浅谈 Java XML 底层解析方式
XML 使用DTD(document type definition)文档类型来标记数据和定义数据,格式统一且跨平台和语言,已成为业界公认的标准。
目前 XML 描述数据龙头老大的地位渐渐受到 Json 威胁。经手项目中,模块/系统之间交互数据方式有 XML 也有 Json,说不上孰好孰坏。
XML 规整/有业界标准/很容易和其他外部的系统进行交互,Json 简单/灵活/占带宽比小。
仁者见仁智者见智,项目推进中描述数据方式需要根据具体场景拿捏。
这篇博客主要描述目前 Java 中比较主流的 XML 解析底层方式,给需要这方面项目实践的同学一些参考。
Demo 项目 git 地址:https://git.oschina.net/LanboEx/xml-parse-demo.git
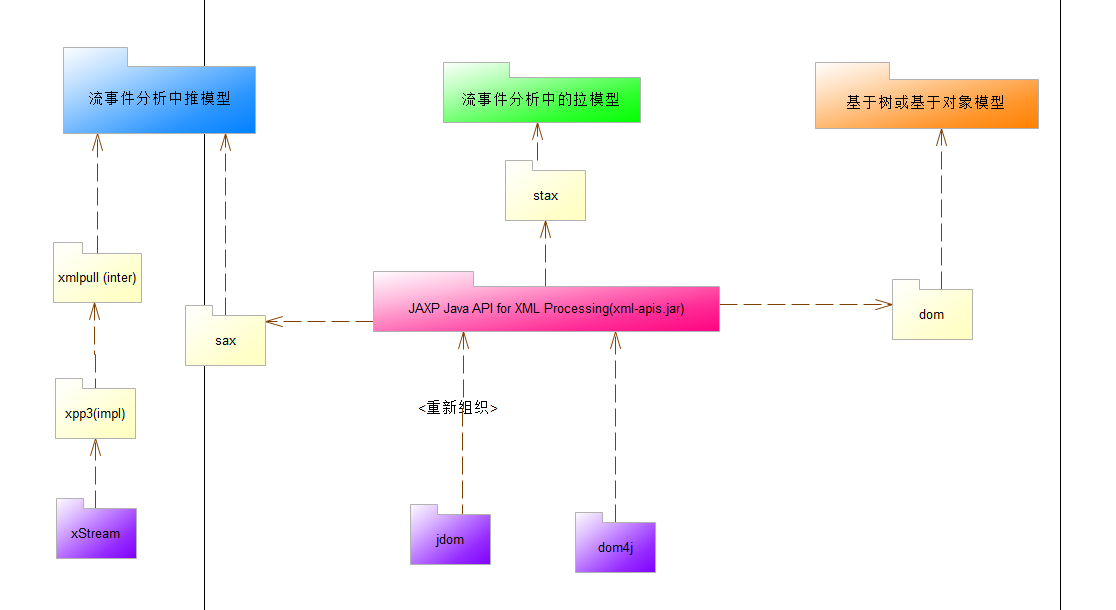
Sax/Satx/Dom 由国外开源社区或组织贡献,Sun 重新组织起名 JAXP 自JDK 1.6 起陆续将他们添加进去。
Xmlpull在 JDK 中没有看到它的身影,如果需要使用它,你需要添加额外的类库。
Jdom/Dom4j/Xstream... 是基于这些底层解析方式重新组织封装的开源类库,提供简洁的 API,有机会再写一篇博客描述。
Dom4j 是基于 JAXP 解析方式,性能优异、功能强大、极易使用的优秀开源类库。
Jdom 如果你细看内部代码,其实也是基于 JAXP 但具体包结构被重新组织, API 大量使用了 Collections 类,在性能上被 dm4j 压了好几个档次。
实例 Demo 中需要解析的 xml 文件如下,中规中矩不简单,也不复杂,示例业务场景都能将节点的值解析出来,组成业务实体对象。


<?xml version="1.0"?>
<classGrid>
<classGridlb>
<class_id>320170105000009363</class_id>
<class_number>0301</class_number>
<adviser>018574</adviser>
<studentGrid>
<studentGridlb>
<stu_id>030101</stu_id>
<stu_name>齐天</stu_name>
<stu_age>9</stu_age>
<stu_birthday>2008-11-07</stu_birthday>
</studentGridlb>
<studentGridlb>
<stu_id>030102</stu_id>
<stu_name>张惠</stu_name>
<stu_age>10</stu_age>
<stu_birthday>2009-04-08</stu_birthday>
</studentGridlb>
<studentGridlb>
<stu_id>030103</stu_id>
<stu_name>龙五</stu_name>
<stu_age>9</stu_age>
<stu_birthday>2008-11-01</stu_birthday>
</studentGridlb>
</studentGrid>
</classGridlb>
<classGridlb>
<class_id>420170105000007363</class_id>
<class_number>0302</class_number>
<adviser>018577</adviser>
<studentGrid>
<studentGridlb>
<stu_id>030201</stu_id>
<stu_name>马宝</stu_name>
<stu_age>10</stu_age>
<stu_birthday>2009-09-02</stu_birthday>
</studentGridlb>
</studentGrid>
</classGridlb>
</classGrid>
1. 基于树或基于对象模型
官方 W3C 标准,以层次结构组织的节点或信息片断的集合。允许在树中寻找特定信息,分析该结构通常需要加载整个文档和构造层次结构。
最早的一种解析模型,加载整个文档意味着在大文件 XMl 会遇到性能瓶颈。
Dom 解析代码示例:
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();//得到Dom解析器的工厂实例
DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder();//从Dom工厂中获得Dom解析器
Document doc = dbBuilder.parse(Thread.currentThread().getContextClassLoader().getResource("demo.xml").getPath());
NodeList nList = doc.getElementsByTagName("studentGridlb");
List<StudentGridlb> studentGridlbList = new ArrayList<>();
for (int i = 0; i < nList.getLength(); i++) {
StudentGridlb studentGridlb = new StudentGridlb();
NodeList childNodes = nList.item(i).getChildNodes();
for (int k = 0; k < childNodes.getLength(); k++) {
if (childNodes.item(k) instanceof Element) {
Element element = (Element) childNodes.item(k);
if ("stu_id".equals(element.getNodeName())) {
studentGridlb.setStu_id(element.getTextContent());
}
if ("stu_name".equals(element.getNodeName())) {
studentGridlb.setStu_name(element.getTextContent());
}
if ("stu_age".equals(element.getNodeName())) {
studentGridlb.setStu_age(Integer.parseInt(element.getTextContent()));
}
if ("stu_birthday".equals(element.getNodeName())) {
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
studentGridlb.setStu_birthday(format.parse(element.getTextContent()));
}
}
}
studentGridlbList.add(studentGridlb);
}
Dom 解析方式有个最大的优点可以在任何时候在树中上下导航,获取和操作任意部分的数据。
2. 流事件分析中推模型
靠事件驱动的模型,当它每发现一个节点就引发一个事件,需要编写这些事件的处理程序。
这样的做法很麻烦,而且不灵活,主流的分析方式有 Xmlpull和 JAXP 中的 Sax。
Xmlpulldemo (引入 xmlpull.jar xpp3_min.jar]):
XmlPullParserFactory pullParserFactory = XmlPullParserFactory.newInstance();
XmlPullParser pullParser = pullParserFactory.newPullParser();//获取XmlPullParser的实例
pullParser.setInput(Thread.currentThread().getContextClassLoader().getResourceAsStream("demo.xml"), "UTF-8");
int event = pullParser.getEventType();
List<StudentGridlb> studentGridlbList = new ArrayList<>();
StudentGridlb studentGridlb = new StudentGridlb();
while (event != XmlPullParser.END_DOCUMENT) {
String nodeName = pullParser.getName();
switch (event) {
case XmlPullParser.START_DOCUMENT:
System.out.println("Xmlpull解析 xml 开始:");
break;
case XmlPullParser.START_TAG:
if ("stu_id".equals(nodeName)) {
studentGridlb.setStu_id(pullParser.nextText());
}
if ("stu_name".equals(nodeName)) {
studentGridlb.setStu_name(pullParser.nextText());
}
if ("stu_age".equals(nodeName)) {
studentGridlb.setStu_age(Integer.parseInt(pullParser.nextText()));
}
if ("stu_birthday".equals(nodeName)) {
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
studentGridlb.setStu_birthday(format.parse(pullParser.nextText()));
}
break;
case XmlPullParser.END_TAG:
if ("studentGridlb".equals(nodeName)) {
studentGridlbList.add(studentGridlb);
studentGridlb = new StudentGridlb();
}
break;
}
event = pullParser.next();
}
Xmlpull为接口层,xpp3_min 为实现层,其实可以引入另外自带接口层 xpp3 版本。
<dependency>
<groupId>xmlpull</groupId>
<artifactId>xmlpull</artifactId>
<version>1.1.3.1</version>
</dependency>
<dependency>
<groupId>xpp3</groupId>
<artifactId>xpp3_min</artifactId>
<version>1.1.4c</version>
</dependency>
Sax demo:
SaxParserFactory SaxParserFactory = SaxParserFactory.newInstance(); //获取Sax分析器的工厂实例,专门负责创建SaxParser分析器
SaxParser SaxParser = SaxParserFactory.newSaxParser();
InputStream inputStream = new FileInputStream(new File(Thread.currentThread().getContextClassLoader().getResource("demo.xml").getPath()));
SaxHandler xmlSaxHandler = new SaxHandler();
SaxParser.parse(inputStream, xmlSaxHandler);
Sax 解析时还需要单独编写时间响应 Handler ,和集合排序时实现的Comparator 类似。
public class SAXHandler extends DefaultHandler {
private List<StudentGridlb> studentGridlbList = null;
private StudentGridlb studentGridlb = null;
private String tagName;
@Override
public void startDocument() throws SAXException {
System.out.println("---->startDocument() is invoked...");
studentGridlbList = new ArrayList<>();
}
@Override
public void endDocument() throws SAXException {
System.out.println("---->endDocument() is invoked...");
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println("-------->startElement() is invoked...,qName:" + qName);
if ("studentGridlb".equals(qName)) {
this.studentGridlb = new StudentGridlb();
}
this.tagName = qName;
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println("-------->endElement() is invoked...");
if (qName.equals("studentGridlb")) {
this.studentGridlbList.add(this.studentGridlb);
}
this.tagName = null;
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
System.out.println("------------>characters() is invoked...");
if (this.tagName != null) {
String contentText = new String(ch, start, length);
if (this.tagName.equals("stu_id")) {
this.studentGridlb.setStu_id(contentText);
}
if (this.tagName.equals("stu_name")) {
this.studentGridlb.setStu_name(contentText);
}
if (this.tagName.equals("stu_age")) {
this.studentGridlb.setStu_age(Integer.parseInt(contentText));
}
if (this.tagName.equals("stu_birthday")) {
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
try {
this.studentGridlb.setStu_birthday(format.parse(contentText));
} catch (ParseException e) {
e.printStackTrace();
}
}
}
}
public List<StudentGridlb> getStudentGridlbList() {
return studentGridlbList;
}
public void setStudentGridlbList(List<StudentGridlb> studentGridlbList) {
this.studentGridlbList = studentGridlbList;
}
}
推模式不需要等待所有数据都被处理,分析就能立即开始;
只在读取数据时检查数据,不需要保存在内存中;
可以在某个条件得到满足时停止解析,不必解析整个文档;
效率和性能较高,能解析大于系统内存的文档;
当然缺点也很突出例如需要自己负责TAG的处理逻辑(例如维护父/子关系等),使用麻烦;
单向导航,很难同时访问同一文档的不同部分数据,不支持 XPath;
3. 流事件分析中的拉模型
在遍历文档时,把感兴趣的部分从读取器中拉出,不需要引发事件,允许我们选择性地处理节点;
大大提高了灵活性,以及整体效率,拉模式中比较常见 stax,stax 提供了两套 API 共使用。
stax demo(基于光标的方式解析XML):
InputStream stream = new FileInputStream(Thread.currentThread().getContextClassLoader().getResource("demo.xml").getPath());
XMLInputFactory factory = XMLInputFactory.newInstance();
XMLStreamReader parser = factory.createXMLStreamReader(stream);
List<StudentGridlb> studentGridlbList = new ArrayList<>();
StudentGridlb studentGridlb = null;
while (parser.hasNext()) {
int event = parser.next();
if (event == XMLStreamConstants.START_DOCUMENT) {
System.out.println("stax 解析xml 开始.....");
}
if (event == XMLStreamConstants.START_ELEMENT) {
if (parser.getLocalName().equals("stu_id")) {
studentGridlb = new StudentGridlb();
studentGridlb.setStu_id(parser.getElementText());
} else if (parser.getLocalName().equals("stu_name")) {
studentGridlb.setStu_name(parser.getElementText());
} else if (parser.getLocalName().equals("stu_age")) {
studentGridlb.setStu_age(Integer.parseInt(parser.getElementText()));
} else if (parser.getLocalName().equals("stu_birthday")) {
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
studentGridlb.setStu_birthday(format.parse(parser.getElementText()));
}
}
if (event == XMLStreamConstants.END_ELEMENT) {
if (parser.getLocalName().equals("studentGridlb")) {
studentGridlbList.add(studentGridlb);
}
}
if (event == XMLStreamConstants.END_DOCUMENT) {
System.out.println("stax 解析xml 结束.....");
}
}
parser.close();
stax demo(基于迭代方式解析XML):
XMLInputFactory xmlInputFactory = XMLInputFactory.newInstance();
XMLEventReader xmlEventReader = xmlInputFactory.createXMLEventReader(Thread.currentThread().getContextClassLoader().getResourceAsStream("demo.xml"));
List<StudentGridlb> studentGridlbList = new ArrayList<>();
StudentGridlb studentGridlb = null;
while (xmlEventReader.hasNext()) {
XMLEvent event = xmlEventReader.nextEvent();
if (event.isStartElement()) {
String name = event.asStartElement().getName().toString();
if (name.equals("stu_id")) {
studentGridlb = new StudentGridlb();
studentGridlb.setStu_id(xmlEventReader.getElementText());
} else if (name.equals("stu_name")) {
studentGridlb.setStu_name(xmlEventReader.getElementText());
} else if (name.equals("stu_age")) {
studentGridlb.setStu_age(Integer.parseInt(xmlEventReader.getElementText()));
} else if (name.equals("stu_birthday")) {
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
studentGridlb.setStu_birthday(format.parse(xmlEventReader.getElementText()));
}
}
if (event.isEndElement()) {
String name = event.asEndElement().getName().toString();
if (name.equals("studentGridlb")) {
studentGridlbList.add(studentGridlb);
}
}
}
xmlEventReader.close();
基于指针的 stax API,这种方式尽管效率高,但没有提供 XML 结构的抽象,因此是一种低层 API。
stax 基于迭代器的 API 是一种面向对象的方式,这也是它与基于指针的 API 的最大区别。
基于迭代器的 API 只需要确定解析事件的类型,然后利用其方法获得属于该事件对象的信息。
通过将事件转变为对象,让应用程序可以用面向对象的方式处理,有利于模块化和不同组件之间的代码重用。
Ok,这篇博客对 java 底层解析 xml 方式做了点总结。其实在实际项目中,上述几种方式解析 xml 编写起来都很费事。
都会引入封装起来的稳定开源库,如 Dom4j/Jdom/Xstream.....,这些类库屏蔽了底层复杂的部分,呈现给我们简洁明了的 API;
但如果公司业务复杂程度已经远远超出了开源类库的提供的范畴,不妨自己依赖底层解析技术自己造轮子。
作者:Orson
出处:http://www.cnblogs.com/java-class/
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】
如果,您对我的博客内容感兴趣,请继续关注我的后续博客,我是【Orson】
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段
声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号