
2023-2024-1 20232320 《网络空间安全导论》第五周学习总结
教材学习内容总结
本章学习了信息内容相关的知识,涉及了信息安全中的威胁与应对,以及信息内容如何处理,同时预警和监测也应重视,做到防患于未然。
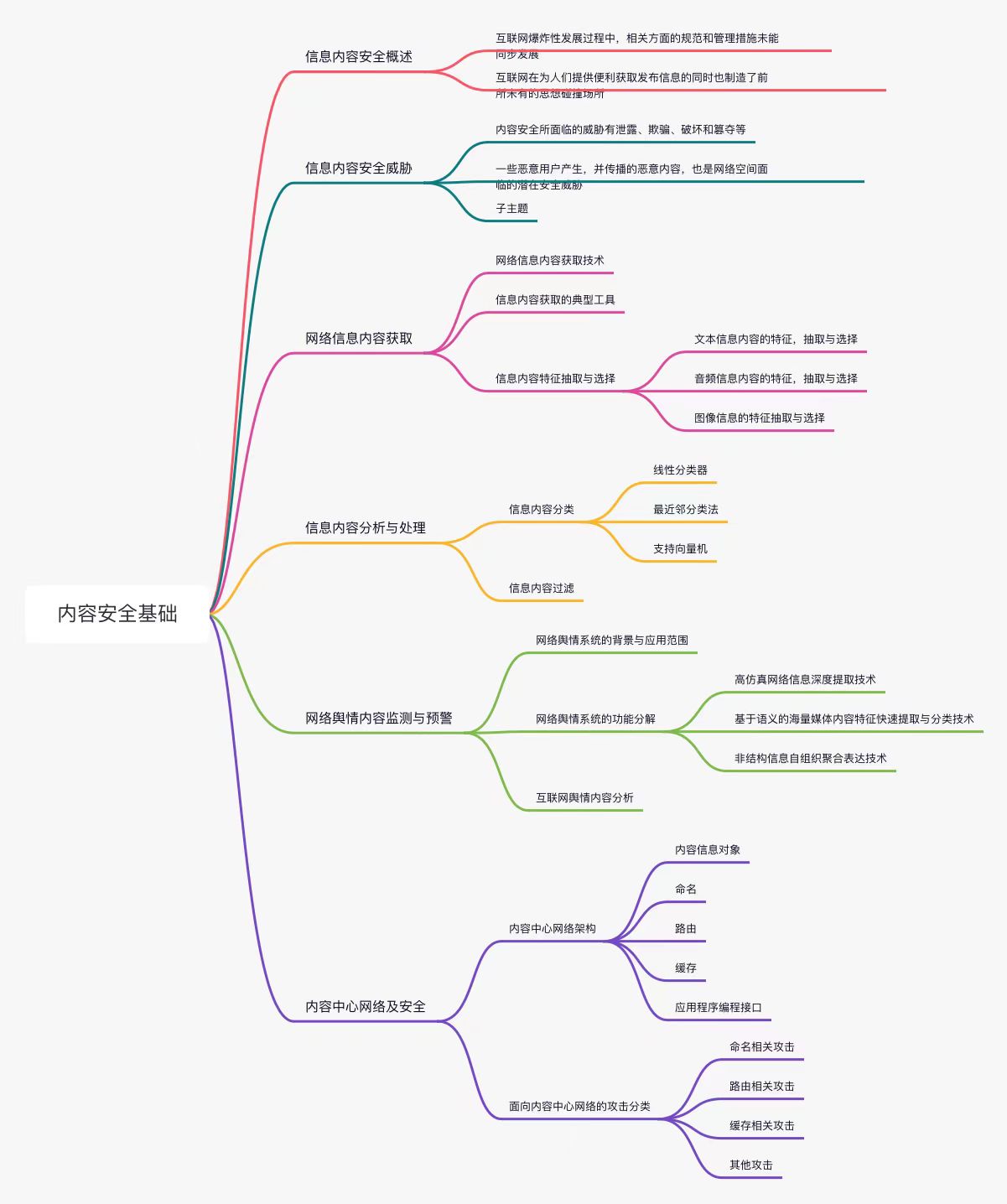
教材中学习问题和解决过程
问题1:网络舆情预警系统是如何设计的?
问题1解决:问AI
网络舆情监测预警系统可以按照以下步骤进行设计:
需求分析:明确系统的需求,包括信息采集、信息预处理、信息分析、舆情预警和可视化界面等方面。
信息采集:系统需要具备跨平台、大范围的信息采集能力,能够从不同来源获取所需信息。
信息预处理:采集到的信息往往存在重复、冗余、错误等情况,需要进行预处理,如去重、纠错、分类等。
信息分析:系统应对预处理后的信息进行深入分析,包括情感分析、主题识别、趋势预测等。
舆情预警:系统应能够在发现异常舆情时及时发出预警,以便用户迅速采取应对措施。
可视化界面:系统应提供直观、易用的可视化界面,方便用户进行操作和监控。
数据存储:使用大规模分布式存储技术,对采集到的数据进行存储和处理。分布式存储技术具有高可用性、高可扩展性等优点,可以满足大规模数据处理的需求。
数据处理:使用云计算技术对采集到的数据进行处理和分析。云计算技术可以提供大规模、高并发、低成本的数据处理能力,可以大大提高数据处理效率和质量。
特征提取:通过文本预处理,将原始文本转化为结构化的数据,并使用TF-IDF、word2vec等算法进行特征提取。
情感分析:通过情感分析,可以对文本的情感倾向进行判断,从而了解公众对某一事件或话题的情感态度。常用的情感分析算法有基于规则的方法和机器学习方法。
以上步骤仅供参考,您可以根据实际情况进行调整和优化。
问题2:简单比较最近邻分类法和线性分类法的异同
线性分类法和最近邻分类法都是常见的机器学习算法,它们在处理分类问题时有所不同。
相同点:
两者都是监督学习算法,需要使用已知标签的训练数据进行学习。
两者都需要对输入数据进行特征提取或预处理,以将原始数据转化为适合模型处理的特征向量。
两者都可以用于多分类问题,且都可以对数据进行分类预测。
不同点:
线性分类法是一种线性模型,通过构建一个线性函数将输入特征向量映射到类别空间。而最近邻分类法是一种基于距离的分类方法,通过计算被识别样本与已知类别样本之间的距离来进行分类。
线性分类法的训练过程是通过学习一组权重和偏置参数来优化模型的分类性能。而最近邻分类法则是在训练过程中统计每个类别样本的数量,并将新样本归为数量最多的类别。
线性分类法通常使用优化算法来调整模型参数,如梯度下降法、牛顿法等。而最近邻分类法则通常使用距离度量来比较样本之间的相似性,如欧氏距离、曼哈顿距离等。
线性分类法在处理非线性可分数据时可能会遇到困难,此时可以考虑使用核函数将输入数据从原始空间映射到一个更高维度的特征空间,从而使得数据在新的空间中线性可分。而最近邻分类法则对数据的线性可分性没有要求,但可能会在处理大规模数据集时效率较低。
总之,线性分类法和最近邻分类法在处理分类问题时有所不同,需要根据具体问题的特点和要求来选择合适的算法。
基于AI的学习
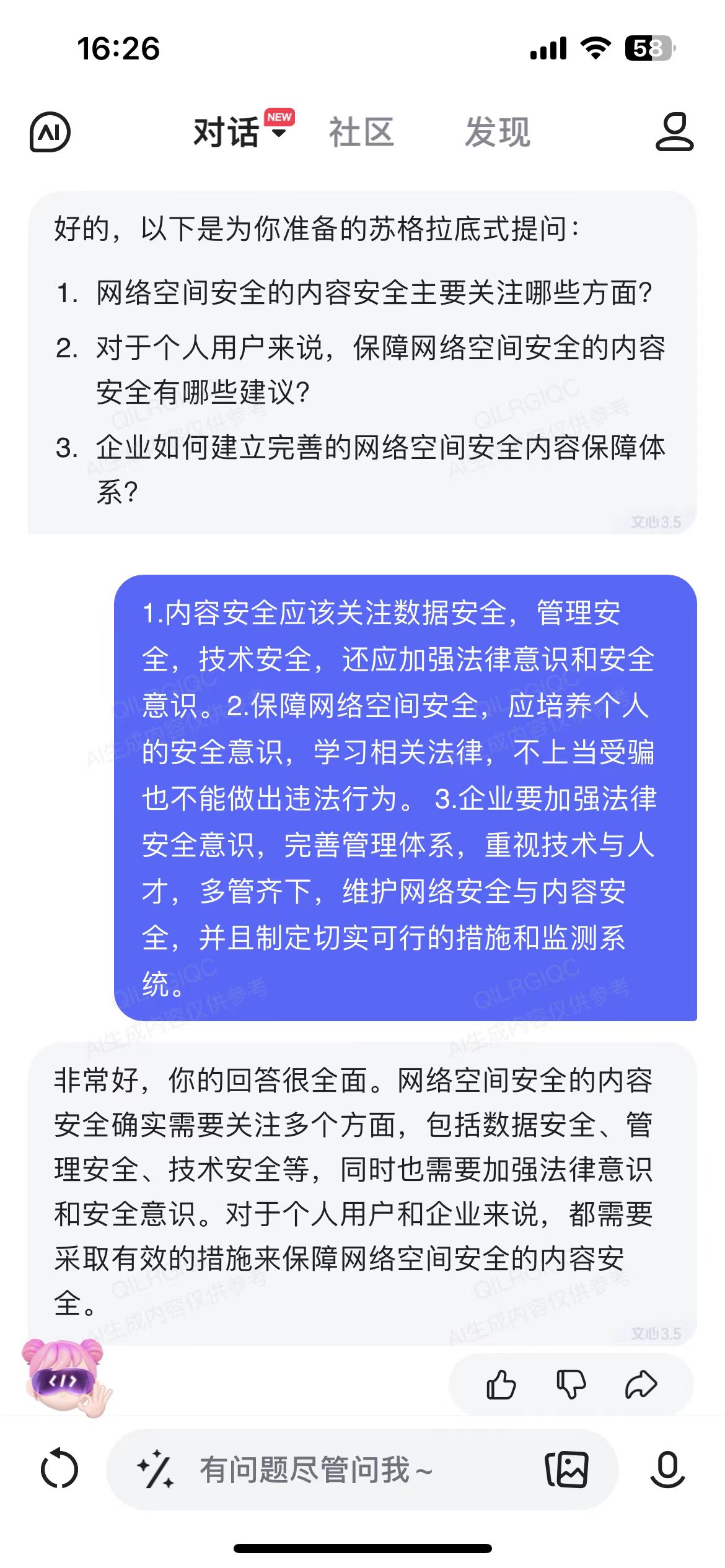
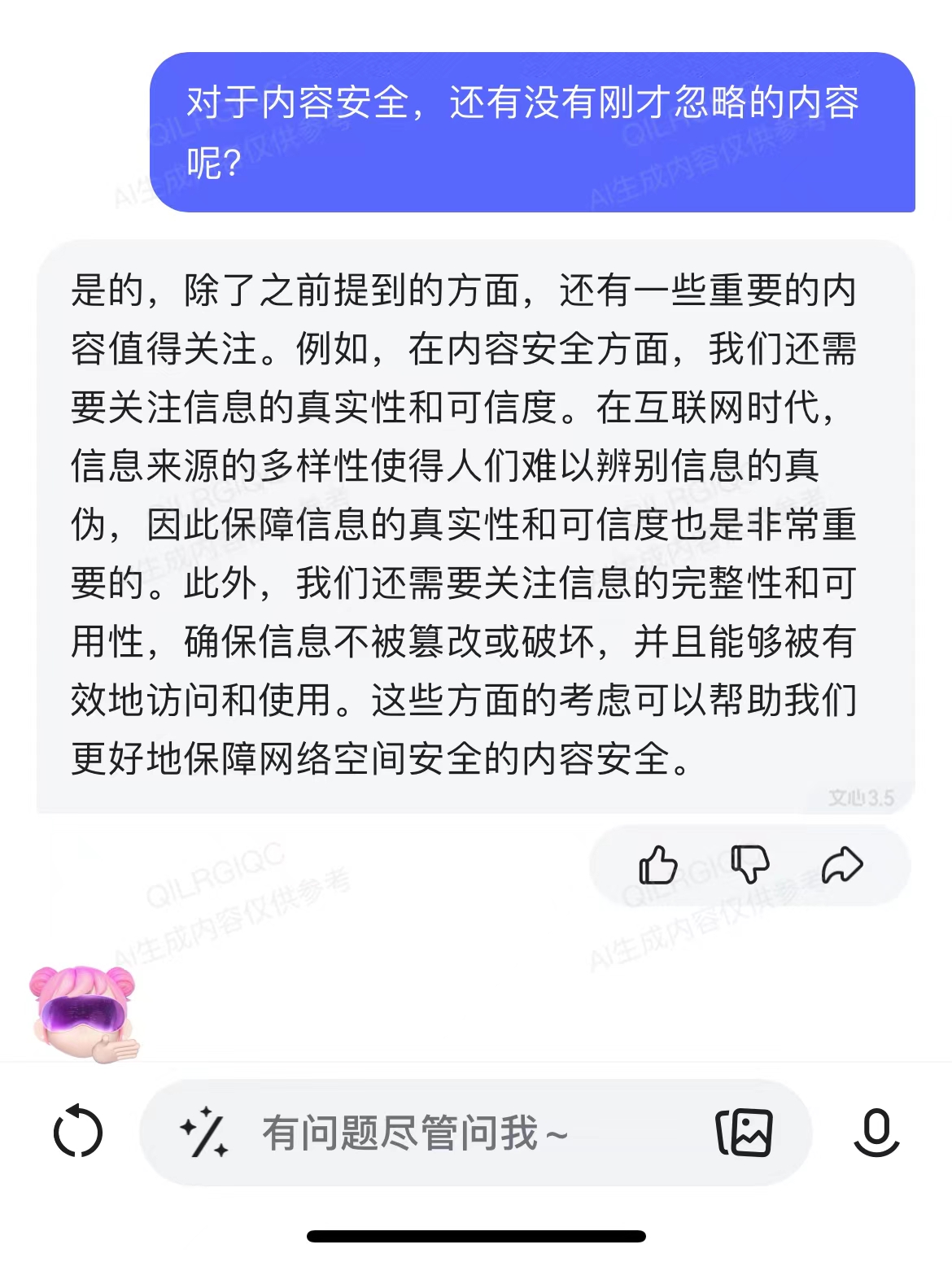
思考
在内容安全方面,是否存在我们监察不到的地方?对于这样的情况,我们又应该如何应对和完善?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号