

系统可靠性设计之看门狗
看门狗不是万能之药,优秀的系统设计通过静态代码分析,MPU保护,CRC校验,全面的单元测试将异常挡之门外。
看门狗(Watchdog Timer, WDT)是保障嵌入式系统可靠性的关键机制,有基础看门狗可窗口看门狗(不能太早或太迟,智能在规定的时间窗口内喂狗)。
窗口看门狗应用场合(裸机正确+严格时序):
- 高安全性系统(如汽车电子、医疗设备):
- 防止程序逻辑错乱后“狂喂狗”却功能异常。
- 确定性要求高的控制循环:
- 要求任务在固定时间窗内完成,既不能太快(逻辑未执行完),也不能太慢(控制失效)。
- 防止程序跑飞后进入假“正常”状态:
- 普通看门狗无法检测“程序仍在喂狗但逻辑错误”的情况,窗口看门狗可缓解。
总结:窗口看门狗用于需要严格时序约束 + 防逻辑错乱喂狗的高可靠性场景。

裸机前后台环境的喂狗策略:
- 不能简单的在main循环中喂狗,即使喂了也无法检测到任务内部死锁、死循环或长时间阻塞。
- 可在循环内关键执行点后,或结合状态机/事件处理阶段进行条件喂狗
- 可设置“健康标志位”,各模块执行成功后置位,喂狗前检查所有标志。
- 关键模块成功执行不是指简单的逻辑与,正确做法是区分关键等级+动态降级机制,核心安全模块0容忍(在汽车电子中(ISO 26262 ASIL等级)),重要功能模块超过阈值才认为异常不喂狗:
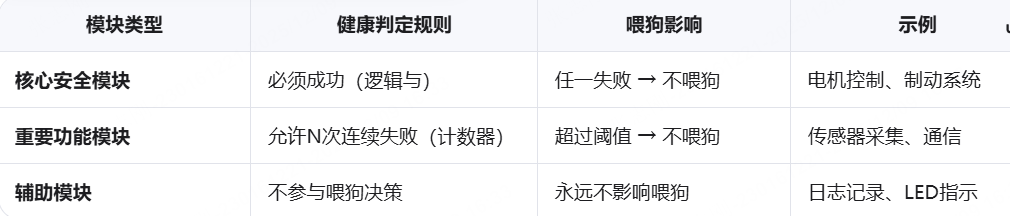
RTOS环境的喂狗策略:
- 不能简单在所有的任务重都喂狗。因为任一任务活跃即可阻止复位,无法检测其他任务卡死。
- 使用“看门狗定时器服务任务”(Watchdog Service Task),集中管理喂狗逻辑。
- 由一个“监督任务”(Monitor Task该需确认其他关键任务处于活跃状态)统一喂狗。方法:其他任务定期更新“心跳标志”或向监督任务发信号(如消息队列、事件标志组)。
-
RTOS多任务中,如何处理任务耦合与动态条件?
采用「双通道监控」架构:心跳通道(基础存活) + 业务通道(功能正确),这是汽车电子(AUTOSAR)和工业控制(IEC 61508)的标准做法:1心跳通道:各模块若正常周期给心跳通道发各自心跳;2 业务通道:有业务数据就认为正常。但平台对设备的在线判断就是心跳通道和业务通道只要有一个正常即判断正常。
✅ 汽车电子实践(AUTOSAR):
在ECU中,监督任务(Watchdog Manager)会区分:- Alive Supervision(心跳监控):检测任务死锁
- Deadline Supervision(截止时间监控):检测任务超时
- Logical Supervision(逻辑监控):验证业务状态机
三者全部通过才允许喂狗,否则触发安全状态(如关闭电机)
-
 View Code
View Code// 全局状态机(带互斥锁保护) typedef enum { SYS_IDLE, SYS_RUNNING, SYS_DEGRADED, SYS_FAULT } SysState; SysState g_system_state = SYS_IDLE; SemaphoreHandle_t state_mutex; // 任务心跳结构 typedef struct { TickType_t last_heartbeat; bool functional_ok; // 业务健康标志 } TaskHealth; TaskHealth task_a_health = {0, false}; TaskHealth task_b_health = {0, false}; // 监督任务(优先级:中) void watchdog_monitor(void *pv) { const TickType_t xDelay = pdMS_TO_TICKS(100); // 100ms周期 while(1) { bool all_alive = true; bool critical_ok = true; // 1. 检查心跳存活(基础层) if((xTaskGetTickCount() - task_a_health.last_heartbeat) > pdMS_TO_TICKS(200)) all_alive = false; if((xTaskGetTickCount() - task_b_health.last_heartbeat) > pdMS_TO_TICKS(300)) all_alive = false; // 2. 检查业务状态(功能层) xSemaphoreTake(state_mutex, portMAX_DELAY); if(g_system_state == SYS_FAULT) critical_ok = false; if(!task_a_health.functional_ok) critical_ok = false; // 注意:task_b的健康可能依赖task_a,由task_b自身判断 xSemaphoreGive(state_mutex); // 3. 喂狗决策 if(all_alive && critical_ok) { feed_watchdog(); } else { trigger_fault_log(); // 记录故障细节 } vTaskDelay(xDelay); } } // 任务A(条件X驱动) void task_a(void *pv) { while(1) { // 更新心跳(证明任务存活) task_a_health.last_heartbeat = xTaskGetTickCount(); // 业务逻辑:仅当条件X满足时执行 if(check_condition_X()) { bool success = execute_critical_A(); task_a_health.functional_ok = success; // 更新全局状态机 if(success) { xSemaphoreTake(state_mutex, portMAX_DELAY); if(g_system_state == SYS_IDLE) g_system_state = SYS_RUNNING; xSemaphoreGive(state_mutex); } } else { task_a_health.functional_ok = false; // 条件不满足,业务不健康 } vTaskDelay(pdMS_TO_TICKS(50)); } } // 任务B(依赖TaskA结果+条件Y) void task_b(void *pv) { while(1) { task_b_health.last_heartbeat = xTaskGetTickCount(); // 业务逻辑:检查依赖状态 xSemaphoreTake(state_mutex, portMAX_DELAY); bool taskA_healthy = task_a_health.functional_ok; SysState current_state = g_system_state; xSemaphoreGive(state_mutex); if(taskA_healthy && check_condition_Y() && current_state == SYS_RUNNING) { bool success = execute_critical_B(); task_b_health.functional_ok = success; // 状态升级(例如:B成功后系统进入稳定状态) if(success) { xSemaphoreTake(state_mutex, portMAX_DELAY); g_system_state = SYS_STABLE; xSemaphoreGive(state_mutex); } } else { task_b_health.functional_ok = false; // 可选:进入降级模式 if(!taskA_healthy) enter_safe_mode(); } vTaskDelay(pdMS_TO_TICKS(100)); } } if(基础存活 && 业务健康) feed_dog(); else if(基础存活) { // 业务故障但任务存活 → 尝试降级恢复 enter_safe_mode(); // 不喂狗!等待看门狗复位(或人工干预) } else { // 任务死锁 → 立即不喂狗 }

看门狗超时时间的确定:
最长正常任务执行周期 < 看门狗超时时间 < 系统可容忍的最大故障恢复时间。
设计步骤:
- 分析系统最坏执行路径(Worst-Case Execution Time, WCET):包括所有中断、任务、通信、控制算法等在高负载下的最大耗时。
- 加上安全裕量(如 20%~50%),防止偶发延迟触发误复位。
- 考虑电源、时钟稳定性:若系统时钟可能漂移,需留余量。
- 避免过长:超时太长会延长故障恢复时间,降低系统可用性。
📌 示例:若系统最大循环周期为 100ms,则 WDT 超时可设为 200~300ms

 浙公网安备 33010602011771号
浙公网安备 33010602011771号