Redis数据结构——链表
Redis链表为双向无环链表!
Redis之数据结构——简单动态字符串SDS提到Redis使用了简单动态字符串,链表,字典(散列表),跳跃表,整数集合,压缩列表这些数据结构来操作内存,并且简单介绍了Redis简单动态字符串。本篇文章我们继续来分析链表。
链表是一种非常常见的数据结构,在Redis中使用非常广泛,列表对象的底层实现之一就是链表。其它如慢查询,发布订阅,监视器等功能也用到了链表。
一、复习链表
1.1 数组与链表
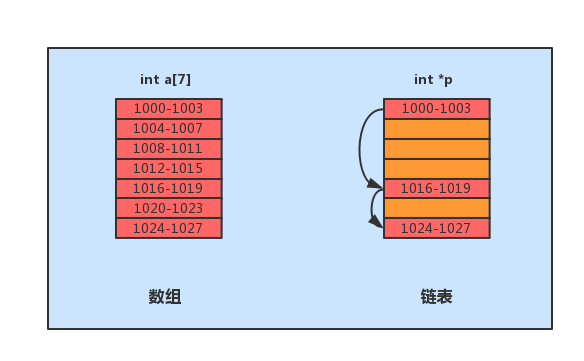
数组需要一块连续的内存来存储,这个特性有利也有弊。好处是其支持根据索引下标"随机访问"(时间复杂度为O(1)),但是其插入与删除操作为了保证在内存中的连续性将会变得非常低效(时间复杂度为O(N)),并且其一经声明就要占用整块连续内存空间,如果声明过大,系统可能内存不足,声明过小又可能导致不够用,而当数组的空间不足的时候需要对其进行扩容(申请一个更大的空间,将原数组拷贝过去)。
而链表恰恰相反,其不需要一块连续的内存空间,其通过"指针"将一组零散的内存连接起来使用。其优点在于本身没有大小限制,天然支持扩容,插入删除操作高效(时间复杂度为O(1)),但缺点是随机访问低效(时间复杂度为O(N))。并且由于需要额外的空间存储指针。
链表的实现方式有很多种,常见的主要有三个,单向链表、双向链表、循环链表。
1.2 单链表
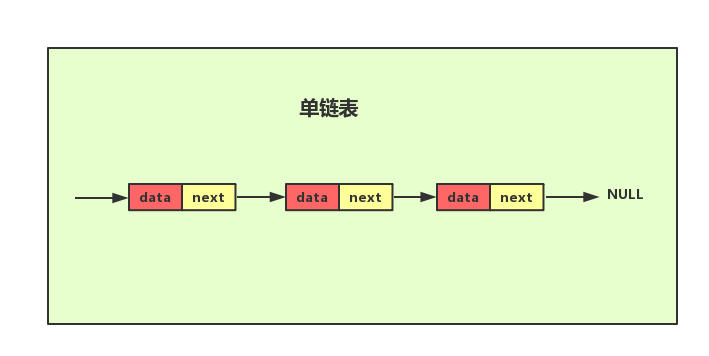
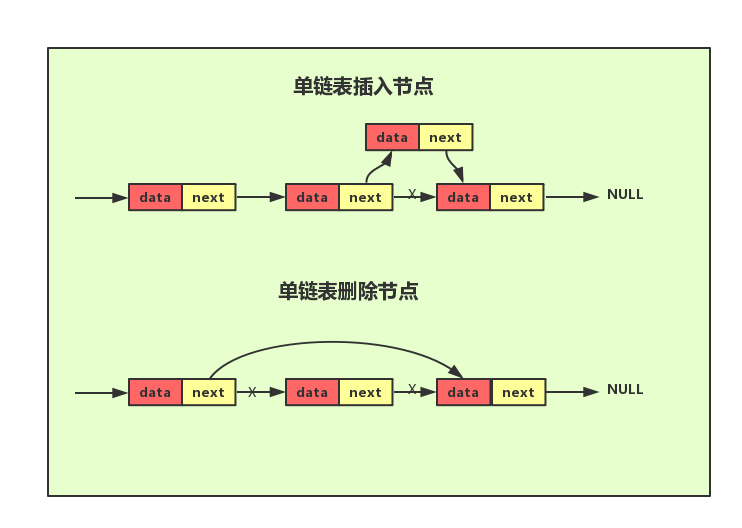
单链表中每个节点除了包含数据之外还包含一个指针,叫后继指针,因此需要额外的空间来存储后继节点的地址。有两个特殊的节点,头结点和尾节点,其中头节点用来记录链表的基地址,有了它就可以遍历整个链表,尾节点的后继指针不是指向下一个节点,而是指向一个空地址NULL表示这是链表上最后一个节点。与数组一样,单链表也支持数据的查找、插入和删除操作,其中插入和删除操作只需要考虑相邻节点指针的变化,因此为常数级时间复杂度O(1)。要想随机访问第 k 个元素,就没有数组那么高效了。因为链表中的数据并非连续存储的,所以无法像数组那样,根据首地址和下标,通过寻址公式就能直接计算出对应的内存地址,而是需要根据指针一个结点一个结点地依次遍历,直到找到相应的结点,因此时间复杂度为O(N)。
1.3 双向链表
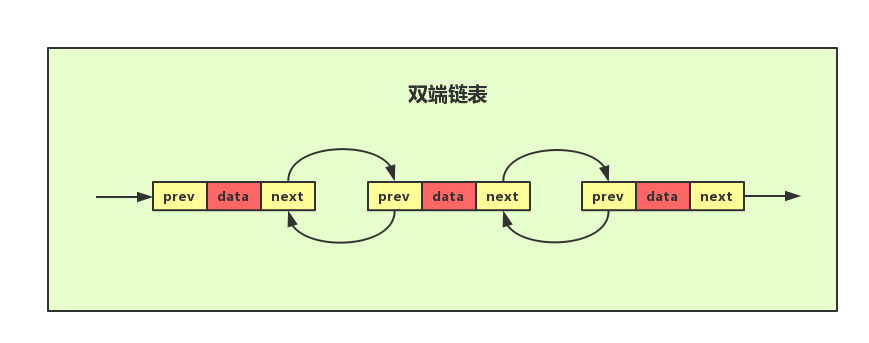
双向链表和单链表不同的是多了一个前驱指针,双向链表需要额外的两个空间来存储后继结点和前驱结点的地址。因此存储同样多的数据,双向链表占用比单链表更多的空间。但其优点在于支持双向遍历,体现在以下两个方面。
- 在有序链表中查找某个元素,单链表由于只有后继指针,因此只能从前往后遍历查找时间复杂度为O(N),而双向链表可以双向遍历。
- 删除给定指针指向的结点。假设已经找到要删除的节点,要删除就必须知道其前驱节点和后继节点,单链表想要知道其前驱节点只能从头开始遍历,时间复杂度为0(n),而双向链表由于保存了其前驱节点的地址,因此时间复杂度为0(1)。
1.4 循环链表
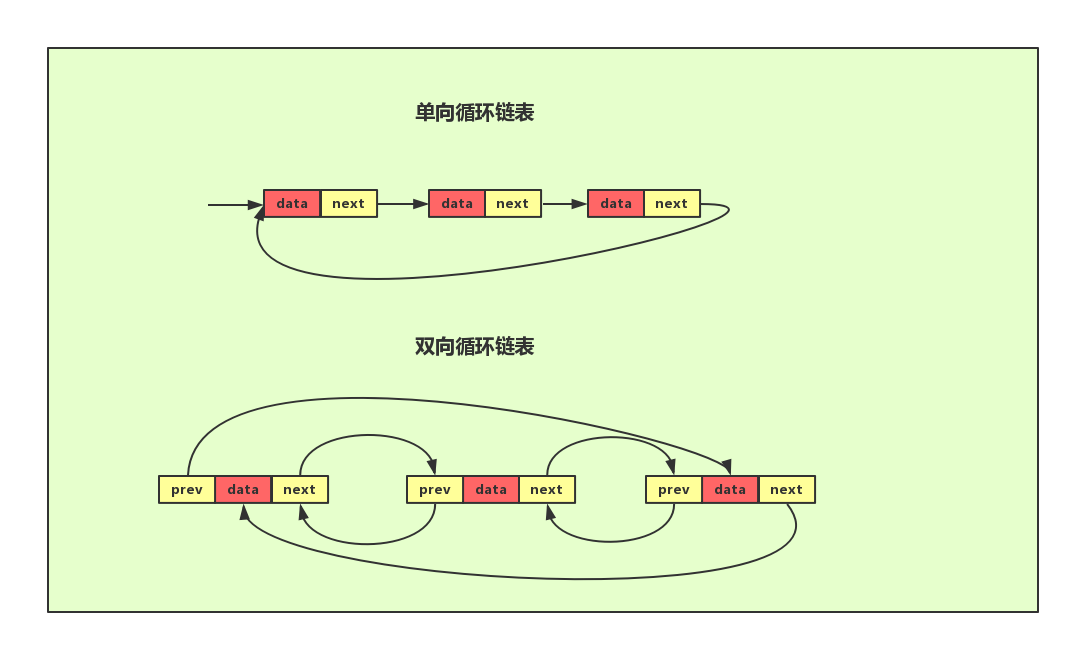
顾名思义。循环链表与单、双链表不同的是其呈环状,单循环链表中其尾节点并非指向NULL而是指向头结点。双循环链表中其头节点的前驱指针指向尾节点,尾节点的后继指针指向头结点。循环链表的优势在于链尾到链头,链头到链尾比较方便适合处理的数据具有环型结构特点。
二、Redis链表
2.1 双向无环链表
Redis链表使用双向无环链表。
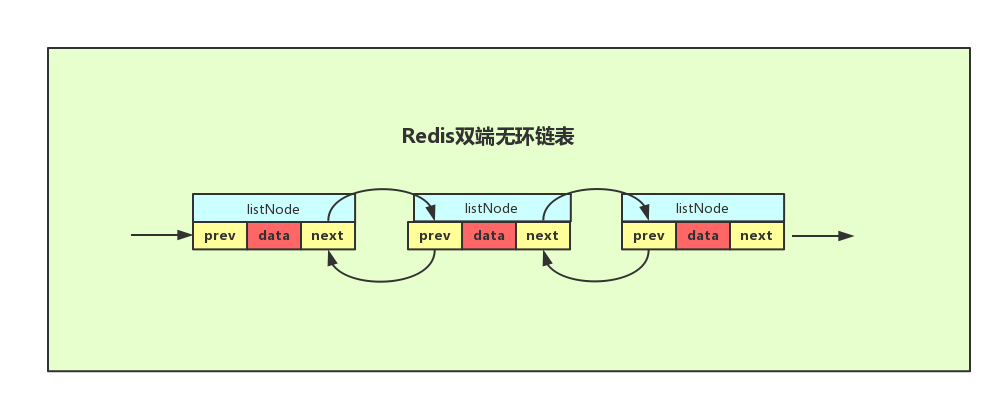
如图所示,Redis使用一个listNode结构来表示。
typedef struct listNode
{
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
2.2 list结构
同时Redis为了方便的操作链表,提供了一个list结构来持有链表。如下图所示
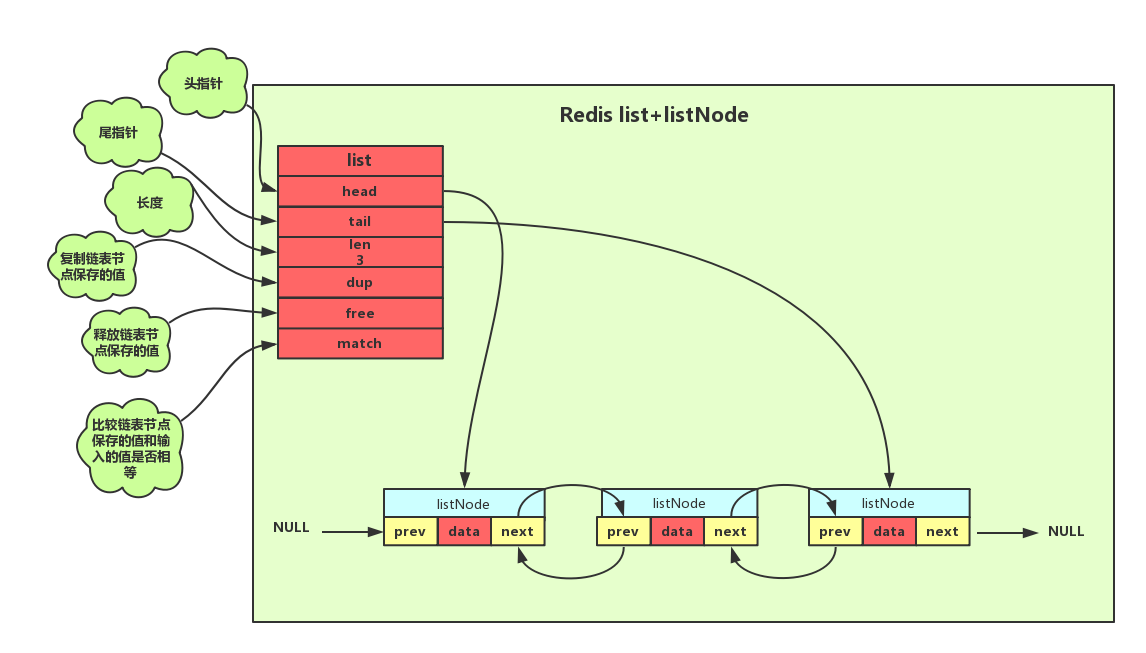
typedef struct list{
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//链表所包含的节点数量
unsigned long len;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void *(*free)(void *ptr);
//节点值对比函数
int (*match)(void *ptr,void *key);
}list;
Redis链表结构其主要特性如下:
- 双向:链表节点带有前驱、后继指针获取某个节点的前驱、后继节点的时间复杂度为0(1)。
- 无环: 链表为非循环链表表头节点的前驱指针和表尾节点的后继指针都指向NULL,对链表的访问以NULL为终点。
- 带表头指针和表尾指针:通过list结构中的head和tail指针,获取表头和表尾节点的时间复杂度都为O(1)。
- 带链表长度计数器:通过list结构的len属性获取节点数量的时间复杂度为O(1)。
- 多态:链表节点使用void*指针保存节点的值,并且可以通过list结构的dup、free、match三个属性为节点值设置类型特定函数,所以链表可以用来保存各种不同类型的值。
2.3 双向无环链表在Redis中的使用
链表在Redis中的应用非常广泛,列表对象的底层实现之一就是链表。此外如发布订阅、慢查询、监视器等功能也用到了链表。我们现在简单想一想Redis为什么要使用双向无环链表这种数据结构,而不是使用数组、单向链表等。既然列表对象的底层实现之一是链表,那么我们通过一个表格来分析列表对象的常用操作命令。如果分别使用数组、单链表和双向链表实现列表对象的时间复杂度对照如下:
| 操作\时间复杂度 | 数组 | 单链表 | 双向链表 |
|---|---|---|---|
| rpush(从右边添加元素) | O(1) | O(1) | O(1) |
| lpush(从左边添加元素) | 0(N) | O(1) | O(1) |
| lpop (从右边删除元素) | O(1) | O(1) | O(1) |
| rpop (从左边删除元素) | O(N) | O(1) | O(1) |
| lindex(获取指定索引下标的元素) | O(1) | O(N) | O(N) |
| len (获取长度) | O(N) | O(N) | O(1) |
| linsert(向某个元素前或后插入元素) | O(N) | O(N) | O(1) |
| lrem (删除指定元素) | O(N) | O(N) | O(N) |
| lset (修改指定索引下标元素) | O(N) | O(N) | O(N) |
我们可以看到在列表对象常用的操作中双向链表的优势所在。但双向链表因为使用两个额外的空间存储前驱和后继指针,因此在数据量较小的情况下会造成空间上的浪费(因为数据量小的时候速度上的差别不大,但空间上的差别很大)。这是一个时间换空间还是空间换时间的思想问题,Redis在列表对象中小数据量的时候使用压缩列表作为底层实现,而大数据量的时候才会使用双向无环链表。(关于列表对象后续会有文章继续介绍可访问我的个人博客持续关注www.laoyu.site)
小结
链表作为一种非常常用的数据结构,内置在许多编程语言里面,更是找工作过程中经常问的面试题之一。本篇文章简单复习了链表这种数据结构常见的几种形式,并且简单分析了Redis中链表的使用。下篇文章将继续分享Redis中用到的数据结构Hash。敬请关注!
系列文章:
关注下方公众号,回复“Redis”,可得Redis相关学习资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号