
一、scrapy的下载安装---Windows(安装软件太让我伤心了)
写博客就和笔记一样真的很有用,你可以随时的翻阅。爬虫的爬虫原理与数据抓取、非结构化与结构化数据提取、动态HTML处理和简单的图像识别已经学完,就差整理博客了
开始学习scrapy了,所以重新建了个分类。
scrapy的下载到安装,再到能够成功运行就耗费了我三个小时的时间,为了防止以后忘记,记录一下。
我用的是Python3.6. Windows 需要四步
1、pip3 install wheel
2、安装Twisted
a. http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted, 下载:Twisted-17.9.0-cp36-cp36m-win_amd64.whl
b. 进入文件所在目录
c. pip3 install Twisted-17.1.0-cp35-cp35m-win_amd64.whl
3、pip3 install scrapy
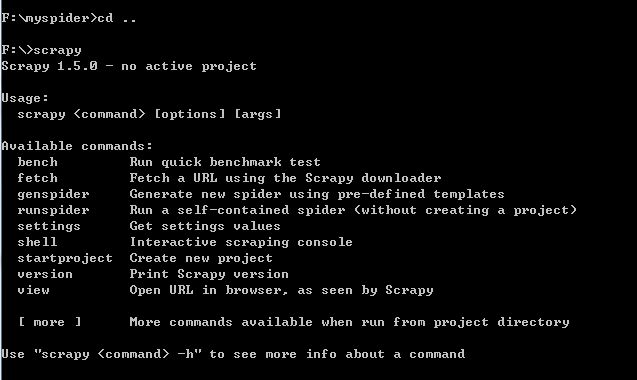
然后我打开cmd,输入了scrapy, 出现:
scrapy startproject myspider -----------创建scrapy项目
cd myspider -----------进入myspider目录
scrapy genspider baidu baidu.com ------------创建爬虫文件
scrapy crawl baidu -------------运行文件
之后,就报错了,说缺少一个模块win32, 上网查说 windows上scrapy依赖pywin32,下载网址: https://sourceforge.net/projects/pywin32/files/
我下载了,在安装的时候出现了:
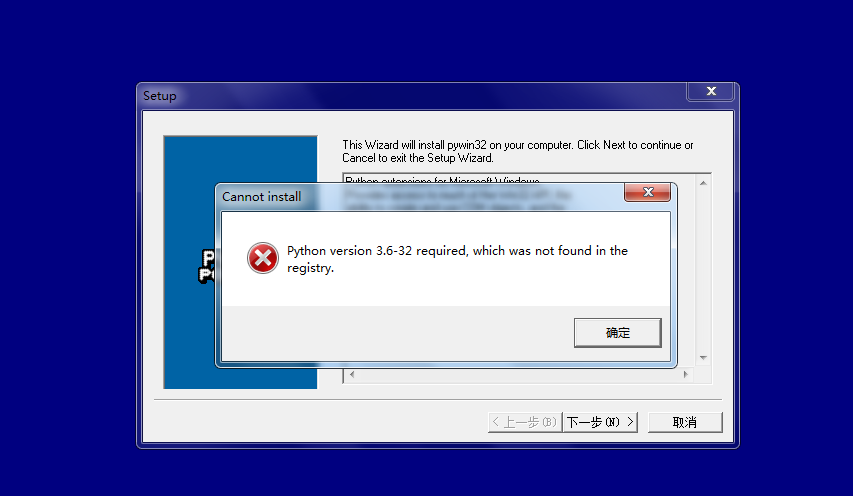
上面说是没注册什么的,上网搜了一下解决方案,唉,自己没看懂。痛心疾首,对我自己的智商感到捉急
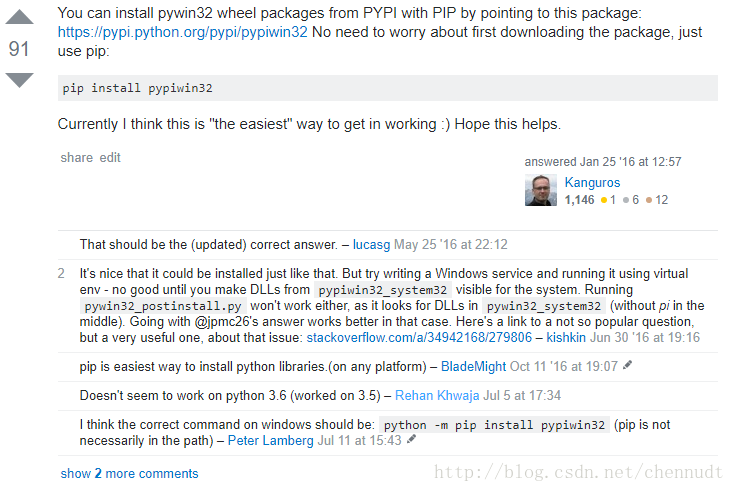
4、在cmd中使用python -m pip install pypiwin32
这是我成功的方法,上网查之后,在https://stackoverflow.com/questions/4863056/how-to-install-pywin32-module-in-windows-7有这样一段话:
每天一个小实例:爬视频(其实找到了视频的url链接,用urllib.request.urlretrieve(视频url,存储的路径)就可以了。
我做的这个例子太简单;用scrapy框架显得复杂,,我只是下载了一页,多页的话循环url,主要是走一遍使用Scrapy的流程:


1 #第一 2 打开mySpider目录下的items.py 3 4 # -*- coding: utf-8 -*- 5 6 # Define here the models for your scraped items 7 # 8 # See documentation in: 9 # https://doc.scrapy.org/en/latest/topics/items.html 10 11 import scrapy 12 13 '''Item 定义结构化数据字段,用来保存爬取到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误。 14 15 可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item(可以理解成类似于ORM的映射关系)。''' 16 class MyspiderItem(scrapy.Item): 17 # define the fields for your item here like: 18 name = scrapy.Field() 19 mp4_url = scrapy.Field() 20 21 22 23 #第二,打开你创建的爬虫文件,我的是baisi.py 24 25 # -*- coding: utf-8 -*- 26 import scrapy 27 from myspider.items import MyspiderItem 28 29 class BaisiSpider(scrapy.Spider): 30 name = 'baisi' 31 allowed_domains = ['http://www.budejie.com'] 32 start_urls = ['http://www.budejie.com/video/'] 33 34 def parse(self, response): 35 # 将我们得到的数据封装到一个 `MyspiderItem` 对象 36 item = MyspiderItem() 37 38 #提取数据 39 mp4_links = response.xpath('//li[@class="j-r-list-tool-l-down f-tar j-down-video j-down-hide ipad-hide"]') 40 for mp4_link in mp4_links: 41 name = mp4_link.xpath('./@data-text')[0].extract() 42 video = mp4_link.xpath('./a/@href')[0].extract() 43 #判断是否有MP4——url链接,有的保存 44 if video: 45 item['name'] = name 46 item['mp4_url'] = video 47 # 将获取的数据交给pipelines 48 yield item 49 50 51 52 53 54 #第三 打开pipelines.py文件 55 56 # -*- coding: utf-8 -*- 57 58 # Define your item pipelines here 59 # 60 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 61 # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html 62 import urllib.request 63 import os 64 class MyspiderPipeline(object): 65 def process_item(self, item, spider): 66 #文件名 67 file_name = "%s.mp4" % item['name'] 68 #文件保存路径 69 file_path = os.path.join("F:\\myspider\\myspider\\video", file_name) 70 urllib.request.urlretrieve(item['mp4_url'],file_path) 71 return item 72 73 74 第四,执行scrapy crawl baisi
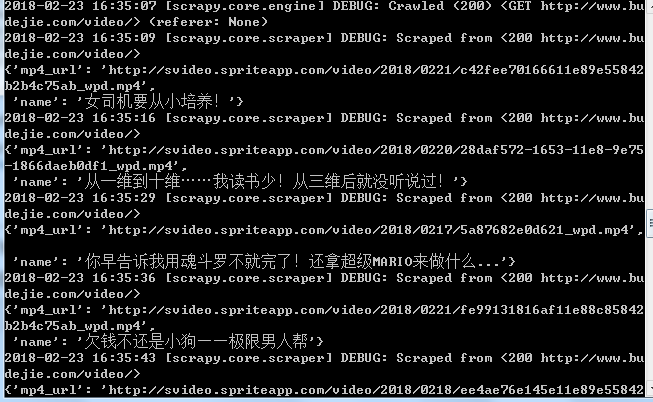
执行结果:
Scrapy 框架
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
- Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。 -
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
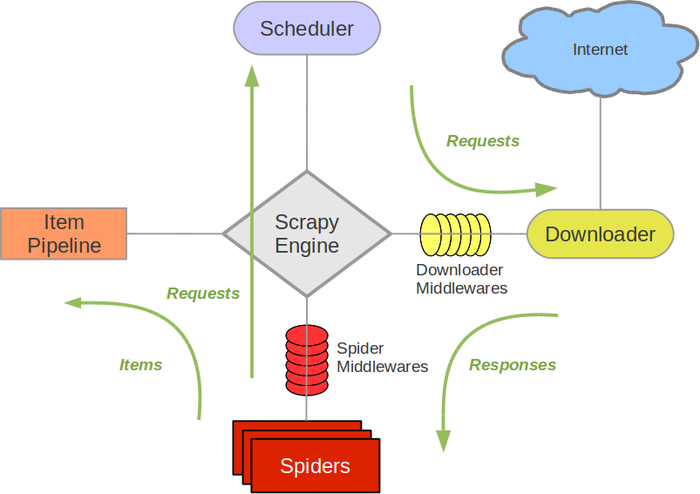
Scrapy架构图(绿线是数据流向):
-
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。 -
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。 -
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理, -
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器), -
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方. -
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。 -
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
scrapy运行的流程大概是:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取。
- 引擎把URL封装成一个请求(request)传给下载器。
- 下载器把资源下载下来,并封装成应答包(response)
- 爬虫解析response
- 解析出实体(item),则交给实体管道进行进一步处理
- 解析出的是衔接(URL),则把URL交给调度器等待抓取
基本使用:
1.在命令行中输入: scrapy startproject myspider -----------创建scrapy项目
自动创建目录:

打开:myspider
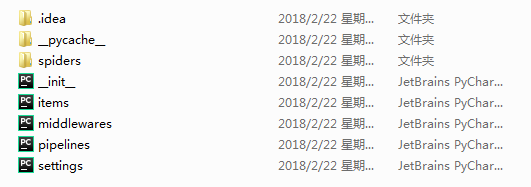
文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
2.
cd myspider -----------进入myspider目录
scrapy genspider baidu baidu.com ------------创建爬虫文件
注意:一般创建爬虫文件时,以网站域名命名,文件会在spiders中,
3. 然后你就可以编写代码了
4. scrapy crawl baidu -------------运行文件
总的来说:
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容


 浙公网安备 33010602011771号
浙公网安备 33010602011771号