自然语言处理系列-4条件随机场(CRF)及其tensorflow实现
前些天与一位NLP大牛交流,请教其如何提升技术水平,其跟我讲务必要重视“NLP的最基本知识”的掌握。掌握好最基本的模型理论,不管是对日常工作和后续论文的发表都有重要的意义。小Dream听了不禁心里一颤,那些自认为放在“历史尘埃”里的机器学习算法我都只有了解了一个大概,至于NLP早期的那些大作也鲜有拜读。心下便决定要好好补一补这个空缺。所以,接下来的数篇文章会相继介绍在NLP中应用比较多的一些机器学习模型,隐马尔科夫模型(HMM),条件随机场(CRF),朴素贝叶斯,支持向量机(SVM),EM算法等相继都会聊到,感兴趣的朋友可以订阅我的博客,或者关注我的微信公众号,会定期更新NLP相关的文章。
好了,废话不多说,这篇博客先好好聊聊条件随机场。
1.条件随机场是什么?
条件随机场(Conditional Random Field,简称CRF),是一种判别式无向图模型。机器学习最重要的任务,是根据一些已观察到的证据(例如训练样本)来对感兴趣的未知变量(例如类别标记)进行估计和推测。概率模型提供这样一种描述的框架,将学习任务归结于计算变量的概率分布。在概率模型中,利用已知变量推测未知变量的分布称为“推断”,其核心是如何基于可观测变量推测出未知变量的条件分布。具体来说,假定所关心的变量集合为Y,可观测变量集合为X,“生成式”模型直接通过训练样本基本联合概率分布P(Y,X);“判别式”模型计算条件分布P(Y|X)[1]。
通俗来讲,CRF是在给定一组变量的情况下,求解另一组变量的条件概率的模型。设X与Y是随机变量,P(Y|X)是给定随机变量X情况下,随机变量Y的条件概率。若随机变量Y构成一个无向图G(V,E)(概率图模型,请看李航,《统计学习方法》chapter10),同时,CRF满足如下的条件,

其中,v表示G中的任一节点,v~V。n(v)表示与v有边连接的节点的集合。
在更多的情况下,应用的都是线性链条件随机场,线性链条件随机场这样定义:
设X={X1,X2,X3,....Xn},Y={Y1,Y2,Y3,....Yn}均为线性链表示的随机变量序列,若在给定随机变量序列X的情况下,随机变量序列Y的条件概率P(Y|X)构成条件随机场,其满足如下的条件:

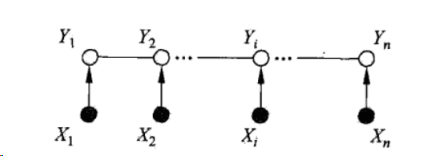
X和Y具有相同图结构的线性链条件随机场
从上面的定义可以看出,条件随机场很适合用于解决序列标注问题问题。例如在分词问题中,X可以作为输入的句子,Y是分词的标注结果。
上面应该大致讲了条件随机场是个什么样的东西,有什么样的性质。可能到目前为止,同志们应该还是有点云里雾里。反正我在第一次看到这个定义的时候,能够理解上述定义,但是总感觉不通透。后来知道,是没有跟实际结合起来,所以理解不到位。但是在将实际应用之前,还有一个东西需要介绍,就是条件随机场的参数化形式。
2.条件随机场的参数化形式
我们先列出来CRF的参数化形式吧。假设P(Y|X)是随机序列Y在给定随机序列X情况下的条件随机场,则在随机变量X取值为x的情况下,随机变量Y的取值y具有如下关系:
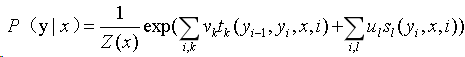
其中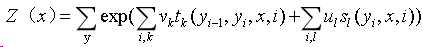
tk和Sl是特征函数,vk和ul是对应的权值。
好的,假如我们所有的tk,sl 和vk,ul都已知的情况下,我们要算的P(Yi =yi|X)是不是就可以算出来啦?已知的有所谓的前向-后向算法。在给定随机序列X的情况下,计算概率最大Y序列可以用维特比算法,感兴趣的同学可以看李航,《统计学习方法》chapter11,我这里就不再赘述了。
网上绝大部分的博客到这里就结束了,但是大家应该还有一大堆的疑问,tk,sl 和vk,ul如何确定和学习?在实际中我们如何使用?小Dream如果只讲到这里,就会太让大家失望了。下面我们看看在tensorflow里,CRF是怎么实现的,以及我们如何使用他,经过这一段,大家对条件随机场应该就会有一个较为完整的认识了。
3.tensorflow里的条件随机场
因为小Dream之前做过一个用LSTM+CRF的命名实体识别项目,这一节我们以命名实体识别为例,来介绍在tensorflow里如何使用条件随机场(CRF)。命名实体识别与分词一样,是一个序列标注的问题,因为篇幅问题,这里就不展开,不清楚的同学可以出门百度一下,以后我们再找机会,好好讲一下命名实体识别的项目。
LSTM+CRF网络的主要结构如下:
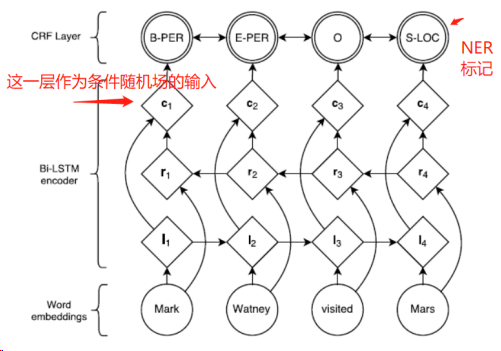
其他的我们先不看,我们只用知道,自然语言的句子经过神经网络进行特征提取之后,会得到一个特征输出,将这个特征和相应的标记(label)输入到条件随机场中,就可以计算损失了。我们来看看具体的代码。
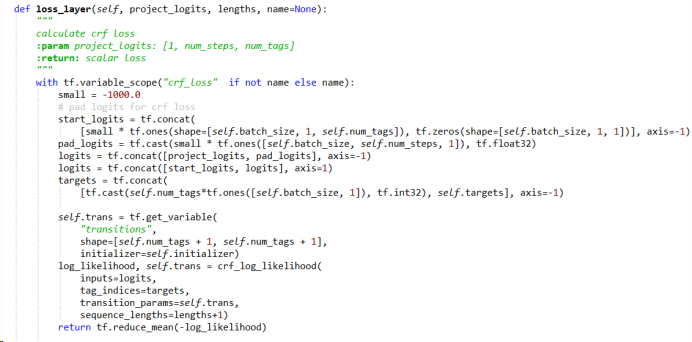
这是我定义的损失层,project_logits是神经网络最后一层的输出,该矩阵的shape为[batch_size, num_steps, num_tags], 第一个是batch size,第二个是输入的句子的长度,第三个标记的个数,即命名实体识别总标记的类别数。targets是输入句子的label,即每个字的label,它的维度为[batch_size, num_steps]。损失层定义了一个self.trans矩阵,大小是[num_tags+1, num_tags+1], 加1是因为还有一个类别是未定义。
将project_logit,targets以及self.trans交给tensorflow的系统函数crf_log_likelihood即可求得损失了。
下面我们进一步来看看crf_log_likelihood是怎么实现的。
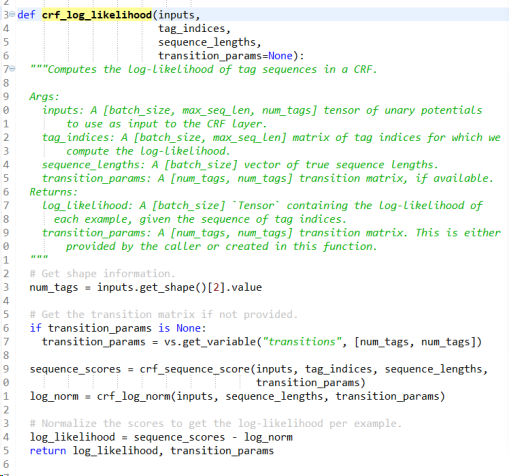
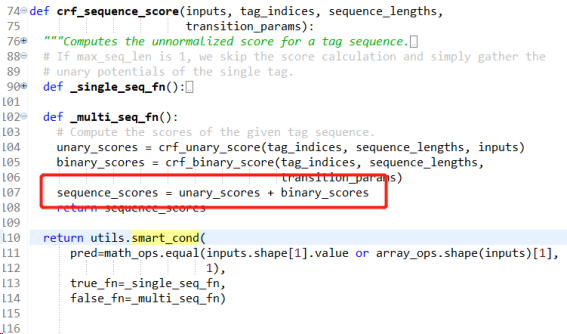
从crf_sequence_score函数的实现中,我们看出,tf中的损失值包括一元损失和二元损失。其中unary_scores表示的是标记是输入序列之间的损失,unary_scores表示的转化矩阵的损失值。那这两项到底是什么呢?是不是和CRF的参数化形式感觉有点像?我们看看相关论文[3]是怎么说的。

我们看一下,得分分为两项,第一项,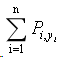
它表示输入句子中,第i个词,相应标记位置的概率。举个例子,加入输入的句子是“Mark Watney visit Mars”, 相应的label是[B-PER,E-PER,O,S-LOC],则P1,“B-PER”表示的是第一个词的标记是B-PER的概率。所以第一项会是(P1,“B-PER”) + (P2,“E-PER”) +( P3,“O”) + (P4,“S-LOC”),具体在代码中,就会取到project_logits矩阵中相应的值,这一点交叉熵有点像,同学们体会一下。第二项,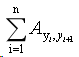
它代表的是真个序列从一个标记转化到下一个标记的损失值,这个矩阵就是self.trans,它最开始是按照我们初始化的方式初始化的,然后会随着训练的过程优化。最后再对整个序列的损失值做一个归一化,也就是执行crf_log_norm函数。好了,tensorflow中crf就是这么实现的,是不是有种豁然开朗的感觉??
我们来做一个总结,CRF是一个在给定某一个随机序列的情况下,求另一个随机序列的概率分布的概率图模型,在序列标注的问题中有广泛的应用。在tensorflow中,实现了crf_log_likelihood函数。在本文讲的命名实体识别项目中,自然语言经是已知的序列,自然语言经过特征提取过后的logits被当作是tk函数,随机初始化的self.trans矩阵是Sl函数,随着训练的过程不断的优化。
这就是条件随机场要讲的全部内容啦,欢迎各位评论。后续更新HMM,SVM等,感兴趣的朋友可以关注我的博客或者公众号。
[1] 周志华. 机器学习. 清华大学出版社
[2] 李航 统计学习方法.清华大学出版社
[3]Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[J]. arXiv preprint arXiv:1603.01360, 2016.
如引用,请务必注明出处!https://www.cnblogs.com/jen104/p/10549690.html
分享时刻:
常常再想,人生大抵苦多乐少。每个人都有太多不想做却又不得不去做的事。那么,何不在心中忘苦常乐,就算人生命有定数,也要活的自在。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号