
数据库连接池之Druid源码解析
一、Druid的使用
1.1、Springboot项目集成druid
1.1.1、配置maven
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.15</version
</dependency>
1.1.2、添加数据源相关配置
1 spring: 2 datasource:
druid: 3 url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&zeroDataTimeBehavior=convertToNull&useSSL=false 4 username: root 5 password: root 6 type: com.alibaba.druid.pool.DruidDataSource 7 initialSize: 5 8 maxInactive: 10 9 minIdle: 5 10 timeBetweenEvictionRunsMillis: 5000 11 minEvictableIdleTimeMillis: 10000 12 filters: stat,wall 13 testOnBorrow: false
1.1.3、定义DruidConfig配置文件
1 package com.lucky.test.config; 2 3 import com.alibaba.druid.pool.DruidDataSource; 4 import org.springframework.boot.context.properties.ConfigurationProperties; 5 import org.springframework.context.annotation.Configuration; 6 7 import javax.sql.DataSource; 8 9 /** 10 * @Auther: Lucky 11 * @Date: 2020/12/14 下午8:16 12 * @Desc: 13 */ 14 @Configuration 15 public class DruidConfig { 16 17 @ConfigurationProperties(prefix = "spring.datasource") 18 public DataSource druidDataSource(){ 19 return new DruidDataSource(); 20 } 21 }
定义了DruidDataSource数据源的bean之后,项目中使用的就是数据源就是DruidDataSource了
1.2、Druid数据源的配置
| 配置项 | 案例值 | 描述 |
| url |
jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&zeroDataTimeBehavior=convertToNull&useSSL=false |
数据库连接地址 |
|
username
|
root | 数据库连接用户名 |
| password | 123456 | 数据库连接用户密码 |
| initialSize | 10 | 连接池初始化连接数 |
| minIdle | 1 | 连接池最小连接数 |
| maxActive | 20 | 连接池最大活跃连接数 |
| maxWait | 60000 | 客户端获取连接等待超时时间,单位为毫秒,此处的超时时间和创建连接超时时间是不一样的,客户端获取连接超时有可能是创建连接超时,也有可能是当前连接数达到最大值并且其他客户端正在使用,客户端一直排队等待可用连接超时了,所以尽量避免慢SQL,否则一旦可用连接被占用了且都在执行慢SQL,就会导致其他客户端长时间无法获取连接而超时 |
| timeBetweenEvictionRunsMillis | 60000 | 连接空闲检测间隔时长,单位为毫秒,当连接长时间空闲时,有定时任务会间隔间隔一段时间检测一次,如果发现连接空闲时间足够长,则关闭连接 |
| minEvictableIdleTimeMillis | 60000 | 连接最小生成时间,虽然空闲连接会被关闭,但是并非所有空闲的连接都会关闭,而是要看连接空闲了多长时间,比如配置了60000毫秒,那么当连接空闲超过1分钟时才会被关闭,否则可以继续空闲等待客户端 |
| validationQuery | select 'X' | 检测SQL |
| testwhileIdle | false | 空闲的时候检测执行validtionQuery严重连接是否有效,开启会消耗性能 |
| testOnReturn | false | 归还连接时执行validationQuery验证连接是否有效,开启会消耗性能 |
| poolPreparedStatements | true | 是否开启Prepared缓存,开启会提高重复查询的效率,但是会消耗一定的内存 |
| maxOpenPreparedStatements | 20 | 每个Connection的prepared缓存语句数量 |
二、Druid源码解析
连接池的主要作用是提供连接给应用程序,所以需要实现数据源DataSource接口,Druid提供的数据源为DruidDataSource实现了DataSource接口,核心逻辑实际就是实现了DataSource接口的getConnection方法,在分析getConnecction方法实现逻辑之前,首先需要了解DruidDataSource的主要属性,分别如下:
1. /** 初始化连接数,默认为0 */ 2 protected volatile int initialSize = DEFAULT_INITIAL_SIZE; 3 /** 最大连接数,默认是8 */ 4 protected volatile int maxActive = DEFAULT_MAX_ACTIVE_SIZE; 5 /** 最小空闲连接数,默认是0 */ 6 protected volatile int minIdle = DEFAULT_MIN_IDLE; 7 /** 最大空闲连接数,默认数8 */ 8 protected volatile int maxIdle = DEFAULT_MAX_IDLE; 9 /** 最大等待超时时间, 默认为-1,表示不会超时 */ 10 protected volatile long maxWait = DEFAULT_MAX_WAIT;
DruidDataSource的getConnection方法逻辑如下:
1 /** 获取数据库连接*/ 2 public DruidPooledConnection getConnection() throws SQLException { 3 return getConnection(maxWait); 4 } 5 6 public DruidPooledConnection getConnection(long maxWaitMillis) throws SQLException { 7 /** 初始化*/ 8 init(); 9 /** 初始化过滤器*/ 10 if (filters.size() > 0) { 11 FilterChainImpl filterChain = new FilterChainImpl(this); 12 return filterChain.dataSource_connect(this, maxWaitMillis); 13 } else { 14 /** 直接获取连接*/ 15 return getConnectionDirect(maxWaitMillis); 16 } 17 }
获取数据库连接时首先需要对连接池进行初始化,然后才能从连接池中获取连接,分别对应了方法init方法和getConnectionDirect方法,两个方法逻辑分别如下
2.1、连接池的初始化
init方法逻辑如下:
1 /** 连接池初始化 */ 2 public void init() throws SQLException { 3 /** 如果已经初始化直接返回 */ 4 if (inited) { 5 return; 6 } 7 8 final ReentrantLock lock = this.lock; 9 try { 10 /*** 加锁处理 */ 11 lock.lockInterruptibly(); 12 } catch (InterruptedException e) { 13 throw new SQLException("interrupt", e); 14 } 15 try { 16 /** 1.创建数据源ID */ 17 this.id = DruidDriver.createDataSourceId(); 18 19 /** 2.初始化过滤器 */ 20 for (Filter filter : filters) { 21 filter.init(this); 22 } 23 24 /** 25 * 3.maxActive、maxActive、minIdle、initialSize等参数校验以及JDBC等对象初始化 26 * */ 27 28 /** 4.初始化连接数组,数组大小为最大连接数*/ 29 connections = new DruidConnectionHolder[maxActive]; 30 31 SQLException connectError = null; 32 33 /** 5.根据初始化大小,初始化数据库连接*/ 34 for (int i = 0, size = getInitialSize(); i < size; ++i) { 35 //1.创建连接 36 Connection conn = createPhysicalConnection(); 37 //2.将连接封装成DruidConnectionHolder对象 38 DruidConnectionHolder holder = new DruidConnectionHolder(this, conn); 39 //3.将连接添加到连接数组中 40 connections[poolingCount] = holder; 41 incrementPoolingCount();//连接池中连接数自增+1 42 } 43 44 /** 创建并开启日志线程 */ 45 createAndLogThread(); 46 /** 创建并开启创建连接线程*/ 47 createAndStartCreatorThread(); 48 /** 创建并开启销毁连接线程*/ 49 createAndStartDestroyThread(); 50 /** 等待 创建连接线程 和 销毁连接线程 全部开启才算初始化完成 */ 51 initedLatch.await(); 52 53 }finally { 54 /** 标记已经初始化*/ 55 inited = true; 56 /** 释放锁*/ 57 lock.unlock(); 58 } 59 }
连接池初始化的逻辑主要如下:
1、判断是否已经初始化,如果已经初始化直接跳出;如果没有初始化则继续初始化
2、防止并发初始化需要加锁处理
3、初始化过滤器并进行初始化参数校验
4、初始化连接数组,并根据配置的初始化大小创建指定数量的连接存入数组中,初始化的连接数就是传入的参数值initialSIze的值
5、创建并开启创建连接和销毁连接的线程
6、标记初始化完成并释放锁
连接池初始化时会创建执指定数量的连接,并存入数组中。但是通常情况下连接池中的连接数量不是固定不变的,通常需要随着并发量提高要增加,随着并发量小而减少。所以在初始化的时候分别创建了创建连接的线程和销毁连接的线程,用于动态的创建连接和销毁连接,从而达到连接池动态的增删连接的效果。
2.1.1、创建连接的线程createAndStartCreatorThread方法源码解析
1 protected void createAndStartCreatorThread() { 2 if (createScheduler == null) { 3 String threadName = "Druid-ConnectionPool-Create-" + System.identityHashCode(this); 4 createConnectionThread = new CreateConnectionThread(threadName); 5 createConnectionThread.start(); 6 return; 7 } 8 9 initedLatch.countDown(); 10 }
该方法的主要作用就是创建了一个创建连接的线程CreateConnectionThread对象,并且启动了线程,所以核心逻辑就是需要分析该线程主要的流程,逻辑如下:
1 /** 创建连接线程*/ 2 public class CreateConnectionThread extends Thread { 3 4 public CreateConnectionThread(String name){ 5 super(name); 6 this.setDaemon(true); 7 } 8 9 public void run() { 10 initedLatch.countDown(); 11 for (;;) { 12 try { 13 lock.lockInterruptibly(); 14 } catch (InterruptedException e2) { 15 break; 16 } 17 18 try { 19 /** 20 * poolingCount:连接池中的空闲连接数量 21 * notEmptyWaitThreadCount:等待连接的线程数量 22 * 当连接足够时,睡眠线程 23 * */ 24 // 必须存在线程等待,才创建连接 25 if (poolingCount >= notEmptyWaitThreadCount) { 26 empty.await(); 27 } 28 29 // 防止创建超过maxActive数量的连接 30 /** 31 * activeCount: 活跃的连接数 32 * maxActive: 最大线程数 33 * 当活跃连接数 + 空闲连接数 >= 最大连接数时 睡眠线程 34 * */ 35 if (activeCount + poolingCount >= maxActive) { 36 empty.await(); 37 continue; 38 } 39 40 } catch (InterruptedException e) { 41 break; 42 } finally { 43 lock.unlock(); 44 } 45 46 /** 47 * 当等待连接的线程超过空闲线程;并且总连接数没有超过最大连接数时,创建新连接 48 * */ 49 Connection connection = null; 50 51 try { 52 /** 1.创建新连接 */ 53 connection = createPhysicalConnection(); 54 } catch (SQLException e) { 55 LOG.error("create connection error", e); 56 break; 57 } 58 59 if (connection == null) { 60 continue; 61 } 62 /** 2.将连接放入连接池中 */ 63 put(connection); 64 } 65 } 66 }
逻辑并不复杂,就是在一个死循环中不断判断当前连接数是否够用,并且是否超过最大上限,如果满足条件就创建新的连接,并且将连接添加到连接池中。
在这里有一个Condition对象empty,该对象主要用于监视当前的连接池是否需要创建连接了,如果不需要创建连接则调用await进行等待,等待连接不足时进行唤醒。
当连接创建之后,会调用put方法将连接放到连接数组中,逻辑如下:
1 protected void put(Connection connection) { 2 DruidConnectionHolder holder = null; 3 try { 4 /** 1.将连接封装成功DruidConnectionHolder对象 */ 5 holder = new DruidConnectionHolder(DruidDataSource.this, connection); 6 } catch (SQLException ex) { 7 lock.lock(); 8 try { 9 /** 10 * createScheduler 是创建连接的线程池 11 * createTaskCount 是当前需要创建连接的任务个数 12 * 当线程池不为空时,任务个数减1 13 * */ 14 if (createScheduler != null) { 15 createTaskCount--; 16 } 17 } finally { 18 lock.unlock(); 19 } 20 LOG.error("create connection holder error", ex); 21 return; 22 } 23 24 lock.lock(); 25 try { 26 /** 2.存入连接池数组中 */ 27 connections[poolingCount] = holder; 28 /** 3.空闲连接数poolingCount自增*/ 29 incrementPoolingCount(); 30 if (poolingCount > poolingPeak) { 31 /** 4.超过峰值则记录连接数量的峰值 */ 32 poolingPeak = poolingCount; 33 poolingPeakTime = System.currentTimeMillis(); 34 } 35 /** 3.唤醒notEmpty,因为该连接是非初始化创建而是动态额外添加的,所以需要唤醒销毁线程准备销毁该连接 */ 36 notEmpty.signal(); 37 notEmptySignalCount++; 38 39 if (createScheduler != null) { 40 createTaskCount--; 41 42 if (poolingCount + createTaskCount < notEmptyWaitThreadCount // 43 && activeCount + poolingCount + createTaskCount < maxActive) { 44 /** 如果连接数还是不足,则继续唤醒empty */ 45 emptySignal(); 46 } 47 } 48 } finally { 49 lock.unlock(); 50 } 51 } 52 53 /** 唤醒empty */ 54 private void emptySignal() { 55 if (createScheduler == null) { 56 empty.signal(); 57 return; 58 } 59 60 if (createTaskCount >= maxCreateTaskCount) { 61 return; 62 } 63 64 if (activeCount + poolingCount + createTaskCount >= maxActive) { 65 return; 66 } 67 68 createTaskCount++; 69 CreateConnectionTask task = new CreateConnectionTask();//创建连接的Task逻辑和CreateConneactionThread线程的逻辑完全一致 70 createScheduler.submit(task); 71 }
2.2.1.2、销毁连接的线程createAndStartDestroyThread方法源码解析
销毁连接的线程方法逻辑基本和创建连接的逻辑相反,主要逻辑如下:
1 /** 销毁连接线程 */ 2 public class DestroyConnectionThread extends Thread { 3 4 public DestroyConnectionThread(String name){ 5 super(name); 6 this.setDaemon(true); 7 } 8 9 public void run() { 10 initedLatch.countDown(); 11 12 for (;;) { 13 // 从前面开始删除 14 try { 15 if (closed) { 16 break; 17 } 18 /** 如果设置了检查间隔,则睡眠线程指定时长,否则就默认睡眠1秒*/ 19 if (timeBetweenEvictionRunsMillis > 0) { 20 Thread.sleep(timeBetweenEvictionRunsMillis); 21 } else { 22 Thread.sleep(1000); // 23 } 24 25 if (Thread.interrupted()) { 26 break; 27 } 28 /** 执行销毁连接的任务 */ 29 destoryTask.run(); 30 } catch (InterruptedException e) { 31 break; 32 } 33 } 34 } 35 36 }
销毁连接的任务交给了DestroyTask来实现,逻辑如下:
1 /** 销毁连接任务*/ 2 public class DestroyTask implements Runnable { 3 4 @Override 5 public void run() { 6 /** 1.销毁超过最大空闲时间的连接 */ 7 shrink(true); 8 9 /** 2.强制回收超过超时时间的连接*/ 10 if (isRemoveAbandoned()) { 11 removeAbandoned(); 12 } 13 } 14 }
销毁连接的任务主要有两个核心逻辑:
1、销毁空闲连接
当一个连接长时间没有被使用,如果不及时清理就会造成资源浪费,所以需要定时检查空闲时间过长的连接进行断开连接销毁
2、回收超时连接
当一个连接被一个线程长时间占有没有被归还,有可能是程序出故障了或是有漏洞导致吃吃没有归还连接,这样就可能会导致连接池中的连接不够用,所以需要定时检查霸占连接时间过长的线程,如果超过规定时间没有归还连接,则强制回收该连接。
销毁空闲连接逻辑如下:
1 /** 连接空闲时间,默认为30分钟 */ 2 public static final long DEFAULT_MIN_EVICTABLE_IDLE_TIME_MILLIS = 1000L * 60L * 30L; 3 4 /** 销毁空闲连接 */ 5 public void shrink(boolean checkTime) { 6 /** 1.需要从连接池中去除的连接列表 */ 7 final List<DruidConnectionHolder> evictList = new ArrayList<DruidConnectionHolder>(); 8 try { 9 lock.lockInterruptibly(); 10 } catch (InterruptedException e) { 11 return; 12 } 13 14 try { 15 /** 2.获取需要去除的个数 */ 16 final int checkCount = poolingCount - minIdle; 17 final long currentTimeMillis = System.currentTimeMillis(); 18 for (int i = 0; i < checkCount; ++i) { 19 DruidConnectionHolder connection = connections[i]; 20 /** 是否校验连接的空闲时间*/ 21 if (checkTime) { 22 long idleMillis = currentTimeMillis - connection.getLastActiveTimeMillis(); 23 /** 3.1.如果连接空闲时间超过设置的值,则去除*/ 24 if (idleMillis >= minEvictableIdleTimeMillis) { 25 evictList.add(connection); 26 } else { 27 break; 28 } 29 } else { 30 /** 3.2.如果不校验时间,则按顺序去除*/ 31 evictList.add(connection); 32 } 33 } 34 35 int removeCount = evictList.size(); 36 /** 4.从数组中将多余的连接移除*/ 37 if (removeCount > 0) { 38 System.arraycopy(connections, removeCount, connections, 0, poolingCount - removeCount); 39 Arrays.fill(connections, poolingCount - removeCount, poolingCount, null); 40 poolingCount -= removeCount; 41 } 42 } finally { 43 lock.unlock(); 44 } 45 46 /** 5.依次断开被移除的连接 */ 47 for (DruidConnectionHolder item : evictList) { 48 Connection connection = item.getConnection(); 49 JdbcUtils.close(connection); 50 destroyCount.incrementAndGet(); 51 } 52 }
回收超时连接逻辑如下:
1 /** 强制回收连接 */ 2 public int removeAbandoned() { 3 int removeCount = 0; 4 5 long currrentNanos = System.nanoTime(); 6 7 /** 1.定义需要回收的连接列表*/ 8 List<DruidPooledConnection> abandonedList = new ArrayList<DruidPooledConnection>(); 9 10 synchronized (activeConnections) { 11 Iterator<DruidPooledConnection> iter = activeConnections.keySet().iterator(); 12 13 for (; iter.hasNext();) { 14 DruidPooledConnection pooledConnection = iter.next(); 15 if (pooledConnection.isRunning()) { 16 continue; 17 } 18 long timeMillis = (currrentNanos - pooledConnection.getConnectedTimeNano()) / (1000 * 1000); 19 /** 2.遍历判断超时未回收的连接,并加入列表中 */ 20 if (timeMillis >= removeAbandonedTimeoutMillis) { 21 iter.remove(); 22 pooledConnection.setTraceEnable(false); 23 abandonedList.add(pooledConnection); 24 } 25 } 26 } 27 28 if (abandonedList.size() > 0) { 29 /** 3.遍历回收连接列表,进行连接回收*/ 30 for (DruidPooledConnection pooledConnection : abandonedList) { 31 synchronized (pooledConnection) { 32 if (pooledConnection.isDisable()) { 33 continue; 34 } 35 } 36 /** 3.1.强制断开连接*/ 37 JdbcUtils.close(pooledConnection); 38 pooledConnection.abandond(); 39 removeAbandonedCount++; 40 removeCount++; 41 42 /** 3.2.日志打印*/ 43 if (isLogAbandoned()) { 44 StringBuilder buf = new StringBuilder(); 45 buf.append("abandon connection, owner thread: "); 46 buf.append(pooledConnection.getOwnerThread().getName()); 47 buf.append(", connected time nano: "); 48 buf.append(pooledConnection.getConnectedTimeNano()); 49 buf.append(", open stackTrace\n"); 50 51 StackTraceElement[] trace = pooledConnection.getConnectStackTrace(); 52 for (int i = 0; i < trace.length; i++) { 53 buf.append("\tat "); 54 buf.append(trace[i].toString()); 55 buf.append("\n"); 56 } 57 58 LOG.error(buf.toString()); 59 } 60 } 61 } 62 return removeCount; 63 }
2.2、连接池中获取连接
1 /** 从连接池中获取连接 */ 2 public DruidPooledConnection getConnectionDirect(long maxWaitMillis) throws SQLException { 3 int notFullTimeoutRetryCnt = 0; 4 for (;;) { 5 // handle notFullTimeoutRetry 6 DruidPooledConnection poolableConnection; 7 try { 8 /** 1.获取连接 */ 9 poolableConnection = getConnectionInternal(maxWaitMillis); 10 } catch (GetConnectionTimeoutException ex) { 11 if (notFullTimeoutRetryCnt <= this.notFullTimeoutRetryCount && !isFull()) { 12 notFullTimeoutRetryCnt++; 13 if (LOG.isWarnEnabled()) { 14 LOG.warn("not full timeout retry : " + notFullTimeoutRetryCnt); 15 } 16 continue; 17 } 18 throw ex; 19 } 20 21 /** 2.判断获取的连接是否有效 */ 22 if (isTestOnBorrow()) { 23 boolean validate = testConnectionInternal(poolableConnection.getConnection()); 24 if (!validate) { 25 if (LOG.isDebugEnabled()) { 26 LOG.debug("skip not validate connection."); 27 } 28 /** 2.1 连接无效则抛弃连接 */ 29 Connection realConnection = poolableConnection.getConnection(); 30 discardConnection(realConnection); 31 continue; 32 } 33 } else { 34 Connection realConnection = poolableConnection.getConnection(); 35 if (realConnection.isClosed()) { 36 discardConnection(null); // 传入null,避免重复关闭 37 continue; 38 } 39 /** 3.如果没有判断连接有效性,则判断该连接是否空闲*/ 40 if (isTestWhileIdle()) { 41 final long currentTimeMillis = System.currentTimeMillis(); 42 final long lastActiveTimeMillis = poolableConnection.getConnectionHolder().getLastActiveTimeMillis(); 43 final long idleMillis = currentTimeMillis - lastActiveTimeMillis; 44 long timeBetweenEvictionRunsMillis = this.getTimeBetweenEvictionRunsMillis(); 45 if (timeBetweenEvictionRunsMillis <= 0) { 46 timeBetweenEvictionRunsMillis = DEFAULT_TIME_BETWEEN_EVICTION_RUNS_MILLIS; 47 } 48 /** 4.如连接空闲时间过长,则强制校验连接的有效性 */ 49 if (idleMillis >= timeBetweenEvictionRunsMillis) { 50 boolean validate = testConnectionInternal(poolableConnection.getConnection()); 51 if (!validate) { 52 if (LOG.isDebugEnabled()) { 53 LOG.debug("skip not validate connection."); 54 } 55 discardConnection(realConnection); 56 continue; 57 } 58 } 59 } 60 } 61 /** 4.给连接添加监听,超过时间未归还,则强制回收该连接*/ 62 if (isRemoveAbandoned()) { 63 StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace(); 64 poolableConnection.setConnectStackTrace(stackTrace); 65 poolableConnection.setConnectedTimeNano(); 66 poolableConnection.setTraceEnable(true); 67 68 synchronized (activeConnections) { 69 activeConnections.put(poolableConnection, PRESENT); 70 } 71 } 72 /** 5.设置是否自动提交 */ 73 if (!this.isDefaultAutoCommit()) { 74 poolableConnection.setAutoCommit(false); 75 } 76 return poolableConnection; 77 } 78 }
获取连接的逻辑步骤不多,首先是从连接池中获取连接,获取到连接之后根据配置项判断是否需要对连接进行有效性检测,防止获取到了一个无效的连接。
获取连接的方法getConnectionInternal方法逻辑如下:
1 /** 获取连接*/ 2 private DruidPooledConnection getConnectionInternal(long maxWait) throws SQLException { 3 /** 1.连接池状态判断*/ 4 if (closed) { 5 connectErrorCount.incrementAndGet(); 6 throw new DataSourceClosedException("dataSource already closed at " + new Date(closeTimeMillis)); 7 } 8 9 if (!enable) { 10 connectErrorCount.incrementAndGet(); 11 throw new DataSourceDisableException(); 12 } 13 14 final long nanos = TimeUnit.MILLISECONDS.toNanos(maxWait); 15 final int maxWaitThreadCount = getMaxWaitThreadCount(); 16 17 DruidConnectionHolder holder; 18 try { 19 lock.lockInterruptibly(); 20 } catch (InterruptedException e) { 21 connectErrorCount.incrementAndGet(); 22 throw new SQLException("interrupt", e); 23 } 24 25 try { 26 /** 2.判断等待获取连接的线程是否超过最大值 */ 27 if (maxWaitThreadCount > 0) { 28 if (notEmptyWaitThreadCount >= maxWaitThreadCount) { 29 connectErrorCount.incrementAndGet(); 30 throw new SQLException("maxWaitThreadCount " + maxWaitThreadCount + ", current wait Thread count " 31 + lock.getQueueLength()); 32 } 33 } 34 35 connectCount++; 36 if (maxWait > 0) { 37 /** 3.1 如果设置超时时间,则堵塞指定时长获取连接*/ 38 holder = pollLast(nanos); 39 } else { 40 /** 3.2 如果没有设置超时时间,则堵塞获取连接*/ 41 holder = takeLast(); 42 } 43 44 if (holder != null) { 45 activeCount++; 46 if (activeCount > activePeak) { 47 activePeak = activeCount; 48 activePeakTime = System.currentTimeMillis(); 49 } 50 } 51 } catch (InterruptedException e) { 52 connectErrorCount.incrementAndGet(); 53 throw new SQLException(e.getMessage(), e); 54 } catch (SQLException e) { 55 connectErrorCount.incrementAndGet(); 56 throw e; 57 } finally { 58 lock.unlock(); 59 } 60 61 /** 4.如果获取不到连接,则打印错误日志并抛异常 */ 62 if (holder == null) { 63 long waitNanos = waitNanosLocal.get(); 64 65 StringBuilder buf = new StringBuilder(); 66 buf.append("wait millis ")// 67 .append(waitNanos / (1000 * 1000))// 68 .append(", active " + activeCount)// 69 .append(", maxActive " + maxActive)// 70 ; 71 72 List<JdbcSqlStatValue> sqlList = this.getDataSourceStat().getRuningSqlList(); 73 for (int i = 0; i < sqlList.size(); ++i) { 74 if (i != 0) { 75 buf.append('\n'); 76 } else { 77 buf.append(", "); 78 } 79 JdbcSqlStatValue sql = sqlList.get(i); 80 buf.append("runningSqlCount "); 81 buf.append(sql.getRunningCount()); 82 buf.append(" : "); 83 buf.append(sql.getSql()); 84 } 85 86 String errorMessage = buf.toString(); 87 88 if (this.createError != null) { 89 throw new GetConnectionTimeoutException(errorMessage, createError); 90 } else { 91 throw new GetConnectionTimeoutException(errorMessage); 92 } 93 } 94 95 holder.incrementUseCount(); 96 /** 5.构造连接对象并返回 */ 97 DruidPooledConnection poolalbeConnection = new DruidPooledConnection(holder); 98 return poolalbeConnection; 99 }
获取连接主要看有没有设置超时时间,如果设置了超时时间则调用pollLast方法进行尝试获取连接,超时没有获取则返回空;takeLast方法是一直堵塞当前线程直到获取连接成功才会返回。
1 /** 一直堵塞获取连接*/ 2 DruidConnectionHolder takeLast() throws InterruptedException, SQLException { 3 try { 4 /** 1.如果当前空闲连接数为0 */ 5 while (poolingCount == 0) { 6 /** 2.发送信号等待创建连接*/ 7 emptySignal(); // send signal to CreateThread create connection 8 notEmptyWaitThreadCount++; 9 if (notEmptyWaitThreadCount > notEmptyWaitThreadPeak) { 10 notEmptyWaitThreadPeak = notEmptyWaitThreadCount; 11 } 12 try { 13 /** 等待信号*/ 14 notEmpty.await(); // signal by recycle or creator 15 } finally { 16 notEmptyWaitThreadCount--; 17 } 18 notEmptyWaitCount++; 19 20 if (!enable) { 21 connectErrorCount.incrementAndGet(); 22 throw new DataSourceDisableException(); 23 } 24 } 25 } catch (InterruptedException ie) { 26 notEmpty.signal(); // propagate to non-interrupted thread 27 notEmptySignalCount++; 28 throw ie; 29 } 30 31 decrementPoolingCount(); 32 /** 获取连接池最后一位的连接*/ 33 DruidConnectionHolder last = connections[poolingCount]; 34 /** 将数组对应位置置为空*/ 35 connections[poolingCount] = null; 36 return last; 37 }
1 private DruidConnectionHolder pollLast(long nanos) throws InterruptedException, SQLException { 2 long estimate = nanos; 3 4 for (;;) { 5 if (poolingCount == 0) { 6 emptySignal(); // send signal to CreateThread create connection 7 8 if (estimate <= 0) { 9 waitNanosLocal.set(nanos - estimate); 10 return null; 11 } 12 13 notEmptyWaitThreadCount++; 14 if (notEmptyWaitThreadCount > notEmptyWaitThreadPeak) { 15 notEmptyWaitThreadPeak = notEmptyWaitThreadCount; 16 } 17 18 try { 19 long startEstimate = estimate; 20 /** 等待信号指定时长*/ 21 estimate = notEmpty.awaitNanos(estimate); // signal by 22 // recycle or 23 // creator 24 notEmptyWaitCount++; 25 notEmptyWaitNanos += (startEstimate - estimate); 26 27 if (!enable) { 28 connectErrorCount.incrementAndGet(); 29 throw new DataSourceDisableException(); 30 } 31 } catch (InterruptedException ie) { 32 notEmpty.signal(); // propagate to non-interrupted thread 33 notEmptySignalCount++; 34 throw ie; 35 } finally { 36 notEmptyWaitThreadCount--; 37 } 38 39 if (poolingCount == 0) { 40 if (estimate > 0) { 41 continue; 42 } 43 44 waitNanosLocal.set(nanos - estimate); 45 return null; 46 } 47 } 48 49 decrementPoolingCount(); 50 DruidConnectionHolder last = connections[poolingCount]; 51 connections[poolingCount] = null; 52 53 return last; 54 } 55 }
takeLast和pollLast的逻辑基本上一直,主要是看等待连接时是一直等待还是超时等待,一般都会设置超时时间,防止程序一直堵塞着。这里又使用到了emptySignal和notEmptySignal, 后面仔细分析。
2.3、连接归还到连接池
当程序使用完连接需要将连接归还到线程池,通过会执行connection.close方法进行关闭,Druid中的连接对象为DruidPooledConnection,close方法中执行了回收的方法recycle(),该方法会将连接回收到连接池中,逻辑如下:
1 public void recycle() throws SQLException { 2 if (this.disable) { 3 return; 4 } 5 6 DruidConnectionHolder holder = this.holder; 7 if (holder == null) { 8 if (dupCloseLogEnable) { 9 LOG.error("dup close"); 10 } 11 return; 12 } 13 14 if (!this.abandoned) { 15 /** 获取数据源头像 */ 16 DruidAbstractDataSource dataSource = holder.getDataSource(); 17 /** 执行数据源的recycle方法进行连接回收*/ 18 dataSource.recycle(this); 19 } 20 21 this.holder = null; 22 conn = null; 23 transactionInfo = null; 24 closed = true; 25 }
主要步骤为先获取该连接所属的数据源对象,然后直接执行DataSource对象的recycle方法进行连接的回收,DruidDataSource中的recycle方法逻辑如下:
1 /** 2 * 回收连接 3 */ 4 protected void recycle(DruidPooledConnection pooledConnection) throws SQLException { 5 final DruidConnectionHolder holder = pooledConnection.getConnectionHolder(); 6 7 if (holder == null) { 8 LOG.warn("connectionHolder is null"); 9 return; 10 } 11 12 final Connection physicalConnection = holder.getConnection(); 13 14 if (pooledConnection.isTraceEnable()) { 15 synchronized (activeConnections) { 16 if (pooledConnection.isTraceEnable()) { 17 Object oldInfo = activeConnections.remove(pooledConnection); 18 if (oldInfo == null) { 19 if (LOG.isWarnEnabled()) { 20 LOG.warn("remove abandonded failed. activeConnections.size " + activeConnections.size()); 21 } 22 } 23 pooledConnection.setTraceEnable(false); 24 } 25 } 26 } 27 28 final boolean isAutoCommit = holder.isUnderlyingAutoCommit(); 29 final boolean isReadOnly = holder.isUnderlyingReadOnly(); 30 final boolean testOnReturn = this.isTestOnReturn(); 31 32 try { 33 // check need to rollback? 34 if ((!isAutoCommit) && (!isReadOnly)) { 35 pooledConnection.rollback(); 36 } 37 38 //校验回收线程和获取线程是否一致,并对连接持有对象进行重置 39 boolean isSameThread = pooledConnection.getOwnerThread() == Thread.currentThread(); 40 if (!isSameThread) { 41 synchronized (pooledConnection) { 42 holder.reset(); 43 } 44 } else { 45 holder.reset(); 46 } 47 48 if (holder.isDiscard()) { 49 return; 50 } 51 52 /** 校验连接*/ 53 if (testOnReturn) { 54 boolean validate = testConnectionInternal(physicalConnection); 55 if (!validate) { 56 JdbcUtils.close(physicalConnection); 57 58 destroyCount.incrementAndGet(); 59 60 lock.lock(); 61 try { 62 activeCount--; 63 closeCount++; 64 } finally { 65 lock.unlock(); 66 } 67 return; 68 } 69 } 70 71 if (!enable) { 72 /** 如果连接池不可用则丢弃连接*/ 73 discardConnection(holder.getConnection()); 74 return; 75 } 76 77 final long lastActiveTimeMillis = System.currentTimeMillis(); 78 lock.lockInterruptibly(); 79 try { 80 /** 统计数据修改*/ 81 activeCount--; 82 closeCount++; 83 /** 将连接添加到连接池数组的尾部 */ 84 putLast(holder, lastActiveTimeMillis); 85 recycleCount++; 86 } finally { 87 lock.unlock(); 88 } 89 } catch (Throwable e) { 90 holder.clearStatementCache(); 91 92 if (!holder.isDiscard()) { 93 this.discardConnection(physicalConnection); 94 holder.setDiscard(true); 95 } 96 97 LOG.error("recyle error", e); 98 recycleErrorCount.incrementAndGet(); 99 } 100 }
1 void putLast(DruidConnectionHolder e, long lastActiveTimeMillis) { 2 e.setLastActiveTimeMillis(lastActiveTimeMillis); 3 /** 将连接放到连接池数组的尾部 */ 4 connections[poolingCount] = e; 5 incrementPoolingCount(); 6 7 if (poolingCount > poolingPeak) { 8 poolingPeak = poolingCount; 9 poolingPeakTime = lastActiveTimeMillis; 10 } 11 /** 唤醒notEmpty */ 12 notEmpty.signal(); 13 notEmptySignalCount++; 14 }
三、Druid的实现细节
3.1、核心类
3.1.1、DruidDataSource类
DruidDataSource是Druid提供的数据类,实现了DataSource接口,实现了获取连接的getConnection方法,用于应用程序使用的数据对象,内部持有连接的数组DruidConnectionHolder[] connections表示连接池
3.1.2、DruidPooledConnection类
DruidPooledConnection表示数据库连接对象,应用程序获取DruidPooledConnection执行SQL,使用完毕调用close方法释放连接
3.1.3、DruidConnectionHolder类型
DruidConnectionHolder是DruidPooledConnection类的封装,表示连接池中持有的连接对象,连接池添加连接时实际是创建DruidConnectionHolder对象放入数组中,获取连接就是从数组尾部获取DruidConnectionHolder对象
3.2、ReentrantLock和Condition的使用
DruidDataSource内部有一个ReentrantLock lock对象和两个Condition对象,分别为empty和notEmpty,主要用于连接的创建和销毁的等待和通知。
数据库连接池初始化的时候会初始化固定数量的连接,但是随着应用程序的运行,数据库连接的需求往往是动态变化的,比如初始化时创建了10个连接,但是高峰期的时候需要15个连接才可以满足需求,此时连接池就需要动态的对连接池进行扩容,而等到高峰期过了之后,数据库连接池还需要将多余创建的5个连接进行释放,不然在空闲时间也会占据着连接造成资源的浪费。连接池中连接的动态增删就是依靠了empty和notEmpty这两个Condition对象。
empty用于通知创建连接,notEmpty用于通知应用获取应用
初始化时启动创建连接的线程,判断当前是否需要创建连接,如果不需要创建则调用empty.await()方法进行等待,等待empty被唤醒之后进行创建连接,一旦empty被唤醒就会创建连接,创建完成之后通知notEmpty,让用户不再阻塞,拿到连接对象。
客户端调用getConnection方法获取连接时,如果当前没有可用连接,则调用empty.signal()方法唤醒empty,并调用notEmpty.await()睡眠等待连接创建完成
3.3、Druid工作流程图
1、 getConnection方法流程如下:
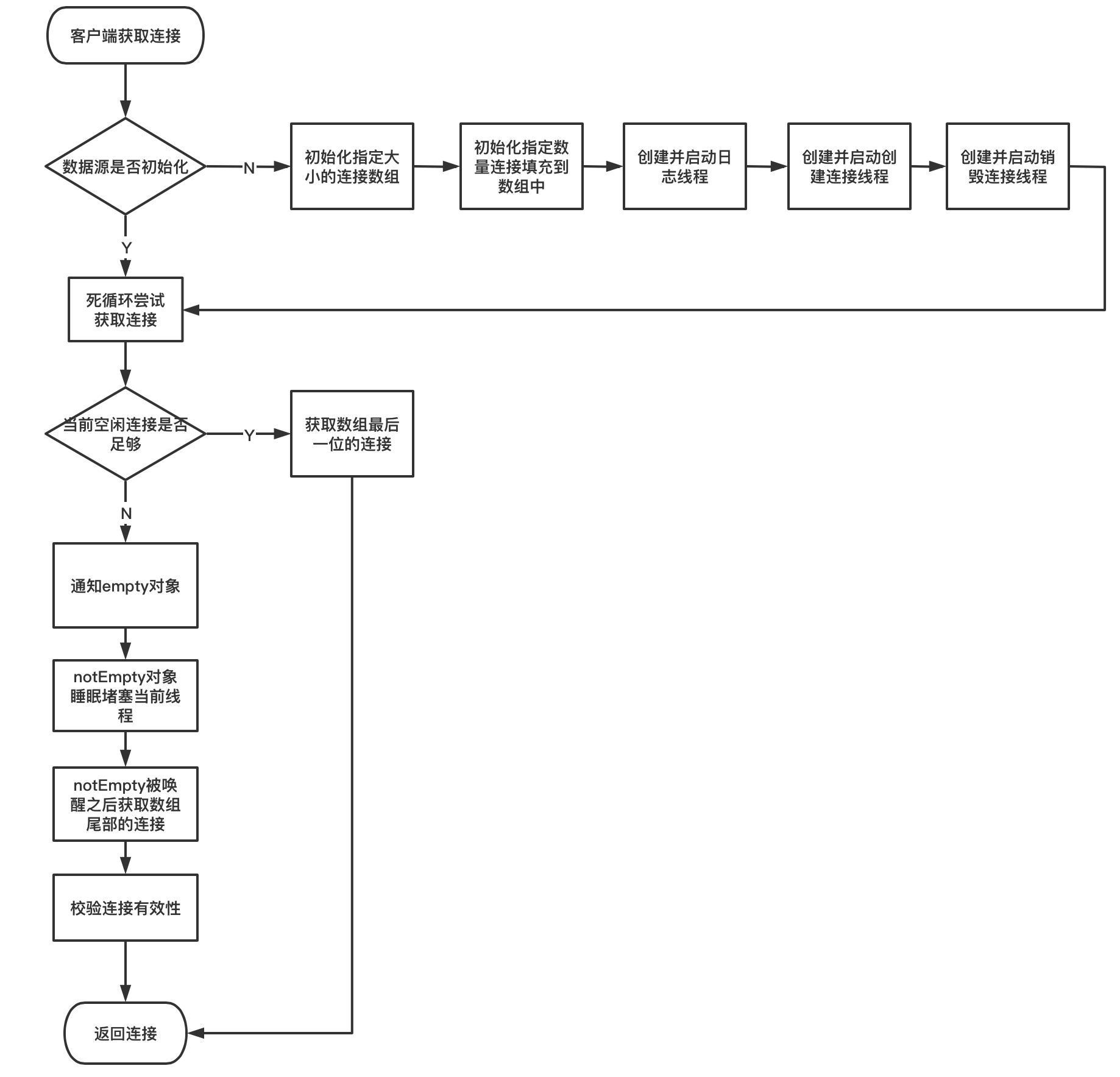
2、创建连接线程和销毁连接线程流程如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号