数组中最大子数组之和2
一、实验目的
1,以指定格式的文本文件形式输入数组。
2,数组由一维变为二维。
3,熟练使用git常用命令将作业签入代码版本控制平台。
4,给出单元测试/代码覆盖率的最终覆盖率的报告,撰写博客。
二、实验代码
import pandas as pd import numpy as np def count_Line(filepath): # 该函数用于获取文本文件的行数 with open(filepath, 'r', encoding='UTF8') as f: count_line = 0 # 存储文本文件的行数 while True: # 获取文本文件的行数 line = f.readline() if not line: break count_line += 1 return count_line def readline(filepath, lineNum): with open(filepath, 'r', encoding='UTF8') as f: count_line = count_Line(filepath) # 存储文本文件的行数 if lineNum == count_line: # 判断是否读取到了文件的最后一行 out = f.readlines()[lineNum - 1] else: out = f.readlines()[lineNum - 1][0:-1] # 读取文件,并读取指定行 str_row = '' # 用于将每一行中分隔起来的每一个有效数据保存 num = [] # 用于存入有效数据 count = 0 # 用于记录数据是否读取完毕 judge = [',', ','] # 判断分隔符用 for x in out: count += 1 if x not in judge: str_row += x # 将需要的数据提取出来(’连续的数字‘ 或 ’负号加连续的数字‘) elif x in judge: num.append(str_row) str_row = '' # 将分隔符前的实数放入数组 num 中 if count == len(out): num.append(str_row) str_row = '' # 将最后一个数据也放入数组 num 中 if '' in num: num.remove('') # 去掉数组中的空元素 num = list(map(int, num)) # 将字符串数组转换成整型数组 return num def doubleArray(filepath): # 该函数用于将上述文本文件中的二维数组存储起来 outLine_1 = readline(filepath, 1) num_douArray = [] for x in range(outLine_1[0]): num_douArray.append(readline(filepath, x+3)) return num_douArray def getAllNumSons(filepath, num): data = pd.DataFrame(num) # 将 num 转换成 DataFrame 数据形式 NUM =[] # 用来存放所有的连续子数组 for x in range(readline(filepath, 2)[0]): # x 用来指定从哪一行开始截取原二维数组 for y in range(readline(filepath, 1)[0] + 1): # y 用来指定到哪一行结束截取原二维数组 if len(data[x:y]) != 0: # 判断是否有空的数据 data_1 = data[x:y] # 将截取的数据赋值给 data_1 for i in range(readline(filepath, 2)[0]): # i 用来指定从哪一列开始截取 data_1 for j in range(readline(filepath, 2)[0] + 1): # j 用来指定到哪一列结束截取 data_1 if len(list(data_1.iloc[:, i:j])) != 0: # 判断是否有空值 data_array = np.array(data_1.iloc[:, i:j]) # 将 DataFrame 转换成 array NUM.append(data_array.tolist()) # 将这个子数组放入 NUM 中 return NUM def outPut(filepath): # 此函数的参数为文本文件的路径 num = doubleArray(filepath) NUM = getAllNumSons(filepath, num) numSum = [] # 用来存放每个子数组的和 for x in NUM: numSum.append(sum(map(sum, x))) return max(numSum), NUM[numSum.index(max(numSum))] # 返回最大子数组之和 和 最大子数组
三、单元测试(unittest)
3.1代码:
import unittest from 最大子数组之和2.lbk import outPut filepath2 = r'C:\Users\VULCAN\Desktop\test.txt' class Test(unittest.TestCase): def test_outPut(self): self.assertEqual(outPut(filepath2), (964, [[9, 12, -9, -2, 23], [201, -1, 309, 3, 6], [100, 21, 292, -2, 2]])) if __name__ == "__main__": unittest.main()
3.2test文件:

3.3测试结果:
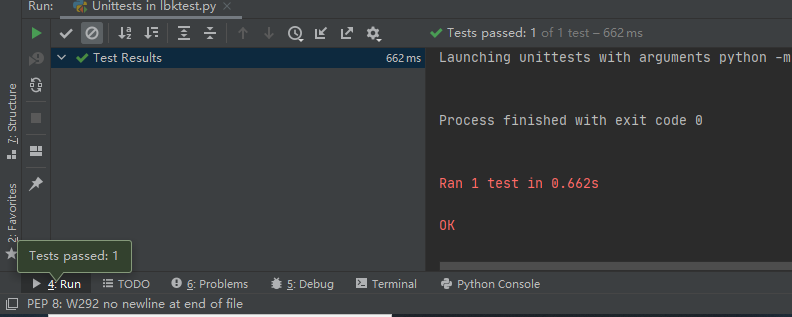
四、代码覆盖率(coverage)
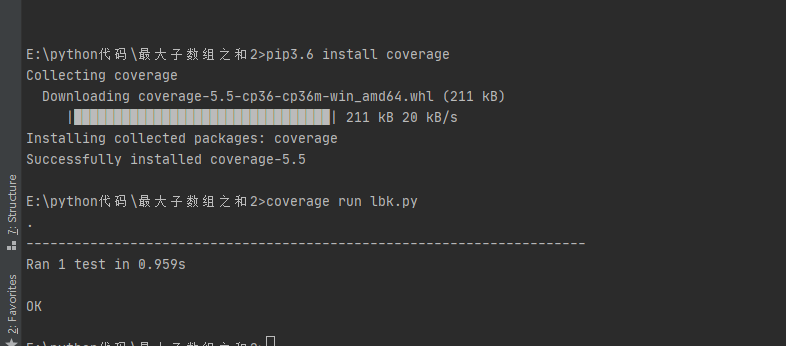
4.1代码覆盖率测试
4.2生成报告

文件中打开:
最终结果:
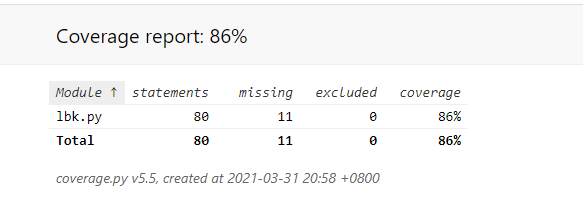

其中红色代码表示未覆盖,绿色代表已经覆盖的代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号