Java基础—集合
一、概述
Java中的集合框架主要分为两大派别:Collection 和 Map —— 位于util包下
类的基础关系图如下(图片来自百度)
常用:
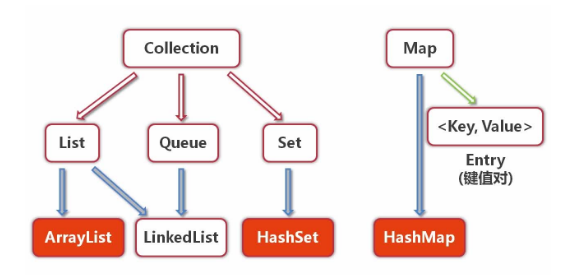
List——有序可重复
Set——无序不可重复
Map——key-value键值对的形式
完整家谱:

/
常用API可以查阅JDK API(IDEA中structure视图查看)
二、基本方法使用
基本的增删改查的方法,请自行依据API进行测试与练习。
list基本方法(ArrayList)
添加方法是:.add(e);
获取方法是:.get(index);
包含方法是:contains(Object o)
删除方法是:.remove(index); 按照索引删除; .remove(Object o); 按照元素内容删除;
其它常用方法与实例参见:http://www.cnblogs.com/epeter/p/5648026.html (完整内容请参见API)
set基本方法(HashSet)
添加方法是:.add(e);
删除方法是:.remove(Object o);
map基本方法(HashMap)
添加方法是:put(K key, V value) ;
删除方法是:remove(Object key);
获取方法是:value:get(key);
包含的方法:containsKey(key) containsValue(value)
其它常用方法参见:http://www.cnblogs.com/lwlxqlccc/p/6143887.html
注意:
若使用如下的多态的形式定义容器,请注意是否合理:

此例多态中c不能使用ArrayList的新增方法,也即是:多态不能使用新增方法!
三、遍历集合
ArrayList——主要存在2种方式,foreach(与普通for类似);iterator迭代器遍历


public static void main(String[] args) { List<String> list = new ArrayList<>();//JDK7新特性 list.add("aa"); list.add("bb"); list.add("cc"); //普通for循环 for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i)); } //foreach循环 for (String s : list) { System.out.println(s); } //迭代器遍历 Iterator<String> iterator = list.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } }
//类似 Map<String, String> map = new HashMap<>();的泛型省略写法是7之后的新特性
Java中的迭代器 iterator:对 collection 进行迭代的迭代器。
通过集合的 .iterator()方法获取到迭代器后便可以进行迭代的操作,如果有删除的操作,请使用 Iterator而不是foreach
迭代器的介绍,参见:http://www.cnblogs.com/xujian2014/p/5846128.html
HashSet——主要也是以上两种方式,foreach(实质与iterator有关,只是写法不同)与iterator
public static void main(String[] args) { Set<String> set = new HashSet<>(); set.add("aa"); set.add("bb"); set.add("cc"); //foreach遍历 for (String s : set) { System.out.println(s); } //迭代器遍历 Iterator<String> iterator = set.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } }
HashMap——主要存在四种遍历方式,通过keySet遍历;通过enterSet遍历;单独遍历key或者value;通过迭代器遍历entry
public static void main(String[] args) { Map<String, String> map = new HashMap<>(); map.put("k1", "v1"); map.put("k2", "v2"); System.out.println("=================keySet"); //通过keySet二次遍历 --慢且无效率 for (String key : map.keySet()) { System.out.println("key为"+key+" value为"+map.get(key)); } System.out.println("=================entrySet"); //最常见的通过enterSet遍历 --推荐 for (Map.Entry<String, String> entry : map.entrySet()) { System.out.println("key为"+entry.getKey()+" value为"+entry.getValue()); } System.out.println("=================keys"); //单独遍历keys或者values(只需要其中一个的情况) for (String key : map.keySet()) { System.out.println(key); } System.out.println("=================values"); for (String value : map.values()) { System.out.println(value); } System.out.println("=================iterator"); //使用迭代器iterator,通过entrySet遍历 Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<String, String> entry = iterator.next(); System.out.println("key为"+entry.getKey()+" value为"+entry.getValue()); } }
完整介绍与相关性能分析等,参见:http://www.cnblogs.com/leskang/p/6031282.html
更新:list中存放的是对象的时候,里面真正放的是对象的引用的复制品(副本),但是这个副本也是指向这个对象的。[注意有序可重复和无序不可重复]
详细可以参见:http://m.blog.csdn.net/article/details?id=23520263
四、集合比较与排序
先简单介绍一下即将用到的compareTo()方法:
此方法接收一个同类型的参数,当调用的对象比传入的对象大时,返回正数,否则返回负数(相等返回0),一个简单的 例子如下:
@Override
public int compareTo(Object o) {
return (this.getAge() < ((Student) o).getAge() ? -1 :
(this.getAge() == ((Student) o).getAge() ? 0 : 1));
}
由于Integer与String等常用类都实现了此方法,所以我们可以很愉快的使用它们当我们需要的时候而不必处处都进行重写。
一般来说,基本类型使用> < ==等进行比较!,一般来说可以自己使用三目运算符实现,也可以使用相应包装类的比较方法(原理一样)!
关于此方法几种写法的探讨,给出网友博文参考:http://blog.csdn.net/u013591605/article/details/75267629
1.内排序——实体类实现Comparable接口
只需要集合中的实体类实现此接口重写CompareTo()方法,然后调用Collections工具类的sort方法即可
实体类:
package com.jiangbei.test.sort; /** * 学生实体类 * 作者: Administrator * 日期: 2017/9/13 **/ public class Student implements Comparable<Student>{ private Integer age; private String name; public Student() { } public Student(Integer age, String name) { this.age = age; this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } @Override public String toString() { return "Student{" + "age=" + age + ", name='" + name + '\'' + '}'; } @Override public int compareTo(Student s) { // return (this.getAge() < ((Student) o).getAge() ? -1 : // (this.getAge() == ((Student) o).getAge() ? 0 : 1)); return this.getAge().compareTo(s.getAge()); } }
测试类:
public static void main(String[] args) { Student s1 = new Student(10, "小明"); Student s2 = new Student(18, "小张"); Student s3 = new Student(15, "小红"); List<Student> list = new ArrayList<>(); list.add(s1); list.add(s2); list.add(s3); System.out.println(list); Collections.sort(list); System.out.println(list); }
2.外排序——排序的类定义Comparato
实体类还是纯洁的实体类,没有任何污染;只是在排序的地方(Collections.sort里需要传入一个Compartor)
实体类:
package com.jiangbei.test.sort; /** * 学生实体类 * 作者: Administrator * 日期: 2017/9/13 **/ public class Student{ private Integer age; private String name; public Student() { } public Student(Integer age, String name) { this.age = age; this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } @Override public String toString() { return "Student{" + "age=" + age + ", name='" + name + '\'' + '}'; } }
排序测试:
package com.jiangbei.test.sort; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.List; /** * 集合比较测试类 * 作者: Administrator * 日期: 2017/9/13 **/ public class ListSortTest{ public static void main(String[] args) { Student s1 = new Student(10, "小明"); Student s2 = new Student(18, "小张"); Student s3 = new Student(15, "小红"); List<Student> list = new ArrayList<>(); list.add(s1); list.add(s2); list.add(s3); System.out.println(list); Collections.sort(list, comparator); System.out.println(list); } // 当然可以在sort方法里通过匿名内部类的形式实现此排序 static Comparator<Student> comparator = new Comparator<Student>() { @Override public int compare(Student s1, Student s2) { return s1.getAge() > s2.getAge()? 1 : (s1.getAge() == s2.getAge()? 0 : -1); } }; }
关于Collections工具类的其它常见用法,参见:http://blog.csdn.net/wangshuang1631/article/details/53200764
五、重要概念——equals()和hashCode()
想要弄明白hashCode的作用,必须要先知道Java中的集合。
总的来说,Java中的集合(Collection)有两类,一类是List,再有一类是Set。前者集合内的元素是有序的,元素可以重复;后者元素无序,但元素不可重复。这里就引出一个问题:要想保证元素不重复,可两个元素是否重复应该依据什么来判断呢?
这就是Object.equals方法了。但是,如果每增加一个元素就检查一次,那么当元素很多时,后添加到集合中的元素比较的次数就非常多了。也就是说,如果集合中现在已经有1000个元素,那么第1001个元素加入集合时,它就要调用1000次equals方法。这显然会大大降低效率。
于是,Java采用了哈希表的原理。哈希(Hash)实际上是个人名,由于他提出一哈希算法的概念,所以就以他的名字命名了。哈希算法也称为散列算法,是将数据依特定算法直接指定到一个地址上,初学者可以简单理解,hashCode方法实际上返回的就是对象存储的物理地址(实际可能并不是)。
这样一来,当集合要添加新的元素时,先调用这个元素的hashCode方法,就一下子能定位到它应该放置的物理位置上。如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;如果这个位置上已经有元素了,就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址。所以这里存在一个冲突解决的问题。这样一来实际调用equals方法的次数就大大降低了,几乎只需要一两次。
简而言之,在集合查找时,hashcode能大大降低对象比较次数,提高查找效率!
Java对象的eqauls方法和hashCode方法是这样规定的:
1、equals相等(相同)的对象必须具有相等的哈希码(或者散列码)。
2、如果两个对象的hashCode相同,它们并不一定相同。
所以说,我们如果重写了equals方法,一定要重写hasCode,以保证上述规定的逻辑正确性。
一般而言,存进list,set中的对象类型的元素需要重写 equals、hashCode()方法才能使用去重等功能!
如何重写?
1.equals()方法是object方法,代码如下:
public boolean equals(Object obj) { return (this == obj); }
当然,实际使用中不可能使用这样的版本,这里举出一个重写的例子:
public boolean equals(Object obj) {
if(obj == null)
return false;
if(this == obj){
return true;
}
if (obj instanceof Person) {
Person other = (Person) obj;
return (p.name).equals(this.name);
}
return false;
2.hsahCode()方法,这里主要出现多的地方是集合里元素的排列问题
此方式主要返回对象的hashCode值(int类型的)
内容引用自:http://www.cnblogs.com/Qian123/p/5703507.html
对于如何实际重写两个方法,请参见:http://blog.csdn.net/zzg1229059735/article/details/51498310

 浙公网安备 33010602011771号
浙公网安备 33010602011771号