全面解读Group Normalization,对比BN,LN,IN
前言
Face book AI research(FAIR)吴育昕-何恺明联合推出重磅新作Group Normalization(GN),提出使用Group Normalization 替代深度学习里程碑式的工作Batch normalization,本文将从以下三个方面为读者详细解读此篇文章:
What's wrong with BN ?
How GN work ?
Why GN work ?
Group Normalizition是什么
一句话概括,Group Normalization(GN)是一种新的深度学习归一化方式,可以替代BN。众所周知,BN是深度学习中常使用的归一化方法,在提升训练以及收敛速度上发挥了重大的作用,是深度学习上里程碑式的工作。
但是其仍然存在一些问题,而新提出的GN解决了BN式归一化对batch size依赖的影响。
So, BN到底出了什么问题, GN又厉害在哪里?
What's wrong with BN
BN全名是Batch Normalization,见名知意,其是一种归一化方式,而且是以batch的维度做归一化,那么问题就来了,此归一化方式对batch是independent的,过小的batch size会导致其性能下降,一般来说每GPU上batch设为32最合适;
但是对于一些其他深度学习任务batch size往往只有1-2,比如目标检测,图像分割,视频分类上,输入的图像数据很大,较大的batchsize显存吃不消。那么,对于较小的batch size,其performance是什么样的呢?如下图:
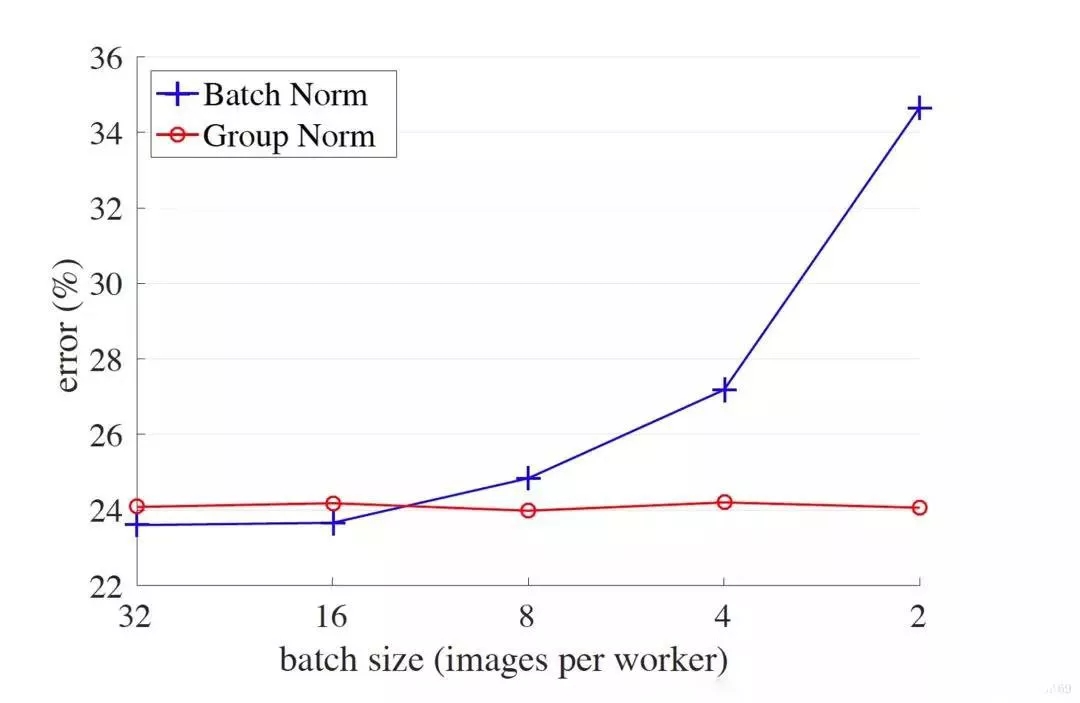
横轴表示每个GPU上的batch size大小,从左到右一次递减,纵轴是误差率,可见,在batch较小的时候,GN较BN有少于10%的误差率。
另外,Batch Normalization是在batch这个维度上Normalization,但是这个维度并不是固定不变的,比如训练和测试时一般不一样,一般都是训练的时候在训练集上通过滑动平均预先计算好平均-mean,和方差-variance参数。
在测试的时候,不再计算这些值,而是直接调用这些预计算好的来用,但是,当训练数据和测试数据分布有差别是时,训练机上预计算好的数据并不能代表测试数据,这就导致在训练,验证,测试这三个阶段存在inconsistency。
既然明确了问题,解决起来就简单了,归一化的时候避开batch这个维度是不是可行呢,于是就出现了layer normalization和instance normalization等工作,但是仍比不上本篇介绍的工作GN。
How GN work
GN本质上仍是归一化,但是它灵活的避开了BN的问题,同时又不同于Layer Norm,Instance Norm ,四者的工作方式从下图可窥一斑:

从左到右依次是BN,LN,IN,GN
众所周知,深度网络中的数据维度一般是[N, C, H, W]或者[N, H, W,C]格式,N是batch size,H/W是feature的高/宽,C是feature的channel,压缩H/W至一个维度,其三维的表示如上图,假设单个方格的长度是1,那么其表示的是[6, 6,*, * ]
上图形象的表示了四种norm的工作方式:
BN在batch的维度上norm,归一化维度为[N,H,W],对batch中对应的channel归一化;
LN避开了batch维度,归一化的维度为[C,H,W];
IN 归一化的维度为[H,W];
而GN介于LN和IN之间,其首先将channel分为许多组(group),对每一组做归一化,及先将feature的维度由[N, C, H, W]reshape为[N, G,C//G , H, W],归一化的维度为[C//G , H, W]
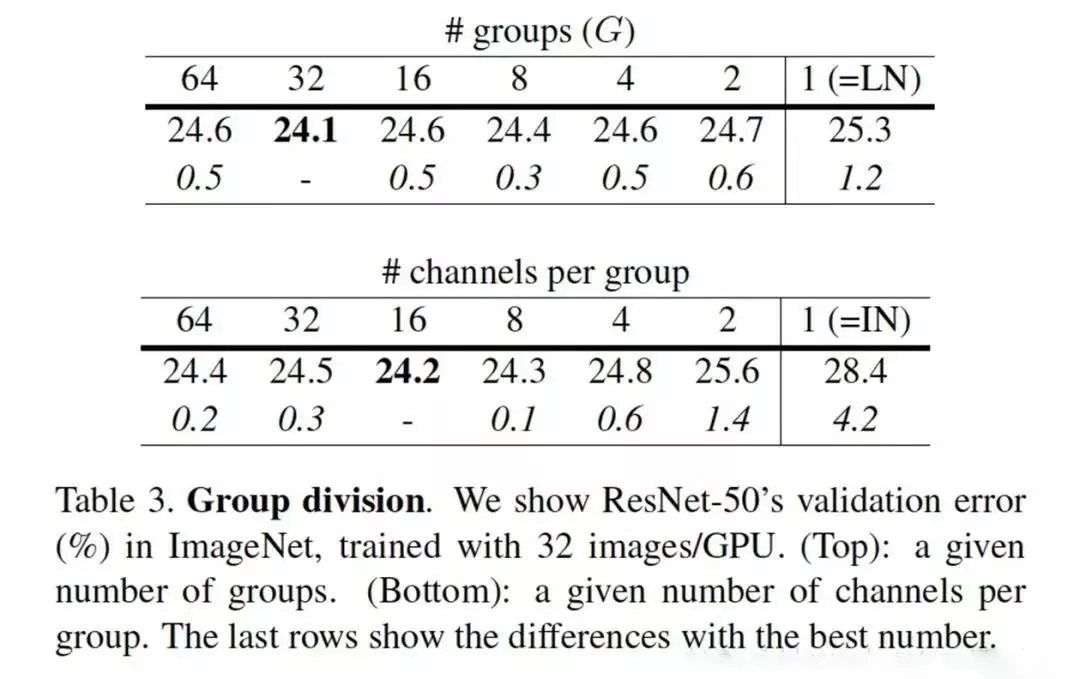
事实上,GN的极端情况就是LN和I N,分别对应G等于C和G等于1,作者在论文中给出G设为32较好
由此可以看出,GN和BN是有很多相似之处的,代码相比较BN改动只有一两行而已,论文给出的代码实现如下:
def GroupNorm(x, gamma, beta, G, eps=1e-5): # x: input features with shape [N,C,H,W] # gamma, beta: scale and offset, with shape [1,C,1,1] # G: number of groups for GN N, C, H, W = x.shape x = tf.reshape(x, [N, G, C // G, H, W]) mean, var = tf.nn.moments(x, [2, 3, 4], keep dims=True) x = (x - mean) / tf.sqrt(var + eps) x = tf.reshape(x, [N, C, H, W]) return x * gamma + beta
其中beta 和gama参数是norm中可训练参数,表示平移和缩放因子,具体介绍见博客,从上述norm的对比来看,不得不佩服作者四两拨千斤的功力,仅仅是稍微的改动就能拥有举重若轻的效果。
Why GN work
上面三节分别介绍了BN的问题,以及GN的工作方式,本节将介绍GN work的原因。
传统角度来讲,在深度学习没有火起来之前,提取特征通常是使用SIFT,HOG和GIST特征,这些特征有一个共性,都具有按group表示的特性,每一个group由相同种类直方图的构建而成,这些特征通常是对在每个直方图(histogram)或每个方向(orientation)上进行组归一化(group-wise norm)而得到。
而更高维的特征比如VLAD和Fisher Vectors(FV)也可以看作是group-wise feature,此处的group可以被认为是每个聚类(cluster)下的子向量sub-vector。
从深度学习上来讲,完全可以认为卷积提取的特征是一种非结构化的特征或者向量,拿网络的第一层卷积为例,卷积层中的的卷积核filter1和此卷积核的其他经过transform过的版本filter2(transform可以是horizontal flipping等),在同一张图像上学习到的特征应该是具有相同的分布,那么,具有相同的特征可以被分到同一个group中,按照个人理解,每一层有很多的卷积核,这些核学习到的特征并不完全是独立的,某些特征具有相同的分布,因此可以被group。
导致分组(group)的因素有很多,比如频率、形状、亮度和纹理等,HOG特征根据orientation分组,而对神经网络来讲,其提取特征的机制更加复杂,也更加难以描述,变得不那么直观。
另在神经科学领域,一种被广泛接受的计算模型是对cell的响应做归一化,此现象存在于浅层视觉皮层和整个视觉系统。
作者基于此,提出了组归一化(Group Normalization)的方式,且效果表明,显著优于BN、LN、IN等。GN的归一化方式避开了batch size对模型的影响,特征的group归一化同样可以解决$Internal$ $Covariate$ $Shift$的问题,并取得较好的效果。
效果展示
showtime!
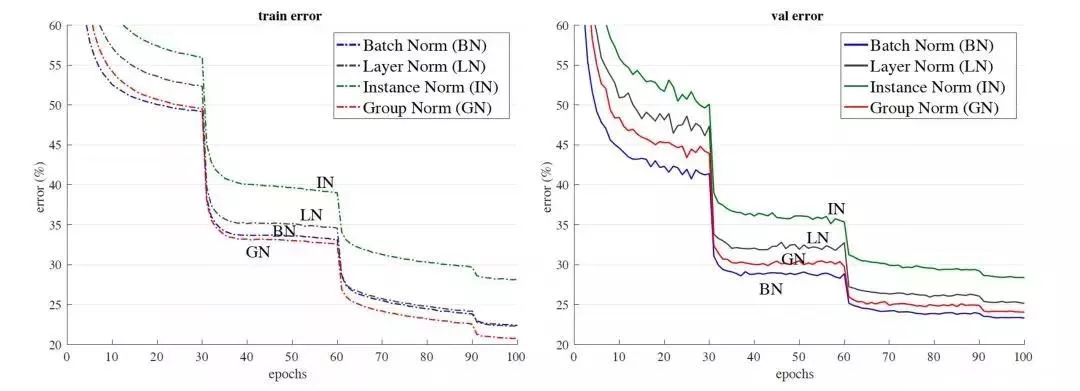
以resnet50为base model,batchsize设置为32在imagenet数据集上的训练误差(左)和测试误差(右)。GN没有表现出很大的优势,在测试误差上稍大于使用BN的结果。
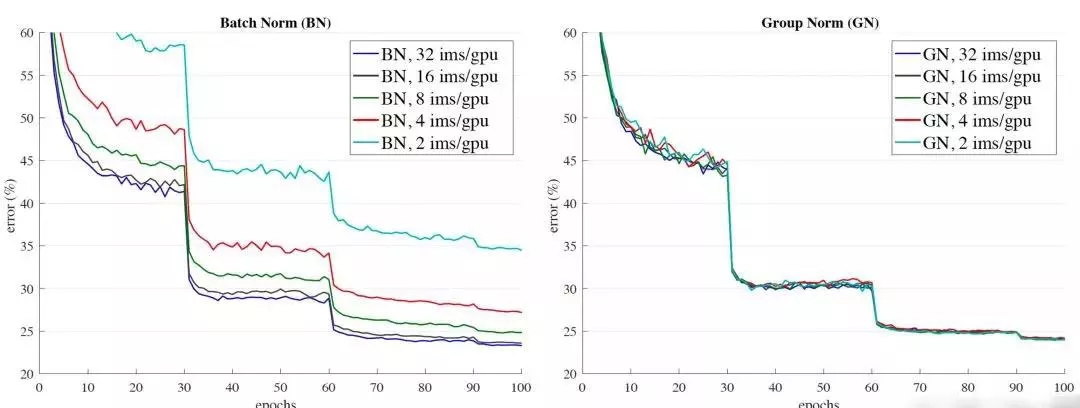
可以很容易的看出,GN对batch size的鲁棒性更强
同时,作者以VGG16为例,分析了某一层卷积后的特征分布学习情况,分别根据不使用Norm 和使用BN,GN做了实验,实验结果如下:
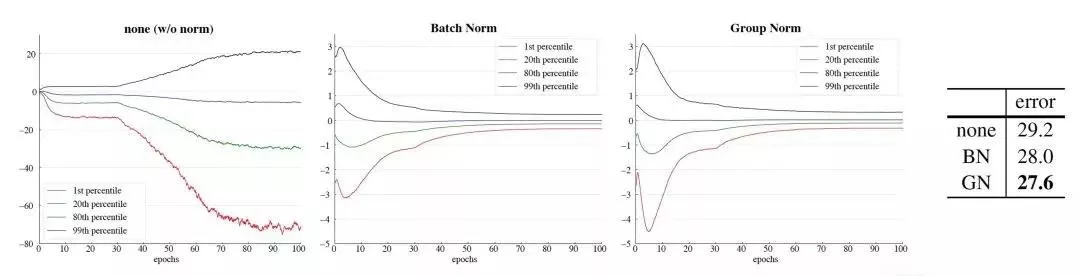
统一batch size设置的是32,最左图是不使用norm的conv5的特征学习情况,中间是使用了BN结果,最右是使用了GN的学习情况,相比较不使用norm,使用norm的学习效果显著,而后两者学习情况相似,不过更改小的batch size后,BN是比不上GN的。
欢迎转载,转载请保留页面地址。帮助到你的请点个推荐。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号