[Feature] Feature engineering
复习旧知识:
[Pandas] 03 - DataFrame【读入并处理表格】
初步瞧:列属性的大概样子
属性间:apply新添加一列
属性内:窗口数据
[Scikit-learn] 4.3 Preprocessing data【基础夯实】
单个特征:去量纲(若干方法)、规范化
特殊情况:数据量不大、异常值较多、缺失值,特征升维
去相关性:白化(降低数据的冗余性)
[Feature] Preprocessing tutorial【伟哥笔记】
网页爬虫:import urllib.request
网页解析:from bs4 import BeautifulSoup
数据处理:缺失值、加标签、去量纲
数据训练:线性回归之相关性分析
学习新知识:
Ref: Feature Preprocessing on Kaggle
好文章:特征工程
(1)使用sklearn做单机特征工程【特征预处理】
(2)使用sklearn优雅地进行数据挖掘【特征选择,pipeline工程】
(3)谁动了我的特征?——sklearn特征转换行为全记录【继续改进】
本文主要是给出一个轮廓,具体还是要实践一套代码。
下一步,可能就是学习复现一些kaggle万能的模型,如此一来就差不多了。
故事背景
一、特征的重要性
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
找到最重要的特征,找的全,找的准。
二、特征工程
数据清洗,是针对数据:
(1) 特别不对劲的数据应该直接干掉。
(2) 市场调查采样不均衡也是个问题。
之后就是“正式篇章”:预处理,主要就是对特征的操作,提高“机器学习的上限”。
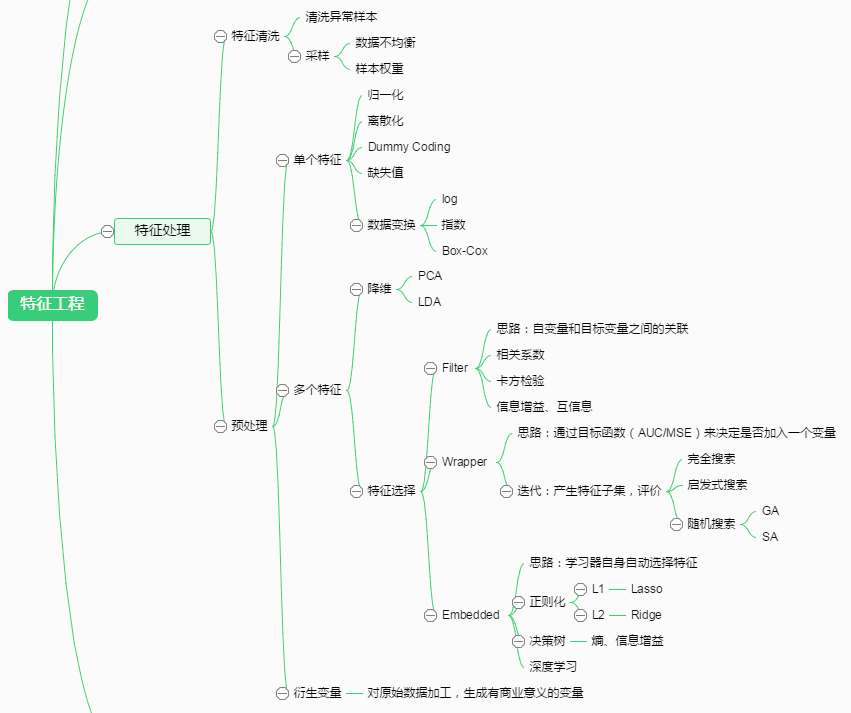
IRIS (鸢尾花) 数据集
韭言韭语谈套路
一、读取数据集
韭言韭语
(1) 数据可能非常大,故先查看下类型,以及头几行数据;
(2) 进一步地,了解总体走势。
”先头部队“ 四步走,针对数据。
二、数据预处理
韭言韭语
(*) 这部分属于”特征处理“ 部分,针对列属性 (特征)。
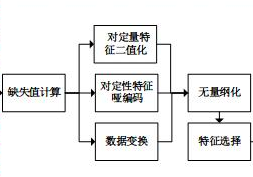
- 存在缺失值:缺失值需要补充。
- 信息冗余:(二值化,加标签) 对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心“及格”或不“及格”,那么需要将定量的考分,转换成“1”和“0”表示及格和未及格。二值化可以解决这一问题;“白化”也可以考虑。
- 定性特征不能直接使用:(哑编码) 某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。
- 最简单的方式是为每一种定性值指定一个定量值,但是这种方式过于灵活,增加了调参的工作。
- 通常使用哑编码的方式将定性特征转换为定量特征:假设有N种定性值,则将这一个特征扩展为N种特征,当原始特征值为第i种定性值时,第i个扩展特征赋值为1,其他扩展特征赋值为0。哑编码的方式相比直接指定的方式,不用增加调参的工作,对于线性模型来说,使用哑编码后的特征可达到非线性的效果。
- 信息利用率低:(数据升维,多项式变换) 不同的机器学习算法和模型对数据中信息的利用是不同的,之前提到在线性模型中,使用对定性特征哑编码可以达到非线性的效果。类似地,对定量变量多项式化,或者进行其他的转换,都能达到非线性的效果。
以上内容,集中整理在:[Feature] Preprocessing tutorial【伟哥笔记,注重实践]】
- 不属于同一量纲:即特征的规格不一样,不能够放在一起比较。无量纲化可以解决这一问题。
集中整理在: [Feature] Compare the effect of different scalers【案例模板学习】
三、特征选择
Goto: [Feature] Feature selection【详解】
3.1 Filter
3.1.1 方差选择法
3.1.2 相关系数法
3.1.3 卡方检验
3.1.4 互信息法
3.2 Wrapper
3.2.1 递归特征消除法
3.3 Embedded
3.3.1 基于惩罚项的特征选择法
3.3.2 基于树模型的特征选择法
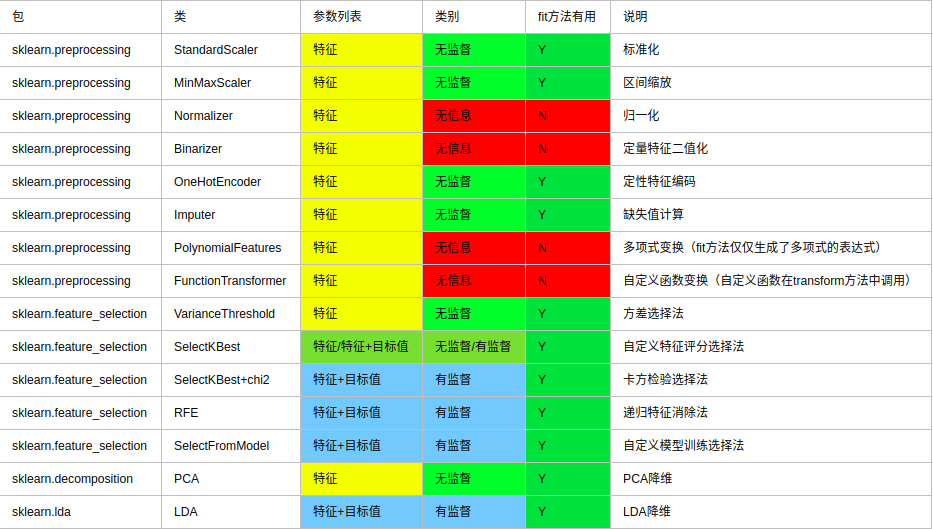
| 类 | 所属方式 | 说明 |
| VarianceThreshold | Filter | 方差选择法 |
| SelectKBest | Filter | 可选关联系数、卡方校验、最大信息系数作为得分计算的方法 |
| RFE | Wrapper | 递归地训练基模型,将权值系数较小的特征从特征集合中消除 |
| SelectFromModel | Embedded | 训练基模型,选择权值系数较高的特征 |
四、降维
4.1 主成分分析法(PCA)
4.2 线性判别分析法(LDA)
| 库 | 类 | 说明 |
| decomposition | PCA | 主成分分析法 |
| lda | LDA | 线性判别分析法 |
基本的数据挖掘场景
一、数据挖掘流程
韭言韭语
“先头部队” 四大基本操作,涉及到的库有 urllib, bs4, numpy, pandas
(1) 数据采集 data collection
网页爬虫:import urllib.request
网页解析:from bs4 import BeautifulSoup
(2) 数据分析 data previewing
数据初瞧。
(3) 数据清洗 data cleansing
去掉极端样本。
(4 )数据采样 data sampling
解决“采样不均衡”问题。
数据挖掘通常包括数据采集,数据分析,特征工程,训练模型,模型评估等步骤。
接下来便是“特征处理"的过程。
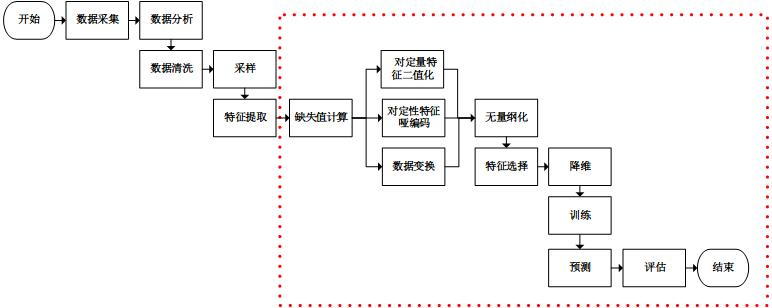
二、transform方法
“transform方法” 主要用来对特征进行转换。从可利用信息的角度来说,转换分为无信息转换和有信息转换。
-
- 无信息转换是指不利用任何其他信息进行转换,比如指数、对数函数转换等。
- 有信息转换从是否利用目标值向量又可分为无监督转换和有监督转换。
- 无监督转换指只利用特征的统计信息的转换,统计信息包括均值、标准差、边界等等,比如标准化、PCA法降维等。
- 有监督转换指既利用了特征信息又利用了目标值信息的转换,比如通过模型选择特征、LDA法降维等。
通过总结常用的转换类,我们得到下表:
优雅地进行数据挖掘
并行处理,流水线处理,自动化调参,持久化是使用sklearn优雅地进行数据挖掘的核心。
Ref: 使用sklearn优雅地进行数据挖掘【特征选择,pipeline工程】
Ref: 谁动了我的特征?——sklearn特征转换行为全记录
两篇闲散笔记,主要是能吃透这套代码,必将受益匪浅.
[Feature] Build pipeline【展示大概思路过程】
[Feature] Final exam: code analysis【代码分析,架构思路不错】
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号