
NIO之路5--Netty框架详细整理
一、Netty简介
Netty是目前最流行的NIO框架之一,健壮性、功能、性能、可定制性和可扩展性都是首屈一指的。Dubbo、Tomcat等都采用Netty作为底层的NIO通信框架,主要优点有:
1.API使用简单
2.功能强大,预制了多种编解码功能,支持多种主流协议
3.定制能力强,可以通过ChannelHandler对通信框架进行灵活的扩展
4.性能高,Netty综合性能比其他NIO框架要高
5.成熟稳定,修复了JDK NIO的epoll BUG
6.社区活跃(JDK的NIO使用复杂,Mina停止维护)
二、Netty核心组件
和NIO一样,Netty核心组件也有Buffer和Channel
2.1、ByteBuf(缓冲区)
JDK的ByteBuffer是缺点是长度固定,不可动态扩展;只有一个标志位置position,需要手动调用flip()和rewind(),API使用不当就容易出错
Netty在Java NIO的ByteBuffer基础之上进行封装和扩展,从而衍生了ByteBuf,ByteBuf实际就是由两个索引分别控制读写位置的字节数组,ByteBuf优点如下:
1.容量可以按需进行扩容
2.在读写之间切换不需要手动执行ByteBuffer的flip()方法进行切换
3.读写操作使用了不同的索引
4.支持引用计数
5.支持内存池化进行优化
另外ByteBuf可以动态扩容,当可写的大小小于需要写入的大小时,就需要进行扩容,扩容机制 以64为基础不停乘以2 或者 是2的22次方整数倍,直到满足大小(满足的大小=待写入大小+已写入大小)
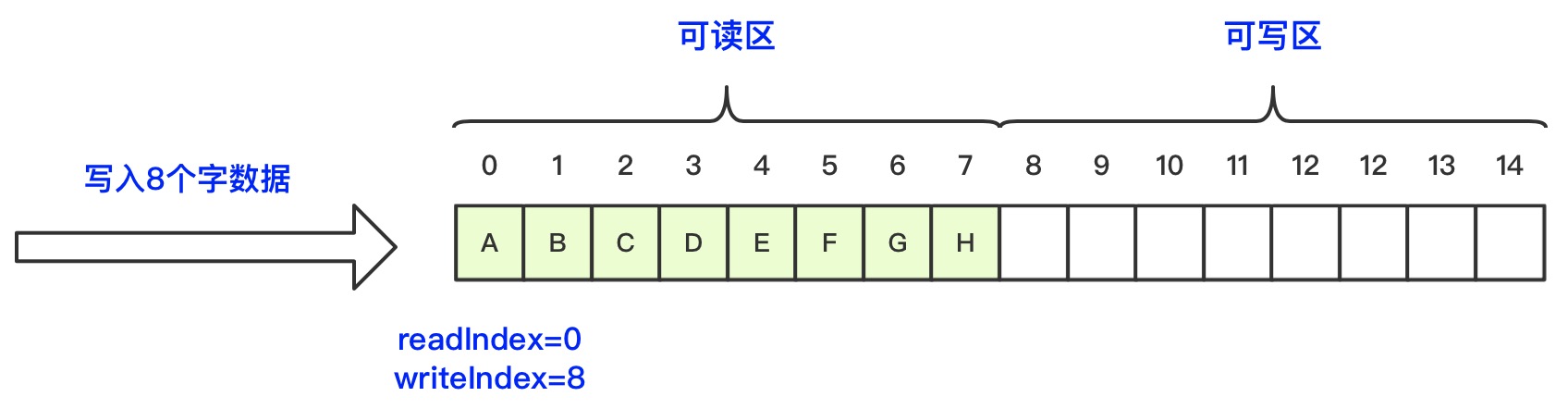
ByteBuf是一个字节数组,通过读索引readIndex和写索引writeIndex来控制读写位置,初始化ByteBuf时readIndex和writeIndex值都为0,随着数据的写入writeIndex会增加,数据的读取会使readIndex增加,但是readIndex不可以超过writeIndex。被读取过后的区域也就是0~readIndex之间的区域就是可以被丢弃的区域,可以调用discardReadBytes方法释放这块区域的空间,相当于ByteBuffer的compact方法,而readIndex~writeIndex之间的区域表示是可读区域,writeIndex~capacity之间的区域是可写的。读写操作都仅改变自己的索引值,所以不需要进行读写之间的切换,大大简化了缓冲区的操作复杂度。ByteBuf的整体工作状态如下图示:
1、初始化ByteBuf,readIndex和writeIndex值都为0

2、调用write方法写入8位的数据之后,readIndex不变,writeIndex值为8
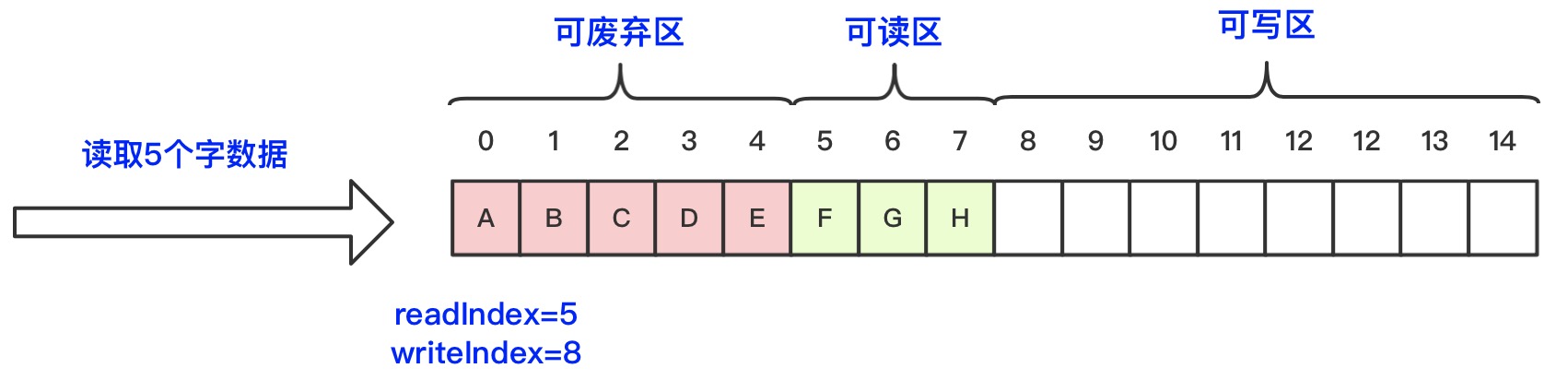
3、调用read方法读取5位的数据之后,readIndex值为5,writeIndex值为8,读取完的区域为可废弃的区域
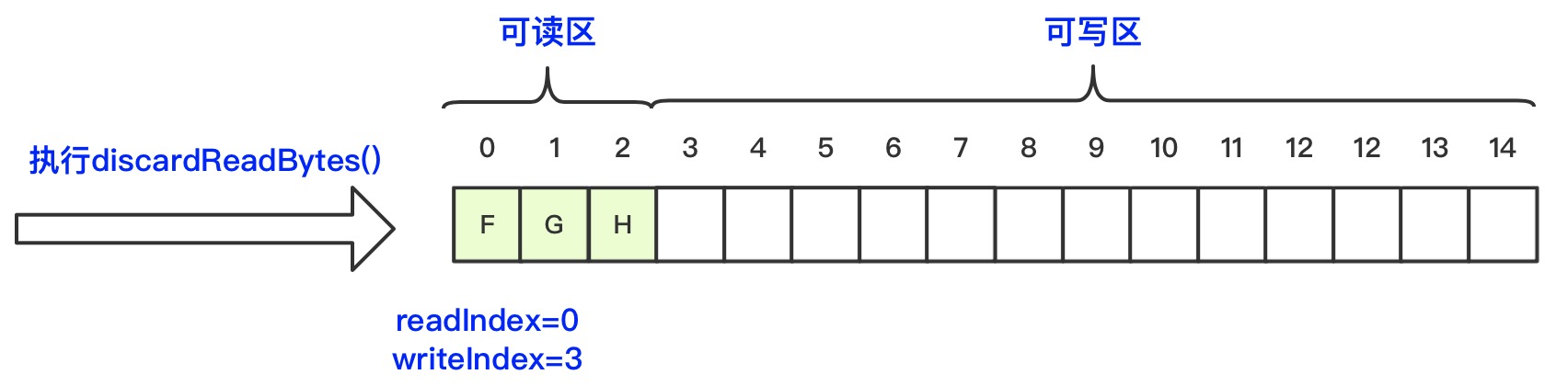
4、调用discardReadBytes()方法可以回收废弃区的空间,则readIndex值为0,writeIndex值为未读数据量3
ByteBuf提供的API分成读写两种,而读写又分别分成是否改变索引值两种情况
以get为方法前缀的操作都是读操作,但是不会修改readIndex索引的值,只是单纯的从指定的索引位置读取数据
以set为方法前缀的操作都是写操作,但是不会修改writeIndex索引的值,只是单纯的从指定的索引位置写入数据
以read为方法前缀的操作是根据readIndex进行读取操作,并且读完之后会修改readIndex索引的值
以write为方法前缀的操作都是根据writeIndex进行写入操作,并且写完之后会修改writeIndex索引的值
主要API如下:
get系列方法是获取指定索引位置的数据,根据返回值类型读取对应的字节数,但是不会改变readIndex值
| 方法 | 描述 |
| getBoolean(int index) | 返回指定索引位置的boolean值,读取一个字节,0为false;1:为true |
| getByte(int index) | 返回指定索引位置的byte值,读取一个字节 |
| getInt(int index) | 返回指定索引位置的int值,读取4个字节,计算int值 |
| getLong(int index) | 返回指定索引位置的long值,读取8个字节,计算long值 |
| getShort(int index) | 返回索引位置的short值,读取2个字节,计算short值 |
set系列方法是设置指定索引位置的值,根据不同类型写入对应的字节树,但是不会改变writeIndex值
| 方法 | 描述 |
| setBoolean(int index, boolean value) | 设置指定索引位置的boolean值,写1个字节 |
| setByte(int index, byte value) | 设置指定索引位置的byte值,写1个字节 |
| setInt(int index, int value) | 设置指定索引位置的int值,写4个字节 |
| setLong(int index, long value) | 设置指定索引位置的long值,写8个字节 |
| setShort(int index, short value) | 设置指定索引位置的short值,写2个字节 |
read系列方法是读取当前readIndex位置的数据,根据返回值类型读取对应的字节树,而且会改变readIndex值
| 方法 | 描述 |
| readBoolean() | 返回当前readIndex索引位置的boolean值,readIndex自增1位 |
| readByte() | 返回当前readIndex索引位置的byte值,readIndex自增1位 |
| readInt() | 返回当前readIndex索引位置的int值,readIndex自增4位 |
| readLong() | 返回当前readIndex索引位置的long值,readIndex自增8位 |
| readShort() | 返回当前readIndex索引位置的,readIndex自增2位 |
write系列方法是从当前writeIndex位置开始写入实际,根据类型写入固定位的字节树,而且会改变writeIndex值
| 方法 | 描述 |
| writeBoolean(boolean value) | 从当前writeIndex索引位置写入boolean值,writeIndex自增1位 |
| writeByte(byte value) | 从当前writeIndex索引位置写入byte值,writeIndex自增1位 |
| writeInt(int value) | 从当前writeIndex索引位置写入int值,writeIndex自增4位 |
| writeLong(long value) | 从当前writeIndex索引位置写入long值,writeIndex自增8位 |
| writeShort(short value) | 从当前writeIndex索引位置写入short值,writeIndex自增2位 |
除了读写方法之后,ByteBuf还提供了一些工具方法,分别如下:
| 方法 | 描述 |
| isReadable() | 是否可读,至少有一个字节可读就返回true |
| isWritable() | 是否可写,至少有一个字节可写就返回true |
| readableBytes() | 返回可读字节数 |
| writableBytes() | 返回可写字节数 |
| capacity() | 返回ByteBuf的容量,值会动态扩容变化,但是不会超过maxCapacity()的值 |
| hasArray() | 如果ByteBuf是一个字节数组,那么返回true |
| array() | 如果ByteBuf是一个字节数组,那么返回字节数组,否则抛异常 |
ByteBuf的分配,ByteBuf的分配通常有专门的分配工具ByteBufAllocator接口,ByteBufAllocator接口有两个实现类PooledByteBufAllocator和UnpooledByteBufAllocator
PooledByteBufAllocator分配的ByteBuf是采用了内存池技术,需要ByteBuf对象时会从内存池中直接获取,避免了ByteBuf的频繁创建和释放带来的性能消耗和内存碎片
UnpooledByteBufAllocator分配的ByteBuf没有采用池化技术,所以每次获取ByteBuf对象时都会直接新创建一个新的实例
另外和MINA的IoBuffer一样,ByteBuf的分配不仅可以从堆内分配内存,也可以从直接内存中分配内存,ByteBufAllocator提供的API如下:
buffer():从堆内内存或直接内存中返回一个ByteBuf对象,实际情况会情况启动参数配置来选择是堆内内存还是直接内存
heapBuffer():从堆内内存中返回一个ByteBuf对象
directBuffer():从直接内存中返回一个ByteBuf对象
以上上个方法返回的ByteBuf对象是否采用池化技术就看调用的ByteBufAllocator实现类是哪个
另外ByteBuf类实现了ReferenceCounted接口,ReferenceCounted接口用于引用计数,主要是统计对象被引用的次数,方法如下:
int refCnt():返回当前对象被引用的次数
ReferenceCounted retain():引用次数增加1
boolean release():引用次数减少1,但引用次数为0时返回true
ByteBuf池化技术就比较依赖引用计数的实现,通过引用计数判断ByteBuf是否被引用.
当ByteBuf需要通过SocketChannel网络读写时,需要将ByteBuf转换成ByteBuffer,通过 nioBuffer()方法实现,将当前ByteBuf的可读缓冲区转换成ByteBuffer,两者共享同一个缓冲区内容引用
重点:
ByteBuffer的实现有两种,一种是堆内存,一种是直接内存
堆内存:JVM堆内分配,分配和回收由JVM控制,速度较快,但是在进行socket的IO读写时,需要将数据从堆内存copy到直接内存,涉及到一次CPU拷贝
直接内存:socket读写io时,不需要进行额外的copy操作,性能较好,但是分配和回收效率不如堆内存
最佳方案:IO通信线程的读写缓冲区采用DirectByteBuffer;业务处理的编解码模块等使用HeapByteBuffer
AbstractsByteBuf 继承自ByteBuf,也是主要属性和功能等实现类
AbstractReferenceCountedByteBuf:主要作用是引用进行计数
对象每调用一次retain方法,引用计数器会加1,通过CAS自增的方式,初始值是1,当被释放和被申请的次数相等时,就调用回收方法回收当前的ByteBuf对象。调用deallocatie方法进行释放
2.2、Channel(通道)
和JDK NIO中的channel类似,Netty定义了自己的channel类,除了可以进行网络的读写、连接的管理还包括了获取该Channel的EventLoop、获取缓冲分配器和pipeline等
每一个Channel都对应这一个客户端socket连接,而且IO数据的读写都是分别调用channel的read和write方法进行操作的
那么为什么不使用JDK的Channel呢?原因如下:
1.SocketChannel和ServerSocketChannel相对独立,没有统一接口
2.只能实现网络的IO读写
Netty提供的channell功能很多
1.read():从channel中读取数据到缓冲区
2.write():将msg通过channelPipeLine写入到目标channel中,但是只是存放到发送环形数组中,并没有发送
3.flush():将环形数组中的数据发送到目标channel
4.writeAndFlush():写入并发送
5.close、connection、disconnection等和连接相关的方法
6.metadata():获取TCP连接的配置参数
parent():对于服务端,父channel为空,对于客户端,父channel就是创建它的ServerSocketChannel
eventLoop():获取channel注册的EventLoop
Channel中实际的网络IO操作都是通过Unsafe类的方法实现
2.3、EventLoop、EventLoopGroup接口(工作线程组)
EventLoop用来处理连接的生命周期内的所有事件,每一个channel都会绑定一个EventLoop,这个Channel发生的所有事件都有这个EventLoop处理,而一个EventLoop同时可以绑定多个Channel
而通常EventLoop不会单独出现,而是以组的形式出现,定义的接口为EventLoopGroup,一个EventLoopGroup中包含多个EventLoop,所以Channel、EventLoop、EventLoopGroup的关系如下图示:
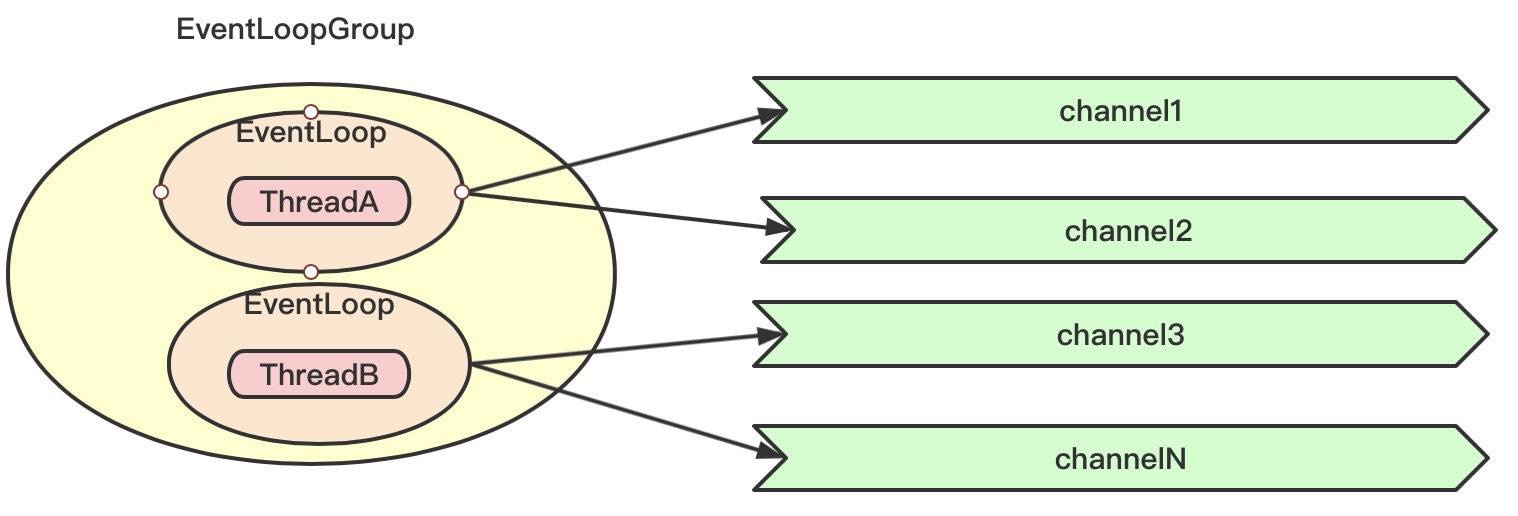
1、一个EventLoopGroup中包含多个EventLoop
2、channel注册到EventLoopGroup之后,会从EventLoopGroup分配一个EventLoop
3、EventLoop用于处理channel整个生命周期内的所有事件
4、一个channel只可以注册到一个EventLoop
5、一个EventLoop可以被分配多个channel
6、一个EventLoop的整个生命周期都由一个线程处理
所以可以得出结论就是一个channel的所有IO事件都由同一个EventLoop处理,且都由同一个线程处理,可以将EventLoop看作是NIO中的Selector的角色
2.4、ChannelHandler接口(业务处理器)
是ChannelHandler顾名思义就是用来处理Channel发生的事件或状态的变化的处理器。而处理Channel的IO事件,channel本身也有着多种状态
| 状态 | 描述 |
| ChannelUnregistered | channel已经创建,但是还没有注册EventLoop |
| ChannelRegistered | channel已经创建并且已经注册EventLoop |
| ChannelActive | channel处于活跃状态,表示已经连接成功,可以发送和接收数据 |
| ChannelInactive | channel处于不活跃状态,表示连接异常或连接已经断开 |
通常Channel的状态变化顺序为: ChannelRegistered -> ChannelActive -> ChannelInactive -> ChannelUnregistered
当channel出现状态的变化时,就会产生对应的事件交给ChannelHandler来处理
另外ChannelHandler通常也不是只有一个,而是和MINA的IoFilter类似,通常是以处理器链的方式存在,而将多个ChannelHandler存在在一起的组件就叫做ChannelPipeline
所以ChannelHandler本身又会有生命周期,从添加到ChannelPipeline中开始到从ChannelPipeline中移除结束,ChannelHandler定义了如下方法:
| 方法 | 描述 |
| handlerAdded | 当ChannelHandler添加到ChannelPipeline中时会被调用 |
| handlerRemoved | 当ChannelHandler从ChannelPipeline中移除时会被调用 |
| exceptionCaught | 当在ChannelPipeline中抛异常时会被调用 |
MINA的IoFilter会处理所有的IO流,而ChannelHandler则对IO流进行了区分,按读事件和写事件进行区分,所以ChannelHandler就有了两个子接口ChannelInboundHandler和ChannelOutboundHandler
2.4.1、ChannelInboundHandler接口(入站操作和数据处理器)
ChannelInboundHandler专门用于处理入站操作和数据以及对应的Channel发生状态的变化时会被调用。核心方法如下:
| 方法 | 描述 |
| channelRegistered | 当channel注册到EventLoop且能够处理IO时被调用 |
| channelUnregistered | 当channel从EventLoop中移除且无法处理IO时被调用 |
| channelActive | 当channel处于活跃状态时被调用,表示channel连接成功可以处理IO |
|
channelInactive |
当channel处于不活跃状态并且不会再连接远程节点时被调用 |
| channelRead | 当channel读取数据时会调用,实现类实现了之后需要显式的池化和释放ByteBuf相关的内存 |
| channelReadComplete | 当channel一个读操作完成时被调用 |
| channelWritabilityChanged | 当channel的可写状态发生改变时被调用 |
| userEventTriggered | 当ChannelInboundHandler的fireUserEventTriggered()方法被调用时会调用,主要用于处理用户自定义事件 |
2.4.2、ChannelOutboundHandler接口(出站操作和数据处理器)
ChannelOutboundHandler专门用于处理出站操作和数据,通常由Channel、ChannelPipeline和ChannelHandlerContext调用。核心方法如下:
| 方法 | 描述 |
| bind | 当请求将channel绑定到本地地址时调用 |
| connect | 当请求将channel连接到远程主机时调用 |
| disconnect | 当请求将channel从远程主机断开时调用 |
| close | 当请求关闭channel时调用 |
| deregister | 当请求将channel从EventLoop中注销注册时调用 |
| read | 当请求从channel中读取更多数据时调用 |
| flush | 当请求通过channel将入队数据冲刷到远程主机时调用,冲刷就是立即发送 |
| write | 当请求通过channel将数据写到远程主机时调用,只是写但是并非立即发送 |
2.4.3、ChannelHandlerAdapter类(处理器适配器)
ChannelHandler接口定义的方法比较多,而两个子接口又分别添加了各自的方法,所以实现类就需要实现所有的方法,但是并非所有的实现类都需要关系ChannelHandler所有的方法的,此时就可以使用适配器模式来解决.
ChannelHandler的两个子接口都有各自的适配器,分别为ChannelInboundHandlerAdapter和ChannelOutboundHandlerAdapter
ChannelInboundHandlerAdapter和ChannelOutboundHandlerAdapter都对各自实现的接口完成了基本的实现,子类只需要对于自己感兴趣的方法进行重写即可,而不需要实现所有的方法
2.5、ChannelPipeline接口(事件传播器)
ChannelPipeline是ChannelHandler的容器,也可以理解为一个管道,每一个ChannelHandler创建都需要关联一个所有ChannelPipeline的ChannelHandler都会在ChannelPipeline中按顺序组成链路.
当channel中有入站事件,那么该事件会在ChannelPipeline所有的ChannelInboundHandler依次处理;
当channel中有出站事件,那么该事件会在ChannelPipeline所有的ChannelOutboundHandler依次处理;
ChannelPipeline提供了多个方法用于增删改ChannelHandler,提供方法分别如下:
| 方法 | 描述 |
| addFirst | 在头部插入一个ChannelHandler |
| addBefore | 在指定ChannelHandler前面插入一个ChannelHandler |
| addAfter | 在指定ChannelHandler后面插入一个ChannelHandler |
| addLast | 在尾部插入一个ChannelHandler |
| remove | 从ChannelPipeline中删除指定ChannelHandler |
| replace | 从ChannelPipeline中将指定ChannelHandler替换成新的ChannelHandler |
channelPipeline对于入站事件提供的方法如下:
| 方法 | 描述 |
| fireChannelRegistered | 调用ChannelPipeline中下一个ChannelInboundHandler的channelRegistered方法 |
| fireChannelUnregistered | 调用ChannelPipeline中下一个ChannelInboundHandler的channelUnregistered方法 |
| fireChannelActive | 调用ChannelPipeline中下一个ChannelInboundHandler的channelActive方法 |
| fireChannelInactive | 调用ChannelPipeline中下一个ChannelInboundHandler的channelInactive方法 |
| fireExceptionCaught | 调用ChannelPipeline中下一个ChannelInboundHandler的exceptionCaught方法 |
| fireUserEventTriggered | 调用ChannelPipeline中下一个ChannelInboundHandler的userEventTriggered方法 |
| fireChannelRead | 调用ChannelPipeline中下一个ChannelInboundHandler的channelRead方法 |
| fireChannelReadComplete | 调用ChannelPipeline中下一个ChannelInboundHandler的channelReadComplete方法 |
| fireChannelWritabilityChanged | 调用ChannelPipeline中下一个ChannelInboundHandler的channelWritabilityChanged方法 |
channelPipeline对于出站事件提供的方法如下:
| 方法 | 描述 |
| bind | 将Channel绑定到一个本地地址,将调用ChannelPipeline中下一个ChannelOutboundHandler的bind方法 |
| connect | 将Channel连接一个远程主机,将调用ChannelPipeline中下一个ChannelOutboundHandler的connect方法 |
| disconnect | 将Channel断开连接,将调用ChannelPipeline中下一个ChannelOutboundHandler的disconnect方法 |
| close | 将Channel关闭,将调用ChannelPipeline中下一个ChannelOutboundHandler的close方法 |
| deregister | 将Channel从分配的EventLoop中注销,将调用ChannelPipeline中下一个ChannelOutboundHandler的deregister方法 |
| flush | 冲刷Channel中所有挂起的写入,将调用ChannelPipeline中下一个ChannelOutboundHandler的flush方法 |
| write | 将消息写入Channel,将调用ChannelPipeline中下一个ChannelOutboundHandler的write方法 |
| writeAndFlush | 同时调用write和flush方法,表示写入消息并立即冲刷 |
| read | 请求从Channel中读取更多的数据,将调用ChannelPipeline中下一个ChannelOutboundHandler的read方法 |
总结:
ChannelPipeline保存了和Channel关联的ChannelHandler
ChannelPipeline提供API,用于响应出站和入站事件,并会将事件传递给内部维护的所有ChannelInboundHandler或ChannelOutboundHandler依次处理
一个ChannelPipeline中包含了多个ChannelHandler;
一个ChannelHandler可以关联多个ChannelPipeline,这一个和MINA的IoFilter有所区别
2.6、ChannelHandlerContext(业务处理器上下文)
ChannelHandlerContext可以理解为ChannelHandler的上下文,主要用来维护ChannelHandler和ChannelPipeline的关联关系,因为ChannelPipeline可以关联多个ChannelHandler,而ChannelHandler同样可以关联多个ChannelPipeline,这就涉及到多个ChannelPipeline共享同一个ChannelHandler的场景(比如跨Channel统计一些Channel相关信息时当出现共享ChannelHandler时,就会出现ChannelHandler处理完IO事件之后不知道下一个需要处理IO事件的ChannelHandler是哪一个了,此时就需要ChannelHandlerContext来解决每一个ChannelHandler关联一个ChannelPipeline都会创建一个ChannelHandlerContext对象,ChannelHandlerContext的功能就是管理所关联的ChannelHandler和在同一个ChannelPipeline中的其他的ChannelHandler进行交互.
可以看出ChannelHandlerContext提供的很多方法在ChannelPipeline中也提供了,区别是调用ChannelPipeline的方法会沿着整个ChannelPipeline进行传播;而调用ChannelHandlerContext上对应的方法则会从当前所关联的ChannelHandler开始,并且只会传播给位于该ChannelPipeline中下一个需要处理该事件的ChannelHandler.这样做的好处是可以避免将事件传递给对此事件不感兴趣的ChannelHandler处理
ChannelHandlerContext提供的API大致如下:
| 方法 | 描述 |
| alloc | 返回关联的Channel配置的ByteBufAllocator |
| bind | 将Channel绑定到指定的SocketAddress,并返回ChannelFuture |
| channel | 返回绑定的Channel |
| close | 关闭Channel,并返回ChannelFuture |
| connect | 连接到指定的SocketAddress,并返回ChannelFuture |
| disconnect | 远程节点端口,并返回ChannelFuture |
| deregister | 将Channel从分配的EventLoop中注销,并返回ChannelFuture |
| executor | 返回调度事件的EventExecutor |
| fireChannelActive | 触发下一个ChannelInboundHandler的fireChannelActive方法 |
| fireChannelInactive | 触发下一个ChannelInboundHandler的fireChannelInactive方法 |
| fireChannelRead | 触发下一个ChannelInboundHandler的fireChannelRead方法 |
| fireChannelReadComplete | 触发下一个ChannelInboundHandler的fireReadComplete方法 |
| fireChannelRegistered | 触发下一个ChannelInboundHandler的fireChannelRegistered方法 |
| fireChannelUnregistered | 触发下一个ChannelInboundHandler的channelUnregistered方法 |
| fireChannelWritabilityChanged | 触发下一个ChannelInboundHandler的fireChannelWritabilityChanged方法 |
| fireExceptionCaught | 触发下一个ChannelInboundHandler的fireExceptionCaught方法 |
| fireUserEventTriggered | 触发下一个ChannelInboundHandler的fireUserEventTriggered方法 |
| handler | 返回绑定的ChannelHandler |
| isRemoved | 返回ChannelHandler是否从ChannelPipeline中移除 |
| pipeline | 返回关联的ChannelPipeline |
| read | 将数据从Channel读取到第一个入站缓冲区,如果读取成功则触发一个channelRead事件 |
| write | 通过当前ChannelHandler写入消息并经过ChannelPipeline |
| writeAndFlush | 通过当前ChannelHandler写入消息并立即冲刷消息 |
对于调用ChannelHandlerContext和ChannelPipeline上相同的方法,ChannelHandlerContext的效率更高,因为不需要传播给无需处理的ChannelHandler进行处理
三、Netty的启动类和配置
Netty中组件比较多,而组件之间是如何工作对于用户是模糊的,所以Netty提供了引导类来组合Netty的组件,引导类提供了一些API使得可以将Netty的各种组件组合在一起形成可以工作的真正的Netty服务器或客户端。
Netty中引导类父类为AbstractBootStrap类,引导客户端可以使用子类BootStrap类,引导服务端可以使用子类ServerBootStrap类
以服务端为例,引导类ServerBootStrap提供的API方法分别如下:
| 方法 | 描述 |
| group(EventLoopGroup parentGroup, EventLoopGroup childGroup) | 设置主从线程组,parentGroup用于处理客户端连接请求,childGroup用于处理分配的IO事件 |
| channel(Class<? extends C channelClass) | 设置用于客户端连接的通道,如NioServerSocketChanel.class |
| option(ChannelOption<T> option, T value) | 设置ServerChannel的配置 |
| childOption(ChannelOption<T> childOption, T value) | 设置客户端channel的配置 |
| handler(ChannelHandler handler) | 设置被添加到ServerChannel中的ChannelPipeline的ChannelHandler,用于处理客户端连接事件 |
| childHandler(ChannelHandler handler) | 设置客户端连接通过Channel中的ChannelPipeline的ChannelHandler,用于处理客户端IO事件 |
| bind | 绑定ServerChannel并且返回一个ChannelFuture,会在绑定操作完成后收到结果 |
Netty启动类案例代码如下:
1 int availableProcessors = Runtime.getRuntime().availableProcessors(); 2 NioEventLoopGroup bossGroup = new NioEventLoopGroup(4); 3 NioEventLoopGroup workerGroup = new NioEventLoopGroup(availableProcessors * 2); 4 ServerBootstrap bootstrap = new ServerBootstrap(); 5 bootstrap.group(bossGroup, workerGroup); 6 bootstrap.channel(NioServerSocketChannel.class); 7 bootstrap.option(ChannelOption.SO_BACKLOG, 1024); 8 bootstrap.childOption(ChannelOption.TCP_NODELAY, true); 9 bootstrap.childOption(ChannelOption.SO_RCVBUF, refParams.getBufferSize()); 10 bootstrap.childOption(ChannelOption.SO_SNDBUF, refParams.getBufferSize()); 11 bootstrap.handler(new LoggingHandler(LogLevel.DEBUG)); 12 13 bootstrap.childHandler(new ChannelInitializer<SocketChannel>() { 14 @Override 15 protected void initChannel(SocketChannel ch) { 16 17 ChannelPipeline pipeline = ch.pipeline(); 18 pipeline.addLast("Idle", new IdleStateHandler(16, 16, 40)); 19 pipeline.addLast("decode", new JSONDecoder(refParams.getPolicyFormat())); 20 pipeline.addLast("encode", new JSONEncoder(refParams.getPolicyFormat())); 21 pipeline.addLast(new AliveHandler()); 22 pipeline.addLast("handler", refParams.getHandler()); 23 24 } 25 });
Netty初始化时常用配置如下:
| 配置 | 描述 |
| ChannelOption.ALLOCATOR | ByteBuf分配器,默认为ByteBufAllocator.DEFAULT,用于设置是否采用内存池,可选值为使用内存池PooledByteBufAllocator和不使用内存次UnpooledByteBufAllocator |
| ChannelOption.RCVBUF_ALLOCATOR | 用于channel分配接收Buffer的分配器,默认为AdaptiveRecvByteBufAllocator.DEFAULT,是自适应调整大小的缓冲区分配器,还有一个FixedRecvByteBufAllocator固定大小的缓冲区分配器 |
| ChannelOption.SO_BACKLOG | 对应TCP协议listen函数中的backlog参数,服务端处理客户端连接请求是顺序处理的,同一时间只可以处理一个客户端,多个客户端来的时候,服务端不能处理的客户端连接会放在队列中等待处理,backlog就表示等待连接处理的队列大小 |
| ChannelOption.SO_KEEPALIVE | 对应TCP协议的的SO_KEEPALIVE参数,当连接两小时内没有数据通信时,TCP会自动发送心跳包检测连接状态 |
| ChannelOption.SO_SNDBUF | 对应套接字中的SO_SNDBUF参数,表示发送缓冲区的大小 |
| ChannelOption.SO_RCVBUF | 对应套接字中的SO_RCVBUF参数,表示接收缓冲区的大小 |
| ChannelOption.REUSEADDR | 对应套接字中的REUSEADDR参数,表示是否允许重复使用本地地址和端口,当端口被占用时,设置为true表示允许公用端口 |
| ChannelOption.SO_LINGER | 对应套接字中的SO_LINGER参数,表示当调用close方法关闭客户端连接时,阻塞close方法直到数据完全发送完毕,否则可能会造成数据没有发送完全就关闭了连接,破坏数据完整性 |
| ChannelOption.SO_TIMEOUT | 对应套接字中的SO_TIMEOUT参数,表示读取数据超时的时间 |
| ChannelOption.TCO_NODELAY | 对应TCP协议的TCP_NODELAY,表示使用使用Nagle算法,采用Nagle算法TCP数据包会有一定的延迟,但是会提高网络使用率 |
| ChannelOption.IP_TOS | 对应IP参数Type_of_Service字段,用于描述IP包的优先级和QoS选项 |
四、Netty的心跳检测机制
当客户端连接长期处理不活跃状态时,TCP连接默认会在两个小时只会检测发送心跳包来判断客户端是否断开.而很显然两个小时对于应用程序来说有点久,所以Netty就提供了自己的心跳检测机制,同样也是通过ChannelHandler来实现的.
当连接空闲指定时间后触发一个IdleStateEvent事件,然后通过自定义ChannelHandler在userEventTriggered方法中处理该IdleStateEvent事件。Netty分别提供了三种ChannelHandler来给用户使用,分别如下:
| handler | 描述 |
| IdeaStateHandler | 可以设置读空闲时间、写空闲时间和读写都空闲时间,检测空闲之后发送IdleStateEvent事件上报给ChannelPipeline进行传播 |
| ReadTimeoutHandler | 如果在指定时间内没有收到任何入站的数据,那么抛ReadTimeoutException,并关闭Channel |
| WriteTimeoutHandler | 如果在指定时间内没有写入任何出站的数据,那么抛WriteTimeoutException,并关闭Channel |
IdleStateHandler的工作原理如下:
1、初始化IdleStateHandler时传入读空闲时长、写空闲时长和读写空闲时长
2、IdleStateHandler监听channel活跃状态,活跃之后执行channelActive方法
3、channel活跃之后分别针对读空闲、写空闲和读写空闲开启定时任务,定时任务执行时间为定义的最大空闲时长
4、channel每次有读写事件发生时都会记录上次读写的时间lastReadTime和lastWriteTime
5、定时任务执行,判断当前时间和上一次读写时间和设置的最大空闲时长进行比较
6、如果实际读写间隔时长大于设置的空闲时长,则创建IdleStateEvent事件,并调用ChannelHandlerContext的fireUserEventTriggered进行传播
7、需要处理空闲事件的ChannelHandler进行空闲事件处理
五、Netty粘包拆包问题解决及预制编解码
TCP传输数据是以字节流的方式进行传输,而流是没有界限的一串数据,而业务层需要将一串字节流数据进行划分成业务层需要的数据。但是TCP发送包的大小是有限制的,如果业务层的数据比较大就必须将业务层数据拆分成多个TCP包进行发送,此时就是拆包情况。
另外如果业务层数据比较小,那么此时封装成TCP包进行发送就比较浪费网络资源,所以通常会将多个业务层数据包合并成一个TCP包进行发送,这样就形成了粘包的情况。
假设TCP包容量为两个字符,那么连续发送两个字符"A"和"B"就会将两个业务层数据合并成"AB"一块发送;发送字符串"JACK"就会被拆分成两个TCP包"JA"和"CK"分别发送,如下图所示:

底层TCP是无法理解业务层的数据格式的,所以粘包和拆包问题只能通过业务层来进行解决,通常需要发送方和接收方定义好通信的协议,发送方和接收方都根据规定好的通信协议进行数据的发送和接收。通常解决粘包拆包问题的主流协议解决方案如下:
1、包文定长,例如每次TCP包文固定发送200大小的数据包,如果不足大小则通过补空格补齐(不足大小时比较浪费网络资源)
2、在包尾添加回车换行符进行分割(当业务数据中真的包含回车换行符时还是会出现拆包情况,只能通过业务层缓存直到完整的数据包解析完成)
3、在包尾添加自定义分割符进行分割,和第二种方案原理一样,只是分隔符采用自定义的符号
4、将包文逻辑拆分成包头和消息体,包头存储整个数据包的大小,消息体包含内容,这样接收方先读取包头然后读取固定长度的包内容即可,通常采用int类型存储包的大小,用4为的byte存储
5、根据实际场景自定义协议
在Netty中由于网络传输的原始数据都是字节码流,而字节码流是业务层不认识的,需要通过编码或解码成业务层需要的数据格式,而Netty中可以通过自定义ChannelHandler的方式来统一对传输的IO数据进行编解码操作.
将入站的IO字节码格式的数据转化成业务数据就需要通过解码器来进行解码;将出站的业务数据转化成用于网络传输的字节码数据就需要通过编码器来进行编码。解决TCP粘包拆包问题比较通用的有四种方案,而Netty就针对这四种方案分别提供了编解码器,分别如下:
1、LineBasedFrameDecoder:通过"\n"或"\r\n"作为分割符对数据进行解码处理
2、DelimiterBasedFrameDecoder:通过自定义分隔符对数据进行解码处理
3、FixedLengthFrameDecoder:固定长度的解码器,长度通过构造函数固定
4、LengthFieldBasedFrameDecoder:长度存放在消息体头部,解析指定长度的数据
五、Netty的线程模型
Netty框架可主要分成三层通信调度层、职责链路层、业务处理层
5.1、Reactor通信调度层
包括两个线程池组成的Reactor线程模型,主要职责是监听网络的读写和连接事件,负责将网络层的数据读取到缓冲区,然后触发各种网络事件,将这些事件触发到pipeLine中,由pipeLine管理的职责链进行后续的处理
Netty的整体线程模型采用了Reactor线程模型中的主从多线程模式,Reactor主从多线程整体模型如下图示:
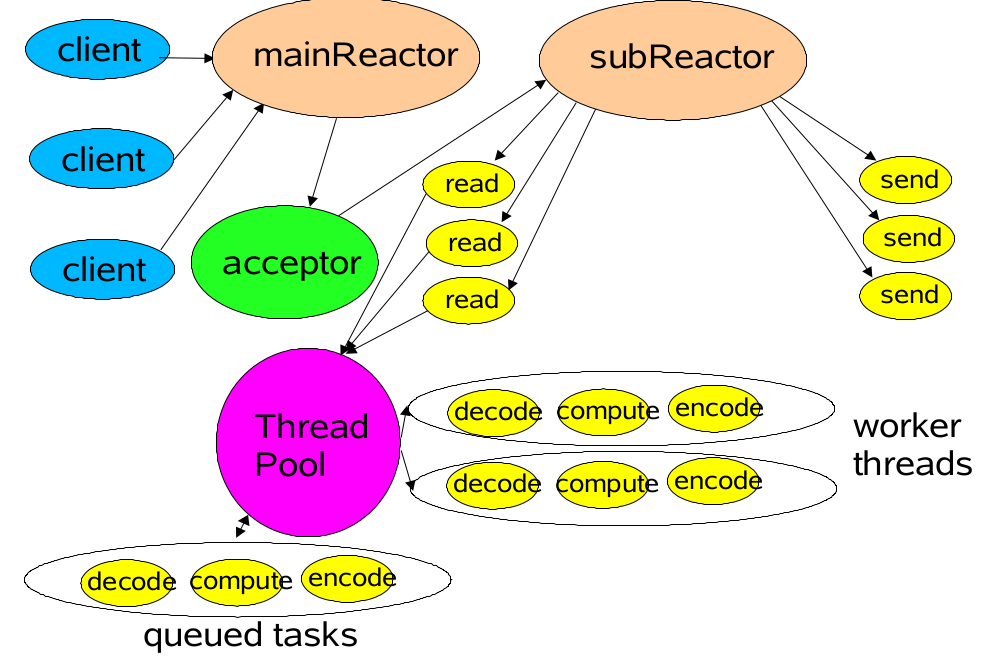
Reactor主从多线程模型主要分成两个线程池,mainReactor线程池专门用于监听处理客户端连接请求,当有连接到达时调用accept()函数将创建的SocketChannel注册到subReactor,subReactor会通过负载均衡算法为客户端channel分配一个线程并绑定感兴趣的IO事件,然后通过Selector监听IO事件状态,当IO事件触发之后将IO事件交给对应的线程进行IO事件处理。另外SubReactor中每个线程都会负责多个客户端channel的IO事件处理,所以会存在工作队列进行按序处理IO事件
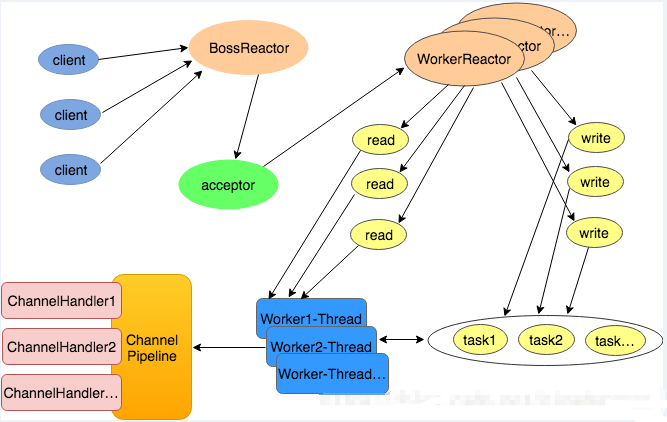
Netty的线程模型是基于Reactor线程模型设计的,线程模型图如下:
5.2、职责链ChannelPipeline
负责事件在职责链中的有序传播,负责动态编排职责链,职责链相当于一系列的拦截器,对于自己感兴趣的事件进行拦截处理,然后向后或向前传播事件,最常用的就是编解码handler,将外部的协议消息格式转换成应用需要的数据格式
这样的好处是业务层只需要处理具体的业务逻辑即可,不需要关心底层的数据传输及编解码的过程。
5.3、ChannelHandler
纯粹的业务处理层,负责具体业务的处理
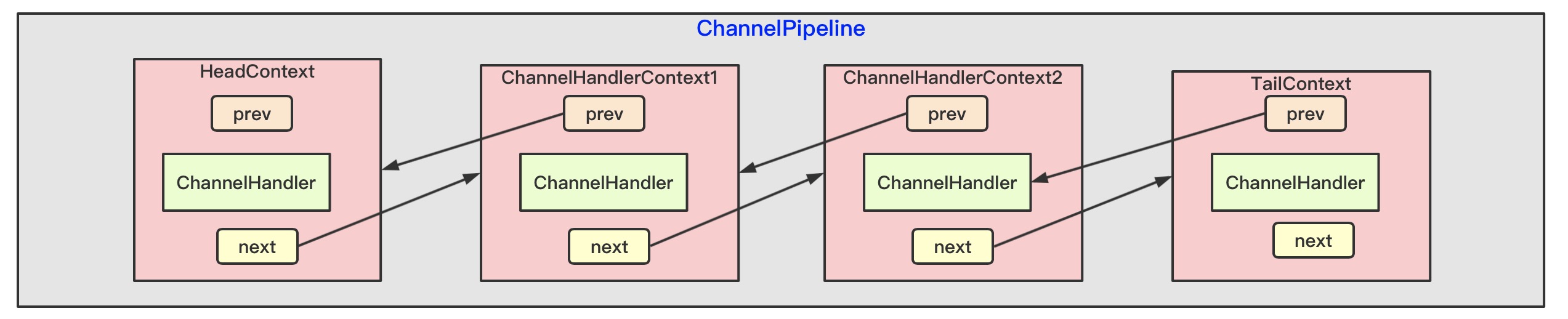
ChannelPipeline内部维护着ChannelHandlerContext的双向链表,而ChannelHandlerContext是和ChannelHandler是一一绑定的,所以ChannelPipeline和ChannelHandler以及ChannelHandlerContext的关系如下图示:
ChannelPipeline处理入站事件时会从头节点HeadContext开始处理一直到TailContext,而ChannelPipeline处理出站事件时会从TailContext开始处理一直到HeadContext
六、Netty工作流程及源码实现细节
1、服务端初始化ServerChannel,并初始化两个线程池bossEventLoopGroup和workEventLoopGroup,分别用于处理客户端连接请求和客户端IO事件
2、boosEventLoopGroup中的线程通过Selector接收到客户端连接请求之后,将客户端连接封装成Channel,并交给workEventLoopGroup处理
3、workEventLoop会根据channel的id进行取模算法选取一个EventLoop和channel进行注册,并监听channel的IO事件,并创建一个ChannelPipeline和ChannelHandler
4、当channel触发IO事件之后,EventLoop中的Selector可以监听到,将IO事件交给ChannelPipeline
5、ChannelPipeline将IO事件从内部的ChannelHandler链路中依次传播,依次调用ChannelHandler的对应处理方法
6、ChannelPipeline中最后一个ChannelHandler也就是tailHandler会将IO数据交给业务层的ChannelHandler处理
7、业务层的ChannelHandler对IO数据进行业务处理
Netty服务端配置及启动案例如下:
1 public static void main(String[] args) throws InterruptedException { 2 /** 初始化服务器引导对象*/ 3 ServerBootstrap bootstrap = new ServerBootstrap(); 4 //获取CPU核数 5 int processorsCount = Runtime.getRuntime().availableProcessors(); 6 /** 初始化boss线程池,线程数为2*/ 7 NioEventLoopGroup bossGroup = new NioEventLoopGroup(2); 8 /** 初始化worker线程池,线程数为CPU核数两倍*/ 9 NioEventLoopGroup workGroup = new NioEventLoopGroup(processorsCount * 2); 10 /** 设置boss线程池和work线程池 */ 11 bootstrap.group(bossGroup, workGroup); 12 /** 设置boss线程池在的Channel实现类类型 */ 13 bootstrap.channel(NioServerSocketChannel.class); 14 /** 设置ServerChannel的配置*/ 15 bootstrap.option(ChannelOption.SO_BACKLOG, 1024); 16 /** 主线程ServerChannel添加ChannelHandler */ 17 bootstrap.handler(new LoggingHandler()); 18 19 /** 初始化客户端Channel的ChannelPipeline和ChannelHandler */ 20 bootstrap.childHandler(new ChannelInitializer<SocketChannel>() { 21 @Override 22 protected void initChannel(SocketChannel socketChannel) throws Exception { 23 /** 创建ChannelPipeline对象 */ 24 ChannelPipeline pipeline = socketChannel.pipeline(); 25 26 /** 在ChannelPipeline 尾部添加 心跳检测ChannelHandler*/ 27 pipeline.addLast("Idle", new IdleStateHandler(30, 30, 40)); 28 29 /** 根据\n或\r\n作为分隔符进行解码处理 */ 30 pipeline.addLast("lineDecoder", new LineBasedFrameDecoder(1024)); 31 32 /** 根据 & 作为分隔符进行解码处理 */ 33 ByteBuf delimiter = Unpooled.copiedBuffer("&".getBytes()); 34 pipeline.addLast("lenghtDecoder", new DelimiterBasedFrameDecoder(1024, delimiter)); 35 36 /** 固定长度为200进行解码处理 */ 37 pipeline.addLast("fixedLengthDecoder", new FixedLengthFrameDecoder(200)); 38 39 /** 表示字节码的从0为到8位为数据的大小,截取指定大小的数据进行解码 40 * 如数据大小为100,则字节码0-8位数据为 01100100 表示数据包长度为100,然后再解码后面100位的数据进行解析 41 * */ 42 pipeline.addLast("lengthFieldDecoder", new LengthFieldBasedFrameDecoder(1024, 0, 8)); 43 44 } 45 }); 46 47 /** 绑定端口号 */ 48 ChannelFuture future = bootstrap.bind(8000); 49 /** 阻塞当前main线程*/ 50 future.sync(); 51 }
主要是构造了ServerBootstrap类并且设置了主从线程池并且设置响应的参数,最终执行bind方法监听端口,而bind方法执行之后实际也就相当于Netty服务器正式开始工作了,最后的future.sync()方法则是调用wait方法阻塞当前线程,否则主线程执行完毕就关闭了。
6.1、ChannelPipeline初始化及添加ChannelHandler
ChannelPipeline通过SocketChannel.pipeline()方法返回,pipeline()方法的实现在于抽象类AbstractChannel中,AbstractChannel内部有一个pipeline属性,并且会在初始化AbstractChannel时初始化一个ChannelPipeline的默认实现类,源码如下:
1 protected AbstractChannel(Channel parent) { 2 this.parent = parent; 3 id = newId(); 4 unsafe = newUnsafe(); 5 pipeline = newChannelPipeline(); 6 }
默认的实现类为DefaultChannelPipeline,构造方法如下:
protected DefaultChannelPipeline(Channel channel) { /** 初始化尾节点handler */ tail = new TailContext(this); /** 初始化首节点*/ head = new HeadContext(this); head.next = tail; tail.prev = head; }
ChannelPipeline初始化的时候会初始化两个ChannelHandler,分别是HeadContext和TailContext,而HeadContext和TailContext分别是ChannelHandlerContext的子类
ChannelPipeline内部维护一个ChannelHandlerContext对象的链表,头部是HeadContext对象,尾部是TailContext对象,而用户自定义的ChannelHandler会插入到head节点和tail节点之间,如addLast方法大致逻辑如下:
1 public final ChannelPipeline addLast(EventExecutorGroup group, String name, ChannelHandler handler) { 2 final AbstractChannelHandlerContext newCtx; 3 synchronized (this) { 4 /** 将ChannelHandler封装成ChannelHandlerContext对象 */ 5 newCtx = newContext(group, filterName(name, handler), handler); 6 /** 插入链表中 */ 7 addLast0(newCtx); 8 } 9 } 10 return this; 11 } 12 13 private void addLast0(AbstractChannelHandlerContext newCtx) { 14 /** 设置新插入的节点的前继节点为当前尾节点前继节点,后继节点为尾节点 15 * 设置尾节点的前继节点为新插入的节点,并设置原先的前继节点的后继节点为新插入的节点*/ 16 AbstractChannelHandlerContext prev = tail.prev; 17 newCtx.prev = prev; 18 newCtx.next = tail; 19 prev.next = newCtx; 20 tail.prev = newCtx; 21 }
6.2、bind方法的实现
bind的方法主要可以分成两步:
第一步是通过反射机制创建ServerChannel,反射的类通过bootStrap.channel(NioServerSocketChannel.class)这一行进行设置,会通过反射创建NioServerSocketChannel的实例。并对serverChannel进行初始化和注册。
同时会对serverChannel初始化ChannelPipeline以及ChannelHandler等属性,并给ChannelPipeline添加处理器ServerBootstrapAcceptor,用于处理接收客户端请求
第二步是调用doBind()方法对于端口进行绑定和监听,该方法最终调用了channelPipeline的bind方法,而我们知道channelPipeline上执行的方法都会依次调用注册的ChannelHandler的对应方法,所以channelPipeline实际就是调用了尾节点tail的bind方法
根据ChannelPipeline的工作机制可以得知,ChannelPipeline执行bind方法,实际上就是从TailContext节点开始依次调用所有对于bind事件感兴趣的ChannelHandler的bind方法。
由于事件需要从tail节点开始传播,所以tail节点需要指定剩下的ChannelHandler都有哪些是对于bind事件感兴趣的,在AbstractChannelHandlerContext中提供了寻找的方法,findContextOutbound(int mask)和findContextInbound(int mask),源码如下:
/** 寻找下一个对于指定入站事件感兴趣的ChannelHandlerContext * 通常是从头节点开始 * */ private AbstractChannelHandlerContext findContextInbound(int mask) { AbstractChannelHandlerContext ctx = this; do { /** 循环获取下一个节点 */ ctx = ctx.next; /** 根据位运算判断是否对于指定事件感兴趣*/ } while ((ctx.executionMask & mask) == 0); return ctx; } /** 寻找下一个对于指定出站事件感兴趣的ChannelHandlerContext * 通常是从尾节点开始 * */ private AbstractChannelHandlerContext findContextOutbound(int mask) { AbstractChannelHandlerContext ctx = this; do { /** 循环获取上一个节点 */ ctx = ctx.prev; /** 根据位运算判断是否对于指定事件感兴趣*/ } while ((ctx.executionMask & mask) == 0); return ctx; }
寻找的逻辑就是从当前开始,循环依次返回下一个对于入站事件感兴趣的或上一个对于出站事件感兴趣的ChannelHandlerContext。而参数mask就代表指定的事件,所有的事件对应的二进制值在ChannelHandlerMask中定义,如下:
static final int MASK_EXCEPTION_CAUGHT = 1; //异常事件,二进制为 0000 0000 0000 0001 static final int MASK_CHANNEL_REGISTERED = 1 << 1;//channel注册事件,二进制为 0000 0000 0000 0010 static final int MASK_CHANNEL_UNREGISTERED = 1 << 2;//channel取消注册事件,二进制为 0000 0000 0000 0100 static final int MASK_CHANNEL_ACTIVE = 1 << 3;//channel活跃事件,二进制为 0000 0000 0000 1000 static final int MASK_CHANNEL_INACTIVE = 1 << 4;//channel不活跃事件,二进制为 0000 0000 0001 0000 static final int MASK_CHANNEL_READ = 1 << 5;//channel可读事件,二进制为 0000 0000 0010 0000 static final int MASK_CHANNEL_READ_COMPLETE = 1 << 6;//channel读完成事件,二进制为 0000 0000 0100 0000 static final int MASK_USER_EVENT_TRIGGERED = 1 << 7;//触发用户自定义事件,二进制为 0000 0000 1000 0000 static final int MASK_CHANNEL_WRITABILITY_CHANGED = 1 << 8;//channel写状态变化,二进制为 0000 0001 0000 0000 static final int MASK_BIND = 1 << 9;//绑定事件,二进制为 0000 0010 0000 0000 static final int MASK_CONNECT = 1 << 10;//连接事件,二进制为 0000 0100 0000 0000 static final int MASK_DISCONNECT = 1 << 11;//断开连接事件,二进制为 0000 1000 0000 0000 static final int MASK_CLOSE = 1 << 12;//关闭连接事件,二进制为 0001 0000 0000 0000 static final int MASK_DEREGISTER = 1 << 13;//注销事件,二进制为 0010 0000 0000 0000 static final int MASK_READ = 1 << 14;//读事件,二进制为 0100 0000 0000 0000 static final int MASK_WRITE = 1 << 15;//写事件,二进制为 1000 0000 0000 0000 static final int MASK_FLUSH = 1 << 16;//冲刷事件,二进制为 0001 0000 0000 0000 0000
再回到bind方法,channelPipeline会先调用tail节点的bind方法,tail节点会先寻找上一个对于bind事件感兴趣的handler,然后执行下一个节点的invokeBind方法,源码如下:
1 public ChannelFuture bind(final SocketAddress localAddress, final ChannelPromise promise) { 2 /** 找到上一个对于bind事件感兴趣的ChannelHandlerContext */ 3 final AbstractChannelHandlerContext next = findContextOutbound(MASK_BIND); 4 /** 获取下一个ChannelHandlerContext的线程执行器 */ 5 EventExecutor executor = next.executor(); 6 /** 如果是channel绑定的EventLoop*/ 7 if (executor.inEventLoop()) { 8 //执行下一个节点的invokeBind方法 9 next.invokeBind(localAddress, promise); 10 } else { 11 /** 如果是自定义线程*/ 12 safeExecute(executor, new Runnable() { 13 @Override 14 public void run() { 15 next.invokeBind(localAddress, promise); 16 } 17 }, promise, null); 18 } 19 return promise; 20 }
bind事件会沿着ChannelPipeline直到找到HeadContext,HeadContext的bind方法会先调用JDK的bind方法绑定监听本地端口号,当channel活跃之后就调用ChannelPipeline的fireCahnnelActive()方法上报channel活跃事件,核心逻辑如下:
1 public final void bind(final SocketAddress localAddress, final ChannelPromise promise) { 2 boolean wasActive = isActive(); 3 /** 绑定监听本地地址端口号*/ 4 doBind(localAddress); 5 /** 当channel活跃之后*/ 6 if (!wasActive && isActive()) { 7 invokeLater(new Runnable() { 8 @Override 9 public void run() { 10 /** 执行pipeline的fireChannelActive()方法 */ 11 pipeline.fireChannelActive(); 12 } 13 }); 14 } 15 }
所以bind方法最终会调用底层工具绑定监听本地端口,当ServerChannel活跃之后,通知ChannelPipeline通道活跃事件channelActive,开始执行ChannelPipeline的fireChannelActive()方法
6.3、ChannelPipeline的fireChannelActive()方法的实现
channelActive事件是一个入站事件,所以会从ChannelPipeline的头节点HeadContext节点开始处理,然后依次唤醒下一个ChannelHandlerContext节点的channelActive()方法,代码如下:
1 static void invokeChannelActive(final AbstractChannelHandlerContext next) { 2 /** 获取当前节点的下一个节点的线程 */ 3 EventExecutor executor = next.executor(); 4 if (executor.inEventLoop()) { 5 /** 使用EventLoop线程之间执行*/ 6 next.invokeChannelActive(); 7 } else { 8 /** 使用非EventLoop线程执行*/ 9 executor.execute(new Runnable() { 10 @Override 11 public void run() { 12 next.invokeChannelActive(); 13 } 14 }); 15 } 16 }
ChannelPipeline会依次调用所有需要处理channelActive事件的ChannelHandler的channelActive(),HeadContext处理ChannelActive事件的方法如下:
1 public void channelActive(ChannelHandlerContext ctx) { 2 /** 执行对于的context的方法,并执行下一个context的channelActive方法 */ 3 ctx.fireChannelActive(); 4 /** 如果设置了自动读则执行*/ 5 readIfIsAutoRead(); 6 }
可以看出HeadContext再链式调用完所有的ChannelHandler的channelActive方法之后,还会判断是否设置了autoRead,如果设置了就会之间调用channel的read()方法开始尝试读取数据,而实现类AbstractChannel的read方法实际就是调用ChannelPipeline的read方法,而ChannelPipeline的read方法实现就是从tail节点开始,依次执行对于read事件感兴趣的ChannelHandler依次实现read方法,直到执行了HeadContext的read方法,最终会执行AbstractNioChannel的doBeginRead()方法,代码如下:
1 protected void doBeginRead() throws Exception { 2 // Channel.read() or ChannelHandlerContext.read() was called 3 final SelectionKey selectionKey = this.selectionKey; 4 if (!selectionKey.isValid()) { 5 return; 6 } 7 /** 设置channel监听可读OP_ACCEPT事件*/ 8 final int interestOps = selectionKey.interestOps(); 9 if ((interestOps & readInterestOp) == 0) { 10 selectionKey.interestOps(interestOps | readInterestOp); 11 } 12 }
所以最终就相当于ServerChannel开始监听OP_ACCEPT事件
6.4、EventLoop线程开启
通过上面三步了解了Netty服务器端以及初始化了ServerChannel并绑定了本地的端口号,而且还监听了OP_ACCEPT事件,这些流程和NIO的流程基本上一致。当然还有一个步骤就是通过调用Selector.select()方法来获取IO事件。
Netty中有两个线程池分别用来处理客户端连接和客户端IO事件,都是通过EventLoopGroup封装的,那么就再来看下EventLoopGroup的初始化过程。
EventLoopGroup有多个构造函数,最终都是调用到父类的构造函数如下:
1 public NioEventLoopGroup(int nThreads, Executor executor, final SelectorProvider selectorProvider, 2 final SelectStrategyFactory selectStrategyFactory) { 3 super(nThreads, executor, selectorProvider, selectStrategyFactory, RejectedExecutionHandlers.reject()); 4 }
EventLoopGroup继承之MultithreadEventLoopGroup,MultithreadEventLoopGroup又MultithraedEventExecutorGroup,所以最终会执行到MultithreadEventExecutorGroup的构造函数,核心代码如下:
1 /** 2 * @param nThreads:线程数 3 * @param exceutor:自定义线程池 4 * */ 5 protected MultithreadEventExecutorGroup(int nThreads, Executor executor, 6 EventExecutorChooserFactory chooserFactory, Object... args) { 7 if (nThreads <= 0) { 8 if (executor == null) { 9 //如果没有自定义,则创建ThreadPerTaskExecutor线程池 10 executor = new ThreadPerTaskExecutor(newDefaultThreadFactory()); 11 } 12 /** 初始化线程池 */ 13 children = new EventExecutor[nThreads]; 14 for (int i = 0; i < nThreads; i ++) { 15 boolean success = false; 16 try { 17 /** 创建NioEventLoop */ 18 children[i] = newChild(executor, args); 19 success = true; 20 } catch (Exception e) { 21 throw new IllegalStateException("failed to create a child event loop", e); 22 } 23 } 24 }
最终会创建一个指定大小的线程池,然后创建EventLoop线程,加入到线程池中,实际上叫线程池不太准确,应该叫处理IO事件的线程组。而通过newChild方法会创建EventLoop,实际上执行了NioEventLoop的构造函数。
而NioEventLoop又继承之SingleThreadEventLoop,SingleThreadEventLoop又继承之SingleThreadEventExecutor。SingleThreadEventExecutor内部有几个核心属性如下:
1 /** 需要执行的任务队列 */ 2 private final Queue<Runnable> taskQueue; 3 /** 绑定的线程 */ 4 private volatile Thread thread; 5 /** 线程池*/ 6 private final Executor executor;
所以当有Runnable对象交给EventLoop时就会执行SingleThreadEventExecutor的execute(Runnable command)方法进行执行。SingleThreadEventExecutor的execute方法,核心逻辑如下:
1 public void execute(Runnable task) { 2 /** 判断当前线程是否是EventLoop绑定的线程*/ 3 boolean inEventLoop = inEventLoop(); 4 /** 添加任务到任务队列中 */ 5 addTask(task); 6 /** 如果不是EventLoop线程,则开启当前EventLoop线程,正常情况当前线程是mian线程,所以是false */ 7 if (!inEventLoop) { 8 /** 开启当前EventLoop线程*/ 9 startThread(); 10 } 11 } 12 13 private void doStartThread() { 14 assert thread == null; 15 executor.execute(new Runnable() { 16 @Override 17 public void run() { 18 thread = Thread.currentThread(); 19 try { 20 /** 执行EventLoop线程的run方法*/ 21 SingleThreadEventExecutor.this.run(); 22 } catch (Throwable t) { 23 } 24 } 25 }); 26 }
最终调用了NioEventLoop的run方法开启线程,核心逻辑如下:
1 protected void run() { 2 /** 死循环执行 */ 3 for (;;) { 4 try { 5 /** 6 * hasTasks()方法判断当前任务队列中是否存在未处理的任务 7 * */ 8 switch (selectStrategy.calculateStrategy(selectNowSupplier, hasTasks())) { 9 case SelectStrategy.CONTINUE: 10 continue; 11 /** 如果没有任务则执行Select()方法进行IO处理*/ 12 case SelectStrategy.SELECT: 13 /** 执行Selector的select()方法*/ 14 select(wakenUp.getAndSet(false)); 15 if (wakenUp.get()) { 16 //唤醒selector 17 selector.wakeup(); 18 } 19 default: 20 } 21 //处理IO事件花费时间和处理task时间的比例,默认为50% 22 final int ioRatio = this.ioRatio; 23 if (ioRatio == 100) { 24 //如果比例为100%,则表示优先处理IO事件 25 try { 26 /** 处理IO事件 */ 27 processSelectedKeys(); 28 } finally { 29 /** 处理task任务*/ 30 runAllTasks(); 31 } 32 } else { 33 final long ioStartTime = System.nanoTime(); 34 try { 35 /** 处理IO事件 */ 36 processSelectedKeys(); 37 } finally { 38 /** 处理task任务 */ 39 final long ioTime = System.nanoTime() - ioStartTime; 40 runAllTasks(ioTime * (100 - ioRatio) / ioRatio); 41 } 42 } 43 } 44 } 45 }
当EventLoop线程开启之后会在死循环中一直处理,核心逻辑一共有三步,分别是调用Selector的select()方法,调用processSelectedKeys()方法处理IO事件,runAllTasks()执行队列中的任务
6.5、Selector的select()方法执行
1 private void select(boolean oldWakenUp) throws IOException { 2 //获取当前EventLoop的Selector 3 Selector selector = this.selector; 4 try { 5 /** select执行的次数,执行一定次数之后重启select,防止NIO的Selector的空轮询bug*/ 6 int selectCnt = 0; 7 long currentTimeNanos = System.nanoTime(); 8 long selectDeadLineNanos = currentTimeNanos + delayNanos(currentTimeNanos); 9 for (;;) { 10 /** 计算select()函数超时时间*/ 11 long timeoutMillis = (selectDeadLineNanos - currentTimeNanos + 500000L) / 1000000L; 12 if (timeoutMillis <= 0) { 13 if (selectCnt == 0) { 14 selector.selectNow(); 15 selectCnt = 1; 16 } 17 break; 18 } 19 20 //轮询中如果发现有新任务加入,则终端本次轮询 21 if (hasTasks() && wakenUp.compareAndSet(false, true)) { 22 selector.selectNow(); 23 selectCnt = 1; 24 break; 25 } 26 /** 调用select()函数获取触发IO事件的个数*/ 27 int selectedKeys = selector.select(timeoutMillis); 28 /** select()方法执行次数自增1次*/ 29 selectCnt ++; 30 31 /*** 32 * 如果selectedKeys不为空 33 * 或者被用户唤醒 34 * 或者队列中存在任务 35 * 或者存在定时任务 36 * 则中断轮询 37 */ 38 if (selectedKeys != 0 || oldWakenUp || wakenUp.get() || hasTasks() || hasScheduledTasks()) { 39 break; 40 } 41 if (Thread.interrupted()) { 42 selectCnt = 1; 43 break; 44 } 45 46 long time = System.nanoTime(); 47 if (time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos) { 48 //如果超时则次数重置为1 49 selectCnt = 1; 50 } else if (SELECTOR_AUTO_REBUILD_THRESHOLD > 0 && 51 selectCnt >= SELECTOR_AUTO_REBUILD_THRESHOLD) { 52 /** 如果select()执行次数超过上限,那么重置Selector,默认上限为512次*/ 53 rebuildSelector(); 54 selector = this.selector; 55 selector.selectNow(); 56 selectCnt = 1; 57 break; 58 } 59 currentTimeNanos = time; 60 } 61 } catch (CancelledKeyException e) { 62 } 63 }
整体过程如下:
1、通过delayNanos方法获取定时任务队列中最快执行的定时任务执行时间,如果超时则直接执行selectNow()
2、如果定时任务未到时间,则判断是否有task任务需要执行,如果有则中断任务开始执行任务
3、阻塞式调用select()方法,监听IO事件
4、每执行一次select()如果返回值等于0那么计数器+1,达到512次时重启Selector,避免JDK的NIO的空轮询死循环BUG
5、如果有IO事件,或者被用户唤醒,或者队列中有任务或者有定时任务时都跳出循环
6.6、处理所有IO事件
EventLoop线程通过Select()方法获取到存在IO事件之后,会调用processSelectedKeys()方法处理所有的SelectionKey,首先调用Selector的selectedKeys方法获取所有的SelectionKey集合,然后开始遍历处理,核心逻辑如下:
1 private void processSelectedKeysPlain(Set<SelectionKey> selectedKeys) { 2 Iterator<SelectionKey> i = selectedKeys.iterator(); 3 /** 死循环中遍历处理SelectionKey*/ 4 for (;;) { 5 final SelectionKey k = i.next(); 6 final Object a = k.attachment(); 7 i.remove(); 8 9 if (a instanceof AbstractNioChannel) { 10 processSelectedKey(k, (AbstractNioChannel) a); 11 } else { 12 NioTask<SelectableChannel> task = (NioTask<SelectableChannel>) a; 13 processSelectedKey(k, task); 14 } 15 if (!i.hasNext()) { 16 //如果处理完成则跳出循环 17 break; 18 } 19 } 20 } 21 22 private void processSelectedKey(SelectionKey k, AbstractNioChannel ch) { 23 final AbstractNioChannel.NioUnsafe unsafe = ch.unsafe(); 24 try { 25 int readyOps = k.readyOps(); 26 if ((readyOps & SelectionKey.OP_CONNECT) != 0) { 27 int ops = k.interestOps(); 28 ops &= ~SelectionKey.OP_CONNECT; 29 k.interestOps(ops); 30 /** 如果是OP_CONNECT事件则执行finishConnect()方法*/ 31 unsafe.finishConnect(); 32 } 33 if ((readyOps & SelectionKey.OP_WRITE) != 0) { 34 /** 如果OP_WRITE事件,则执行forceFlush()方法强制冲刷*/ 35 ch.unsafe().forceFlush(); 36 } 37 if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) { 38 /** 如果是OP_READ事件,则执行read()读取数据*/ 39 unsafe.read(); 40 } 41 } 42 }
这里会根据具体事件的类型,调用Channel中的unsafe对象的对应方法,而UnSafe的方法的实现实际就是调用ChannelPipeline的对应方法,将IO事件交给ChannelPipeline处理
6.7、处理EventLoop线程任务
EventLoop线程除了需要处理IO事件之后,还需要处理一些交给这个线程执行的Runnable任务以及定时任务工作,定时任务都存在Queue<Runnable> taskQueue队列中,执行runAllTasks()方法实际就是不断从队列中获取任务,并且使用当前线程直接执行即可,逻辑不复杂,不再赘述
七、Netty的高级扩展
7.1、Netty的内存池和对象池技术
7.2、Netty的零拷贝机制
参考链接:浅析操作系统和Netty中的零拷贝机制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号