

HashSet底层、及存入对象时候如何保持唯一
HashSet底层、及存入对象时候如何保持唯一
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。 但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。
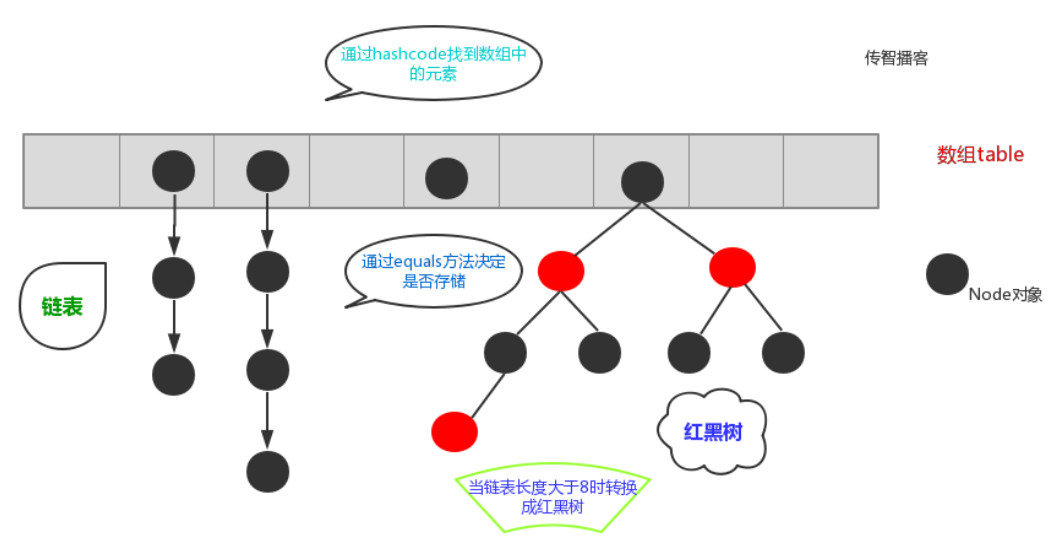
为了更加直观的理解,HashSet是如何存储的,我们用下图解释:
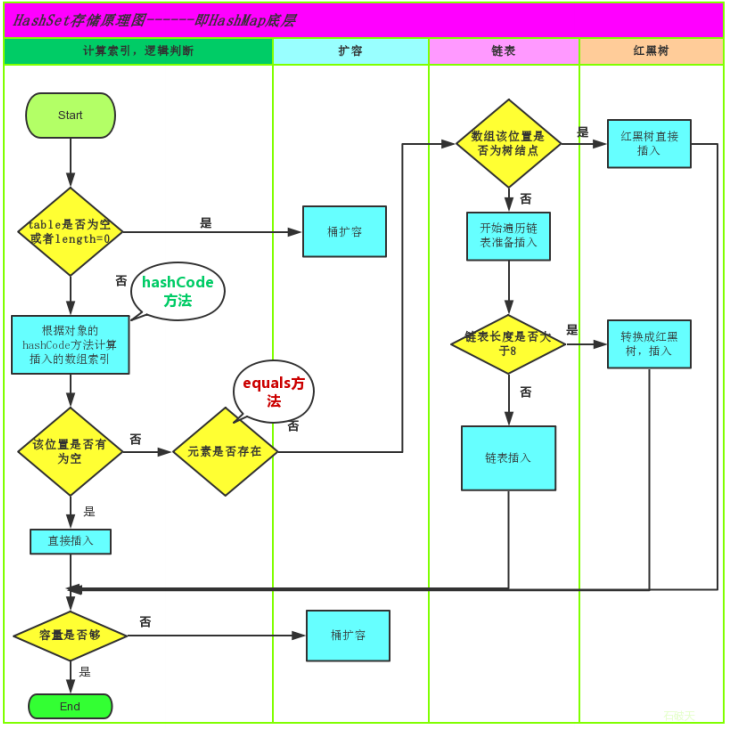
总而言之,JDK1.8引入红黑树大程度优化了HashMap的性能,那么对于我们来讲保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
我们接下来举个例子:
@Data
public class Student {
private String name;
private int age;
@Override public boolean equals(Object o) {
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override public int hashCode() {
return Objects.hash(name, age);
}
注意:在将对象添加入集合时候,应该重写equals和hashCode方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号