

SQL Server ->> 校检函数CHECKSUM、CHECKSUM_AGG、BINARY_CHECKSUM和HASHBYTES
今天特地查了一下SQL Server下的校检函数有哪些。原本我只是在工作中用过一个CHECKSUM,今天特地学习了一下才发现原来还有其他的校检函数。
这里找到了别人对于SQL SERVER下这几个校检函数的学习总结,借此机会学习下别人的学习成果
http://bbs.51cto.com/thread-1145105-1.html
CHECKSUM和BINARY_CHECKSUM
- CHECKSUM和BINARY_CHECKSUM都是可以针对表中一行的单列或者多列又或是表达式生成数据类型为INT的校检值。
- 不同的地方是BINARY_CHECKSUM是转成了二进制后生成的校检值。
- 并不是所有的数据类型都可以用到CHECKSUM或BINARY_CHECKSUM上的。BINARY_CHECKSUM 在计算中忽略具有不可比数据类型的列。 不可比数据类型包括 text、ntext、image、cursor、xml 和不可比公共语言运行库 (CLR) 用户定义的类型。
- MSDN上讲到BINARY_CHECKSUM 可用于检测表中行的更改。但是也提到BINARY_CHECKSUM(*) 将为大多数(但不是全部)行更改返回不同的值,并可用于检测大多数行修改。
- 因为校检值是一个INT,根据INT的数值分布[-2147483648,2147483647],如果某长表中的行数大于2亿估计就会出现重复的情况了。这点在以前工作中就碰到过。
- CHECKSUM和BINARY_CHECKSUM的不同是:1)CHECKSUM是不区分大小写。它认为Jerry和jerry是同样的校检值;2)如果两个表达式具有相同的类型和字节表示,那么对于 BINARY_CHECKSUM 将返回相同的值。例如,BINARY_CHECKSUM 对于“2Volvo Director 20”和“3Volvo Director 30”将会返回相同的值。这段参考了http://ultrasql.blog.51cto.com/9591438/1607407
CHECKSUM_AGG
这个是个聚合函数。返回组中各值的校验和。 将忽略 Null 值。 后面可以跟随 OVER 子句。CHECKSUM_AGG 用于检测表中的更改。如果表达式列表中的某个值发生更改,则列表的校验和通常也会更改。 但只在极少数情况下,校验和会保持不变。很多情况下这个函数应该是用来检测表的数据是否有改动或者表的某个字段的数据是否有发生改动。
HASHBYTES
HASHBYTES是一个加密算法函数,用来对数据进行加密、或校验。它会返回其在 SQL Server 中的输入的 MD2、MD4、MD5、SHA、SHA1 或 SHA2 哈希值。它可以是作为加密功能和强度上更加强大的函数。可以用MD5替换CHECKSUM或BINARY_CHECKSUM避免重复。但是性能上可能有所下降。当然了,比起SHA-256这种加密强度极强的算法,MD5还是完全能接受的。
---------------------------------------------------- Update on 11/21/2015 ---------------------------------------------------------
这些函数的一个作用就是用于数据校验。举一个非常常用的场景 -- 哈希索引。在一些数据仓库(ETL)系统或者一些做EDI的系统里面,source传一些文件给到我们,我们再对这些文件进行处理(加载)。这当中就需要队列表。每次线程扫描目录的时候要能够知道文件是已经在队列表里面,不需要再进一次队列。那么我们就必然需要对“文件完整路径”和“修改时间”建立一条索引来加快每次检索的速度。而我们都知道SQL Server对索引的长度是有限制,最长不得超过16个字段或者900个字节长度(详细参考MSDN的文章)。像“文件完整路径”这种值肯定存在超过900个字节长度的可能性。解决办法就是对“文件完整路径”和“修改时间”建立一条哈希索引,因为哈希索引的长度即便是最长是SHA-256也不过64个字节,相比普通索引还是小得多的。需要说明,长度越长的哈希索引在加密过程所需要消耗的CPU越多,但是它会产生的哈希值冲突的可能性就越低。这个需要你根据对表具体的数据行增长和作为索引字段的个数的情况而选择合适的检验函数。
但是有一点还是需要肯定的是,像上面这样的例子尽量是不要选择CHECKSUM,原因是CHECKSUM返回的是一个INT类型的值。我们都知道INT支持的最大值不过是2亿多。这里做一个测试,在10万行的时候其实已经出现了哈希值冲突的情况了。这种情况选择MD5或者SHA-128/SHA-256。
USE [JerryDB] GO IF OBJECT_ID('dbo.ChecksumCollision') IS NOT NULL DROP TABLE dbo.ChecksumCollision GO CREATE TABLE dbo.ChecksumCollision(col1 NVARCHAR(4000), checksum_col AS CHECKSUM(col1)) GO INSERT dbo.ChecksumCollision(col1) SELECT CAST(CHECKSUM(NEWID()) AS VARCHAR(100)) FROM [dbo].[Numbers] WHERE [Num] <= 100000 select * from ( select col1, checksum_col, count(checksum_col) over (partition by checksum_col) as cnt from dbo.ChecksumCollision) t where cnt > 1 order by checksum_col
上面代码的运行结果

下面测试测试一下用HASHBYTES('MD5',XXX)的情况,
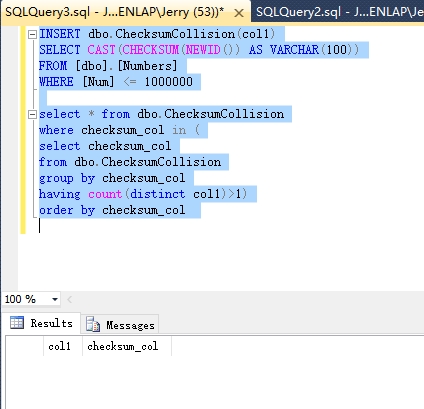
USE [JerryDB] GO IF OBJECT_ID('dbo.ChecksumCollision') IS NOT NULL DROP TABLE dbo.ChecksumCollision GO CREATE TABLE dbo.ChecksumCollision(col1 NVARCHAR(4000), checksum_col AS HASHBYTES('MD5',col1)) GO INSERT dbo.ChecksumCollision(col1) SELECT CAST(CHECKSUM(NEWID()) AS VARCHAR(100)) FROM [dbo].[Numbers] WHERE [Num] <= 1000000 select * from dbo.ChecksumCollision where checksum_col in ( select checksum_col from dbo.ChecksumCollision group by checksum_col having count(distinct col1)>1) order by checksum_col
上代码返回的结果
接下来来实现上面说的那个检查文件队列的例子
接下来我们建立一条索引
create index ix_ChecksumCollision_checksum_col on dbo.ChecksumCollision(checksum_col);
然后找一行来测试

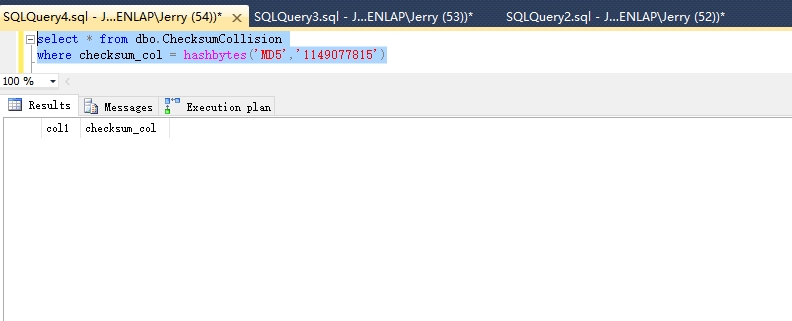
然后试下运行下面的代码利用哈希索引找到改行
select * from dbo.ChecksumCollision where checksum_col = hashbytes('MD5',N'1149077815')
结果

观察执行计划,确定上面建的哈希索引是被使用到的

有1点需要说明的是:
不管是MD5或者SHA都是依赖数据类型来产生哈希值的,这就意味着N'Jerry'和'Jerry'产生的哈希值其实是一同的。像上面的查询语句如果改成这样则不会返回任何结果
关于性能,参考中的第三个链接有人对这些函数都做了性能比较。应该说SHA-512是最慢这点没错,毕竟用了整整64个字节来产生校检值。MD5倒是稍稍比CHECKSUM慢上一点而已。
---------------------------------------------------- Update on 21/02/2022 ---------------------------------------------------------
今年前在写关于数据校验函数的时候,HASHBYTES主要是用于替代老旧的CHECKSUM函数,另外就是HASHBYTES可以作为哈希索引起到优化查询的作用。这里讲下过去几年工作中实际使用到的案例。
一个是去年优化ETL的案例上面。原来ETL每天有一个存储过程对表进行增量同步(ODS层),而同步完之后需要对另外一张10亿行数据的表进行更新,关联条件竟然是5-6个字段关联(其中还有2-3个是字符型字段)。虽然原来的开发工程师对这些字段创建了索引,但是我经过调用DMV(sys.dm_db_index_usage_stats)看到这条索引并没有在执行计划中被SQL SERVER用到,也就是索引建了没用。本质上很容易理解,关联条件的5-6个字段占据了行大小的40%宽度,以10亿行数据算,SQL SERVER选择执行计划的时候基于成本考虑不使用非聚集索引,而选择聚集索引扫描,然后对两张表进行哈希关联。这过程中除了最大的成本是这10亿行数据的聚集索引外,哈希索引所需要的CPU计算资源,以及最大影响的,就是内存容量肯定不足以容纳整个聚集索引所需的哈希计算,肯定会把这张10亿行的表拆分成多个哈希桶,而且还没说到哈希计算中所需要的TEMPDB空间占用。这也就可以理解为什么每次跑到这段代码的时候,需要2小时才能跑完这段更新语句,从每次收集到会话执行监控结果看,每次基本都是卡在这个地方,并发查询都是等待其他并发线程返回结果,而并发线程在等待系统分配内存资源。但是经过我分析,关联的另外一张表每天的数据量其实只有20万不到,最多的时候也不过80万。
我的优化思路就是:
1、对表增加一个叫HASHCOL_FORINDEX的计算字段(如下面代码),把参与关联的表字段都用分隔符拼接在一起,然后传给HASHBYTES函数
2、对HASHCOL_FORINDEX字段创建索引
3、ETL代码中的AB两张表的关联条件,修改成增量数据的小表的关联字段也用同样的计算公式转成HASHBYTES二进制值再和大表进行关联,这样子就可以很好的利用到哈希索引优化执行效率
DECLARE @delimiter AS NVARCHAR(50) = '|~|' ALTER TABLE dbo.TEST_HASHBYTES ADD HASHCOL_FORINDEX AS HASHBYTES('SHA2_512',ISNULL(COL1,'')+@delimiter+ISNULL(FORMAT(COL2,'yyyyMMdd'),'')+@delimiter+ISNULL(CAST(COL3 AS NVARCHAR(50)),'')) PERSISTED
但是这样子会报错,因为如果要持久化计算字段,必须要求字段不能包含不确定性。原因是FORMAT函数被认定为不确定性。这里要把FORMAT替换成CONVERT(NVARCHAR(50),COL2,121)这样子才可以。

那把PERSISTED去掉,不持久化也不行,因为不持久化意味着数据没有固话到磁盘,只有查询的时候才实时计算数值,你创建索引也是要失败的。

虽然可以直接就是把哈希字段创建成固化PERSISTED,但是不建议这样子,因为原来表里面有10亿行数据,一旦指定PERSISTED就意味ALTER TABLE ADD COLUMN预计直接对全表数据进行字段值初始化,整张表直接锁死,很可能整个库甚至实例都会崩溃。对于哪些小的表(几百万几千万,库比较空闲的时候可以),对于大表添加哈希索引字段是可能直接加PERSISTED的。
PS. 加PERSISTED只是把计算交给SQL SERVER自动计算,优点是省力,也不会因为代码原因导致字段值有错误。但是不可控。用代码实现的优点是可控。
所以要换个思路,先ALTER TABLE XXX ADD HASHCOL_FORINDEX VARBINARY(100)添加字段, 把使用HASHBYTES函数计算哈希值的这段计算规则放到存储过程代码里面,像正常数据插入一样在更新源表数据的时候把HASH值更其他ETL字段一起写入到表中。这里要注意这张表是10亿行的表,所以对老数据要事先更新,可以这样子。
1、如果表的聚集索引是一个自增列主键,那就以10-100万每个数值段对表里面的数据进行计算初始化表里面的数据(测试得出执行时间,再拿定具体的数据区块大小)。
2、最后再把初始化中间增量的那部分数据单独拎出来再更新一遍(俗称tailing data update,尾部数据更新)
对超大表进行数据更新要考虑的几个因素:
1、越大的表在初始化之前要先算好增加的数据是否会导致磁盘分区空间满的风险
2、表中的非聚集索引数量也是影响执行时间长短的因素之一
3、HASHBYTES和数据压缩都是非常消耗CPU的,避免在ETL繁忙的时间段去执行初始化,可以有意去避开,CPU相对空闲些的时间去执行
4、TEMPDB空间大小,不过这点不是很重要,虽然我们也预估不到会占用多少TEMPDB,但是从实际经验看不会有什么影响,比较我们都通过聚集索引分成多个批次来执行了
在实际的案例中,原来没有创建哈希索引的时候,存储过程光执行表更新的这段UPDATE语句就需要执行2小时,而创建了哈希索引后CPU增长比较明显,但是执行时间缩短到只有30分钟。
另外一个案例不算ETL,但是也是数据同步。要把某个表的数据同步到另外一个库里面,其实和上面的例子是一样的背景原因造成的,就是MERGE的时候由于需要多个字段同时关联,为了提高效率而选择用HASHBYTES哈希索引。
所以由此可见,HASHBYTES的实际应用场景里面,索引优化还是很有用的,对于数据同步\ETL更新的时候,多字段关联情况下,非常实用。
其次,由于其本身哈希值计算的特点,可以用来做密码这样的敏感数据存储。哈希值无法被反向转换成原始值。
参考:
http://www.brentozar.com/archive/2013/05/indexing-wide-keys-in-sql-server/
https://technet.microsoft.com/zh-cn/library/ms174415(v=sql.105).aspx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号