[Feature] Final pipeline: custom transformers
有视频:https://www.youtube.com/watch?v=BFaadIqWlAg
有代码:https://github.com/jem1031/pandas-pipelines-custom-transformers
幼儿级模型
一、模型训练
简单的preprocessing后,仅使用一个“属性”做预测,看看结果如何?
#%% import pandas as pd import numpy as np import os from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import roc_auc_score from sklearn.pipeline import Pipeline # SET UP # Read in data # source: https://data.seattle.gov/Permitting/Special-Events-Permits/dm95-f8w5 data_folder = '../data/' data_file = 'Special_Events_Permits_2016.csv' data_file_path = os.path.join(data_folder, data_file) print("debug: data_file_path is {}".format(data_file_path)) df = pd.read_csv(data_file_path) # Set aside 25% as test data df_train, df_test = train_test_split(df, random_state=4321) # Take a look df_train.head() #%% # SIMPLE MODEL # Binarize string feature y_train = np.where(df_train.permit_status == 'Complete', 1, 0) y_test = np.where(df_test.permit_status == 'Complete', 1, 0) print(y_train[:5]) print(y_test[:5]) # Missing value,且只使用这一列做出这次模型训练的特征! X_train_1 = df_train[['attendance']].fillna(value=0) X_test_1 = df_test[['attendance']].fillna(value=0) print(X_train_1[:5]) print(X_test_1[:5]) #%% # Fit model model_1 = LogisticRegression(random_state=5678) model_1.fit(X_train_1, y_train)
二、模型评估
评估指标 ROC AUC
(1) 获得二值化的分类结果;
(2) 获得分类的概率数值。
y_pred_train_1 = model_1.predict(X_train_1) print("y_pred_train_1 is {}".format(y_pred_train_1)) p_pred_train_1 = model_1.predict_proba(X_train_1)[:, 1] print("p_pred_train_1 is {}".format(p_pred_train_1)) # Evaluate model # baseline: always predict the average p_baseline_test = [y_train.mean()]*len(y_test) auc_baseline = roc_auc_score(y_test, p_baseline_test) print(auc_baseline) # 0.5
#######################################################
y_pred_test_1 = model_1.predict(X_test_1) print("y_pred_test_1 is {}".format(y_pred_test_1)) p_pred_test_1 = model_1.predict_proba(X_test_1)[:, 1] print("p_pred_test_1 is {}".format(p_pred_test_1))
# Evaluate model auc_test_1 = roc_auc_score(y_test, p_pred_test_1) print(auc_test_1) # 0.576553672316
Ref: 机器学习评价指标 ROC与AUC 的理解和python实现
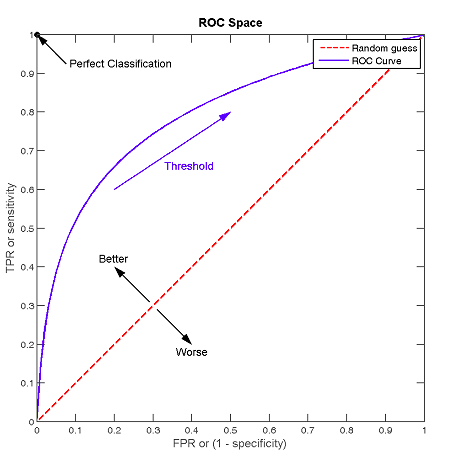
以FPR为横坐标,TPR为纵坐标,那么ROC曲线就是改变各种阈值后得到的所有坐标点 (FPR,TPR) 的连线,画出来如下。
红线是随机乱猜情况下的 ROC,曲线越靠左上角,分类器越佳。
AUC(Area Under Curve)就是ROC曲线下的面积。
既然已经这么多评价标准,为什么还要使用ROC和AUC呢?
因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。
评估指标 R2
决定系数R2 Score ,衡量模型预测能力好坏(真实和预测的 相关程度百分比)
预测数据和真实数据越接近,R2越大,当然最大值是 1;模型的R2 值为0,还不如直接用平均值(均值模型)来预测效果好。
Ref: 【从零开始学机器学习12】MSE、RMSE、R2_score
既然不同数据集的量纲不同,很难通过上面的三种方式去比较,那么不妨找一个第三者作为参照,根据参照计算 R方值,就可以比较模型的好坏了。
R2_score < 0 :分子大于分母,训练模型产生的误差比使用均值产生的还要大,也就是训练模型反而不如直接去均值效果好。出现这种情况,通常是模型本身不是线性关系的,而我们误使用了线性模型,导致误差很大。
评估指标 Residual
方差越大,模型越不稳定;


import numpy as np from sklearn.datasets import load_boston from sklearn.gaussian_process import GaussianProcessRegressor from sklearn.gaussian_process.kernels import RBF, ConstantKernel as CK from sklearn.model_selection import cross_val_predict boston = load_boston() boston_X = boston.data boston_y = boston.target train_set = np.random.choice([True, False], len(boston_y),p=[.75, .25]) # 这里获得布尔index,方便从数据集中pick up所需数据 mixed_kernel = kernel = CK(1.0, (1e-4, 1e4)) * RBF(10, (1e-4, 1e4)) gpr = GaussianProcessRegressor(alpha=5, n_restarts_optimizer=20, kernel = mixed_kernel) gpr.fit(boston_X[train_set], boston_y[train_set]) test_preds = gpr.predict(boston_X[~train_set]
from matplotlib import pyplot as plt f, ax = plt.subplots(figsize=(10, 7), nrows=3) f.tight_layout() ax[0].plot(range(len(test_preds)), test_preds, label='Predicted Values') ax[0].plot(range(len(test_preds)), boston_y[~train_set], label='Actual Values') ax[0].set_title("Predicted vs Actuals") # ax[0].legend(loc='best') # 参差图 residual residual = test_preds - boston_y[~train_set] ax[1].plot(range(len(test_preds)), residual) ax[1].set_title("Plotted Residuals") ax[2].hist(residual) ax[2].set_title("Histogram of Residuals")
Result:

模型改进
初探数据
一、数据清理时,需要考虑的内容
-
- 看看某列,瞧瞧某行【第一步】
- 可视化一列数据【第一步】
- 分组统计【第三步】
- 重采样【第三步】
Ref: [Feature] Preprocessing tutorial
-
- 特征统计分布【第一步】
- 空数据【第二步】
- 特征间线性关系【第一步】
二、空数据太多怎么办?
可以考虑放弃这个特征。
park_cts = df_train.event_location_park.value_counts(dropna=False) print(park_cts) # NaN 364 # Magnuson Park 8 # Gas Works Park 5 # Occidental Park 3 # Greenlake Park 2 # Volunteer Park 2 # Seattle Center 1 # Seward Park 1 # Anchor Park 1 # Madison Park 1 # OTHER 1 # Myrtle Edwards Park 1 # Martin Luther King Jr Memorial Park 1 # Hamilton Viewpoint Park 1 # Ballard Commons Park 1 # Lake Union Park 1 # Judkins Park 1 # Bell Street Park 1 # Comments: # - about 90% missing values # - could be new values in test data # - Note: there are 400+ parks in Seattle
三、数据太多且分散怎么办?
类似高频特征,可分组归类,resampling。
org_cts = df_train.organization.value_counts(dropna=False)
Red Carpet Valet 44 Seattle Sounders FC 19 Butler Valet 15 Seafair 9 Fuel Sports Eats and Beats 6 CBS Seattle 5 Pro-Motion Events, Inc. 5 Madison Park Business Association 4 Rejuvenation 4 Fremont Arts Council 4 The U District Partnership 4 Seattle Department of Transportation 4 University of Washington Rowing 4 Upper Left 3 Seattle Symphony 3 Argosy Cruises 3 The Corson Building 3 Waterways Cruises 3 Run for Good Racing Co./5 Focus 3 Seattle Symphony/Benaroya Hall 3 West Seattle Junction Association 3 University of Washington Husky Marching Band 3 Pro-Motion Events, Inc 2 Northwest Yacht Brokers Association 2 Seattle Yacht Club 2 Café Campagne 2 HONK! Fest West 2 Umoja Fest 2 Ethiopians in Seattle 2 Emerald City Pet Rescue 2 .. Fizz Events, LLC 1 Wing Luke Museum of the Asian Pacific American Experience 1 Independent Event Solutions 1 Vulcan Inc. 1 City of Seattle/Animal Shelter 1 GO LONG SR520 Floating Bridge Run 1 The Queen AnneCamber of Commerce 1 Greenwood Knights 1 Alki Art Fair 1 Fizz Events LLC 1 Sea Deli, Inc 1 Rotary Foundation of West Seattle 1 Seattle Buddhist Church 1 TUNE 1 AMERICAN CANCER SOCIETY, INC. 1 CWD Group, Inc. 1 Beacon Arts 1 Southwest Seattle Historical Society 1 Northwest Museum of Legends and Lore 1 magnolia chamber of commerce 1 Ram Racing 1 Seattle Events A Non-Profit Corporation 1 Sound Transit 1 Piranha Blonde Interactive 1 City of Seattle Parks and Recreation Department 1 El Centro de La Raza 1 Northwest Hope and Healing Foundation 1 Orswell Events 1 Lifelong 1 NaN 1 Name: organization, Length: 245, dtype: int64
四、极端值outlier太多怎么办?
”泰尔森估算“是其中的一个策略,但这属于ML estimator的选择范畴。
具体参见:[AI] 深度数学 - Bayes
清理数据
一、特征名字统一格式
# Switch column names to lower_case_with_underscores def standardize_name(cname): cname = re.sub(r'[-\.]', ' ', cname) cname = cname.strip().lower() cname = re.sub(r'\s+', '_', cname) return cname print(df_raw.columns) df_raw.columns = df_raw.columns.map(standardize_name) print(df_raw.columns)
Index(['Application Date', 'Permit Status', 'Permit Type', 'Event Category', 'Event Sub-Category', 'Name of Event', 'Year-Month-App.', 'Event Start Date', 'Event End Date', 'Event Location - Park', 'Event Location - Neighborhood', 'Council District', 'Precinct', 'Organization', 'Attendance'], dtype='object') Index(['application_date', 'permit_status', 'permit_type', 'event_category', 'event_sub_category', 'name_of_event', 'year_month_app', 'event_start_date', 'event_end_date', 'event_location_park', 'event_location_neighborhood', 'council_district', 'precinct', 'organization', 'attendance'], dtype='object')
二、分割数据
按照时间分割,比较常见的方式。
# Filter to 2016 events df_raw['event_start_date1'] = pd.to_datetime(df_raw.event_start_date)
df = df_raw[np.logical_and(df_raw.event_start_date1 >= '2016-01-01', df_raw.event_start_date1 <= '2016-12-31')] df = df.drop('event_start_date1', axis=1) # Export data data_file = 'Special_Events_Permits_2016.csv' df.to_csv(data_folder + data_file, index=False)
特征选择
可以自己添加一些随机特征作为noise,作为特征选择的上手练习。
工作流模型
一、FeatureUnion 组织 Transform
>>> from sklearn.pipeline import FeatureUnion >>> feature_union = FeatureUnion([ ... ('fill_avg', Imputer(strategy='mean')), ... ('fill_mid', Imputer(strategy='median')), ... ('fill_freq', Imputer(strategy='most_frequent')) ... ]) >>> X_train = feature_union.fit_transform(X_train_raw) >>> X_test = feature_union.transform(X_test_raw)
二、构建自定义 Transform
一个表格中有很多特征,"定性特征" 和 "定量特征" 可以按照如下的思路分开且并行的解决。
# Preprocessing with a Pipeline pipeline = Pipeline([
('features', DFFeatureUnion([ ('categoricals', Pipeline([ ('extract', ColumnExtractor(CAT_FEATS)), ('dummy', DummyTransformer()) ])), ('numerics', Pipeline([ ('extract', ColumnExtractor(NUM_FEATS)), ('zero_fill', ZeroFillTransformer()), ('log', Log1pTransformer()) ])) ])), ('scale', DFStandardScaler()) ])
固定的套路是:继承TransformerMixin后,实现 fit 和 tranform 方法。
class DummyTransformer(TransformerMixin): def __init__(self): self.dv = None def fit(self, X, y=None): # assumes all columns of X are strings Xdict = X.to_dict('records') self.dv = DictVectorizer(sparse=False) self.dv.fit(Xdict) return self def transform(self, X): # assumes X is a DataFrame Xdict = X.to_dict('records') Xt = self.dv.transform(Xdict) cols = self.dv.get_feature_names() Xdum = pd.DataFrame(Xt, index=X.index, columns=cols) # drop column indicating NaNs nan_cols = [c for c in cols if '=' not in c] Xdum = Xdum.drop(nan_cols, axis=1) return Xdum
知识点
处理 "定性特征" 的套路。
Ref: pandas.DataFrame.to_dict()的使用详解
Ref: 特征提升之特征抽取----DictVectorizer
三、特征联合 Feature Union
因为默认是用numpy作为参数格式,但这里都是dataframe结构,稍微自定义下即可。
class DFFeatureUnion(TransformerMixin): # FeatureUnion but for pandas DataFrames def __init__(self, transformer_list): self.transformer_list = transformer_list def fit(self, X, y=None):
# 执行完,却不需要结果 for (_, t) in self.transformer_list: t.fit(X, y) return self def transform(self, X): # 执行完,需要结果;因为结果还要被用来做reduce操作 Xts = [t.transform(X) for _, t in self.transformer_list] Xunion = reduce(lambda X1, X2: pd.merge(X1, X2, left_index=True, right_index=True), Xts) return Xunion
四、训练模型并测试
可见,测试结果好了一些。
pipeline.fit(df_train) X_train_2 = pipeline.transform(df_train) X_test_2 = pipeline.transform(df_test) # Fit model model_2 = LogisticRegression(random_state=5678) model_2.fit(X_train_2, y_train) y_pred_train_2 = model_2.predict(X_train_2) p_pred_train_2 = model_2.predict_proba(X_train_2)[:, 1] # Evaluate model p_pred_test_2 = model_2.predict_proba(X_test_2)[:, 1] auc_test_2 = roc_auc_score(y_test, p_pred_test_2) print(auc_test_2) # 0.70508474576
过拟合
更多的特征导致过拟合,如下,反而性能下降了。
# Preprocessing with a Pipeline pipeline3 = Pipeline([ ('features', DFFeatureUnion([ ('dates', Pipeline([ ('extract', ColumnExtractor(DATE_FEATS)), # 考虑日期相关特征 ('to_date', DateFormatter()), ('diffs', DateDiffer()), ('mid_fill', DFImputer(strategy='median')) ])), ('categoricals', Pipeline([ ('extract', ColumnExtractor(CAT_FEATS)), ('dummy', DummyTransformer()) ])), ('multi_labels', Pipeline([ ('extract', ColumnExtractor(MULTI_FEATS)), ('multi_dummy', MultiEncoder(sep=';')) ])), ('numerics', Pipeline([ ('extract', ColumnExtractor(NUM_FEATS)), ('zero_fill', ZeroFillTransformer()), ('log', Log1pTransformer()) ])) ])), ('scale', DFStandardScaler()) ])
pipeline3.fit(df_train) X_train_3 = pipeline3.transform(df_train) X_test_3 = pipeline3.transform(df_test) # Fit model model_3 = LogisticRegression(random_state=5678) model_3.fit(X_train_3, y_train) y_pred_train_3 = model_3.predict(X_train_3) p_pred_train_3 = model_3.predict_proba(X_train_3)[:, 1] # Evaluate model p_pred_test_3 = model_3.predict_proba(X_test_3)[:, 1] auc_test_3 = roc_auc_score(y_test, p_pred_test_3) print(auc_test_3) # 0.680790960452 # too many features -> starting to overfit
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号