

OpenCV入门之获取验证码的单个字符(二)
在文章 OpenCV入门之获取验证码的单个字符(字符切割)中,介绍了一类验证码的处理方法,该验证码如下:
该验证码的特点是字母之间的间隔较大,很容易就能提取出其中的单个字符。接下来,笔者将会介绍如何在另一种验证码中提取单个字符的方法。
测试的验证码来源于某个账号注册的网站,如下:

笔者一共收集了346张验证码。我们可以看到,这些验证码的特点是:噪声较大,有些验证码之间的字母黏连在一起,这样的话,想要提取单个字符的难度会加大。
首先,我们按照文章 OpenCV入门之获取验证码的单个字符(字符切割)的处理方式来提取单个字符,看看效果,完整的Python
代码如下:

import os
import uuid
import cv2
def split_picture(imagepath):
# 以灰度模式读取图片
gray = cv2.imread(imagepath, 0)
# 将图片的边缘变为白色
height, width = gray.shape
for i in range(width):
gray[0, i] = 255
gray[height-1, i] = 255
for j in range(height):
gray[j, 0] = 255
gray[j, width-1] = 255
# 中值滤波
blur = cv2.medianBlur(gray, 3) #模板大小3*3
# 二值化
ret,thresh1 = cv2.threshold(blur, 200, 255, cv2.THRESH_BINARY)
# 提取单个字符
image, contours, hierarchy = cv2.findContours(thresh1, 2, 2)
for cnt in contours:
# 最小的外接矩形
x, y, w, h = cv2.boundingRect(cnt)
if x != 0 and y != 0 and w*h >= 100:
print((x,y,w,h))
# 显示图片
cv2.imwrite('E://chars/%s.jpg'%(uuid.uuid1()), thresh1[y:y+h, x:x+w])
def main():
dir = "E://verifycode"
for file in os.listdir(dir):
imagepath = dir+'/'+file
split_picture(imagepath)
main()
得到的单个字符的效果如下:
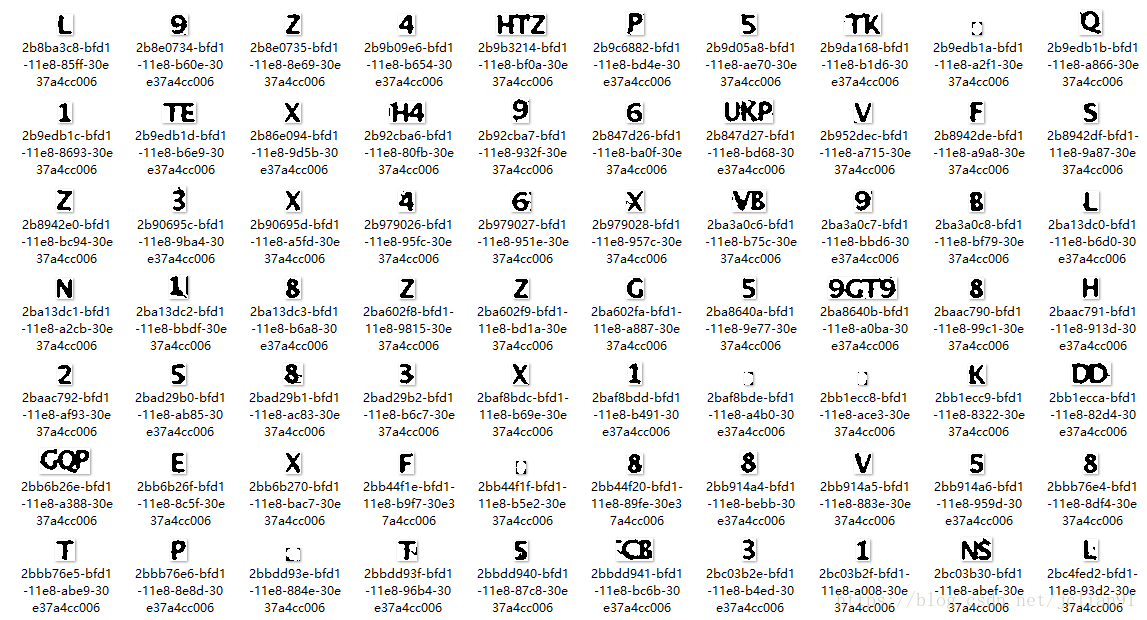
可以看到,虽然我们也能得到单个的字符,但是也产生了很多噪声图片以及黏连在一起的字符图片(以下简称黏连图片)。因此,下一步的工作是如何处理噪声图片和黏连图片。
首先我们介绍如何去掉噪声图片。观察以上的噪声图片,即中间有大片空白,角落里有部分黑色的图片,如下:

笔者选择的处理方式如下:在该图片的四个角落的像素点取值,一共是四个值,如果黑色像素的点大于等于3个,则被认为是噪声图片。处理的Python函数如下:
def remove_edge_picture(imagepath):
image = cv2.imread(imagepath, 0)
height, width = image.shape
corner_list = [image[0,0] < 127,
image[height-1, 0] < 127,
image[0, width-1]<127,
image[ height-1, width-1] < 127
]
if sum(corner_list) >= 3:
os.remove(imagepath)
接着是黏连图片的处理,所谓黏连图片,指的是提取字符的图片中含有2个及以上字符的图片,如下:
对于黏连图片,我们很容易想到的处理方式就是均分图片,图片中含有几个字符,就将图片均分成几等分。那么,怎样才能知道图片中所含字符的数量呢?笔者暂时没有完美的处理方法,能想到的就是根据图片的宽度来决定字符的个数。根据观察,4个字符的图片宽度往往大于等于64,3个字符的图片宽度往往大于等于48,两个字符的图片往往大于等于26,因此,就把这个作为图片中含有字符数量的标准。处理黏连图片的Python代码如下:

def resplit_with_parts(imagepath, parts):
image = cv2.imread(imagepath, 0)
height, width = image.shape
# 将图片重新分裂成parts部分
step = width//parts # 步长
start = 0 # 起始位置
for _ in range(parts):
cv2.imwrite('E://chars/%s.jpg'%uuid.uuid1(), image[:, start:start+step])
start += step
os.remove(imagepath)
def resplit(imagepath):
image = cv2.imread(imagepath, 0)
height, width = image.shape
if width >= 64:
resplit_with_parts(imagepath, 4)
elif width >= 48:
resplit_with_parts(imagepath, 3)
elif width >= 26:
resplit_with_parts(imagepath, 2)
好了,有了以上处理噪声图片和黏连图片的方法,我们来试试处理后的效果,显示的图片如下:
一共是346张验证码,每个验证码4个字符,一共是1384张图片。按照这样处理方法,得到1381张图片,当然,存在极少的噪声图片(1~2张)和有些为切分的图片,如上图中用红线圈出的部分。总的来说,得到的有效单个字符的图片为1371张图片,提取的效率为99%,这无疑是极好的,达到了笔者的预期效果。
下面给出以上处理的完整的Python代码:

import os
import cv2
import uuid
def remove_edge_picture(imagepath):
image = cv2.imread(imagepath, 0)
height, width = image.shape
corner_list = [image[0,0] < 127,
image[height-1, 0] < 127,
image[0, width-1]<127,
image[ height-1, width-1] < 127
]
if sum(corner_list) >= 3:
os.remove(imagepath)
def resplit_with_parts(imagepath, parts):
image = cv2.imread(imagepath, 0)
height, width = image.shape
# 将图片重新分裂成parts部分
step = width//parts # 步长
start = 0 # 起始位置
for _ in range(parts):
cv2.imwrite('E://chars/%s.jpg'%uuid.uuid1(), image[:, start:start+step])
start += step
os.remove(imagepath)
def resplit(imagepath):
image = cv2.imread(imagepath, 0)
height, width = image.shape
if width >= 64:
resplit_with_parts(imagepath, 4)
elif width >= 48:
resplit_with_parts(imagepath, 3)
elif width >= 26:
resplit_with_parts(imagepath, 2)
def main():
dir = 'E://chars'
for file in os.listdir(dir):
remove_edge_picture(imagepath=dir+'/'+file)
for file in os.listdir(dir):
resplit(imagepath=dir+'/'+file)
main()
今日中秋,祝大家中秋节快乐~
注意:本人现已开通两个微信公众号: 轻松学会Python爬虫(微信号为:easy_web_scrape), 欢迎大家关注哦~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号