

Python os库 os.walk使用(详细教程、带实践)
Python os库 os.walk使用(详细教程、带实践)
-----------------------PS:env python version==3.10----------------
简介:
本文以实际案例说明os.walk对文件的使用方式。主要教学内容:
os.walk库实际的使用os.walk最佳实践- (可选)os.walk原理
- (可选)迭代器方向理解
全文2000字左右,代码字数800(含迭代器180)左右,建议学习时间10-15min(不含迭代器)。若学习迭代器建议30min+
1 模拟实际使用环境
PS:仅作为案例说明参考,若已有可用的文件夹/目录,请移步第二步
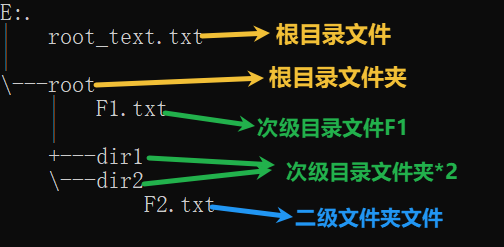
-
根据上图模拟实际使用情况:
-
随意新建一个目录(确保不会有其他文件)
-
在(新建目录的)根目录创建一个文件和文件夹(名称随意,也可以参照我的样例来)
-
进入
root文件夹,新建两个次级文件夹(dir1、dir2)- root文件夹下直接创建次级目录文件
F1.txt - 创建次级目录文件
dir1、dir2- 进入
dir2文件夹- 创建文件(
F2.txt)
- 创建文件(
- 进入
- root文件夹下直接创建次级目录文件
-
2 解析os.walk函数
面向基础讲解,详细见 os.walk官方说明
-
什么是 python 的
os库- 本模块提供了一种使用与操作系统相关的功能的便捷式途径。(如文件路径控制、文件信息获取、遍历目录文件【
os.walk】、其他系统调用功能)
- 本模块提供了一种使用与操作系统相关的功能的便捷式途径。(如文件路径控制、文件信息获取、遍历目录文件【
-
os.walk函数讲解:os.walk(top, topdown=True, onerror=None, followlinks=False)-
主要聚焦于前两个参数即可:
top:根目录路径(str)topdown:自上而下模式,默认(True)为自上而下遍历,False则从底向上遍历
-
返回值:
-
返回迭代器 ,迭代器每次生成的对象为:
(dirpath, dirnames, filenames)dirpath: 当前文件夹路径dirnames:文件夹名称filenames:文件名称 -
如果不理解迭代器,可以暂时理解为os.walk返回了 元组
(dirpath, dirnames, filenames)的列表,类似于下文 (省略双引号):[ (C:/user/, [root],[rott_text.txt] ), #根目录 (C:/user/root, [dir1,dir2],[F1.txt] ), #进入root文件夹 (C:/user/root/dir1, [],[] ), #进入dir1文件夹 (C:/user/root/dir2, [],[F2.txt] ) #dir1中没有文件了,退回上一层级,进入dir2文件夹中 #读取所有文件/文件名完毕, ]只不过他生成的特殊“列表”经常适用于for,不能直接作为列表打印,直接打印是这样子的:
#code dir_path = r'your_dir' #替换为你的文件夹 dirpath, dirnames, filenames = os.walk(dir_path) print(f'dir_path:{dirpath}\ndir_name:{dirnames}\nfile_names:{filenames}') #result: dirpath, dirnames, filenames = os.walk(dir_path) ValueError: too many values to unpack (expected 3)究其原因是返回的单个迭代器,并非三个列表元组,喜欢细究这部分的见后文,简要的话知道不能直接调用,一般结合
for调用就好,这个并非深度挖掘,看完后面会看可能有更好的理解。迭代器学习建议:【Python】从迭代器到生成器:小内存也能处理大数据
-
-
3 调用样例:
前面参数有点不好理解也没关系,只要大概知道就好了,下面是实际函数使用
- 先复制下面代码至新py文件,改一下
dir_path运行一下体会一下
import os
def walk_example(dir_path:str):
#os.walk 返回类似于三元组列表结构,然后进行遍历
for root, dir_names, file_names in os.walk(dir_path): #(dirpath, dirnames, filenames)
print(f'dirpath :{root}')
print(f'dir_names :{dir_names}')
print(f'file_names:{file_names}')
print('-'*50)
if __name__ == '__main__':
dir_path = r'your_dir_path'
walk_example(dir_path)
-
输出结果:
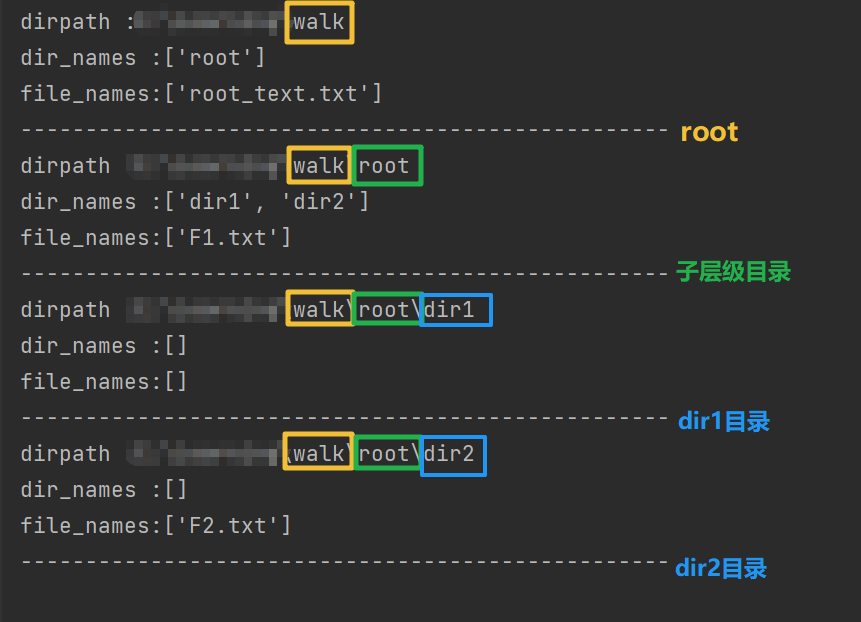
![image-20251222223407130]()
这里可以看出(默认状态下),是从顶向下,一层层遍历。
dirpath :
x:\your_path\walkdir_names :['root']
file_names:['root_text.txt']- 这里是根目录中出现的文件夹名称(root)、文件('root_text.txt')
dirpath :
x:\your_path\walk\root
dir_names :['dir1', 'dir2']
file_names:['F1.txt']- 进入了root文件夹,里面包含两个文件夹及当前文件夹根目录下的单个文件
- 后面两个同理,主要是感受每一层级的变化,每次进入下一个文件夹时,
root所表达的属性都会有所变化,变成了当前根路径。 - 除此之外,可以看到,4项的
dir_name输出,刚好是我们全部的目录名称,file_names同理
- 后面两个同理,主要是感受每一层级的变化,每次进入下一个文件夹时,
-
从上文,可以看出
os.walk函数的遍历结果会根据深入的层级输出以下信息:- 当前文件路径(str)
- 存在的文件夹(list)
- 存在的文件(list)
把他们聚合起来,就能获取我们所需要的:
- 提取文件夹信息(或处理)
- 提取文件信息(或处理)
4 实际运用案例(最佳实践)
本小节会从以下几点来说明如何通过os.walk进行文件的提取及处理。
- 提取全部信息(文件夹、文件)【理解调用方式】
- 构造文件夹中,所有文件的路径
- 根据关键字提取(文件/文件夹)路径
4.1 提取全部信息(文件夹、文件)【理解调用方式】
很简单,只要把对应全部输出收集起来,就能获得我们需要的全文件名、文件信息了。
def walk_get_all_info(dir_path:str):
'''
获取所有文件名、文件信息
:param dir_path: 输入文件夹路径
'''
dir_list = []
file_list = []
for root, dirnames, files in os.walk(dir_path):
for dir_name in dirnames:
dir_list.append(dir_name)
# print(dir_name) #不理解可以调试来一下理解一下,两者是相互独立的
for file in files:
file_list.append(file)
# print(file)
print(dir_list)
print(file_list)
if __name__ == '__main__':
dir_path = r'your_path'
walk_get_all_info(dir_path)
输出:
root
root_text.txt
dir1
dir2
F1.txt
F2.txt
4.2 构造文件夹中,所有文件的路径
通过4.1 我们知道了os.walk的迭代方式。可以通过“当前根目录”与 “所需文件名称”相结合,从而遍历所有文件的路径。
def walk_get_file_path(dir_path:str):
'''
获取文件路径
:param dir_path: 输入文件夹路径
'''
file_list = []
for root, dirnames, files in os.walk(dir_path):
print(f'local root path :{root}')
for file in files:
file_path = os.path.join(root, file) #window 上,等价于 root + "\\" + file
# file_path = root + "\\" + file
print(f'file path :{file_path}')
file_list.append(file_path)
print('-'*50)
print(file_list)
4.3 根据关键字提取文件路径
这里以最简单的关键字提取,即 if keyword in file为例。
def filter_by_key_word(dir_path,key_word:str='F1'):
'''
文件夹路径以关键字,递归查找符合关键字的文件
:param dir_path: 输入根文件夹
:param key_word: 关键字
'''
res:list = []
for root, dirnames, files in os.walk(dir_path):
for file in files:
if key_word in file:
res.append(
os.path.join(root, file)
)
print(res)
return
按照预期,就应该输出F1:
['E:\walk\root\F1.txt']
更改关键字,也可以做到筛选不同文件的功能,可以自己改一下。对files迭代改为对dirname迭代,一样能完成对文件夹的关键字提取,可以尝试一下
4.4 其他运用
能找到文件地址,后续就可以按照你想处理的方式对文件进行处理了,这个根据各自需要进行扩展就好,教程结束。
5. 部分代码:
import os
def walk_example(dir_path:str):
# walk_iter = os.walk(dir_path)
# print(walk_iter.__next__())
for root, dir_names, file_names in os.walk(dir_path): #(dirpath, dirnames, filenames)
print(f'dirpath :{root}')
print(f'dir_names :{dir_names}')
print(f'file_names:{file_names}')
print('-'*50)
def walk_get_file_path(dir_path:str):
'''
获取文件路径
:param dir_path: 输入文件夹路径
'''
file_list = []
for root, dirnames, files in os.walk(dir_path):
print(f'local root path :{root}')
for file in files:
file_path = os.path.join(root, file) #window 上,等价于 root + "\\" + file
# file_path = root + "\\" + file
print(f'file path :{file_path}')
file_list.append(file_path)
print('-'*50)
print(file_list)
return
def filter_by_key_word(dir_path,key_word:str='F1'):
'''
文件夹路径以关键字,递归查找符合关键字的文件
:param dir_path: 输入根文件夹
:param key_word: 关键字
'''
res:list = []
for root, dirnames, files in os.walk(dir_path):
for file in files:
if key_word in file:
res.append(
os.path.join(root, file)
)
print(res)
return
if __name__ == '__main__':
dir_path = r'your_path'
# walk_example(dir_path)
# walk_get_file_path(dir_path)
filter_by_key_word(dir_path)
6 迭代器相关(非必须)
建议先去学习一下什么是迭代器,再看这个演示代码,对os.walk理解会更深,这边还是建议学一下的,如果够时间的话,趁学os.walk多学一个迭代器/生成器,何乐而不为呢,函数讲解塞里面了,就这样吧。
def iter_example(dir_path:str):
'''
迭代器理解代码
:param dir_path:
'''
#我没记错的话,是要有__next__ 和 __iter__ 类方法,才能是迭代器类
walk_iter = os.walk(dir_path)
print(walk_iter.__next__()) #获取迭代器的下一个元素,一般都用next访问下一个元素
print(walk_iter.__iter__()) #获取迭代器本身,这里os.walk返回的是generator object,本质上也是迭代器,不太能获取当前迭代器的元素噢!
print(next(walk_iter)) #相同写法
print('#'*25+"分隔符"+'#'*25)
count = 0
while True:
count += 1
try:
print(f'next element:{walk_iter.__next__()}')
print("-"*50 + f"{count}")
except Exception as e: #无可迭代对象后,会raise一个StopIteration Error
# print('finish iter, break')
# break #常规循环退出机制
raise e

 浙公网安备 33010602011771号
浙公网安备 33010602011771号