
OHEM Online Hard Example Mining
论文地址
https://arxiv.org/pdf/1604.03540.pdf
引言
当前基于深度学习的目标检测主要包括:基于 two-stage 的目标检测和基于 one-stage 的目标检测。two-stage 的目标检测框架一般检测精度相对较高,但检测速度慢;而 one-stage 的目标检测速度相对较快,但是检测精度相对较低。one-stage 的精度不如 two-stage 的精度,一个主要的原因是训练过程中样本极度不均衡造成的。
样本类别
目标检测任务中,样本类别包括:
- 正样本:标签区域内的图像区域,即目标图像块;
- 负样本:标签区域以外的图像区域,即图像背景区域;
- 易分正样本:容易正确分类的正样本,在实际训练过程中,该类占总体样本的比重非常高,单个样本的损失函数较小,但是累计的损失函数会主导损失函数;
- 易分负样本:容易正确分类的负样本,在实际训练过程中,该类占的比重非常高,单个样本的损失函数较小,但是累计的损失函数会主导损失函数;
- 难分正样本:错分成负样本的正样本,这部分样本在训练过程中单个样本的损失函数教高,但是该类占总体样本的比例教小;
- 难分负样本:错分成正样本的负样本,这部分样本在训练过程中单个样本的损失函数教高,但是该类占总体样本的比例教小。
样本不均衡问题
所谓的样本不平衡问题是指在训练的时候各个类别的样本数量极不均衡。以基于深度学习的单阶段目标检测为例,样本类别不均衡主要体现在两方面:正负样本不均衡(正负样本比例达到 1:1000)和难易样本不均衡(简单样本主导 loss)。一般在目标检测任务框架中,保持正负样本的比例为 1:3(经验值)。
对于一个样本,如果它能很容易地被正确分类,那么这个样本对模型来说就是一个简单样本,模型很难从这个样本中得到更多的信息;而对于一个分错的样本,它对模型来说就是一个困难的样本,它更能指导模型优化的方向。
对于单阶段分类器来说,简单样本的数量非常大,他们产生的累计贡献在模型更新中占主导作用,而这部分样本本身就能被模型很好地分类,所以这部分的参数更新并不会改善模型的判断能力,这会导致整个训练变得低效。
实际训练过程中如何划分正负样本训练集
近年来,不少的研究者针对样本不均衡问题进行了深入研究,比较典型的有 OHEM [1](在线困难样本挖掘)、S-OHEM[2]、A-Fast-RCNN[3]、Focal Loss[4]、GHM[5](梯度均衡化)。样本不均衡的处理方法
OHEM(在线困难样本挖掘)
OHEM 算法[1](Online Hard Example Mining,发表于 2016 年的 CVPR)主要是针对训练过程中的困难样本自动选择,其核心思想是根据输入样本的损失进行筛选,筛选出困难样本(即对分类和检测影响较大的样本),然后将筛选得到的这些样本应用在随机梯度下降中训练。
在实际操作中是将原来的一个 ROI Network 扩充为两个 ROI Network,这两个 ROI Network 共享参数。其中前面一个 ROI Network 只有前向操作,主要用于计算损失;后面一个 ROI Network 包括前向和后向操作,以 hard example 作为输入,计算损失并回传梯度。该算法在目标检测框架中被大量使用,如 Fast RCNN。
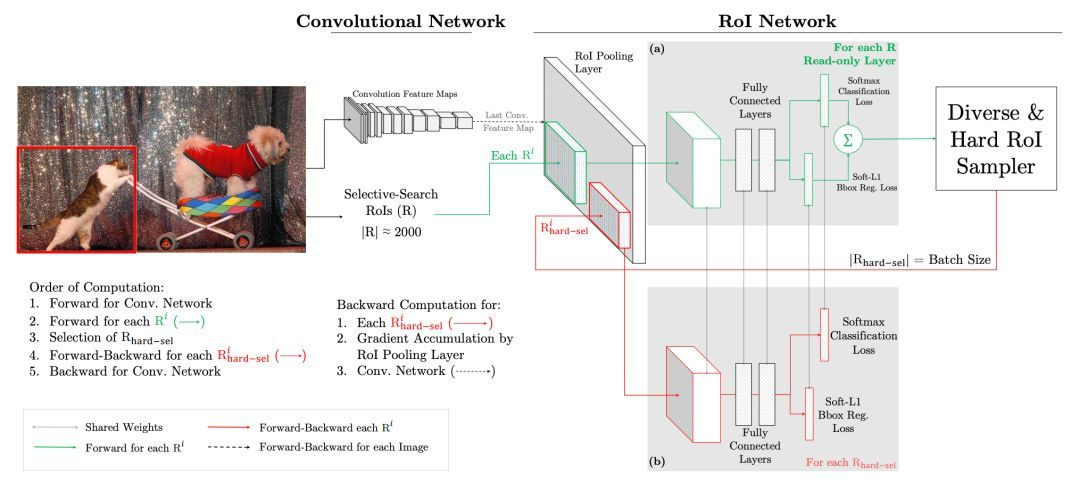
该算法的优点:1)对于数据的类别不平衡问题不需要采用设置正负样本比例的方式来解决,这种在线选择方式针对性更强;2)随着数据集的增大,算法的提升更加明显。
该算法的缺点:只保留 loss 较高的样本,完全忽略简单的样本,这本质上是改变了训练时的输入分布(仅包含困难样本),这会导致模型在学习的时候失去对简单样本的判别能力。
S-OHEM(基于loss分布采样的在线困难样本挖掘)
先来看看原生的 OHEM 存在什么问题?假设给定 RoI_A 和 RoI_B,其对应的分类和边框回归损失分别为和。
如果按照原生的 OHEM(假定各损失函数权重相同),此时 RoI_A 的总体 loss 大于 RoI_B,也就是说 A 相对于 B 更难分类;而实际上单从分类损失函数(交叉熵),RoI_A 和 RoI_B 的实际类别概率分别是 61.6% 和 64.5%,在类别概率上两者只相差 0.031,可以认为 A 和 B 具有相同的性能。
单从边框损失函数(Smooth L1),虽然 A 和 B 的损失函数只相差 0.01,但这个微小的差会导致预测边框和 groudtruth 有 0.14 的差距,此时,B 相对于 A 更难分类,因此单从 top-N 损失函数来筛选困难样本是不可靠的。
针对上述问题,提出了 S-OHEM 方法[2](发表于 2017 年的 CCCV),主要考虑 OHEM 训练过程忽略了不同损失分布的影响,因此 S-OHEM 根据 loss 的分布抽样训练样本。它的做法是将预设 loss 的四个分段:
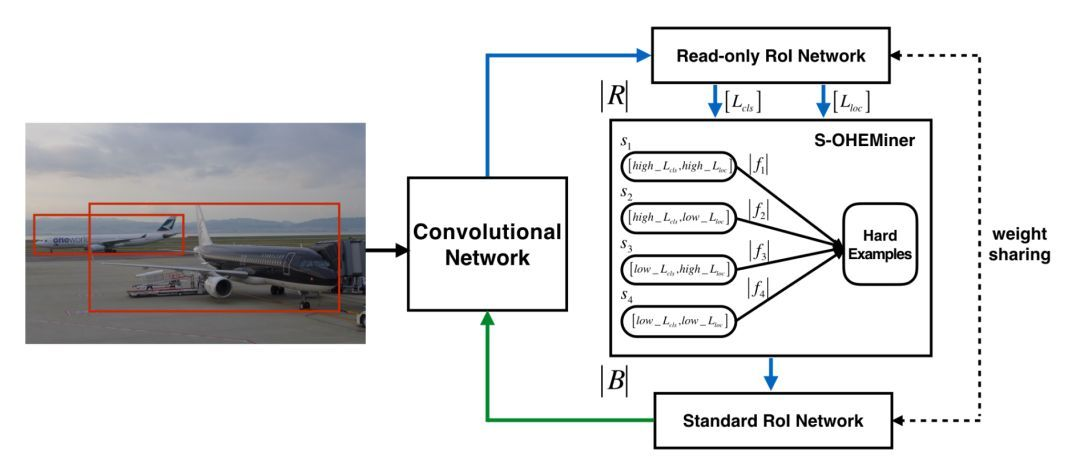
给定一个 batch,先生成输入 batch 中所有图像的候选 RoI,再将这些 RoI 送入到 Read only RoI 网络得到 RoIs 的损失,然后将每个 RoI 根据损失(这里损失是一个组合,具体公式为,α,β 随着训练阶段变化而变化。
之所以采用这个公式是因为在训练初期阶段,分类损失占主导作用;在训练后期阶段,边框回归损失函数占主导作用)划分到上面四个分段中,然后针对每个分段,通过排序筛选困难样本。再将经过筛选的 RoIs 送入反向传播,用于更新网络参数。
优点:相比原生 OHEM,S-OHEM 考虑了基于不同损失函数的分布来抽样选择困难样本,避免了仅使用高损失的样本来更新模型参数。
缺点:因为不同阶段,分类损失和定位损失的贡献不同,所以选择损失中的两个参数 α,β 需要根据不同训练阶段进行改变,当应用与不同数据集时,参数的选取也是不一样的.即引入了额外的超参数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号