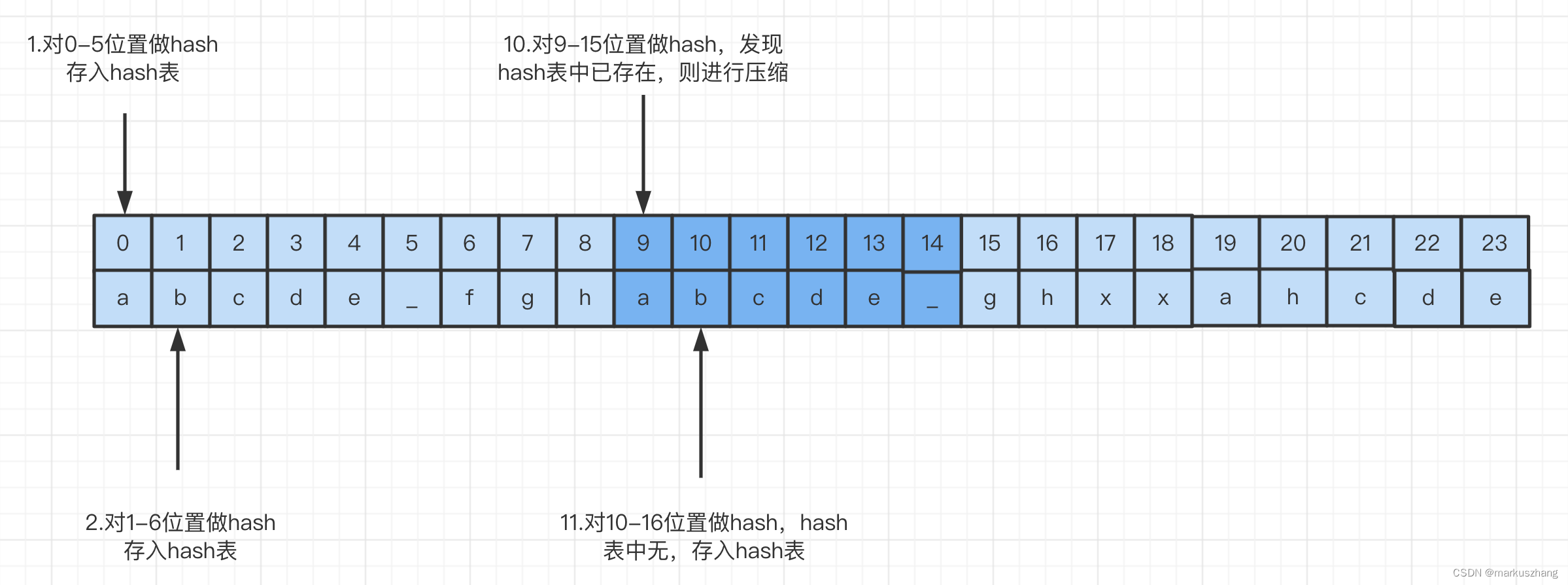
- 假设lz4的滑动窗口大小为6字节,扫描窗口为1字节;
- lz4开始扫描,首先对0-5位置做hash运算,hash表中无该值,所以存入hash表;
- 向后扫描,开始计算1-6位置hash值,hash表中依然无此值,所以继续将hash值存入hash表;
- 扫描过程依次类推,直到图中例子,在计算9-15位置的hash值时,发现hash表中已经存在,则进行压缩,偏移量offset值置为9,重复长度为6,该值存入token值的低4位中;
- 匹配压缩项后开始尝试扩大匹配,当窗口扫描到10-16时,发现并没有匹配到,则将此值存入hash表;如果发现hash表中有值,如果符合匹配条件(例如10-15符合1-6)则扩大匹配项,重复长度设为7,调整相应的token值
- 这样滑动窗口扫描完所有的字符串之后,结束操作
最终,这样压缩过程就结束了,得到这样一个字节串[-110, 97, 98, 99, 100, 101, 95, 102, 103, 104, 9, 0, -112, 103, 104, 120, 120, 97, 104, 99, 100, 101]。大家可能在看到这段内容可能有些懵逼,我在解压过程解释一下。
LZ4 解压过程
lz4压缩串:[-110, 97, 98, 99, 100, 101, 95, 102, 103, 104, 9, 0, -112, 103, 104, 120, 120, 97, 104, 99, 100, 101]
二进制是字符串经过utf-8编码后的值
下图是对上面压缩串的解释:
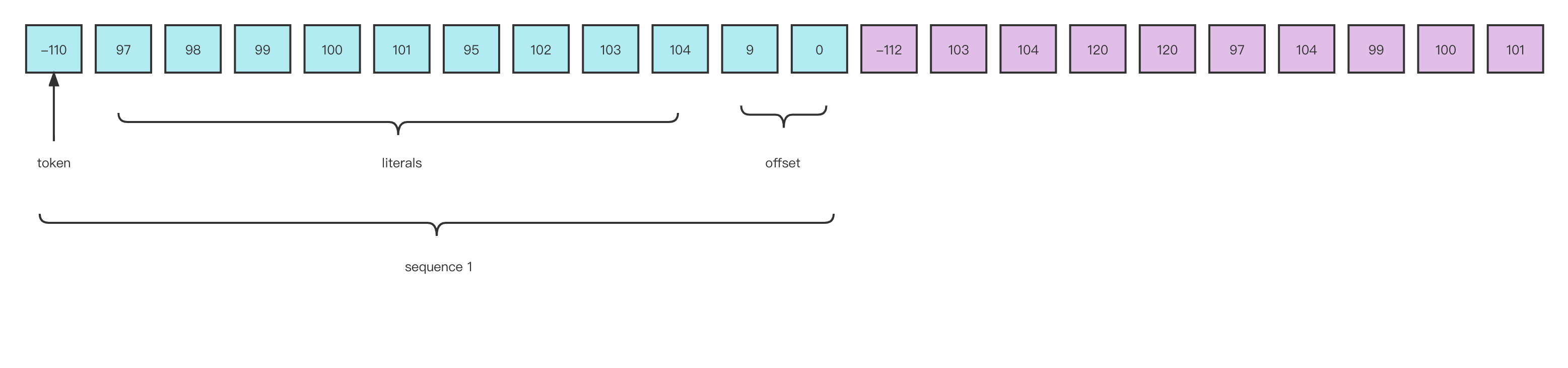
这里简单记录下解压的过程:
- 当lz4解压从0开始遍历时,先判断token值(-110),-110转换为计算机二进制为10010010,高四位1001代表字面量长度为9,低四位0010代表重复项匹配的长度2+4(minimum repeated bytes)
- 向后遍历9位,得到长度为9的字符串(abcde_fgh),偏移量为9,从当前位置向前移动9位则是重复位起始位置,低四位说明重复项长度为6字节,则继续生成长度为6的字符串(abcde_)
- 此时生成(abcde_fghabcde_),接着开始判断下一sequence token起始位,最终生成abcde_fghabcde_ghxxahcde(压缩前的字符串)
典型用法
-
命令行压缩:
lz4 -z 源文件 压缩文件.lz4 # 压缩 lz4 -d 压缩文件.lz4 解压文件 # 解压 -
编程集成:
支持 C、C++、Java、Python、Go 等多种语言,例如 Java 中使用lz4-java库:byte[] input = "test data".getBytes(); byte[] compressed = LZ4Factory.fastestInstance().compress(input); // 快速压缩 byte[] decompressed = LZ4Factory.fastestInstance().decompress(compressed); // 解压
适用场景
- 实时计算:Flink、Spark 等流处理框架的状态存储(RocksDB 状态后端默认使用 LZ4)、Checkpoint 压缩。
- 消息队列:Kafka 消息压缩(生产者压缩消息以减少网络传输,消费者快速解压)。
- 分布式存储:HDFS、对象存储(如 S3)中的大文件压缩(配合 TAR 打包为
.tar.lz4)。 - 日志/数据备份:实时日志压缩(如 ELK 生态中 Logstash 对日志的压缩传输)。
- 缓存系统:Redis 等缓存中对大Value的压缩存储。
2 LZ4压缩算法的命令行工具
- LZ4C是
LZ4【压缩算法】对应的命令行工具(或旧版工具名称)**。
主要用于在终端中执行
LZ4格式的压缩/解压操作**,具体说明如下:
- LZ4C 的核心定位
LZ4C本质是LZ4算法的命令行实现工具。
功能是将【文件/数据流】通过
LZ4压缩算法压缩为.lz4格式,或解压.lz4文件。
以下是 LZ4(含LZ4C)常用命令清单,覆盖文件压缩、解压、数据流处理、性能优化等核心场景,适配 Linux/macOS 环境(Windows 可通过
WSL或LZ4官方二进制包使用):
基础命令(LZ4 与 LZ4C 通用)
| 功能 | LZ4 命令(推荐) | LZ4C 命令(旧版兼容) | 说明 |
|---|---|---|---|
| 压缩文件 | lz4 -z 源文件 目标文件.lz4 |
lz4c compress 源文件 目标文件.lz4 |
如 lz4 -z data.txt data.txt.lz4 |
| 解压文件 | lz4 -d 源文件.lz4 目标文件 |
lz4c decompress 源文件.lz4 目标文件 |
如 lz4 -d data.txt.lz4 data.txt |
| 压缩并覆盖目标文件 | lz4 -zf 源文件 目标文件.lz4 |
lz4c compress -f 源文件 目标文件.lz4 |
若目标文件已存在,强制覆盖 |
| 解压并覆盖目标文件 | lz4 -df 源文件.lz4 目标文件 |
lz4c decompress -f 源文件.lz4 目标文件 |
若目标文件已存在,强制覆盖 |
| 压缩目录(递归) | lz4 -zr 源目录 目标目录.lz4 |
lz4c compress -r 源目录 目标目录.lz4 |
递归压缩目录内所有文件,生成单个压缩包 |
| 查看压缩包信息 | lz4 -l 源文件.lz4 |
lz4c list 源文件.lz4 |
显示压缩比、原始大小、压缩后大小等 |
| 校验压缩包完整性 | lz4 -t 源文件.lz4 |
lz4c test 源文件.lz4 |
检查压缩包是否损坏,无输出则为正常 |
高级用法(性能优化/大数据场景)
| 功能 | 命令示例 | 说明 |
|---|---|---|
| 调整压缩级别(速度/压缩比) | lz4 -z -9 源文件 目标文件.lz4 |
-1(默认,最快)~-12(最慢,压缩比最高),大数据场景推荐 -3~-6(平衡速度) |
| 快速压缩(极致速度) | lz4 -z -1 源文件 目标文件.lz4 |
优先保证压缩速度,适合实时流数据(如 Kafka/Flink 中间数据) |
| 管道压缩(大文件流式处理) | `cat 大文件.bin | lz4 -z > 大文件.bin.lz4` |
| 管道解压(流式输出) | `lz4 -d 大文件.bin.lz4 | 处理命令` |
| 多线程压缩(LZ4 1.9.0+) | lz4 -z -T4 源文件 目标文件.lz4 |
-T 指定线程数(如 -T4 用 4 线程),提升大文件压缩速度 |
| 分块压缩(适合 HDFS/分布式存储) | lz4 -z -B64 源文件 目标文件.lz4 |
-B 指定分块大小(单位 KB,如 -B64=64KB),支持后续并行解压 |
| 保留原始文件权限 | lz4 -z -p 源文件 目标文件.lz4 |
压缩后保留文件的读写权限、所有者信息 |
常用组合场景(大数据/日常办公)
1. 大数据场景:压缩 HDFS 上传文件
# 快速压缩日志文件(适合 Flume 采集后上传 HDFS)
lz4 -z -1 /data/logs/app.log /data/logs/app.log.lz4
# 多线程压缩大文件(4 线程,分块 128KB,适合 Spark/Flink 输入文件)
lz4 -z -T4 -B128 /data/dataset.csv /data/dataset.csv.lz4
2. 日常场景:压缩/解压文件夹
# 递归压缩文件夹(生成 archive.lz4)
lz4 -zr /home/user/docs /backup/archive.lz4
# 解压文件夹到指定目录
lz4 -dr /backup/archive.lz4 /home/user/restored_docs
3. 流式处理:实时压缩日志输出
# 实时压缩应用日志并写入文件(适合高吞吐日志场景)
tail -f /var/log/app.log | lz4 -z > /var/log/app.log.lz4
关键参数说明
| 参数 | 作用 | 适用场景 |
|---|---|---|
-z |
压缩模式(默认,可省略) | 所有压缩操作 |
-d |
解压模式 | 所有解压操作 |
-f |
强制覆盖目标文件 | 避免重复确认 |
-r |
递归处理目录 | 文件夹压缩/解压 |
-l |
显示压缩包详情 | 校验压缩效果 |
-t |
校验压缩包完整性 | 传输后检查文件是否损坏 |
-1~-12 |
压缩级别(1=最快,12=最高压缩比) | 实时场景用 -1,存储优化用 -6+ |
-T<num> |
多线程数(如 -T8=8 线程) |
大文件压缩(LZ4 1.9.0+ 支持) |
-B<size> |
分块大小(如 -B64=64KB) |
分布式存储/并行解压 |
-p |
保留文件权限 | 系统文件、配置文件压缩 |
注意事项
-
LZ4C 兼容性:部分旧系统中
lz4c是lz4的别名,功能完全一致;若提示lz4c: command not found,直接替换为lz4即可。 -
压缩级别选择:大数据实时场景(如 Kafka 消息压缩、Flink 状态后端)优先用
-1(最快),离线存储场景(如 HDFS 冷数据)可用-6~-9(平衡压缩比与速度)。 -
分块大小建议:分布式存储(HDFS/OSS)推荐分块大小
64KB~256KB,与大数据框架的块大小(如 HDFS 默认 128MB)匹配,提升并行处理效率。
3 LZ4-Java 库
3.0 2 LZ4-Java 库
3.0.1 LZ4-Java 库
lz4/lz4-java是由Rei Odaira等人写的一套使用lz4压缩的Java类库。
该类库提供了对两种压缩方法的访问,他们都能生成有效的lz4流:
-
快速扫描(lz4)
- 内存占用少(16KB)
- 非常快
- 合理的压缩比(取决于输入的冗余度)
-
高压缩(lz4hc)
- 内存占用中等(256KB)
- 相当慢(比lz4慢10倍)
- 良好的压缩比(取决于输入的大小和冗余度)
-
这两种压缩算法产生的流使用相同的压缩格式,解压缩速度非常快,可以由相同的解压缩实例解、压缩
3.0.2 核心类
LZ4Factory
- Lz4 API的入口点,该类有3个实例:
- 一个
native实例,它是与原始LZ4 C实现的JNI绑定- 一个
safe Java实例,它是原始C库的纯Java端口(Java 官方编写的API)- 一个
unsafe Java实例,它是使用非官方sun.misc.Unsafe API的Java端口(Unsafe类可用来直接访问系统内存资源并进行自主管理,其在提升Java运行效率,增强Java语言底层操作能力方面起到很大的作用,Unsafe可认为是Java中留下的后门,提供了一些低层次操作,如直接内存访问、线程调度等)
只有safe Java实例才能保证在JVM上工作,因此建议使用
fastestInstance()或fastestJavaInstance()来拉取LZ4Factory实例。
LZ4Compressor
- 压缩器有两种:
fastCompressor,也就是lz4简介中说的快速扫描压缩器;highCompressor,是实现高压缩率压缩器(lz4hc)。
LZ4Decompressor
-
lz4-java提供了两个解压器:LZ4FastDecompressor;LZ4SafeDecompressor -
两者不同点在于:
LZ4FastDecompressor在解压缩时是已知源字符串长度,而LZ4SafeDecompressor在解压缩时是已知压缩字段的长度
补充说明
- 上面说到的两个压缩器和两个解压缩器,在压缩和解压缩的时候,是可以互换的.
比如说
FastCompressor可以和LZ4SafeDecompressor搭配使用这样,因为两种压缩算法生成的流格式是一样的,无论用哪个解压缩器都能解压。
3.0.3 总体流程
| 步骤 | 描述 |
|---|---|
| step1 引入依赖 | 引入 LZ4的Java依赖库 |
| step2 创建压缩器 | 创建 LZ4压缩器实例 |
| step3 压缩数据 | 使用压缩器将数据压缩 |
| step4 创建解缩器 | 创建LZ4解压器实例 |
| step5 解压数据 | 使用解压器实例将压缩的数据解压 |
3.1 引入依赖
<lz4-java.version>1.8.0</lz4-java.version>
<dependency>
<groupId>org.lz4</groupId>
<artifactId>lz4-java</artifactId>
<version>${lz4-java.version}</version>
</dependency>
3.2 示例(压缩/解压)
import com.jack.utils.bytes.BytesUtils;
import lombok.extern.slf4j.Slf4j;
import net.jpountz.lz4.*;
import org.junit.Test;
@Slf4j
public class Lz4cFileDemo {
protected static LZ4Factory factory = LZ4Factory.fastestInstance();
protected static LZ4Compressor compressor = factory.fastCompressor();
//protected static LZ4Decompressor decompressor = factory.fastDecompressor();
//protected static LZ4FastDecompressor decompressor = factory.fastDecompressor(); protected LZ4SafeDecompressor decompressor = factory.safeDecompressor();
//待压缩的数据
protected static byte[] rawData = "Hello World Hello World Hello World Hello World".getBytes();
protected static int rawDataLength = rawData.length;
@Test
public void compressTest( ){
//创建一个缓冲区保存压缩后的数据
byte [] compressedData = new byte[compressor.maxCompressedLength(rawData.length)];
//进行压缩
int compressedLength = compressor.compress(rawData, 0, rawData.length, compressedData, 0);
log.info("rawData(hex):{}", BytesUtils.bytesToHexString(rawData) );
//rawData(hex):48656c6c6f20576f726c642048656c6c6f20576f726c642048656c6c6f20576f726c642048656c6c6f20576f726c64
log.info("compressedData(hex): {}", BytesUtils.bytesToHexString(compressedData) );
//compressedData(hex): cf48656c6c6f20576f726c64200c000b50576f726c640000000000000000000000000000000000000000000000000000000000000000000000000000000000
log.info("rawData.length : {} , compressedData.length : {}, compressedLength : {}", rawData.length, compressedData.length, compressedLength);
//rawData.length : 47 , compressedData.length : 63, compressedLength : 22
}
@Test
public void decompressTest(){
//创建一个缓冲区来保存解压后的数据
byte [] decompressData = new byte [rawData.length];
//创建一个缓冲区保存压缩后的数据
byte [] compressedData = new byte[compressor.maxCompressedLength(rawData.length)];
//压缩、及压缩后的数据长度 | 此处的压缩不是关注重点
int compressedLength = compressor.compress(rawData, 0, rawData.length, compressedData, 0);
//解压 | 关注重点
//解压方式1
//int FACTOR = 200;//缓存区倍率
//byte [] compressedData = decompressor.decompress(compressedData, 0 , compressedLength, rawDataLength * FACTOR );//假定知道 原始数据长度(rawDataLength) 时
//解压方式2
int decompressedLength = decompressor.decompress(compressedData, 0 , compressedLength, decompressData, 0);//假定知道 压缩数据长度(rawDataLength) 时
String decompressDataString = new String( decompressData, 0 , decompressedLength );
log.info("compressedData(hex):{}", BytesUtils.bytesToHexString(compressedData) );
//rawData(hex):cf48656c6c6f20576f726c64200c000b50576f726c640000000000000000000000000000000000000000000000000000000000000000000000000000000000
log.info("decompressData(hex): {}", BytesUtils.bytesToHexString(decompressData));
//compressedData(hex): 48656c6c6f20576f726c642048656c6c6f20576f726c642048656c6c6f20576f726c642048656c6c6f20576f726c64
log.info("decompressData(string): {}", decompressDataString);
log.info("decompressData.length : {} , decompressData.length : {}, decompressedLength : {}", decompressData.length, compressedData.length, compressedLength);
//rawData.length : 47 , compressedData.length : 63, compressedLength : 22
}
}
3.X 工具类:LZ4Utils
package com.markus.compress.utils;
import net.jpountz.lz4.*;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.StringReader;
import java.io.UnsupportedEncodingException;
import java.nio.charset.StandardCharsets;
/**
* @author: markus
* @date: 2022/5/22 4:54 下午
* @Description: Lz4压缩工具
* @Blog: http://markuszhang.com
*/
public class Lz4Utils {
private static final int ARRAY_SIZE = 4096;
private static LZ4Factory factory = LZ4Factory.fastestInstance();
private static LZ4Compressor compressor = factory.fastCompressor();
private static LZ4FastDecompressor decompressor = factory.fastDecompressor();
private static LZ4SafeDecompressor safeDecompressor = factory.safeDecompressor();
public static byte[] compress(byte[] bytes) {
if (bytes == null || bytes.length == 0) {
return null;
}
try {
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
LZ4BlockOutputStream lz4BlockOutputStream = new LZ4BlockOutputStream(outputStream, ARRAY_SIZE, compressor);
lz4BlockOutputStream.write(bytes);
lz4BlockOutputStream.finish();
return outputStream.toByteArray();
} catch (Exception e) {
System.err.println("Lz4压缩失败");
}
return null;
}
public static byte[] uncompress(byte[] bytes) {
if (bytes == null || bytes.length == 0) {
return null;
}
try {
ByteArrayOutputStream outputStream = new ByteArrayOutputStream(ARRAY_SIZE);
ByteArrayInputStream inputStream = new ByteArrayInputStream(bytes);
LZ4BlockInputStream decompressedInputStream = new LZ4BlockInputStream(inputStream, decompressor);
int count;
byte[] buffer = new byte[ARRAY_SIZE];
while ((count = decompressedInputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, count);
}
return outputStream.toByteArray();
} catch (Exception e) {
System.err.println("lz4解压缩失败");
}
return null;
}
public static void main(String[] args) {
byte[] bytes = "abcde_fghabcde_ghxxahcde".getBytes(StandardCharsets.UTF_8);
byte[] compress = compress(bytes);
byte[] decompress = uncompress(compress);
}
}
4 LZ4 在大数据场景的实践
以下是 LZ4 在大数据场景的实践,覆盖 Flink 状态后端、Kafka 消息压缩、Hadoop 生态集成,包含配置示例和性能优化技巧。
一、Flink 状态后端 LZ4 压缩配置
1. 适用场景
- 流处理任务状态存储(RocksDB 状态后端)
- Checkpoint / Savepoint 压缩
2. 核心配置(flink-conf.yaml)
# 1. 启用 RocksDB 状态后端
state.backend: rocksdb
# 2. 开启状态压缩(默认 LZ4)
state.backend.rocksdb.compression: lz4
# 3. 调整压缩级别(1=最快,默认;6=平衡;12=最高压缩比)
state.backend.rocksdb.compression.level: 3
# 4. Checkpoint 压缩(可选,推荐 ZSTD,但若要统一用 LZ4)
execution.checkpointing.compression: lz4
3. 代码级配置(可选)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置 RocksDB 状态后端并启用 LZ4 压缩
RocksDBStateBackend backend = new RocksDBStateBackend("hdfs:///flink/checkpoints");
backend.setCompressionType(CompressionType.LZ4);
backend.setCompressionLevel(3); // 对应命令行 -3
env.setStateBackend(backend);
4. 优化建议
- 实时低延迟场景:压缩级别设为 1(最快),减少 CPU 开销
- 高吞吐批处理场景:压缩级别设为 6,平衡压缩比和速度
- 若状态较大,建议搭配 RocksDB 分区索引 和 增量 Checkpoint
二、Kafka 消息 LZ4 压缩配置
1. 适用场景
- 生产者压缩消息减少网络传输
- 消费者解压(自动完成)
2. 生产者配置(producer.properties)
# 启用 LZ4 压缩
compression.type: lz4
# 批量发送阈值(配合压缩,默认 16384)
batch.size: 32768
# linger.ms 延长时间(默认 0,建议 5-10ms 积累数据)
linger.ms: 5
3. 消费者配置(无需额外压缩配置)
# 自动解压,无需手动设置
# 若需兼容其他压缩格式,可配置:
# compression.type: none (但不推荐)
4. 命令行示例
# 创建 LZ4 压缩的主题
kafka-topics.sh --create --topic lz4-test --bootstrap-server localhost:9092 --partitions 3 --replication-factor 1
# 生产者发送压缩消息(命令行)
kafka-console-producer.sh --topic lz4-test --bootstrap-server localhost:9092 --compression-codec lz4
# 消费者接收消息(自动解压)
kafka-console-consumer.sh --topic lz4-test --bootstrap-server localhost:9092 --from-beginning
5. 性能对比
| 压缩算法 | 压缩比 | 压缩速度 | 解压速度 | 适合场景 |
|---|---|---|---|---|
| LZ4 | 中 | 极快 | 极快 | 实时高吞吐 |
| Snappy | 中 | 极快 | 极快 | 通用实时 |
| ZSTD | 高 | 快 | 快 | 存储优化 |
三、Hadoop 生态 LZ4 集成
1. HDFS 文件 LZ4 压缩
配置(core-site.xml)
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.Lz4Codec</value>
</property>
命令行示例
# 压缩文件(生成 .lz4 后缀)
hadoop fs -Dmapreduce.output.fileoutputformat.compress=true \
-Dmapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.Lz4Codec \
-put local-file.txt /hdfs/path/
# 解压文件
hadoop fs -text /hdfs/path/local-file.txt.lz4 | hadoop fs -put - /hdfs/path/uncompressed.txt
2. MapReduce 任务压缩
配置(mapred-site.xml)
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.Lz4Codec</value>
</property>
3. Hive 表 LZ4 压缩
-- 创建表时指定 LZ4 压缩
CREATE TABLE lz4_table (
id INT,
name STRING
)
STORED AS ORC
TBLPROPERTIES (
'orc.compress'='LZ4'
);
-- 插入数据(自动压缩)
INSERT INTO lz4_table SELECT id, name FROM source_table;
四、关键优化技巧
1. 压缩级别选择
| 场景类型 | 推荐级别 | 说明 |
|---|---|---|
| 实时流处理 | 1-3 | 优先保证速度 |
| 离线批处理 | 6-9 | 优先压缩比 |
| 存储密集型 | 9-12 | 冷数据归档 |
2. 分块大小调整
- HDFS / 分布式存储:建议分块 64KB~256KB(与 LZ4
-B参数匹配) - Kafka:消息批次大小建议 32KB~64KB(配合
batch.size)
3. 硬件优化
- LZ4 对 CPU 缓存友好,建议任务绑定 CPU 核心(如 Flink
taskmanager.numberOfTaskSlots匹配 CPU 核心数) - 避免在 HDD 上频繁随机读写压缩文件,优先用 SSD
五、常见问题排查
1. 压缩/解压速度慢
- 检查 CPU 使用率(可能级别过高)
- 降低压缩级别(如从 9→3)
- 开启多线程(Flink RocksDB 自动支持,Kafka 2.0+ 支持多线程压缩)
2. 兼容性问题
- 老版本 Hadoop(<2.6)需手动安装 LZ4 库:
yum install lz4-devel - Flink 需确保依赖包存在:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-statebackend-rocksdb_2.12</artifactId> <version>${flink.version}</version> </dependency>
Y 推荐文献
K 操作实践
压缩算法的性能对比
- 在了解完lz4的算法思想、实现思路以及Java类库后,我们可以使用它来和其他压缩类进行一个性能对比
测试源代码:(相关源码可以去网友的github仓库)
测试脚本
package com.markus.compress.test;
import com.markus.compress.domain.User;
import com.markus.compress.service.UserService;
import com.markus.compress.utils.*;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.results.format.ResultFormatType;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
/**
* @author: markus
* @date: 2022/5/22 5:08 下午
* @Description: 压缩工具的性能测试
* @Blog: http://markuszhang.com/
*/
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class PerformanceTest {
/**
* 用来序列化的用户对象
*/
@State(Scope.Benchmark)
public static class CommonState {
User user;
byte[] originBytes;
byte[] lz4CompressBytes;
byte[] snappyCompressBytes;
byte[] gzipCompressBytes;
byte[] bzipCompressBytes;
byte[] deflateCompressBytes;
@Setup(Level.Trial)
public void prepare() {
UserService userService = new UserService();
user = userService.get();
originBytes = ProtostuffUtils.serialize(user);
lz4CompressBytes = Lz4Utils.compress(originBytes);
snappyCompressBytes = SnappyUtils.compress(originBytes);
gzipCompressBytes = GzipUtils.compress(originBytes);
bzipCompressBytes = Bzip2Utils.compress(originBytes);
deflateCompressBytes = DeflateUtils.compress(originBytes);
}
}
/**
* Lz4压缩
*
* @param commonState
* @return
*/
@Benchmark
public byte[] lz4Compress(CommonState commonState) {
return Lz4Utils.compress(commonState.originBytes);
}
/**
* lz4解压缩
*
* @param commonState
*/
@Benchmark
public byte[] lz4Uncompress(CommonState commonState) {
return Lz4Utils.uncompress(commonState.lz4CompressBytes);
}
/**
* snappy压缩
*
* @param commonState
* @return
*/
@Benchmark
public byte[] snappyCompress(CommonState commonState) {
return SnappyUtils.compress(commonState.originBytes);
}
/**
* snappy解压缩
*
* @param commonState
* @return
*/
@Benchmark
public byte[] snappyUncompress(CommonState commonState) {
return SnappyUtils.uncompress(commonState.snappyCompressBytes);
}
/**
* Gzip压缩
*
* @param commonState
* @return
*/
@Benchmark
public byte[] gzipCompress(CommonState commonState) {
return GzipUtils.compress(commonState.originBytes);
}
/**
* Gzip解压缩
*
* @param commonState
* @return
*/
@Benchmark
public byte[] gzipUncompress(CommonState commonState) {
return GzipUtils.uncompress(commonState.gzipCompressBytes);
}
/**
* bzip2压缩
*
* @param commonState
* @return
*/
@Benchmark
public byte[] bzip2Compress(CommonState commonState) {
return Bzip2Utils.compress(commonState.originBytes);
}
/**
* bzip2压缩
*
* @param commonState
* @return
*/
@Benchmark
public byte[] bzip2Uncompress(CommonState commonState) {
return Bzip2Utils.uncompress(commonState.bzipCompressBytes);
}
/**
* bzip2压缩
*
* @param commonState
* @return
*/
@Benchmark
public byte[] deflateCompress(CommonState commonState) {
return DeflateUtils.compress(commonState.originBytes);
}
/**
* bzip2压缩
*
* @param commonState
* @return
*/
@Benchmark
public byte[] deflateUncompress(CommonState commonState) {
return DeflateUtils.uncompress(commonState.deflateCompressBytes);
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(PerformanceTest.class.getSimpleName())
.forks(1)
.threads(1)
.warmupIterations(10)
.measurementIterations(10)
.result("PerformanceTest.json")
.resultFormat(ResultFormatType.JSON).build();
new Runner(opt).run();
}
}
测试结果
- 性能测试图:
附上lz4官网给出的性能测试图和自己测试的性能图,有些差异,有可能对于压缩数据的不同导致的差异。
官网提供的:
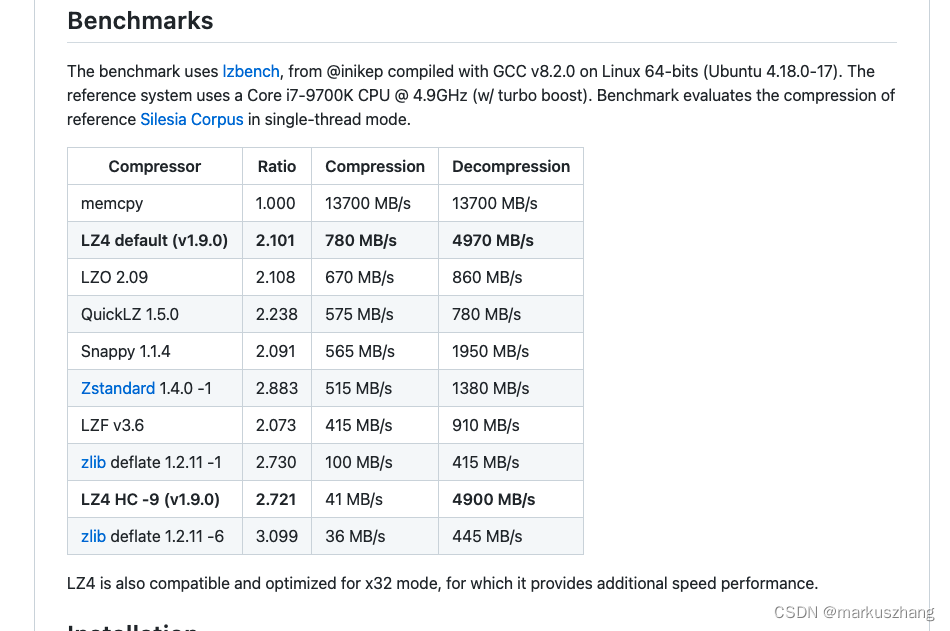
网友自测的:
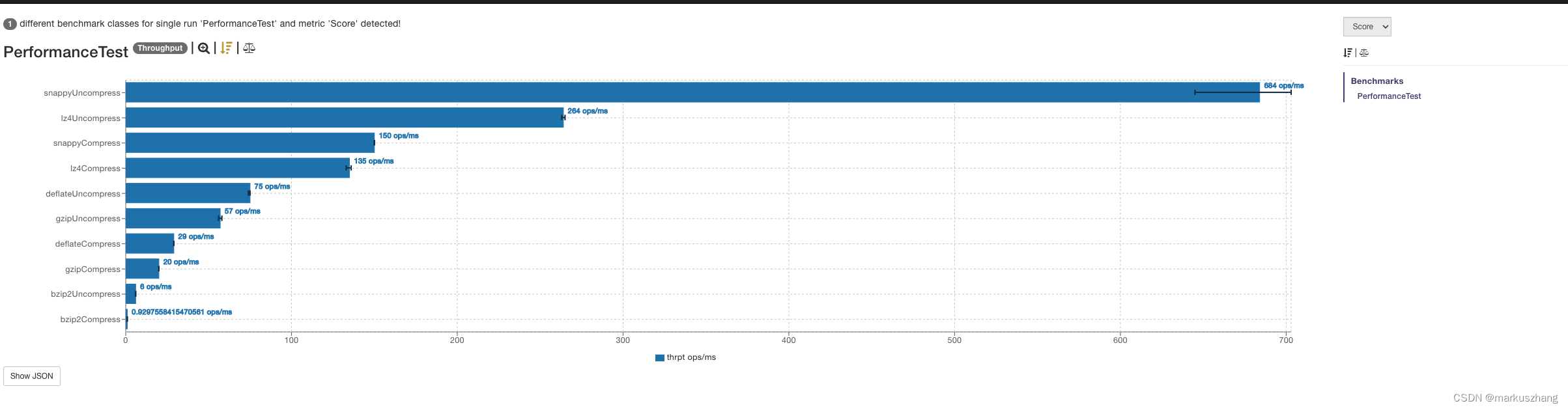
对于特征内容的压缩,观察lz4和snappy的对比,看上去lz4和snappy的压缩和解压缩的性能差不多,但lz4更稳定些,尖刺场景少。
压缩算法的压缩率对比
- 在压缩率上,按照从高到低是:
bzip2 > Deflate > Gzip > lz4 > snappy
测试脚本
CompressDemo
package com.markus.compress.demo;
import com.alibaba.fastjson.JSONObject;
import com.markus.compress.domain.User;
import com.markus.compress.service.UserService;
import com.markus.compress.utils.*;
import java.nio.charset.StandardCharsets;
/**
* @author: markus
* @date: 2022/5/22 3:52 下午
* @Description: 压缩字节示例
* @Blog: http://markuszhang.com/
*/
public class CompressDemo {
public static void main(String[] args) {
User user = new UserService().get();
// json序列化
byte[] origin_json = JSONObject.toJSONBytes(user);
System.out.println("原始json字节数: " + origin_json.length);
// pb序列化
byte[] origin = ProtostuffUtils.serialize(user);
System.out.println("原始pb字节数: " + origin.length);
testGzip(origin, user);
testSnappy(origin, user);
testLz4(origin, user);
testBzip2(origin, user);
testDeflate(origin, user);
}
private static void test(){
System.out.println("--------------------");
String str = getString();
byte[] source = str.getBytes(StandardCharsets.UTF_8);
byte[] compress = Lz4Utils.compress(source);
// 将compress转为字符串
System.out.println(translateString(compress));
System.out.println();
System.out.println("--------------------");
String str2 = getString2();
byte[] source2 = str2.getBytes(StandardCharsets.UTF_8);
byte[] compress2 = Lz4Utils.compress(source2);
byte[] uncompress = Lz4Utils.uncompress(compress2);
System.out.println();
}
private static String translateString(byte[] bytes) {
char[] chars = new char[bytes.length];
for (int i = 0; i < chars.length; i++) {
chars[i] = (char) bytes[i];
}
String str = new String(chars);
return str;
}
private static String getString() {
return "fghabcde_bcdefgh_abcdefghxxxxxxx";
}
private static String getString2() {
return "abcde_fghabcde_ghxxahcde";
}
private static void testGzip(byte[] origin, User user) {
System.out.println("---------------GZIP压缩---------------");
// Gzip压缩
byte[] gzipCompress = GzipUtils.compress(origin);
System.out.println("Gzip压缩: " + gzipCompress.length);
byte[] gzipUncompress = GzipUtils.uncompress(gzipCompress);
System.out.println("Gzip解压缩: " + gzipUncompress.length);
User deUser = ProtostuffUtils.deserialize(gzipUncompress, User.class);
System.out.println("对象是否相等: " + user.equals(deUser));
}
private static void testSnappy(byte[] origin, User user) {
System.out.println("---------------Snappy压缩---------------");
// Snappy压缩
byte[] snappyCompress = SnappyUtils.compress(origin);
System.out.println("Snappy压缩: " + snappyCompress.length);
byte[] snappyUncompress = SnappyUtils.uncompress(snappyCompress);
System.out.println("Snappy解压缩: " + snappyUncompress.length);
User deUser = ProtostuffUtils.deserialize(snappyUncompress, User.class);
System.out.println("对象是否相等: " + user.equals(deUser));
}
private static void testLz4(byte[] origin, User user) {
System.out.println("---------------Lz4压缩---------------");
// Lz4压缩
byte[] Lz4Compress = Lz4Utils.compress(origin);
System.out.println("Lz4压缩: " + Lz4Compress.length);
byte[] Lz4Uncompress = Lz4Utils.uncompress(Lz4Compress);
System.out.println("Lz4解压缩: " + Lz4Uncompress.length);
User deUser = ProtostuffUtils.deserialize(Lz4Uncompress, User.class);
System.out.println("对象是否相等: " + user.equals(deUser));
}
private static void testBzip2(byte[] origin, User user) {
System.out.println("---------------bzip2压缩---------------");
// bzip2压缩
byte[] bzip2Compress = Bzip2Utils.compress(origin);
System.out.println("bzip2压缩: " + bzip2Compress.length);
byte[] bzip2Uncompress = Bzip2Utils.uncompress(bzip2Compress);
System.out.println("bzip2解压缩: " + bzip2Uncompress.length);
User deUser = ProtostuffUtils.deserialize(bzip2Uncompress, User.class);
System.out.println("对象是否相等: " + user.equals(deUser));
}
private static void testDeflate(byte[] origin, User user) {
System.out.println("---------------Deflate压缩---------------");
// Deflate压缩
byte[] deflateCompress = DeflateUtils.compress(origin);
System.out.println("Deflate压缩: " + deflateCompress.length);
byte[] deflateUncompress = DeflateUtils.uncompress(deflateCompress);
System.out.println("Deflate解压缩: " + deflateUncompress.length);
User deUser = ProtostuffUtils.deserialize(deflateUncompress, User.class);
System.out.println("对象是否相等: " + user.equals(deUser));
}
}
测试结果
- out
原始json字节数: 5351
原始pb字节数: 3850
---------------GZIP压缩---------------
Gzip压缩: 2170
Gzip解压缩: 3850
对象是否相等: true
---------------Snappy压缩---------------
Snappy压缩: 3396
Snappy解压缩: 3850
对象是否相等: true
---------------Lz4压缩---------------
Lz4压缩: 3358
Lz4解压缩: 3850
对象是否相等: true
---------------bzip2压缩---------------
bzip2压缩: 2119
bzip2解压缩: 3850
对象是否相等: true
---------------Deflate压缩---------------
Deflate压缩: 2167
Deflate解压缩: 3850
对象是否相等: true
Process finished with exit code 0
Y 推荐文献
-
LZ4 / LZ4C
- https://github.com/lz4/lz4 (LZ4 官方 GitHub(命令行工具源码))
- https://lz4.github.io/lz4/manual.html#CommandLineOptions (LZ4 命令行手册)
X 参考文献
- lz4 - github【推荐】
- zstd - github
zstd(81%)在【压缩率】优于lz4(71%);但在【压缩、解压时间】上lz4远远优于zstd,lz4不愧为压缩界的速度之王
Clickhouse 数据压缩主要使用两个方案LZ4和ZSTD
LZ4解压缩速度上会更快,但压缩率较低, ZSTD解压缩较慢。但是压缩比例较高。
https://www.percona.com/blog/2016/04/13/evaluating-database-compression-methods-update
- Lz4压缩算法学习 - CSDN 【参考/推荐】
- Java的LZ4解压缩工具 - 51CTO
- lz4解压缩 - jianshu
- ios / android
- 速度之王 — LZ4压缩算法(三) - 博客园
- LZ4:压缩速率之王,其优势在于压缩和解压速度,而不是压缩比
- 压缩比排序:lz4 < lz4_HC < gzip < bzip2
- 大数据存储压缩算法调研:snappy、gzip还是lz4? - 51CTO 【推荐】 【TODO】
- 压缩速率 : LZ4 > Snappy > zstd 和 GZIP
- 压缩比:zstd > LZ4 > GZIP > Snappy
即:如果网络不好、且 CPU 资源够,不需要考虑浏览器和操作系统的支持度的话,建议使用 zstd 压缩
- CPU 使用率方面:各个算法表现得差不多,只是在压缩时
Snappy算法使用的 CPU 较多一些,而在解压时GZIP算法则可能使用更多的 CPU。

本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号