Transformer中K 、Q、V的设置以及为什么不能使用同一个值
What is attention?
先简单描述一下attention机制是什么。相信做NLP的同学对这个机制不会很陌生,它在Attention is all you need可以说是大放异彩,在machine translation任务中,帮助深度模型在性能上有了很大的提升,输出了当时最好的state-of-art model。当然该模型除了attention机制外,还用了很多有用的trick,以帮助提升模型性能。但是不能否认的时,这个模型的核心就是attention。
attention机制:又称为注意力机制,顾名思义,是一种能让模型对重要信息重点关注并充分学习吸收的技术,它不算是一个完整的模型,应当是一种技术,能够作用于任何序列模型中。
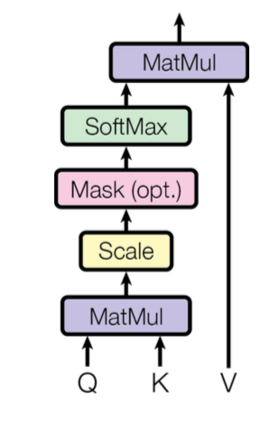
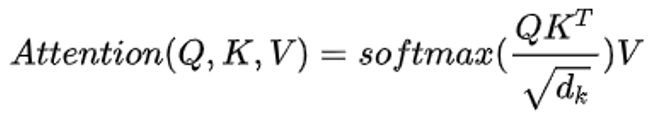
为什么Transformer中K 、Q不能使用同一个值
既然K和Q差不多(唯一区别是W_k和W_Q权值不同),直接拿K自己点乘就行了,何必再创建一个Q?创建了还要花内存去保存,不断去更新,多麻烦。
想要回答这个问题,我们首先要明白,为什么要计算Q和K的点乘。
现补充两点
- 先从点乘的物理意义说,两个向量的点乘表示两个向量的相似度。
2. Q,K,V物理意义上是一样的,都表示同一个句子中不同token组成的矩阵。矩阵中的每一行,是表示一个token的word embedding向量。假设一个句子"Hello, how are you?"长度是6,embedding维度是300,那么Q,K,V都是(6, 300)的矩阵
简单的说,K和Q的点乘是为了计算一个句子中每个token相对于句子中其他token的相似度,这个相似度可以理解为attetnion score,关注度得分。比如说 "Hello, how are you?"这句话,当前token为”Hello"的时候,我们可以知道”Hello“对于” , “, "how", "are", "you", "?"这几个token对应的关注度是多少。有了这个attetnion score,可以知道处理到”Hello“的时候,模型在关注句子中的哪些token。

这个attention score是一个(6, 6)的矩阵。每一行代表每个token相对于其他token的关注度。比如说上图中的第一行,代表的是Hello这个单词相对于本句话中的其他单词的关注度。添加softmax只是为了对关注度进行归一化。
虽然有了attention score矩阵,但是这个矩阵是经过各种计算后得到的,已经很难表示原来的句子了。然而V还代表着原来的句子,所以我们拿这个attention score矩阵与V相乘,得到的是一个加权后结果。也就是说,原本V里的各个单词只用word embedding表示,相互之间没什么关系。但是经过与attention score相乘后,V中每个token的向量(即一个单词的word embedding向量),在300维的每个维度上(每一列)上,都会对其他token做出调整(关注度不同)。与V相乘这一步,相当于提纯,让每个单词关注该关注的部分。
好了,该解释为什么不把K和Q用同一个值了。
经过上面的解释,我们知道K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。K和Q使用了不同的W_k, W_Q来计算,可以理解为是在不同空间上的投影。正因为有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。这里解释下我理解的泛化能力,因为K和Q使用了不同的W_k, W_Q来计算,得到的也是两个完全不同的矩阵,所以表达能力更强。
但是如果不用Q,直接拿K和K点乘的话,你会发现attention score 矩阵是一个对称矩阵。因为是同样一个矩阵,都投影到了同样一个空间,所以泛化能力很差。这样的矩阵导致对V进行提纯的时候,效果也不会好。
=========================================================
在attention中,主要分为两部分,一部分是相似度矩阵的计算,也就是softmax(kq^T),另一部分是利用相似度矩阵将原v值映射到一个新的空间。
那接下来我们需要考虑一点:在已知输入x的情况下,如何建立相似度矩阵?
- 最简单的方式就是自身点乘也就是xx^T,其可以表征在本空间内的相似度。
- 但通常原空间的相似度是不够的,为了使得模型有更强的表征能力,我们需要其在其他空间映射的相似度,这一点可以参考核函数的设计思想。这时一个最标准的做法就是xWx^T(参考马氏距离)。如果对其进行拆解就是xW1(xW2)^T,可以看到此时kq已经有所不同了。
- W1,W2如果保持相同,那么这个距离是对称自反的,也就是d(x1,x2)=d(x2,x1)。但是在attention中,这种对称自反其实是不必要的,想象一下“我是一个男孩”这句话,男孩对修饰我的重要性应该要高于我修饰男孩的重要性。
假设有一个词库,这里面有100个词,现在有两个词,他们的词向量是A和B
现在有一个训练任务,假设是翻译,那么attention机制就是将词向量根据你的训练任务细分成了三个属性,即QKV,这3个属性变换需要的矩阵都是训练得到的。
Q(query)可以理解为词向量A在当前训练语料下的注意力权重,它保存了剩下99个词与A之间的关系。
K(key)是权重索引,通过用别的词(比如B)的注意力索引K(key)与A的注意力权重(Query)相乘,就可以得到B对A的注意力加权
V(value)可以理解为在当前训练语料下的词向量,是在原有词向量的基础上,利用当前训练语料进行强化训练后得到的词向量
这样一来通过QK就可以计算出一句话中所有词对A的注意力加权,然后将这个注意力加权与各自对应的新词向量(value)相乘,就可以得到这句话中所有词对A词的注意力加权词向量集,接下来我们就可以通过这个向量集作为输入,预测A的翻译结果。
https://www.zhihu.com/question/319339652/answer/1617993669
欢迎转载,转载请保留页面地址。帮助到你的请点个推荐。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号