TCP三次握手源码解析与系统调用跟踪
TCP三次握手源码解析与系统调用跟踪
〇,概念介绍
作为面向连接的端到端传输协议,TCP协议在数据传输之前需要事先建立端到端的传输链路。通常情况下,我们将TCP协议中,建立端到端链路的过程形象地称为三次握手,其大致机制如下图所示:
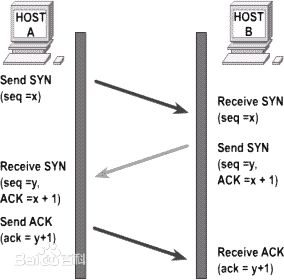
而通过上一篇文章对于socket系统调用的跟踪和到目前为止的几次实验探究,我们已经可以确定,在三次握手阶段,系统依次调用sys_connect和sys_accept函数建立链路。而具体到TCP的三次握手中,这两个函数又各自调用了什么函数,又是如何一步步生成报文和发送并接受报文的,这就是我们这次实验的目的。
本次实验首先从socket调用入手,根据linux源码一步步分析三次握手中每一阶段所调用的函数的次序和功能,再根据对源码的分析结果,设置断点,通过qemu跟踪系统的内核调用来证明我们的猜测。
一,TCP接口跟踪
我们首先对三次握手中的socket调用进行分析:
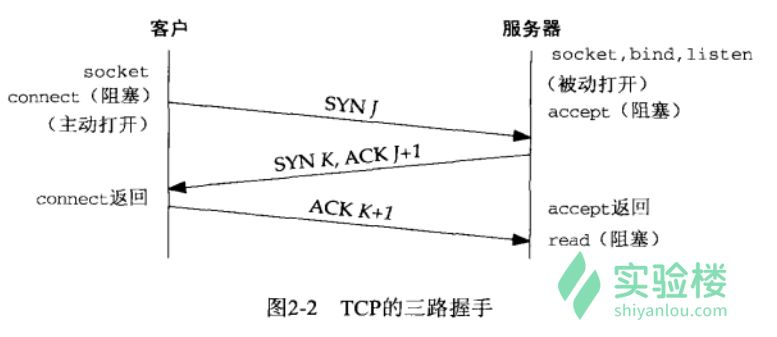
根据上次实验的内容,我们不难定位到系统调用__sys_connect和__sys_accept,以__sys_connect为例,我们分析这一系统调用的源代码(linux/net/socket.c):
1 int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen) 2 { 3 struct socket *sock; 4 ... 5 //通过函数指针实际调用不同协议对应的函数 6 err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen, 7 sock->file->f_flags); 8 ... 9 return err; 10 }
我们继续寻根溯源,去查看socket结构体的源代码(linux/net.h):
1 struct socket { 2 socket_state state; // 连接状态:SS_CONNECTING, SS_CONNECTED 等 3 short type; // 类型:SOCK_STREAM, SOCK_DGRAM 等 4 unsigned long flags; // 标志位:SOCK_ASYNC_NOSPACE(发送队列是否已满)等 5 struct socket_wq __rcu *wq; // 等待队列 6 struct file *file; // 该socket结构体对应VFS中的file指针 7 struct sock *sk; // socket网络层表示,真正处理网络协议的地方 8 const struct proto_ops *ops; // socket操作函数集:bind, connect, accept 等 9 };
1 struct proto_ops { 2 ... 3 int (*connect) (struct socket *sock, 4 struct sockaddr *vaddr, 5 int sockaddr_len, int flags); 6 ... 7 int (*accept) (struct socket *sock, 8 struct socket *newsock, int flags, bool kern); 9 ... 10 };
具体这些函数指针会指向哪个函数,则是在创建socket时指定的,这一部分的工作则有sys_socket完成,具体到TCP协议中,我们找到了如下的源代码(linux/net/ipv4/tcp_ipv4):
1 2 3 struct proto tcp_prot = { 4 .name = "TCP", 5 .owner = THIS_MODULE, 6 .close = tcp_close, 7 .pre_connect = tcp_v4_pre_connect, 8 .connect = tcp_v4_connect, 9 .disconnect = tcp_disconnect, 10 .accept = inet_csk_accept, 11 .ioctl = tcp_ioctl, 12 .init = tcp_v4_init_sock, 13 .destroy = tcp_v4_destroy_sock, 14 .shutdown = tcp_shutdown, 15 .setsockopt = tcp_setsockopt, 16 .getsockopt = tcp_getsockopt, 17 .keepalive = tcp_set_keepalive, 18 .recvmsg = tcp_recvmsg, 19 .sendmsg = tcp_sendmsg, 20 .sendpage = tcp_sendpage, 21 .backlog_rcv = tcp_v4_do_rcv, 22 .release_cb = tcp_release_cb, 23 ... 24 }; 25 EXPORT_SYMBOL(tcp_prot);
至此我们最终找到了TCP下connect所调用的函数接口,接下来就可以对各个函数的源代码进行分析。按照如上所示的方法,我们依次明确三次握手中所调用的函数的位置与次序,结果如下图所示:
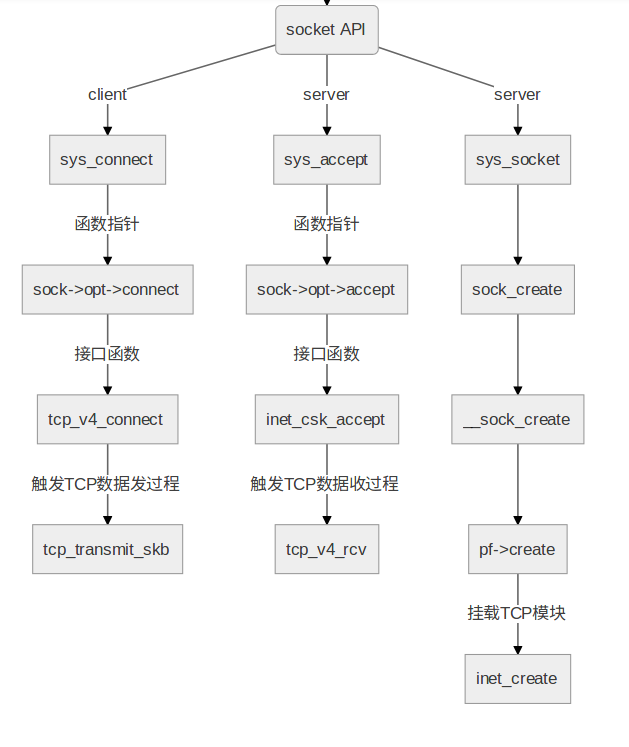
此外,在后续的代码分析阶段,我们发现tcp协议在运行阶段维持一个状态机,即根据不同的状态调用不同的函数或进行不同的处理,因此,我们在此也有必要给出tcp状态机的状态转移图:
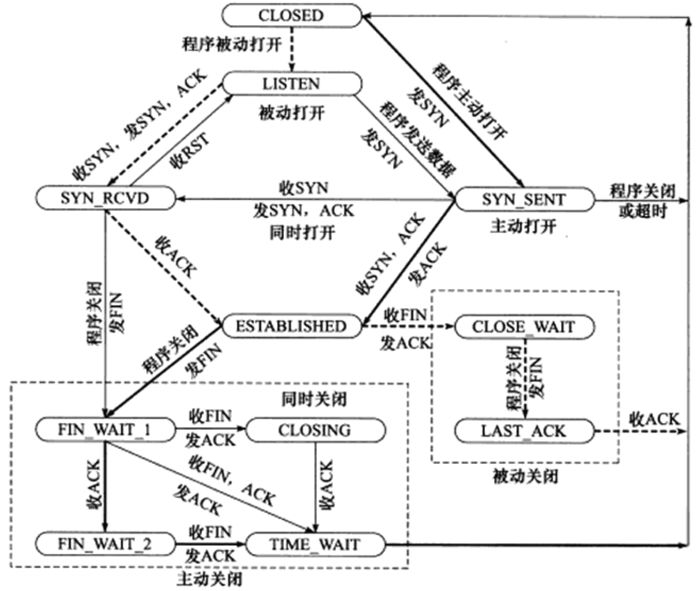
二,客户端发起SYN请求
TCP的三次握手一般由客户端通过connect发起,因此我们先来分析tcp_v4_connect的源代码:
140/* This will initiate an outgoing connection. */ 141int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len) 142{ ... 171 rt = ip_route_connect(fl4, nexthop, inet->inet_saddr, 172 RT_CONN_FLAGS(sk), sk->sk_bound_dev_if, 173 IPPROTO_TCP, 174 orig_sport, orig_dport, sk); ... 215 /* Socket identity is still unknown (sport may be zero). 216 * However we set state to SYN-SENT and not releasing socket 217 * lock select source port, enter ourselves into the hash tables and 218 * complete initialization after this. 219 */ 220 tcp_set_state(sk, TCP_SYN_SENT); ... 227 rt = ip_route_newports(fl4, rt, orig_sport, orig_dport, 228 inet->inet_sport, inet->inet_dport, sk); ... 246 err = tcp_connect(sk); ... 264} 265EXPORT_SYMBOL(tcp_v4_connect);
上述代码的逻辑十分清晰:首先通过ip_route_connect和ip_route_newports函数调用ip层的相关代码提供底层服务,然后通过tcp_set_state函数将状态修改为TCP_SYN_SENT,最后由tcp_connect发送SYN包。对此,我们接着分析tcp_connect函数的源代码:
3090/* Build a SYN and send it off. */ 3091int tcp_connect(struct sock *sk) 3092{ ... 3111 tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN); 3112 tp->retrans_stamp = tcp_time_stamp; 3113 tcp_connect_queue_skb(sk, buff); 3114 tcp_ecn_send_syn(sk, buff); 3115 3116 /* Send off SYN; include data in Fast Open. */ 3117 err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) : 3118 tcp_transmit_skb(sk, buff, 1, sk->sk_allocation); 3119 if (err == -ECONNREFUSED) 3120 return err; 3121 3122 /* We change tp->snd_nxt after the tcp_transmit_skb() call 3123 * in order to make this packet get counted in tcpOutSegs. 3124 */ 3125 tp->snd_nxt = tp->write_seq; 3126 tp->pushed_seq = tp->write_seq; 3127 TCP_INC_STATS(sock_net(sk), TCP_MIB_ACTIVEOPENS); 3128 3129 /* Timer for repeating the SYN until an answer. */ 3130 inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS, 3131 inet_csk(sk)->icsk_rto, TCP_RTO_MAX); 3132 return 0; 3133}
可以看到,在tcp_connect中,首先调用tcp_init_nondata_skb函数构建携带SYN标志的首部,然后再通过tcp_transmit_skb函数进行发送,最后还通过inet_csk_reset_xmit_timer函数设置了重传定时器,这部分代码的关键则在于tcp_transmit_skb函数:
876/* This routine actually transmits TCP packets queued in by 877 * tcp_do_sendmsg(). This is used by both the initial 878 * transmission and possible later retransmissions. 879 * All SKB's seen here are completely headerless. It is our 880 * job to build the TCP header, and pass the packet down to 881 * IP so it can do the same plus pass the packet off to the 882 * device. 883 * 884 * We are working here with either a clone of the original 885 * SKB, or a fresh unique copy made by the retransmit engine. 886 */ 887static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it, 888 gfp_t gfp_mask) 889{ ... 1012 err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl); ... 1020}
如上所示,tcp_transmit_skb函数继续调用icsk->icsk_af_ops->queue_xmit这一函数指针,而这一函数实际上是初始化时ip层向上提供的借口,通过调用这一借口,tcp协议将已经构建好的报文向下传递,至此,在传输层第一次握手的相关工作已经完成。
三,服务器端接受SYN报文并响应 不同于第一次握手是由客户端主动发起,第二次握手前,服务器端已经通过bind和listen绑定端口进行监听,并由accept函数在该端口阻塞等待,相应的函数为inet_csk_accept:
1 /* 2 * This will accept the next outstanding connection. 3 */ 4 //sk为监听套接字传输控制块 5 struct sock *inet_csk_accept(struct sock *sk, int flags, int *err) 6 { 7 struct inet_connection_sock *icsk = inet_csk(sk); 8 struct sock *newsk; 9 int error; 10 11 lock_sock(sk); 12 //传入到的套接字的TCB状态必须是TCP_LISTEN 13 /* We need to make sure that this socket is listening, 14 * and that it has something pending. 15 */ 16 error = -EINVAL; 17 if (sk->sk_state != TCP_LISTEN) 18 goto out_err; 19 20 //如果监听套接字的accept接收队列为空,则需要根据当前套接字是否阻塞进行操作 21 /* Find already established connection */ 22 if (reqsk_queue_empty(&icsk->icsk_accept_queue)) { 23 //根据是否阻塞决定一个超时值,如果为非阻塞模式,那么timeo将为0 24 long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK); 25 26 //对于非阻塞模式,直接返回重试错误 27 /* If this is a non blocking socket don't sleep */ 28 error = -EAGAIN; 29 if (!timeo) 30 goto out_err; 31 //休眠等待accept接收队列非空 32 error = inet_csk_wait_for_connect(sk, timeo); 33 if (error) 34 goto out_err; 35 } 36 //到这里,说明当前accept队列已经有连接可以接收(可能是阻塞后被唤醒的) 37 newsk = reqsk_queue_get_child(&icsk->icsk_accept_queue, sk); 38 BUG_TRAP(newsk->sk_state != TCP_SYN_RECV); 39 out: 40 release_sock(sk); 41 return newsk; 42 out_err: 43 newsk = NULL; 44 *err = error; 45 goto out; 46 }
由上述代码不难看出,阻塞模式下,程序的执行会转入inet_csk_wait_for_connect函数:
1 /* 2 * Wait for an incoming connection, avoid race conditions. This must be called 3 * with the socket locked. 4 */ 5 static int inet_csk_wait_for_connect(struct sock *sk, long timeo) 6 { 7 struct inet_connection_sock *icsk = inet_csk(sk); 8 DEFINE_WAIT(wait); 9 ... 10 for (;;) { 11 prepare_to_wait_exclusive(sk_sleep(sk), &wait, 12 TASK_INTERRUPTIBLE); 13 release_sock(sk); 14 if (reqsk_queue_empty(&icsk->icsk_accept_queue)) 15 timeo = schedule_timeout(timeo); 16 lock_sock(sk); 17 err = 0; 18 if (!reqsk_queue_empty(&icsk->icsk_accept_queue)) 19 break; 20 err = -EINVAL; 21 if (sk->sk_state != TCP_LISTEN) 22 break; 23 err = sock_intr_errno(timeo); 24 if (signal_pending(current)) 25 break; 26 err = -EAGAIN; 27 if (!timeo) 28 break; 29 } 30 finish_wait(sk_sleep(sk), &wait); 31 return err; 32 }
可以看到,代码的逻辑非常清晰,就是通过for(;;)进入死循环,当接收到来自客户端的带有SYN标志的报文时,即accept队列非空时( if (!reqsk_queue_empty(&icsk->icsk_accept_queue)) ),跳出循环,返回inet_csk_accept函数继续执行。那么,tcp又是如何接收报文并放入accept队列的呢?我们找到了如下代码:
1 /* thinking of making this const? Don't. 2 * early_demux can change based on sysctl. 3 */ 4 static struct net_protocol tcp_protocol = { 5 .early_demux = tcp_v4_early_demux, 6 .early_demux_handler = tcp_v4_early_demux, 7 .handler = tcp_v4_rcv, 8 .err_handler = tcp_v4_err, 9 .no_policy = 1, 10 .netns_ok = 1, 11 .icmp_strict_tag_validation = 1, 12 };
从这部分代码中,我们可以推测这个函数是tcp协议中负责接收处理数据的入口,为了证实我们的推测,我们可以查阅源代码:
1 /* 2 * From tcp_input.c 3 */ 4 5 int tcp_v4_rcv(struct sk_buff *skb) 6 { 7 //查找对应的套接字 8 lookup: 9 sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source, 10 th->dest, sdif, &refcounted); 11 if (!sk) 12 goto no_tcp_socket; 13 //根据套接字的状态进行处理,此时处于TCP_LISTEN 14 process: 15 ... 16 if (sk->sk_state == TCP_LISTEN) { 17 ret = tcp_v4_do_rcv(sk, skb); 18 goto put_and_return; 19 } 20 ... 21 put_and_return: 22 if (refcounted) 23 sock_put(sk); 24 25 return ret; 26 ... 27 }
根据上述代码,继续查看tcp_v4_do_rcv函数:
1 /* The socket must have it's spinlock held when we get 2 * here, unless it is a TCP_LISTEN socket. 3 * 4 * We have a potential double-lock case here, so even when 5 * doing backlog processing we use the BH locking scheme. 6 * This is because we cannot sleep with the original spinlock 7 * held. 8 */ 9 int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb) 10 { 11 struct sock *rsk; 12 ... 13 if (sk->sk_state == TCP_LISTEN) { 14 struct sock *nsk = tcp_v4_cookie_check(sk, skb); 15 //返回NULL:出错 16 //nsk == sk:没有找到新的TCB,所以收到的是第一次握手的SYN 17 //nsk != SK: 找到了新的TCB,所以收到的是第三次握手的ACK 18 if (!nsk) 19 goto discard; 20 if (nsk != sk) { 21 if (tcp_child_process(sk, nsk, skb)) { 22 rsk = nsk; 23 goto reset; 24 } 25 return 0; 26 } 27 } else 28 sock_rps_save_rxhash(sk, skb); 29 //收到的TCP报文由该函数根据TCP的状态处理 30 if (tcp_rcv_state_process(sk, skb)) { 31 rsk = sk; 32 goto reset; 33 } 34 return 0; 35 //请求重传 36 reset: 37 tcp_v4_send_reset(rsk, skb); 38 ... 39 } 40 EXPORT_SYMBOL(tcp_v4_do_rcv);
通过网络搜集资料,我们可以解读上述代码的大致逻辑。这里有一点比较有意思:只有在第二次握手时,服务器端的tcp协议才不会调用tcp_child_process,这一点可以尝试在后续的内核调用跟踪阶段进行追踪,也可以用来进一步验证三次握手的具体过程。我们接着来看tcp_v4_send_reset函数的源代码:
1 /* 2 * This function implements the receiving procedure of RFC 793 for 3 * all states except ESTABLISHED and TIME_WAIT. 4 * It's called from both tcp_v4_rcv and tcp_v6_rcv and should be 5 * address independent. 6 */ 7 8 int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) 9 { 10 ... 11 switch (sk->sk_state) { 12 ... 13 case TCP_LISTEN: 14 //此函数只处理SYN报文段,如果ACK置为,说明收到的是非预期的报文, 15 //返回1会导致向对端回复RST报文 16 if (th->ack) 17 return 1; 18 //收到RST报文,只是忽略该报文 19 if (th->rst) 20 goto discard; 21 22 if (th->syn) { 23 //收到了SYN报文 25 ... 26 acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0; 27 ... 28 } 29 ... 30 }
在此处我们终于看到此处出现的 icsk->icsk_af_ops->conn_request 与之前的 icsk->icsk_accept_queue都调用了同一结构体,我们的猜测接近被证实,我们接着找到了如下代码:
1 const struct inet_connection_sock_af_ops ipv4_specific = { 2 .queue_xmit = ip_queue_xmit, 3 .send_check = tcp_v4_send_check, 4 .rebuild_header = inet_sk_rebuild_header, 5 .sk_rx_dst_set = inet_sk_rx_dst_set, 6 .conn_request = tcp_v4_conn_request, 7 .syn_recv_sock = tcp_v4_syn_recv_sock, 8 .net_header_len = sizeof(struct iphdr), 9 .setsockopt = ip_setsockopt, 10 .getsockopt = ip_getsockopt, 11 .addr2sockaddr = inet_csk_addr2sockaddr, 12 .sockaddr_len = sizeof(struct sockaddr_in), 13 #ifdef CONFIG_COMPAT 14 .compat_setsockopt = compat_ip_setsockopt, 15 .compat_getsockopt = compat_ip_getsockopt, 16 #endif 17 .mtu_reduced = tcp_v4_mtu_reduced, 18 }; 19 EXPORT_SYMBOL(ipv4_specific);
可以看到, icsk->icsk_af_ops->conn_request也是一个函数指针,我们继续查看这个函数tcp_v4_conn_request,而该函数中,接着有调用了tcp_conn_request:
1 int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb) 2 { 3 /* Never answer to SYNs send to broadcast or multicast */ 4 if (skb_rtable(skb)->rt_flags & (RTCF_BROADCAST | RTCF_MULTICAST)) 5 goto drop; 6 7 return tcp_conn_request(&tcp_request_sock_ops, 8 &tcp_request_sock_ipv4_ops, sk, skb); 9 10 drop: 11 tcp_listendrop(sk); 12 return 0; 13 } 14 EXPORT_SYMBOL(tcp_v4_conn_request);
事实上,tcp_conn_request函数为syn请求的核心处理流程,我们暂且忽略其中的syn cookies和fastopen相关流程,其核心功能为分析请求参数,新建连接请求控制块,注意,新建请求控制操作中会将连接状态更新为TCP_NEW_SYN_RECV ,并初始化相关成员,初始化完毕之后,加入到半连接队列accept queue中,然后恢复syn+ack包给客户端。我们所需要关注的内容如下:
1 int tcp_conn_request(struct request_sock_ops *rsk_ops, 2 const struct tcp_request_sock_ops *af_ops, 3 struct sock *sk, struct sk_buff *skb) 4 { 5 /* 6 注意: 这个函数将连接状态更新为TCP_NEW_SYN_RECV 7 */ 8 req = inet_reqsk_alloc(rsk_ops, sk, !want_cookie); 9 ... 10 11 if (fastopen_sk) { 12 /* 发送syn+ack */ 13 af_ops->send_synack(fastopen_sk, dst, &fl, req, 14 &foc, TCP_SYNACK_FASTOPEN); 15 /* Add the child socket directly into the accept queue */ 16 if (!inet_csk_reqsk_queue_add(sk, req, fastopen_sk)) { 17 reqsk_fastopen_remove(fastopen_sk, req, false); 18 bh_unlock_sock(fastopen_sk); 19 sock_put(fastopen_sk); 20 goto drop_and_free; 21 } 22 sk->sk_data_ready(sk); 23 bh_unlock_sock(fastopen_sk); 24 sock_put(fastopen_sk); 25 } else { 26 tcp_rsk(req)->tfo_listener = false; 27 if (!want_cookie) 28 inet_csk_reqsk_queue_hash_add(sk, req, 29 tcp_timeout_init((struct sock *)req)); 30 /* 发送syn+ack */ 31 af_ops->send_synack(sk, dst, &fl, req, &foc, 32 !want_cookie ? TCP_SYNACK_NORMAL : 33 TCP_SYNACK_COOKIE); 34 if (want_cookie) { 35 reqsk_free(req); 36 return 0; 37 } 38 } 39 ... 40 }
最后我们查看一下inet_csk_reqsk_queue_add以及inet_csk_reqsk_queue_hash_add函数,结果与我们的预期相符:
1 void inet_csk_reqsk_queue_hash_add(struct sock *sk, struct request_sock *req, 2 unsigned long timeout) 3 { 4 reqsk_queue_hash_req(req, timeout); 5 inet_csk_reqsk_queue_added(sk); 6 }
1 static inline void inet_csk_reqsk_queue_added(struct sock *sk) 2 { 3 reqsk_queue_added(&inet_csk(sk)->icsk_accept_queue); 4 }
至此第二次握手的全部流程已经理清:在绑定端口并进行监听后,socket进入listen状态并调用accept阻塞等待,当底层受到来自客户端的第一个SYN报文后,通过.handler指针调用tcp_v4_rcv,此后依次调用tcp_v4_do_rcv ,tcp_v4_conn_request,tcp_conn_request最后依次改变套接字状态,将报文放入accept队列,回复SYN+ACK报文,完成第二次握手。
四,客户端接收SYN+ACK报文并响应 发送SYN请求报文后,TCB的状态由TCP_CLOSE迁移到TCP_SYN_SENT,所以依据上一小节的分析,在收到SYN+ACK报文后,将由tcp_rcv_state_process()处理:
1 ... 2 case TCP_SYN_SENT: 3 tp->rx_opt.saw_tstamp = 0; 4 tcp_mstamp_refresh(tp); 5 queued = tcp_rcv_synsent_state_process(sk, skb, th); 6 if (queued >= 0) 7 return queued; 8 9 /* Do step6 onward by hand. */ 10 tcp_urg(sk, skb, th); 11 __kfree_skb(skb); 12 tcp_data_snd_check(sk); 13 return 0; 14 } 15 ...
此处不难看出,程序接下来转入tcp_rcv_synsent_state_process函数:
1 static int tcp_rcv_synsent_state_process(struct sock *sk, struct sk_buff *skb, 2 const struct tcphdr *th) 3 { 4 ... 5 if (th->ack) { 6 /* rfc793: 7 * "If the state is SYN-SENT then 8 * first check the ACK bit 9 * If the ACK bit is set 10 * If SEG.ACK =< ISS, or SEG.ACK > SND.NXT, send 11 * a reset (unless the RST bit is set, if so drop 12 * the segment and return)" 13 */ 14 15 //判断序号区间 16 if (!after(TCP_SKB_CB(skb)->ack_seq, tp->snd_una) || 17 after(TCP_SKB_CB(skb)->ack_seq, tp->snd_nxt)) 18 goto reset_and_undo; 19 ... 20 21 /* Now ACK is acceptable. 22 * 23 * "If the RST bit is set 24 * If the ACK was acceptable then signal the user "error: 25 * connection reset", drop the segment, enter CLOSED state, 26 * delete TCB, and return." 27 */ 28 29 //判断重传标志 30 if (th->rst) { 31 tcp_reset(sk);//重传 32 goto discard;//丢弃当前报文 33 } 34 35 /* rfc793: 36 * "fifth, if neither of the SYN or RST bits is set then 37 * drop the segment and return." 38 * 39 * See note below! 40 * --ANK(990513) 41 */ 42 //既不要求重传也不是对之前SYN的确认,丢弃该报文,重传 43 if (!th->syn) 44 goto discard_and_undo; 45 46 /* rfc793: 47 * "If the SYN bit is on ... 48 * are acceptable then ... 49 * (our SYN has been ACKed), change the connection 50 * state to ESTABLISHED..." 51 */ 52 53 //确认收到的报文是对之前SYN报文的确认报文 54 55 tcp_ecn_rcv_synack(tp, th); 56 57 tcp_init_wl(tp, TCP_SKB_CB(skb)->seq); 58 tcp_try_undo_spurious_syn(sk); 59 tcp_ack(sk, skb, FLAG_SLOWPATH); 60 61 /* Ok.. it's good. Set up sequence numbers and 62 * move to established. 63 */ 64 //为当前连接选择一个其实序列号并前将套接字状态转为ESTABLISHED 65 WRITE_ONCE(tp->rcv_nxt, TCP_SKB_CB(skb)->seq + 1); 66 tp->rcv_wup = TCP_SKB_CB(skb)->seq + 1; 67 ... 68 69 discard: 70 tcp_drop(sk, skb); 71 return 0; 72 } else { 73 //发送ACK报文,第二次握手完成 74 tcp_send_ack(sk); 75 } 76 return -1; 77 } 78 79 /* No ACK in the segment */ 80 }
上述代码中通过一系列判断确定当前收到的报文就是对之前的SYN请求的确认报文,然后修改套接字的状态,并调用tcp_send_ack函数发送ACK报文:
1 /* This routine sends an ack and also updates the window. */ 2 void __tcp_send_ack(struct sock *sk, u32 rcv_nxt) 3 { 4 struct sk_buff *buff; 5 6 /* If we have been reset, we may not send again. */ 7 if (sk->sk_state == TCP_CLOSE) 8 return; 9 10 /* We are not putting this on the write queue, so 11 * tcp_transmit_skb() will set the ownership to this 12 * sock. 13 */ 14 buff = alloc_skb(MAX_TCP_HEADER, 15 sk_gfp_mask(sk, GFP_ATOMIC | __GFP_NOWARN)); 16 if (unlikely(!buff)) { 17 inet_csk_schedule_ack(sk); 18 inet_csk(sk)->icsk_ack.ato = TCP_ATO_MIN; 19 inet_csk_reset_xmit_timer(sk, ICSK_TIME_DACK, 20 TCP_DELACK_MAX, TCP_RTO_MAX); 21 return; 22 } 23 24 /* Reserve space for headers and prepare control bits. */ 25 skb_reserve(buff, MAX_TCP_HEADER); 26 tcp_init_nondata_skb(buff, tcp_acceptable_seq(sk), TCPHDR_ACK); 27 28 /* We do not want pure acks influencing TCP Small Queues or fq/pacing 29 * too much. 30 * SKB_TRUESIZE(max(1 .. 66, MAX_TCP_HEADER)) is unfortunately ~784 31 */ 32 skb_set_tcp_pure_ack(buff); 33 34 /* Send it off, this clears delayed acks for us. */ 35 __tcp_transmit_skb(sk, buff, 0, (__force gfp_t)0, rcv_nxt); 36 } 37 EXPORT_SYMBOL_GPL(__tcp_send_ack); 38 39 void tcp_send_ack(struct sock *sk) 40 { 41 __tcp_send_ack(sk, tcp_sk(sk)->rcv_nxt); 42 }
最终通过__tcp_transmit_skb函数调用icsk->icsk_af_ops->queue_xmit函数向下传递报文,与之前发送SYN报文一致( tcp_transmit_skb -> __tcp_transmit_skb -> icsk->icsk_af_ops->queue_xmit )。以上即为客户端第三次握手的过程。
五,服务器端接收ACK报文 最后服务器端还需要接受ACK报文并进入到ESTABLISHED状态,三次握手才算最终完成。由之前的内容,我们从tcp_v4_rcv开始进行分析:
1 int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb) 2 { 3 struct sock *rsk; 4 5 if (sk->sk_state == TCP_LISTEN) { 6 //返回NULL:出错,丢弃数据包 7 //nsk == sk:收到的是第一次握手的SYN 8 //NSK != SK: 收到的是第三次握手的ACK 9 struct sock *nsk = tcp_v4_hnd_req(sk, skb); 10 if (!nsk) 11 goto discard; 12 13 if (nsk != sk) { 14 //收到ACK报文会调用该函数 15 if (tcp_child_process(sk, nsk, skb)) { 16 rsk = nsk; 17 goto reset; 18 } 19 return 0; 20 } 21 } 22 reset: 23 tcp_v4_send_reset(rsk, skb); 24 }
这里有一点值得注意,为什么我们进入的分支是 sk->sk_state == TCP_LISTEN?实际上,此时接收ACK报文的套接字是绑定在这一端口的监听套接字,该套接字始终处于LISTEN状态。当该套接字接收到报文时,就通过tcp_v4_hnd_req来判断报文,如果收到的是第一次握手中的SYN报文,程序会在接下来的过程中生成一个新的套接字,当第三次握手中收到来自同一客户端的ACK报文,tcp_v4_hnd_req返回的就是上次生成的套接字。这也就是为什么接下来程序会进入 if (nsk != sk) 分支。
理清以上过程后,我们接着来看tcp_child_process函数:
1 int tcp_child_process(struct sock *parent, struct sock *child, 2 struct sk_buff *skb) 3 { 4 int ret = 0; 5 int state = child->sk_state; 6 7 /* record NAPI ID of child */ 8 sk_mark_napi_id(child, skb); 9 10 tcp_segs_in(tcp_sk(child), skb); 11 if (!sock_owned_by_user(child)) { 12 ret = tcp_rcv_state_process(child, skb); 13 /* Wakeup parent, send SIGIO */ 14 if (state == TCP_SYN_RECV && child->sk_state != state) 15 parent->sk_data_ready(parent); 16 } else { 17 /* Alas, it is possible again, because we do lookup 18 * in main socket hash table and lock on listening 19 * socket does not protect us more. 20 */ 21 __sk_add_backlog(child, skb); 22 } 23 24 bh_unlock_sock(child); 25 sock_put(child); 26 return ret; 27 } 28 EXPORT_SYMBOL(tcp_child_process);
很好,又见到我们的老朋友tcp_recv_state_process了:
1 ... 2 case TCP_SYN_RECV: 3 tp->delivered++; /* SYN-ACK delivery isn't tracked in tcp_ack */ 4 if (!tp->srtt_us) 5 tcp_synack_rtt_meas(sk, req); 6 7 if (req) { 8 tcp_rcv_synrecv_state_fastopen(sk); 9 } else { 10 tcp_try_undo_spurious_syn(sk); 11 tp->retrans_stamp = 0; 12 tcp_init_transfer(sk, BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB); 13 WRITE_ONCE(tp->copied_seq, tp->rcv_nxt); 14 } 15 smp_mb(); 16 //转入ESTABLISHED状态 17 tcp_set_state(sk, TCP_ESTABLISHED); 18 sk->sk_state_change(sk); 19 20 /* Note, that this wakeup is only for marginal crossed SYN case. 21 * Passively open sockets are not waked up, because 22 * sk->sk_sleep == NULL and sk->sk_socket == NULL. 23 */ 24 if (sk->sk_socket) 25 sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT); 26 27 tp->snd_una = TCP_SKB_CB(skb)->ack_seq; 28 tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale; 29 tcp_init_wl(tp, TCP_SKB_CB(skb)->seq); 30 31 if (tp->rx_opt.tstamp_ok) 32 tp->advmss -= TCPOLEN_TSTAMP_ALIGNED; 33 34 if (!inet_csk(sk)->icsk_ca_ops->cong_control) 35 tcp_update_pacing_rate(sk); 36 37 /* Prevent spurious tcp_cwnd_restart() on first data packet */ 38 tp->lsndtime = tcp_jiffies32; 39 40 tcp_initialize_rcv_mss(sk); 41 tcp_fast_path_on(tp); 42 break; 43 ...
至此,服务器端和客户端都已经进入ESTBLISHED状态,标志三次握手完成。
六,内核调用跟踪: 根据之前的分析,给tcp_v4_connect,tcp_connect,tcp_transmit_skb,ip_queue_xmit,inet_csk_accept,tcp_v4_rcv,tcp_v4_do_rcv ,tcp_v4_conn_request,tcp_conn_request,tcp_rcv_state_process,tcp_rcv_synsent_state_process,tcp_send_ack,tcp_child_process以及tcp_set_state函数打上断点进行跟踪,结果如下:
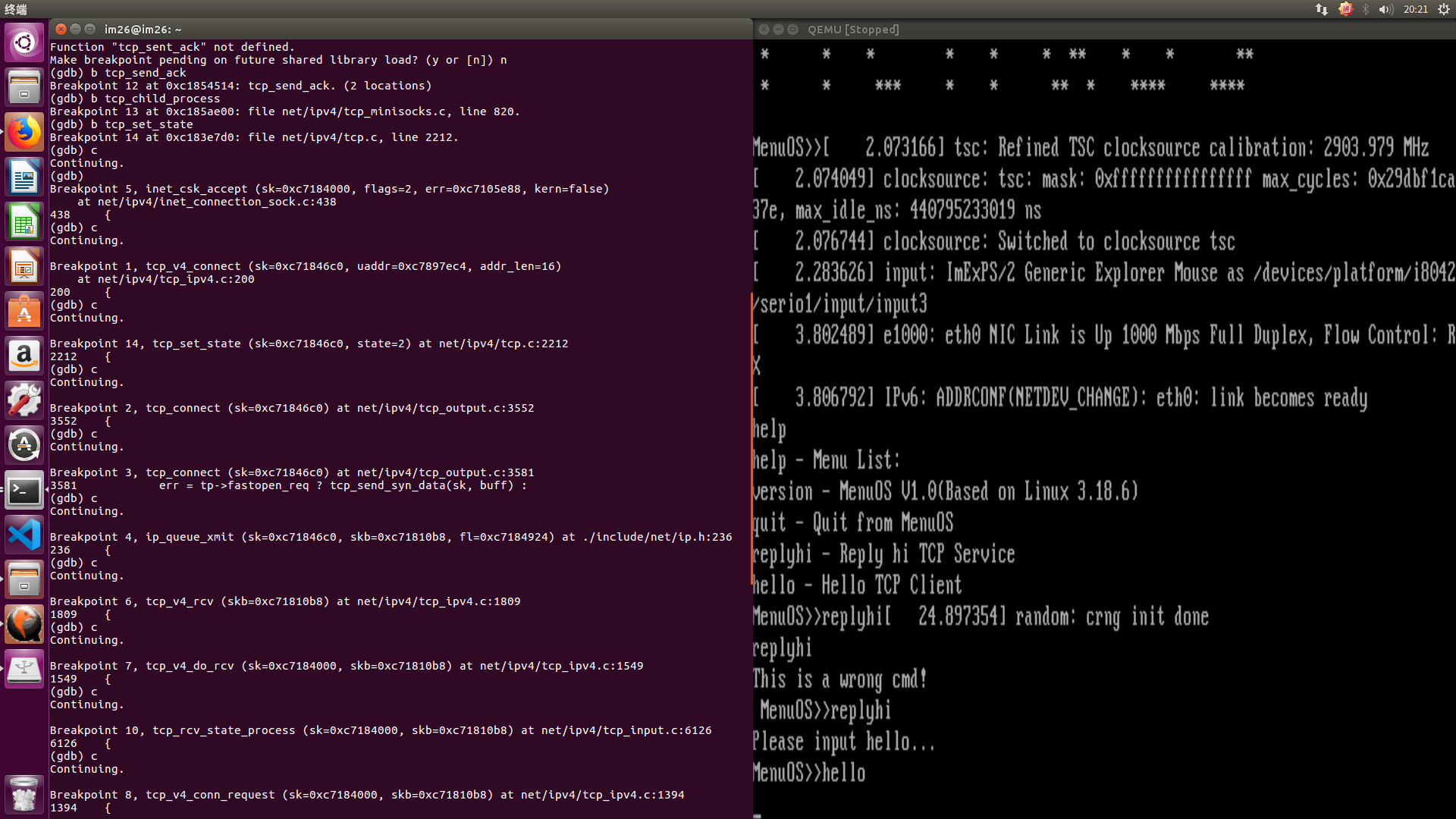
此处客户端已经发送SYN请求,而服务器端正在处理该请求。
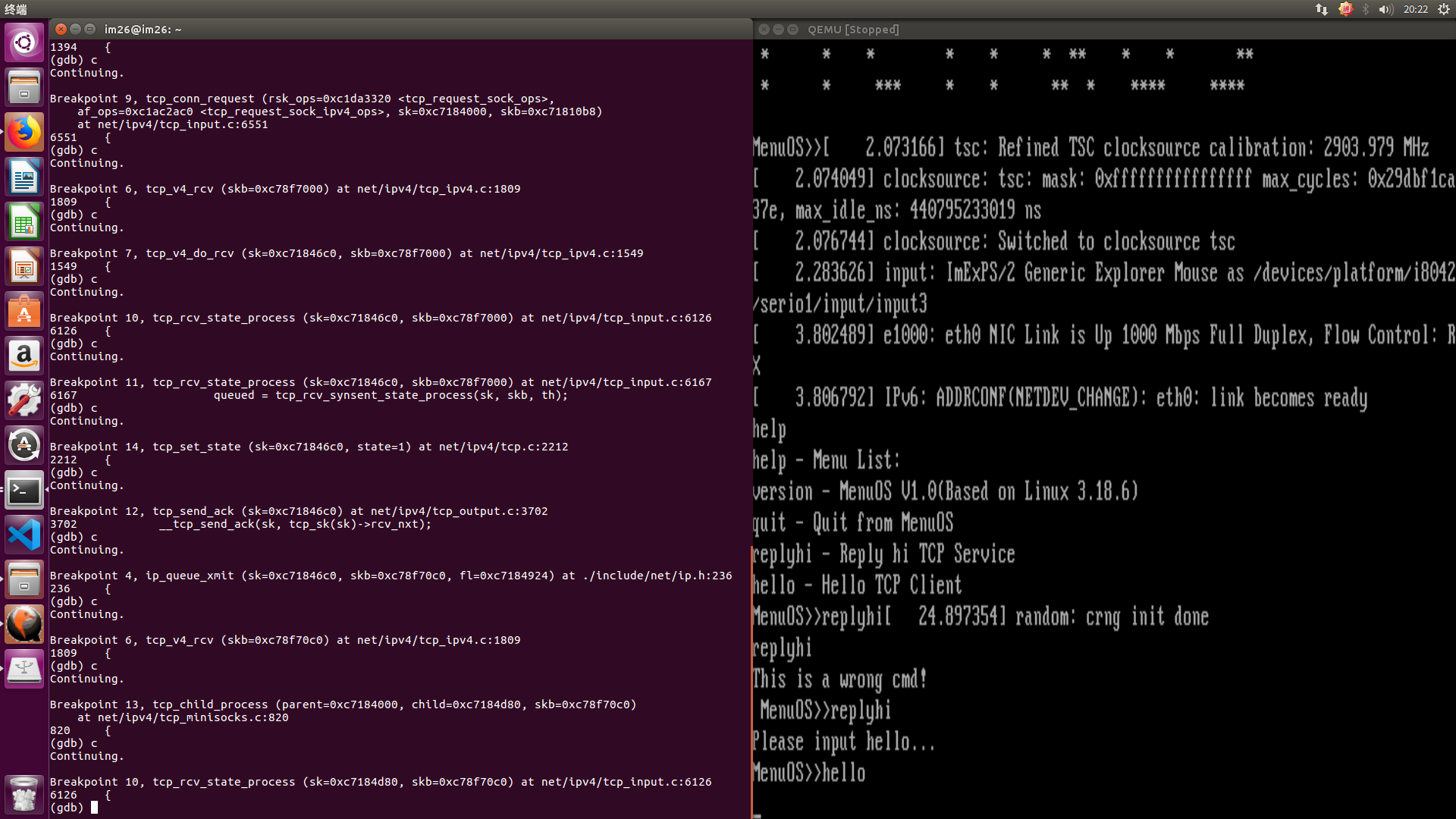
此处第二次握手已经完成,第三次握手正在最后阶段,注意到服务器端tcp_child_process函数被调用,而该函数在处理SYN请求时并未调用,这验证了我们之前的猜想。
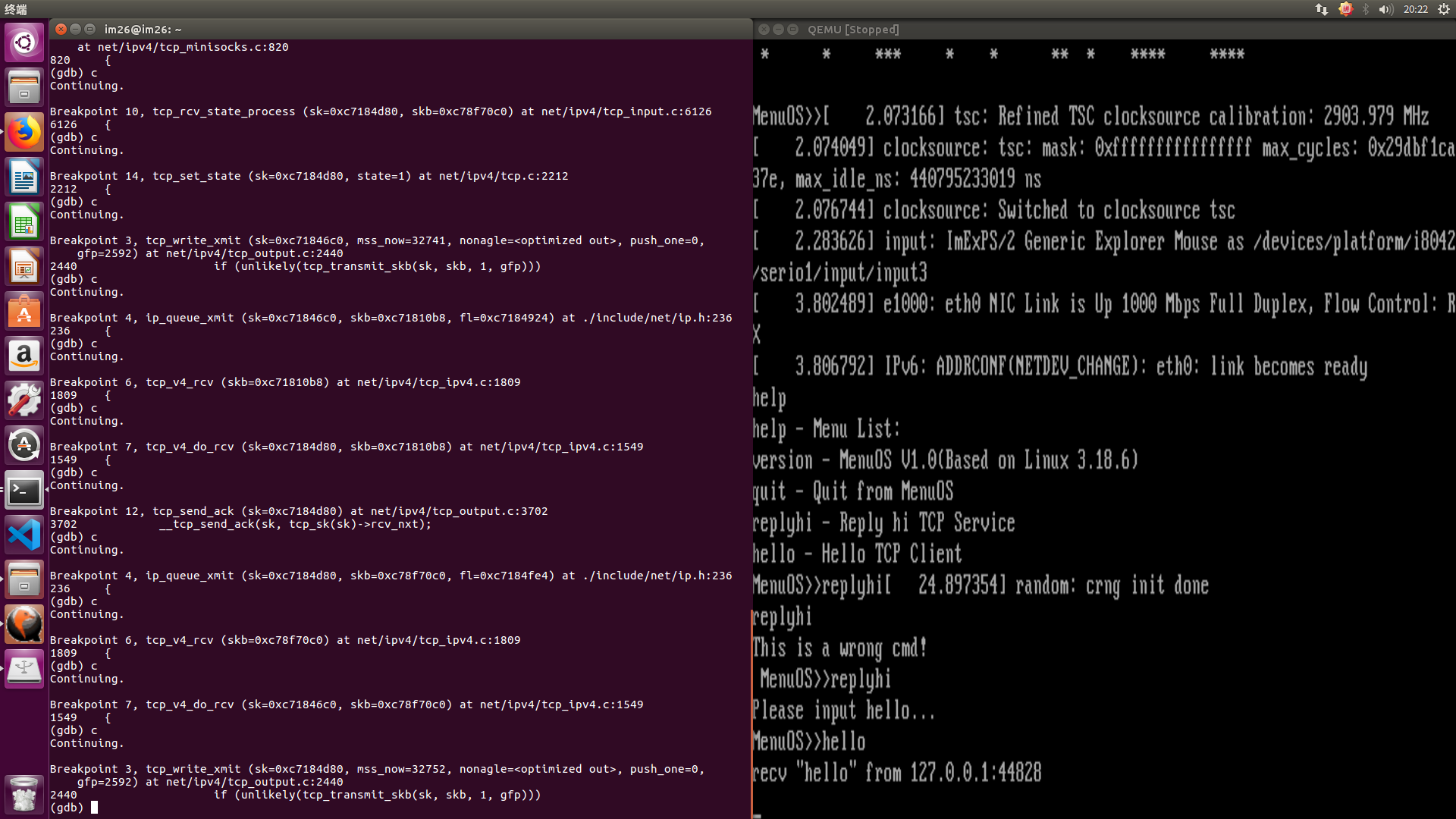
以上就是本次实验的全部内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号