如何将 Mistral OCR 应用于RAG 模型
如何将 Mistral OCR 应用于您的下一个 RAG 模型
检索增强生成(RAG)系统已成为 AI 模型的重要组成部分,能够访问大量相关数据并提供更为全面和上下文敏感的响应。然而,它们的能力主要局限于数字文本,忽视了多模态格式中的有价值信息,例如扫描的文档、图像和手写笔记。Mistral OCR 通过无缝将复杂文档集成到智能检索系统中,打破了这一限制,扩大了可用知识的范围。这一进展增强了 AI 互动,使信息在多种现实场景中更为可获取、全面和适用。本文将探讨 Mistral OCR 的功能和应用,并了解其对 RAG 系统的影响。
目录
- 了解 RAG 及其局限性
- 什么是 Mistral OCR 及其不同之处?
- Mistral OCR 如何增强 RAG
- Mistral OCR 实践:一步步指南
- Mistral 与 Gemini 2.0 Flash 与 GPT 4o
- Mistral OCR 性能基准
- Mistral OCR 的未来应用
- 常见问题解答
了解 RAG 及其局限性
RAG 模型通过检索相关文档并利用它们生成响应来工作。虽然它们在处理大量文本库方面表现出色,但在处理非文本数据时却显得力不从心。这是由于:
- 无法解释图像、方程和表格:许多重要文档包含结构化数据(如表格和方程),传统 RAG 模型无法理解。
- OCR 提取文本时的上下文损失:即使从扫描文档中提取文本,如果忽略结构和布局,其含义往往会扭曲。
- 处理多模态内容的挑战:将视觉和文本元素以有意义的方式结合起来超出了大多数传统 RAG 系统的能力。
- 跨行业适用性有限:研究、法律和金融等领域依赖复杂文档,这需要比单纯的文本理解更多的能力。
没有有效的方式从各种格式中提取和结构化信息,RAG 便显得不完整。这就是 Mistral OCR 改变游戏规则的地方。
什么是 Mistral OCR 及其不同之处?
Mistral OCR 是一个先进的光学字符识别(OCR)API,旨在做的不仅仅是提取文本。与传统的 OCR 工具不同,它能够识别文档的结构和上下文,确保所提取的信息既准确又有意义。它的精确性和性能的结合,使其成为处理大量文档的理想选择。其突出特点包括:
- 深度文档理解:不仅识别和提取文本,还能提取表格、图表、方程和交错图像,保持文档的完整性。
- 高速处理:具有每分钟处理高达 2000 页的能力,Mistral OCR 专为高吞吐量环境设计。
- 文档即提示功能:此功能允许用户将整个文档视为提示,便于准确和结构化信息提取。
- 结构化输出格式:提取的内容可以格式化为 JSON,便于集成到工作流程和 AI 应用中。
- 安全灵活的部署:对于有严格隐私政策的组织,Mistral OCR 提供自托管选项,以确保数据安全和合规。
这些能力使 Mistral OCR 成为将非结构化文档转变为 AI 准备知识源的强大工具。
Mistral OCR 如何增强 RAG
将 Mistral OCR 集成到 RAG 中,解锁了知识检索的新维度。它改善系统的方式包括:
- 将 RAG 扩展到多模态数据:通过处理扫描文档、图像和 PDF,Mistral OCR 允许 RAG 模型超越文本信息。
- 保持文档结构以提供更好上下文:Mistral OCR 维护文本、图像和结构元素之间的关系,确保提取文本的含义不会丢失。
- 加快知识检索:能够以高速处理大量文档库,确保 AI 驱动的搜索和分析保持高效且及时。
- 为行业提供 AI 准备数据:无论是法律文件、科学研究,还是客户支持文档,Mistral OCR 都有助于让知识丰富的文档更易被 AI 系统访问。
- 实现与 AI 管道的无缝集成:结构化输出允许 RAG 系统将提取的信息无缝集成到各种 AI 应用中。
Mistral OCR 实践:一步步指南
Mistral OCR 是一个强大的工具,可以从图像和扫描文档中提取结构化信息。在本节中,我们将通过一个 Python 脚本,利用 Mistral OCR 处理图像并返回结构化数据。
前提条件:访问 API
在开始测试 Mistral OCR 的步骤之前,让我们先看看如何生成所需的 API 密钥。
1. Mistral API 密钥
要访问 Mistral API 密钥,请访问 Mistral API 并注册一个 Mistral 帐户。如果您已经有帐户,只需登录即可。
登录后,点击“创建新密钥”以生成新密钥。
2. OpenAI API 密钥
要访问 OpenAI API 密钥,请访问 OpenAI 并登录您的帐户。如果您还没有 OpenAI 帐户,请注册。
登录后,点击“创建新密钥”以生成新密钥。
3. Gemini API 密钥
要访问 Gemini API 密钥,请访问 Google AI Studio 网站并登录到您的 Google 帐户。如果您没有帐户,请注册。
登录后,导航到 API 密钥部分,点击“创建 API 密钥”以生成新密钥。
现在我们已经准备好了,让我们开始实施。
步骤 1:导入依赖
脚本导入了基本库,包括:
- 从“pydantic”的 Enum 和 BaseModel
- 用于处理文件路径的 Path
- 用于编码图像文件的 base64
- 用于将语言代码映射到其全名的“pycountry”
- 用于与 OCR API 交互的 Mistral SDK
from enum import Enum
from pathlib import Path
from pydantic import BaseModel
import base64
import pycountry
from mistralai import Mistral
步骤 2:设置 Mistral OCR 客户端
脚本使用 API 密钥初始化 Mistral OCR 客户端:
api_key = "API_KEY"
client = Mistral(api_key=api_key)
languages = {lang.alpha_2: lang.name for lang in pycountry.languages if hasattr(lang, 'alpha_2')}
确保将 “API_KEY” 替换为您的实际 API 密钥。
步骤 3:定义语言处理
为了确保提取的文本带有正确的语言信息,脚本使用“pycountry”创建一个字典,将语言代码(例如 en 代表英语)映射到完整名称。
languages = {lang.alpha_2: lang.name for lang in pycountry.languages if hasattr(lang, 'alpha_2')}
class LanguageMeta(Enum.__class__):
def __new__(metacls, cls, bases, classdict):
for code, name in languages.items():
classdict[name.upper().replace(' ', '_')] = name
return super().__new__(metacls, cls, bases, classdict)
class Language(Enum, metaclass=LanguageMeta):
pass
一个 Enum 类(Language)动态生成结构化输出的语言标签。
步骤 4:定义结构化输出模型
使用“pydantic”创建一个 StructuredOCR 类,定义提取的 OCR 数据如何格式化,包括:
- file_name: 处理的图像文件名。
- topics: 从图像中检测到的主题。
- languages: 识别的语言。
- ocr_contents: 结构化格式提取的文本。
class StructuredOCR(BaseModel):
file_name: str
topics: list[str]
languages: list[Language]
ocr_contents: dict
print(StructuredOCR.schema_json())
步骤 5:使用 OCR 处理图像
structured_ocr() 函数处理核心 OCR 过程:
- 图像编码:读取图像并将其编码为 base64 字符串以发送到 API。
- OCR 处理:将图像传递给 Mistral OCR,并以 Markdown 格式检索提取的文本。
- 结构化 OCR 输出:后续请求将提取的文本转换为结构化 JSON 格式。
def structured_ocr(image_path: str) -> StructuredOCR:
image_file = Path(image_path)
assert image_file.is_file(), "The provided image path does not exist."
# 读取并编码图像文件
encoded_image = base64.b64encode(image_file.read_bytes()).decode()
base64_data_url = f"data:image/jpeg;base64,{encoded_image}"
# 使用 OCR 处理图像
image_response = client.ocr.process(document=ImageURLChunk(image_url=base64_data_url), model="mistral-ocr-latest")
image_ocr_markdown = image_response.pages[0].markdown
# 将 OCR 结果解析为结构化 JSON 响应
chat_response = client.chat.parse(
model="pixtral-12b-latest",
messages=[
{
"role": "user",
"content": [
ImageURLChunk(image_url=base64_data_url),
TextChunk(text=(
"This is the image's OCR in markdown:\n"
f"<BEGIN_IMAGE_OCR>\n{image_ocr_markdown}\n<END_IMAGE_OCR>.\n"
"Convert this into a structured JSON response with the OCR contents in a sensible dictionnary."
))
],
},
],
response_format=StructuredOCR,
temperature=0
)
return chat_response.choices[0].message.parsed
image_path = "receipt.png"
structured_response = structured_ocr(image_path)
response_dict = json.loads(structured_response.json())
json_string = json.dumps(response_dict, indent=4)
print(json_string)
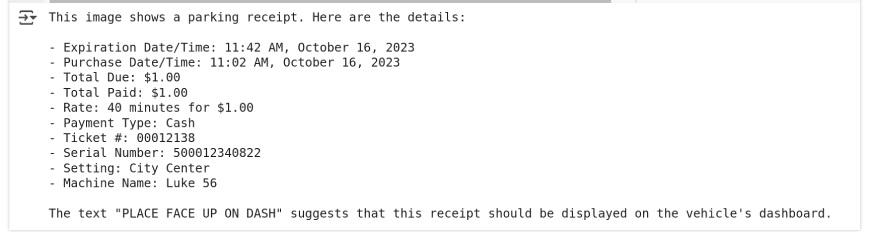
输入图像

步骤 6:运行 OCR 并查看结果
脚本调用 structured_ocr() 函数,使用图像(receipt.png),检索结构化 OCR 输出,并将其格式化为 JSON 字符串。
image_path = "receipt.png"
structured_response = structured_ocr(image_path)
response_dict = json.loads(structured_response.json())
json_string = json.dumps(response_dict, indent=4)
print(json_string)
这将以可读格式打印提取的信息,便于集成到应用程序中。
访问此处查看完整代码的版本。
Mistral 与 Gemini 2.0 Flash 与 GPT 4o
在了解了 Mistral OCR 的工作原理之后,让我们将其性能与 Gemini 2.0 Flash 和 GPT-4o 进行比较。为了确保一致和公平的比较,我们将使用与在实践部分测试 Mistral OCR 时相同的图像。目标是评估 Mistral、Gemini 2.0 和 GPT-4o 在相同输入下的表现。以下是每个模型生成的输出。
Mistral OCR 的输出:
这是我们在实践中获得的响应。

使用 Gemini 2.0 Flash 的输出:
from google import genai
from PIL import Image
# 用您的 API 密钥初始化 GenAI 客户端
client = genai.Client(api_key="AIzaSyCxpgd6KbNOwqNhMmDxskSY3alcY2NUiM0")
# 打开图像文件
image_path = "/content/download.png"
image = Image.open(image_path)
# 为模型定义提示
prompt = "Please extract and provide the text content from the image."
# 使用 Gemini 模型生成内容
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=[image, prompt]
)
# 打印提取的文本
print(response.text)
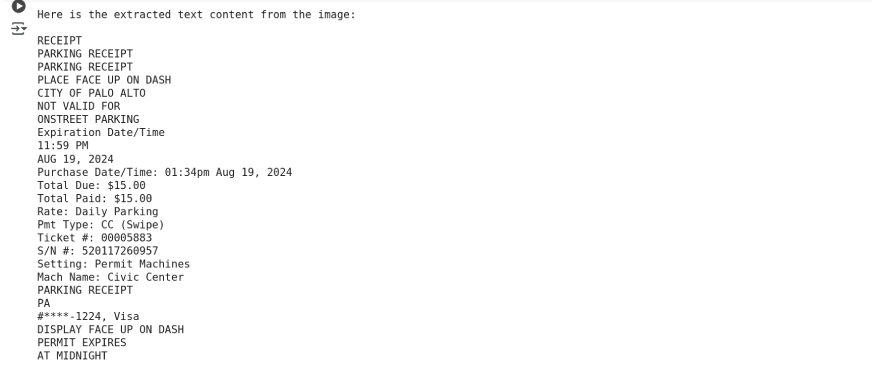
使用 GPT-4o 的输出:
当我测试 GPT-4o 时,它无法访问本地文件。因此,我提供了一个类似图像的 URL,以评估 GPT 的文本提取能力。
from openai import OpenAI
client = OpenAI(api_key="api_key")
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What's in this image?"},
{
"type": "image_url",
"image_url": {
"url": "https://preview.redd.it/11gu042ydlub1.jpg?width=640&crop=smart&auto=webp&s=8cbb551c29e76ecc31210a79a0ef6c179b7609a3",
}
},
],
}
],
max_tokens=300,
)
print(response.choices[0].message.content)
比较分析
| 标准 | Mistral OCR | GPT-4o | Gemini 2.0 Flash |
|---|---|---|---|
| API 价格 | 每千页 $ (批量推断时每美元大约能处理两倍页数) | 每百万输入token $5.00 | $0.10(文本 / 图像 / 视频) | |
| 速度 | 快 | 中等至高 | 中等 |
| 重量 | 轻量级 | 重 | 重 |
Mistral OCR 性能基准
现在,我们来看一下 Mistral OCR 在各类基准测试中表现如何。
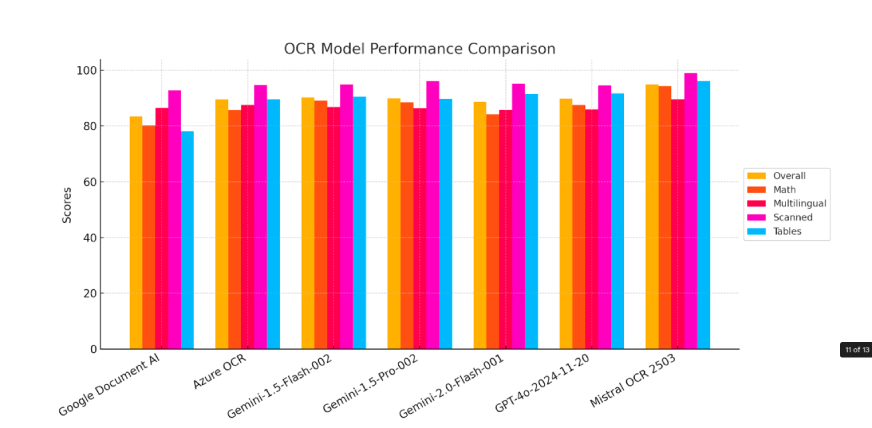
1. 标准基准
Mistral OCR 在文档分析中设定了新的标准,在严格的基准评估中始终表现优于其他领先的 OCR 模型。其先进的能力超越了简单的文本提取,可以准确识别和检索嵌入的图像和文本内容,这是许多竞争模型难以做到的。
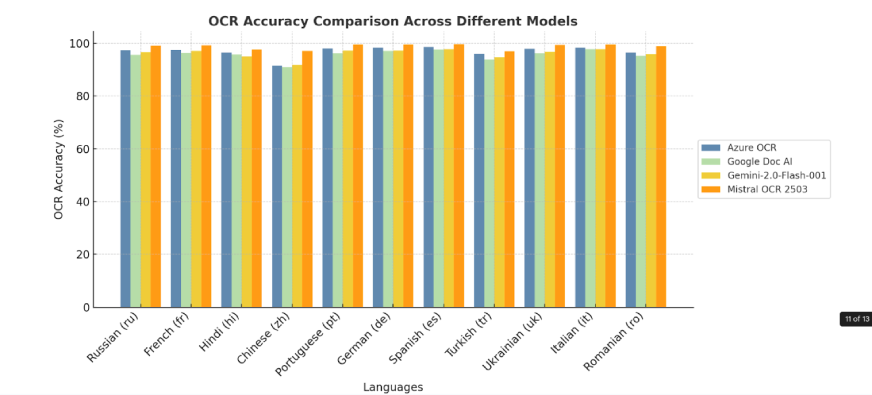
2. 按语言进行基准
Mistral OCR 在识别、解码和翻译来自全球的数千种语言、脚本和字体的能力方面设定了高标准。Mistral OCR 轻松处理各种语言结构,让翻译过程毫不遗漏,成为弥合语言差距的极有用工具。
Mistral OCR 的未来应用
Mistral OCR 有潜力通过使复杂文档更易获取和可操作,彻底改变各行各业。以下是一些关键应用:
- 数字化科学研究:研究机构可以利用 Mistral OCR 将科学文章、期刊和技术报告转化为 AI 兼容的形式。这加速了知识的共享,促进了更顺畅的合作,改善了 AI 辅助文献回顾。
- 保护历史和文化遗产:博物馆、图书馆和档案馆的历史手稿、艺术品和文化遗产可以更易于研究人员和公众访问,同时也能在长期内进行数字化保存。
- 简化客户服务:公司可以将用户指南、产品手册和常见问题转换为有组织、可搜索的知识库,从而降低响应时间,提高客户满意度。
- 让设计、教育和法律领域的文献 AI 准备:从工程蓝图到法律协议和教育内容,Mistral OCR 确保关键行业文档被索引,方便 AI 驱动的洞察和自动化时刻可用。
结论
长久以来,隐藏在复杂文档中的宝贵知识——无论是科学图表、手写手稿还是结构化报告——都与 AI 无缘。Mistral OCR 改变了这一现状,让 RAG 系统不仅仅是简单的文本检索工具,而是能够真正理解和处理各种信息的强大工具。这不仅是技术的进步,更是我们获取和分享知识的突破。通过打开曾经难以处理的文档之门,Mistral OCR 正在帮助 AI 弥合信息和理解之间的差距,使知识比以往任何时候都更容易获取。

数据科学家 | AWS 认证解决方案架构师 | AI 和 ML 创新者
作为 Analytics Vidhya 的数据科学家,我专注于机器学习、深度学习和 AI 驱动的解决方案,利用 NLP、计算机视觉和云技术构建可扩展的应用程序。
我拥有 VIT 的计算机科学(数据科学)学士学位和 AWS 认证解决方案架构师及 TensorFlow 等证书,工作内容包括生成 AI、异常检测、假新闻检测和情感识别。对创新充满热情,我致力于开发能够塑造 AI 未来的智能系统。
来源https://www.analyticsvidhya.com/blog/2025/03/mistral-ocr/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号