

RNN总结
RNN总结
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN 就能够很好地解决这类问题。
RNN基本结构
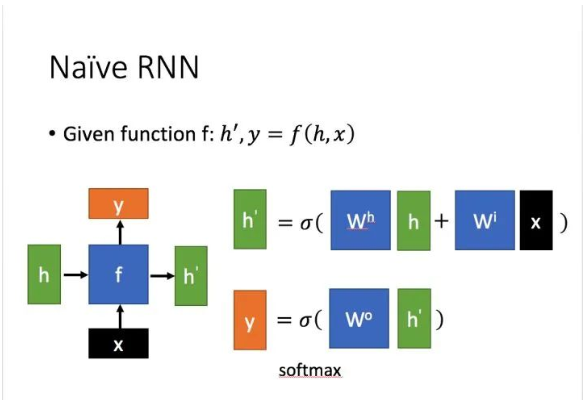
这里:
x为当前状态下数据的输入, h表示接收到的上一个节点的输入。
y为当前节点状态下的输出,而 h`为传递到下一个节点的输出。
通过上图的公式可以看到,输出 h' 与 x 和 h 的值都相关。而 y 则常常使用 h' 投入到一个线性层(主要是进行维度映射)然后使用softmax进行分类得到需要的数据,一般情况下不适用y。
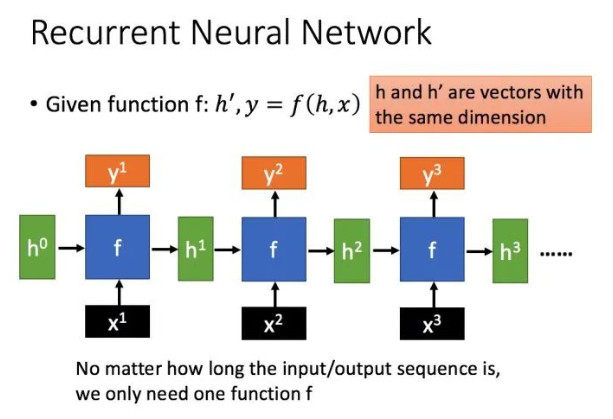
RNN的缺点
使用Rnn会出现长文本处理时候效果很差,是因为Rnn只能记忆最近的序列,记性太差,而且会出现梯度消失、梯度爆炸的情况。
这篇文章已经总结的挺好。
https://www.cnblogs.com/jiangxinyang/p/9362922.html
RNN的分类
- sequence-to-sequence:输入输出都是一个序列。例如股票预测中的RNN,输入是前N天价格,输出明天的股市价格。
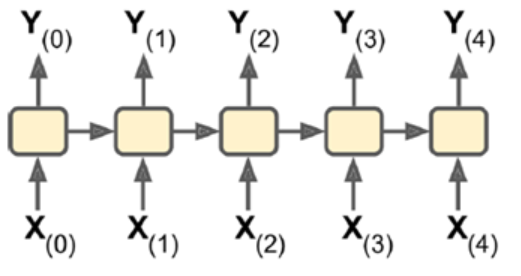
- sequence-to-vector:输入是一个序列,输出单一向量。
例如,输入一个电影评价序列,输出一个分数表示情感趋势(喜欢还是讨厌)。

- vector-to-sequence:输入单一向量,输出一个序列。
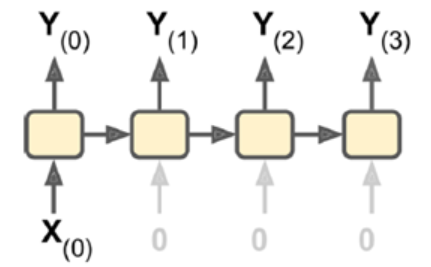
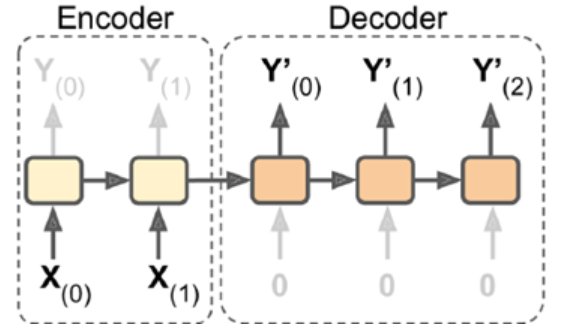
4.Encoder-Decoder:输入sequence-to-vector,称作encoder,输出vector-to-sequence,称作decoder。
这是一个delay模型,经过一段延迟,即把所有输入都读取后,在decoder中获取输入并输出一个序列。这个模型在机器翻译中使用较广泛,源语言输在入放入encoder,浓缩在状态信息中,生成目标语言时,可以生成一个不长度的目标语言序列。
Pytorch实现RNN
class torch.nn.RNN(args,*kwargs)[source]

注意:
batch_first这个参数为True时候,输入Tensor的shape是[batch_size,seq_length,feature],关于这个shape问题是,初学者可能对[batch_size,time_step,feature]更为理解,但是在处理序列的时候,应该是[seq_length,batch_size,feature],因为在训练时候是x0,x1,x2,x3....这样输入的,如果是按照[seq_length,batch_size,feature]这种形式,就可以根据序列长度,每次送入batch_size个字符。
rnn的输入

其中,h_0如果初始值为0,那么可以直接省略
rnn的输出

rnn的模型参数

使用rnn实现正弦函数预测
import torch
import numpy as np
from torch import nn
import matplotlib.pyplot as plt
num_time_steps=50
input_size=1
hidden_size=16
output_size=1
lr=0.001
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.model=nn.RNN(
input_size=input_size,
hidden_size=hidden_size,
num_layers=1,
batch_first=True
)
# 这里对参数进行初始化
for p in self.model.parameters():
nn.init.normal_(p,mean=0.0,std=0.001)
self.linear=nn.Linear(hidden_size,output_size)
def forward(self,x,hidden_prev):
out,hidden_prev = self.model(x,hidden_prev)
out=out.view(-1,hidden_size)
out=self.linear(out)
out=out.unsqueeze(dim=0)
return out,hidden_prev
model=Net()
criterion=nn.MSELoss()
optimizer=torch.optim.Adam(model.parameters(),lr)
# h0的初始值
hidden_prev = torch.zeros(1,1,hidden_size)
for iter in range(10000):
start = np.random.randint(3, size=1)[0]
time_steps = np.linspace(start, start + 10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().reshape(1, num_time_steps - 1, 1)
y = torch.tensor(data[1:]).float().reshape(1, num_time_steps - 1, 1)
output,hidden_prev=model(x,hidden_prev)
# 这一句是干啥的?
hidden_prev=hidden_prev.detach()
loss=criterion(output,y)
# 这里的 语句和 optimizer.zero_grad()有什么区别
model.zero_grad()
loss.backward()
optimizer.step()
if iter % 100 ==0:
print("Iteration: {} loss {}".format(iter,loss.item()))
start = np.random.randint(6,10, size=1)[0]
time_steps = np.linspace(start, start + 10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().reshape(1, num_time_steps - 1, 1)
y = torch.tensor(data[1:]).float().reshape(1, num_time_steps - 1, 1)
prdictions=[]
input=x[:,0,:]
for _ in range(x.shape[1]):
input=input.view(1,1,1)
# 这里看不懂
(pred,hidden_prev) =model(input,hidden_prev)
input=pred
prdictions.append(pred.detach().numpy().ravel()[0])
x =x.data.numpy().ravel()
y=y.data.numpy()
plt.scatter(time_steps[:-1],x.ravel(),s=90)
plt.plot(time_steps[:-1],x.ravel())
plt.scatter(time_steps[1:],prdictions)
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号