[Python]编译错误:编码错误问题(SyntaxError: (unicode error) )
1 错误信息
python文件
1 #coding:utf-8
2
3 class Clz:
4 def func(filePath):
5 """
6 func
7 -----
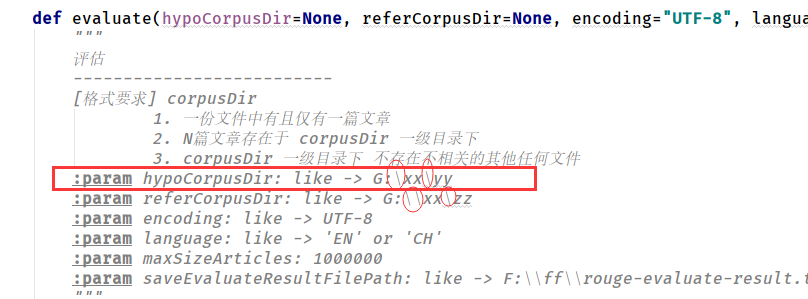
8 :param filePath : like -> D:\xx\yy\zz.txt
9 """
File "E:/workspace/PyDemo20190618/../Clz.py", line 9
"""
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 669-670: truncated \xXX escape
2 分析原因
-
文件自身编码与文件首行声明的编码不一致。
-
函数下方的注释区或者文件其它区域(""" ...""") 存在对【含斜下划线,即 转义字符)】的描述,导致python编译器编译时出错。【此点,较为难发现、排除,亦系撰写本博客的本质原因】
【深层次原因(不完全确定)】在Python中 \ 是转义符,\u表示其后是UNICODE编码,在编译阶段,python编译器与正则表达式语法发生冲突。因此,在第9行会报错。
解决办法1:单斜下划线(转义字符)【\】换为双斜下划线【\\】
解决办法2:在字符串前面加个【r】符(rawstring 原生字符串)
以此避免python与正则表达式语法的冲突。
3 文献

本文作者:
千千寰宇
本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!
本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号