Java 基础【17】 异常与自定义异常
1.异常的分类
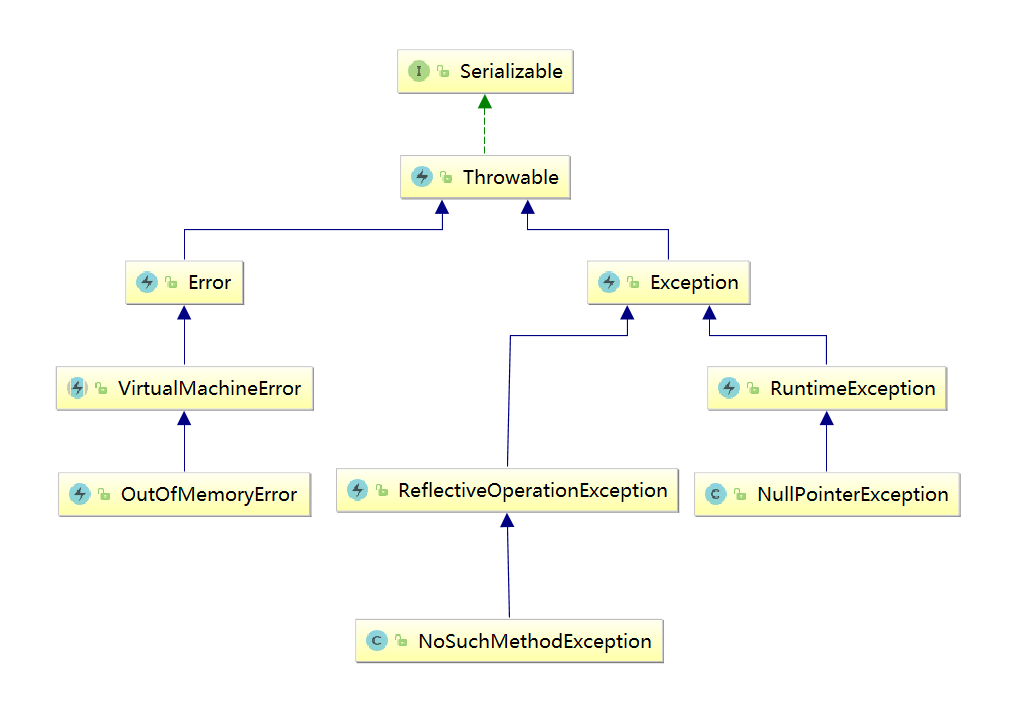
Throwable 是所有异常类的基类,它包括两个子类:Exception 和 Error。
a. 错误 (Error)
错误是无法难通过程序来解决的,所以程序不应该抛出这种类型的对象。
如果出现了这样的内部错误,除了通知给用户,并尽力使程序安全地终止。当然这类情况是很少出现的(上图 OutOfMemoryError)。
a.非运行时异常(UnChecked Exception)
Java 中凡是继承自 Exception 但不是继承自 RuntimeException 的类都是非运行时异常(上图 NoSuchMethodException)。
UnChecked 与 Check 指编译器是否进行检查,是否提示强制 try catch。
b.运行时异常(Runtime Exception)
RuntimeException 类直接继承自 Exception 类,称为运行时异常。
Java 中所有的运行时异常都直接或间接的继承自 RuntimeException (上图 NullPointerException)。
2.异常的处理
a.对应非运行时异常,必须对其进行处理。处理方式有两种:
- 使用 try…catch…finally 语句块进行捕获
- 在产生异常的方法所在的方法声明 throws Exception
b.对于运行时异常,可以不对其进行处理,也可以对其进行处理。一般情况下都不对其进行处理。
在使用Java API的方法时会产生异常,由于实际的需要,我们需要创建和使用自定义异常。使用全新的异常类,应用到系统程序中。
3.自定义异常
在介绍自定义异常时,首要先谈谈什么要使用自定义异常,使用自定义异常的好处。
创建自定义异常是为了表示应用程序的一些错误类型,为代码可能发生的一个或多个问题提供新的含义;
可以显示代码多个位置之间的错误的相似处,也可区分代码运行时可能出现的相似问题的一个或多个错误,或给出应用程序中一组错误的特殊含义。
服务器的基本作用是处理与客户机的通信,若使用标准Java API 使编写的代码在多个位置抛出 IOException。
在设置服务器、等待客户机连接和获取通讯流时,可抛出 IOException。
在通信期间及试图断开连接时,也会抛出IOException。
简而言之,服务器的各个部分都是引发 IOException,但对于服务器而言,这样 IOException 意义不尽相同。
虽然由同一异常类型表示,但与各个异常先关的业务含义存在差异,报告和恢复操作也不相同。
所以,可以将一个异常与服务器配置、启动问题关联,将另一个异常与客户机通讯的实际行动关联,将第三个异常与服务器关闭任务关联等。
为此,我们需要使用自定义异常来定为问题,定位问题与异常实际准确的位置。
自定义异常类可以继承 Throwable 类或者 Exception 类,自定义异常类之间也可以有继承关系。
需要为自定义异常类设计构造方法,以方便构造自定义异常对象。
在继承任何异常时,将自动继承 Throwable 类的一些标准特性,如:错误消息/栈跟踪/ 异常包装....
若要在异常中添加附加信息,则可以为类添加一些变量和方法。
a.首先继承异常类 Exception
本例演示的自定义异常没有按照业务类型来命名,而是创建一个通用异常类。
以 retCd 来区别发生异常的业务类型与发生位置,当然对于具体的 retCd 值,事先必须有具体的规定或说明。
/** * 多数情况下,创建自定义异常需要继承Exception,本例继承Exception的子类RuntimeException */ public class CustomerException extends RuntimeException { private String retCd; //异常对应的返回码 private String msgDes; //异常对应的描述信息 public CustomerException() { super(); } public CustomerException(String message) { super(message); msgDes = message; } public CustomerException(String retCd, String msgDes) { super(); this.retCd = retCd; this.msgDes = msgDes; } public String getRetCd() { return retCd; } public String getMsgDes() { return msgDes; } }
b. 其次声明方法抛出自定义异常
为了使用自定义异常,必须通知调用代码的类:要准备处理这个异常类型。
为此,声明一个或多个方法抛出异常。找到异常发生点,新建异常并加上关键字 throw。
public class TestClass { public void testException() throws CustomerException { try { //..some code that throws CustomerException } catch (Exception e) { throw new CustomerException("14000001", "String[]strs 's length < 4"); } } }
c.捕获异常之后的操作
public class TestCustomerException { public static void main(String[] args) { try { TestClass testClass = new TestClass(); testClass.testException(); } catch (CustomerException e) { e.printStackTrace(); System.out.println(e.getMsgDes()); System.out.println(e.getRetCd()); } } }
4.最佳实践
a.记得释放资源
如果你正在用数据库或网络连接的资源,要记得释放它们。
如果你使用的 API 仅仅使用 unchecked exception,你应该用完后释放它们,使用 try-final。
public void dataAccessCode() { try { Connection conn = getConnection(); //do some code that throws SQLException } catch (SQLException ex) { ex.printStacktrace(); } finally { closeConnection(conn); } } public static void closeConnection(Connection conn) { try { conn.close(); } catch (SQLException ex) { logger.error("Cannot close connection"); throw new RuntimeException(ex); } }
在这个例子中,finally 关闭了连接,如果关闭过程中有问题发生的话,会抛出一个 RuntimeException。
b.不要使用异常控制流程
生成栈回溯是非常昂贵的,栈回溯的价值是在于调试。
在流程控制中,栈回溯是应该避免的,因为客户端仅仅想知道如何继续。
下面的代码,一个自定义的异常 MaximumCountReachedException,用来控制流程。
public void useExceptionsForFlowControl() { try { while (true) { increaseCount(); } } catch (MaximumCountReachedException ex) { } //Continue execution } public void increaseCount() throws MaximumCountReachedException { if (count >= 5000) throw new MaximumCountReachedException(); }
useExceptionsForFlowControl()使用了一个无限的循环来递增计数器,直至异常被抛出。
这样写不仅降低了代码的可读性,而且代码效率低下。
c. 不要忽略异常
当一个 API 方法抛出 checked exception 时,它是要试图告诉你需要采取某些行动处理它。
如果它对你来说没什么意义,不要犹豫,直接转换成 unchecked exception 抛出,千万不要仅仅用空的 {}catch 它,然后当没事发生一样忽略它。
d. 不要 catch 最高层次的 exception
Unchecked exception 是继承自 RuntimeException 类的,而 RuntimeException 继承自 Exception。如果 catch Exception 的话,你也会 catch RuntimeException。
try{ .. }catch(Exception ex){}
上面的代码会忽略掉 unchecked exception。
e. 仅记录 exception 一次
对同一个错误的栈回溯(stack trace)记录多次的话,会让程序员搞不清楚错误的原始来源。所以仅仅记录一次就够了。
总结:这里是我总结出的一些异常处理最佳实施方法。我并不想引起关于 checked exception 和 unchecked exception 的激烈争论。
你可以根据你的需要来设计代码。我相信,随着时间的推移,你会找到些更好的异常处理的方法的。
作者:Orson
出处:http://www.cnblogs.com/java-class/
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】
如果,您对我的博客内容感兴趣,请继续关注我的后续博客,我是【Orson】
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段
声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号