模块导入与包基础
模块与包基础
在前面的学习中,我们已经学习并编写了很多代码,但之前编写的代码,很多时候都是全部写在一个文件中运行起来的。这样的话,随着我们将来不断的深入学习和项目开发,那么代码肯定是越来越多,如果继续把代码放在一个文件中,很容易出现命名冲突(同名变量、同名函数导致覆盖之前的声明),这时候就需要使用python提供的模块与包来把代码按不同的种类,不同的用途来划分到不同的文件或者目录中了。
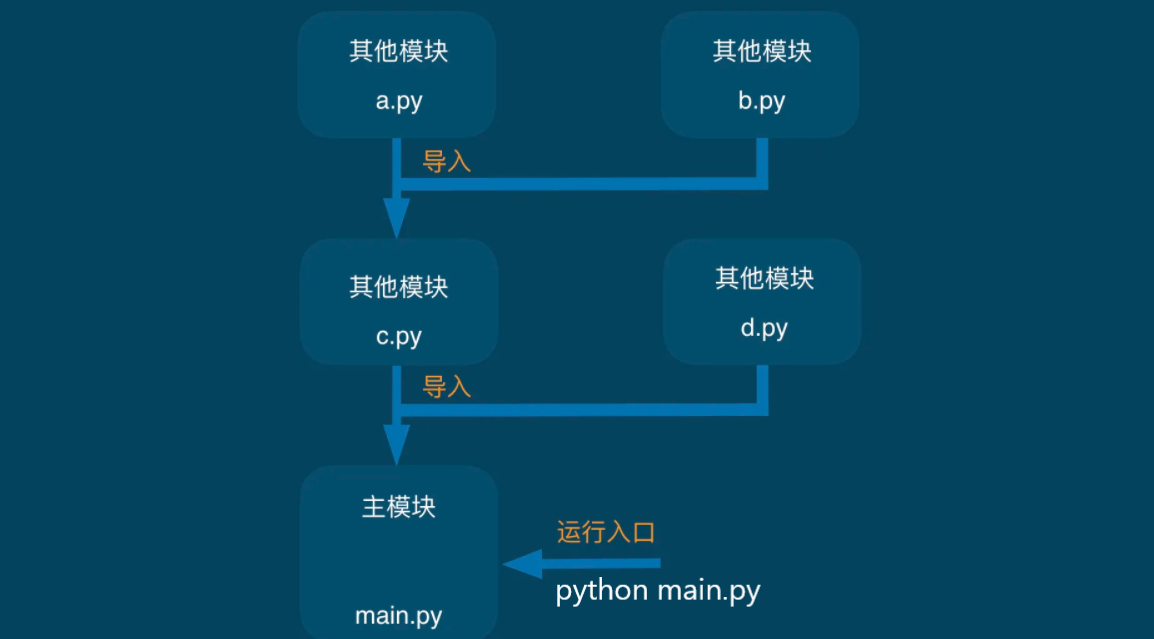
在 Python 中,模块(Module)就是一个个扩展名为.py 的源程序文件,所以我们之前创建的每一个python源程序文件都可以理解是模块。包(Package)就是一个个保存了模块文件和__init__.py文件的特殊目录。一个完整的Python项目通常都是基于模块和包的方式来组织代码。
掌握了模块与包的使用,可以让我们更好地管理和组织代码,提升代码的阅读性和维护性,其次编写代码则不需要每次都从零开始,当一个模块或包编写完成以后,就可以被其他地方所使用。而且在python中,因为有大量的开发者已经把常用的功能代码都已经写好保存成一个个模块或包了,所以在开发中,我们就可以基于别人写好的模块和包更快,更出色的开发项目。
Python中的模块与包可分为3类,分别是内置模块、第三方模块和开发者自定义的模块。
- 内置模块是Python内置标准库中的官方模块,在安装了python解释器以后就可直接导入程序中使用。https://docs.python.org/zh-cn/3.9/library/index.html
- 第三方模块是由非官方开发者制作并发布出来使用的Python模块,在模块使用之前需要先基于包管理软件conda/pip自行安装。https://pypi.org/
- 自定义模块是开发者在编写程序时根据自身业务需要而编写的,存放着功能性代码的python文件。
基本使用
导入语句,有import 和 from ..import 或者 from ... imporit ...as 三种,往往开发中强烈建议大家写在py文件的顶部。
# 导入语句有几种写法:
# 1. 以包作为单位导入,使用时从包名开始,以点语法进行调用包下面的模块文件里面的内容
import 包名.模块
包名.模块.类()
包名.模块.对象
包名.模块.函数()
包名.模块.变量
# 2. 以模块作为单位导入,使用时从模块名开始,以点语法进行调用模块文件里面的内容
import 模块
from 包名 import 模块
模块.类()
模块.对象
模块.函数()
模块.变量
# 3. 以标记符作为单位导入,使用时,直接按标记符进行使用,左边无须使用包名或模块名作为前缀
from 包名.模块 import 类, 对象, 函数, 变量
from 模块 import 类, 对象, 函数, 变量
from 模块 import *
from 模块 import 变量 as 别名
类()
对象
函数()
变量
别名
代码:
"""
from 表示 从....指定目录,从指定模块文件
import 导入,引入,可以引入一个变量,函数,对象,类,常量
from 包名.包名.... import 模块
from 包名.模块 import 变量, 变量, 变量
"""
"""
import 包名.包名.模块
import 包名.模块
通过包名.模块作为前缀调用
"""
# import my_number.demo_number
# ret = my_number.demo_number.num1()
# print(ret) # num1
"""
import 模块
"""
# import my_mod
# ret = my_mod.func()
# print(ret) # my_mod.func函数调用了
"""
from 包名.包名... import 模块
from 包名 import 模块
"""
# from my_number import demo_number
# ret = demo_number.num1()
# print(ret) # num1
"""
from 包名.包名.包名.模块 import 变量
from 包名.包名.模块 import 变量
from 包名.模块 import 变量
from 模块 import 变量,变量,变量
"""
# from my_number.demo_number import num1
# ret = num1()
# print(ret) # num1
# from my_mod import func
# ret = func()
# print(ret) # my_mod.func函数调用了
"""
from 包名.模块 import *
from 模块 import *
# * 表示模块中所有的变量都会被导入使用
"""
# from my_mod import *
# print(number100) # 100
# print(func2()) # [1, 2, 3, 4]
"""
导入模块以后,如果担心与当前文件中的变量冲突,可以使用as关键字,给导入的内容起个变量
"""
# from my_mod import func2 as f2
#
# def func2():
# return 3,45,56
#
# ret = func2()
# print(ret) # (3, 45, 56)
#
# ret = f2()
# print(ret) # [1, 2, 3, 4]
基本内置模块
内置模块也叫官方标准库,官方地址:https://docs.python.org/zh-cn/3.9/library/index.html
我们要使用模块就必须先将模块加载到当前python文件中,通常使用通过关键字 import 或 from进行加载,这个过程,我们一般叫导入包或者导入模块。
在此之前,我们已经学习过程中的random、time,其实都是官方内置的模块或包,所以安装完python解释器以后,即可使用了import 或者 from 来进行了导入。当然,我们之前对于他们的使用其实并不系统,所以我们接下来系统的学习下python开发中常用的模块与包。
数学相关
math模块
| 属性 | 描述 |
|---|---|
| pi | π,圆周率,3.141592653589793 |
| tau | 2π,代表圆的周长与半径之比。 |
| nan | nan,Not a Number,是计算机计算过程中一个代表非数字的浮点数类型常量,不等于任何数字,包括自身。 在python3.5以前,使用float('nan')表示nan。 所以有时候判断一个数字是否是非数字nan,不能单纯靠==和is来判断,会存在判断错误的情况。 为了解决上面的BUG,python3.5以后在math模块中新增了一个浮点数常量nan与isnan函数判断数字是否是nan |
| inf | inf 正无穷大的浮点数 在python3.5以前,使用float("inf")来表示inf,使用float("-inf")表示-inf |
| 方法 | 描述 |
|---|---|
| ceil(x) | 对数值x进行向上取整 |
| comb(n,k) | 获取n项中提取k项的不重复且无顺序组合总数。python3.8新增功能。 |
| perm(n,k=None) | 获取n项中提取k项的不重复且有顺序组合总数。python3.8新增功能。 |
| copysign(x, y) | 返回一个基于x的绝对值和y的符号的浮点数。 |
| fabs(x) | 求数值x的浮点型绝对值,与内置函数abs不同的是,fabs总会返回浮点数结果。 |
| factorial(x) | 求正整数x的阶乘结果。 |
| floor(x) | 对数值x进行向下取整 |
| fmod(x, y) | 取模,返回浮点型结果,x%y适用于整数,而浮点数取模则应该使用fmod更加精确。 |
| fsum(iterable) | 对可迭代对象中的每一个元素进行叠加操作,并得到浮点型结果。 与内置函数sum不同的是,fsum可以得到更加精确的浮点数结果。 |
| gcd(*integers) | 计算给定的所有整数参数的最大公约数。 python3.9版本之前,仅支持获取2个整数参数的最大公约数 |
| lcm(*integers) | 返回给定的整数参数的最小公倍数。python3.9新增功能。 |
| isnan(n) | 判断参数是否是非数字nan。 |
| isqrt(n) | 返回非负整数n的整数平方根(向下取整)。python3.8新增功能。 |
| prod(iterable, *, start=1) | 计算输入的可迭代参数中所有元素与start的总乘积,默认start=1。python3.8新增功能。 |
| remainder(x, y) | 求x相对于y的余数,比%号更加精确的取模运算。python3.7新增功能。 |
import math
"""
pi π,圆周率
tau 2π,代表圆的周长与半径之比。
"""
print(math.pi) # 3.141592653589793
print(math.tau) # 6.283185307179586
# 如果半径r=5,计算圆的面积 S = πr²
r = 5
S = math.pi * r**2
print(f"{S:.2f}") # 78.54
# 如果半径r=5,计算圆的周长 C = 2πr
r = 5
C = math.tau * r
# C = math.pi * 2 * r
print(f"{C:.2f}") # 31.42
"""
inf 正无穷大的浮点数
-inf 负无穷大的浮点数
在python3.5以前,使用float("inf")来表示inf,使用float("-inf")表示-inf
"""
print(math.inf, float("inf")) # inf inf
print(-math.inf, float("-inf")) # -inf -inf
"""
nan Not a Number,是计算机计算过程中一个代表非数字的浮点数类型常量,不等于任何数字,包括自身。
isnan 判断参数是否是非数字(nan)
在python3.5以前,使用float('nan')表示nan。
所以有时候判断一个数字是否是非数字nan,不能单纯靠==和is来判断,会存在判断错误的情况。
为了解决上面的BUG,python3.5以后在math模块中新增了一个浮点数常量nan与isnan函数判断数字是否是nan
"""
nan = float('nan')
print(nan, type(nan)) # nan <class 'float'>
print(nan == nan) # False
print(nan is float('nan')) # False
nan = math.nan
print(nan, type(nan)) # nan <class 'float'>
ret = math.isnan(nan)
print(ret) # True
nan = float('nan')
ret = math.isnan(nan)
print(ret) # True
"""ceil 向上取整"""
print(math.ceil(1.9)) # 2
print(math.ceil(1.3)) # 2
print(math.ceil(-1.9)) # -1
print(math.ceil(-1.3)) # -1
# 如果小数位精度太小,会出现精度丢失问题
print(math.ceil(1.000000000000000111)) # 1
print(math.ceil(-1.9999999999999999)) # -2
"""comb 获取n项中提取k项的不重复且无顺序组合总数"""
ret = math.comb(5, 4)
print(ret) # 5
# {1,2,3,4}, {1,2,3,5}, {1,2,4,5}, {1,3,4,5}, {2,3,4,5}
ret = math.comb(5, 2)
print(ret) # 10
# {1,2}, {1,3}, {1,4}, {1,5}
# {2,3}, {2,4}, {2,5}
# {3,4}, {3,5}
# {4,5}
"""perm 获取n项中提取k项的不重复且有顺序组合总数"""
ret = math.perm(3, 2)
print(ret)
# (1,2), (1,3)
# (2,1), (2,3)
# (3,1), (3,2)
ret = math.perm(5, 2)
print(ret)
# (1,2), (1,3), (1,4), (1,5)
# (2,1), (2,3), (2,4), (2,5)
# (3,1), (3,2), (3,4), (3,5)
# (4,1), (4,2), (4,3), (4,5)
# (5,1), (5,2), (5,3), (5,4)
"""copysign 返回一个基于x的绝对值和y的符号的浮点数。"""
ret = math.copysign(-10, -5)
print(ret) # -10, |-10| 是10,-5的符号是负号,所以结果是-10
ret = math.copysign(5, -2)
print(ret) # -5, |5| 是10,-2的符号是负号,所以结果是-5
"""fabs 求数值的绝对值"""
ret = math.fabs(-3)
print(ret) # 3.0
ret = abs(-3)
print(ret) # 3
"""factorial 求数字的阶乘结果"""
ret = math.factorial(4)
print(ret) # 3628800
"""fmod 浮点型取模"""
ret = math.fmod(10,3)
print(ret) # 1.0
ret = 10 % 3
print(ret) # 1
"""fsum 对列表成员进行浮点数叠加"""
data = [0.1, 1.1, 0.1]
ret = math.fsum(data)
print(ret) # 1.3
ret = sum(data)
print(ret) # 1.3000000000000003
"""gcd 求所有整数参数的最大公约数(公因数)"""
ret = math.gcd(10, 15)
# ret = math.gcd(10,15,30) # 这行代码在低于python3.9版本的解释器中会报错!
print(ret) # 5
"""lcm 求给定的整数参数的最小公倍数"""
ret = math.lcm(3,5) # 这行代码在低于python3.9的解释器中会报错。
print(ret) # 15
"""isqrt 求数值的整数平方根"""
ret = math.isqrt(2)
print(ret) # 1
ret = math.sqrt(2)
print(ret) # 1.4142135623730951
# """prod 计算输入的可迭代参数中所有元素的积。"""
ret = math.prod([1,2,3,4], start=1)
print(ret) # 24
"""remainder 比%更加精确的取模"""
ret = math.remainder(10,3)
print(ret) # 1.0
""""""
decimal模块
Decimal,十进制定点和浮点运算模块。我们都知道计算机中基于二进制进行数值运算,所以在部分数值运算过程中会存在精度丢失问题。所以一般在开发中,设计到金额计算等情况,我们会使用Decimal十进制定点类型来完成计算,Decimal可以避浮点型计算结果丢失精度的问题。
from decimal import getcontext, Decimal
"""计算机中的浮点数计算,存在精度丢失问题,得到的值是一个近似值"""
# print(.1+.1+.1-.3) # 5.551115123125783e-17
# print(0.1+0.1+0.1-0.3) # 5.551115123125783e-17
"""decimal提供了精度计算和定位计算,可以通过getcontext设置计算结果的精度,保留数值的位数。"""
# ret = Decimal('0.1')
# print(ret, type(ret)) # 0.1 <class 'decimal.Decimal'>
"""因为因为类型不同,所以float浮点类型不能直接与decimal类型进行数学计算,但是可以与整数,布尔值进行计算"""
# print(1.1 + Decimal('0.1')) # TypeError: unsupported operand type(s) for +: 'float' and 'decimal.Decimal'
"""如果要float浮点类型与decimal进行计算,则必须统一类型"""
# num = 1.1
# print(Decimal(str(num)) + Decimal('0.1')) # 1.2
"""所以Decimal里面的参数,务必是数字组成的字符串。"""
"""计算浮点数计算丢失精度问题"""
getcontext().prec = 3
print(Decimal('0.1')+Decimal('0.1')+Decimal('0.1')-Decimal('0.3')) # 0.0
random模块
伪随机数模块,并非真正的随机。
| 方法 | 描述 |
|---|---|
| random() | 产生一个[0.0, 1.0) 范围内的随机浮点数。 |
| uniform(a, b) | 产生一个指定范围[a,b]内的随机浮点数。 |
| randint(a, b) | 产生指定范围[a,b]内的随机整数 |
| randrange(start, stop, step) | 从一个指定步长step的指定范围[start, stop)中产生的随机整数 |
| choice(seq) | 从序列seq中随机抽取一个成员 |
| choices(seq, k) | 从序列seq中随机抽取k个成员,以列表格式返回结果 |
| shuffle() | 打乱列表中成员的排列循序 |
| sample(s, k) | 打乱一个不可变序列并随机提取k个成员返回新列表 |
| randbytes(n) | 生成指定长度n个随机字节。python3.9新增功能。 |
代码:
import random
"""random 产生一个[0.0, 1.0)范围内的随机浮点数"""
print(random.random()) # 0.4293187888221397
"""uniform 产生一个[a,b]范围内的随机浮点数"""
print(random.uniform(0, 1)) # 5.755090621492538
"""randint 产生一个[a,b]范围内的整数"""
print(random.randint(1, 2)) # 6
"""randrange 产生一个[start, stop)范围内,步进值为step的整数"""
print(random.randrange(1, 5, 1)) # 4
"""choice 从序列中随机抽取一个成员"""
seq = ["A", "B", "C"]
seq = "abdcef"
print(random.choice(seq))
"""choices 从序列中随机抽取k个成员,以列表格式返回结果"""
ret = random.choices(seq, k=2)
print(ret) # ['d', 'd']
"""shuffle 打乱排列循序"""
seq = ["A", "B", "C", "D", "E", "F"]
random.shuffle(seq)
print(seq) # ['A', 'E', 'B', 'F', 'C', 'D']
"""打乱一个不可变序列并随机提取k个成员返回新列表"""
# 打乱一个字符串的字符排列
s = "ABCDEFG"
data = random.sample(s, k=len(s))
ret = "".join(data)
print(ret) # GAEFBCD
# 从字符串中随机抽取4个成员组成的新列表
s = "ABCDEFG"
ret = random.sample(s, k=4)
print(ret, ) # ['D', 'G', 'F', 'B']
"""生成指定长度n个随机字节"""
ret = random.randbytes(6)
print(ret) # b'\xc6\xeb3\xcf\xb4\xee'
ret = random.randbytes(16)
print(ret) # b'\xd2\x9d\xfa@^\xe1\xa3\x97z?!\x1b\\\x03\xd3Q'
secrets模块
random在日常开发中,针对常用的随机数相关功能基本都已经满足,但如果希望得到更加安全的随机数。python3.6版本以后,secrets模块用于生成高度加密的随机数,适于管理密码、账户验证、安全凭据及机密数据。
"""表示同时引入 2个模块文件"""
import secrets, string
"""生成指定长度随机字符串"""
def genstr(size=6):
characters = string.ascii_letters + string.digits
# ecure_password = ""
# for i in range(size):
# ecure_password += secrets.choice(characters)
# return ecure_password
secure_password = "".join(secrets.choice(characters) for i in range(size))
return secure_password
ret = genstr(16)
print(ret) # 4imU1S9GV4Kxl8ue
"""生成指定长度的高强度密码串(字母数字组成,包含至少一个小写字母,至少一个大写字母以及至少三个数字)"""
def genstongpwd(size=16):
# 密码本有大小写字母,数字,特殊符号组成
characters = string.ascii_letters + string.digits+string.punctuation
while True:
password = "".join(secrets.choice(characters) for i in range(size))
if (any(c.islower() for c in password)
and any(c.isupper() for c in password)
and sum(c.isdigit() for c in password) >= 3
and any(c in string.punctuation for c in password) ):
break
return password
ret = genstongpwd(16)
print(ret)
"""生成安全Token(令牌),适用于密码重置、密保 URL 等应用场景"""
# www.qq.com?token=令牌字符串
# 十六进制随机文本字符串组成的token
print(secrets.token_hex(16)) # 9b9909f0812010732ca9005acdcc0f48
# 安全的URL随机文本字符串
print(secrets.token_urlsafe(16)) # -y22LB66GqtaSbW1zK_Iow
时间日期
Python 程序能用很多方式处理日期和时间,转换日期格式是一个常见的功能。Python 内置提供了 time、datetime 和 calendar 模块可以用于格式化日期和时间。
时间模块(Time)
引入和使用
import time # 引入time模块
timestamp = time.time()
print(f"当前时间戳为: {timestamp}")
常用操作
| 方法/属性 | 描述 |
|---|---|
| time() | 获取本地时间戳,精度在微秒级别 |
| time_ns() | 获取本地时间戳,精度在纳秒级别 |
| ctime(seconds=None) | 获取本地时间字符串(seconds=时间戳),默认为None,表示当前时间 |
| localtime(seconds=None) | 获取本地时间元组(seconds=时间戳),默认为None,表示当前时间 |
| mktime(p_tuple) | 通过时间元组获取秒时间戳 (p_tuple=时间元组) |
| asctime(p_tuple=None) | 获取本地时间字符串(p_tuple=时间元组),默认为None,表示当前时间 |
| sleep(seconds) | 程序睡眠等待指定秒数(seconds=秒) |
| strftime(format, p_tuple=None) | 格式化时间字符串(format=格式化字符串,p_tuple=时间元祖), 默认p_tuple为None,表示当前时间元祖 |
| strptime(string, format) | 将时间字符串通过指定格式提取到时间元组中(string=时间字符串,format=格式化字符串) |
| perf_counter() | 性能计数器,用于计算程序运行的总秒数,从代码第一行开始从0计时。 |
| perf_counter_ns() | 性能计数器,用于计算程序运行的总纳秒数,从代码第一行开始从0计时。 |
| process_time() | 性能计算器,用于计算程序运行当前进程时的总秒数,不计算time.sleep()耗时。 |
| process_time_ns() | 性能计算器,用于计算程序运行当前进程时的总纳秒数,不计算time.sleep()耗时。 |
| gmtime() | 获取当前UTC/GMT的时间元组(世界标准时间) |
| timezone | 获取当前时区与中时区的时间差。 全球以本初子午线为基准,所有地区按经度15°划分24时区,东加西减。 本初子午线经过英国伦敦所以为中时区(格林威治时间,UTC), 首都北京是东八区(CST,UTC/GMT+8), 日本东京是东九区(JST,UTC/GMT+9), 美国纽约是西五区(UTC/GMT-5)。 |
| altzone | 获取格林威治西部的夏令时与当前时区的偏移秒数。 |
| daylight | 获取本地时间是否处于夏令时状态,值为1时是夏令时,值为0时不是夏令时 |
注意:python3.7以上版本支持time模块获取纳秒级别的时间戳,但是并不精确,如果真要使用纳秒级别的计算,建议使用第三方模块如Pandas或Numpy来计算。
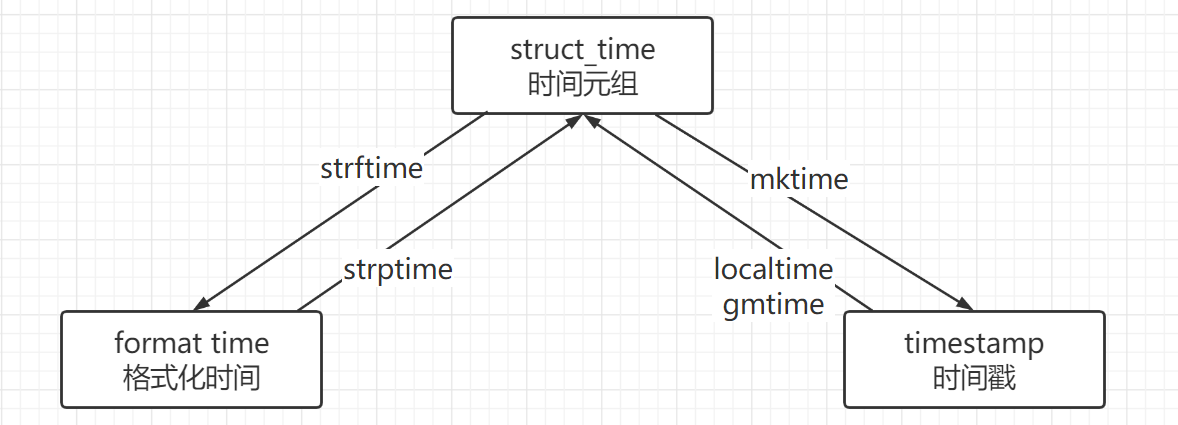
time模块中时间表现的格式主要有3种格式:
- 时间戳(timestamp),也叫纪元(epoch),表示从1970年1月1日00:00:00至今的总秒数,是数值类型。
- 时间元组(struct_time),共有九个代表时间各个单位的成员,是元祖类型。
- 格式化时间(format time),以格式化字符串的方式让时间更具可读性。支持固定格式和自定义格式,是字符串类型。
时间戳(timestamp)
时间戳,表示从1970年1月1日00:00:00至今的总秒数,是数值类型,所以两个时间戳之间可进行算术运算,比较运算等数学操作。
import time
"""time() 获取当前时间戳"""
timestamp = time.time()
print(f"timestamp={timestamp}") # timestamp=1647071394.9340892
# 秒时间戳
seconds_timestamp = int(timestamp)
print(f"seconds_timestamp={seconds_timestamp}") # seconds_timestamp=1647071461
# 毫秒时间戳
millisecond_timestamp = int(timestamp * 1000)
print(f"millisecond_timestamp={millisecond_timestamp}") # millisecond_timestamp=1647071461553
# 微秒时间戳
microsecond_timestamp = int(timestamp * 1000 * 1000)
print(f"microsecond_timestamp={microsecond_timestamp}") # microsecond_timestamp=1647071565791817
# 纳秒时间戳
nanosecond_timestamp = time.time_ns()
print(f"nanosecond_timestamp={nanosecond_timestamp}") # 1649100424880418300
"""ctime() 获取当前本地时间字符串"""
str_time = time.ctime()
print(str_time) # Tue Feb 22 22:22:53 2022
"""根据指定时间戳获取本地时间字符串"""
str_time = time.ctime(1645539742)
print(str_time) # Tue Feb 22 22:22:22 2022
"""perf_counter() 或 process_counter性能计数器"""
t1 = time.perf_counter()
s = 0
for i in range(100000):
s+=i
t2 = time.perf_counter()
print(f"{t2-t1=}")
# t2-t1=0.007430800000000001
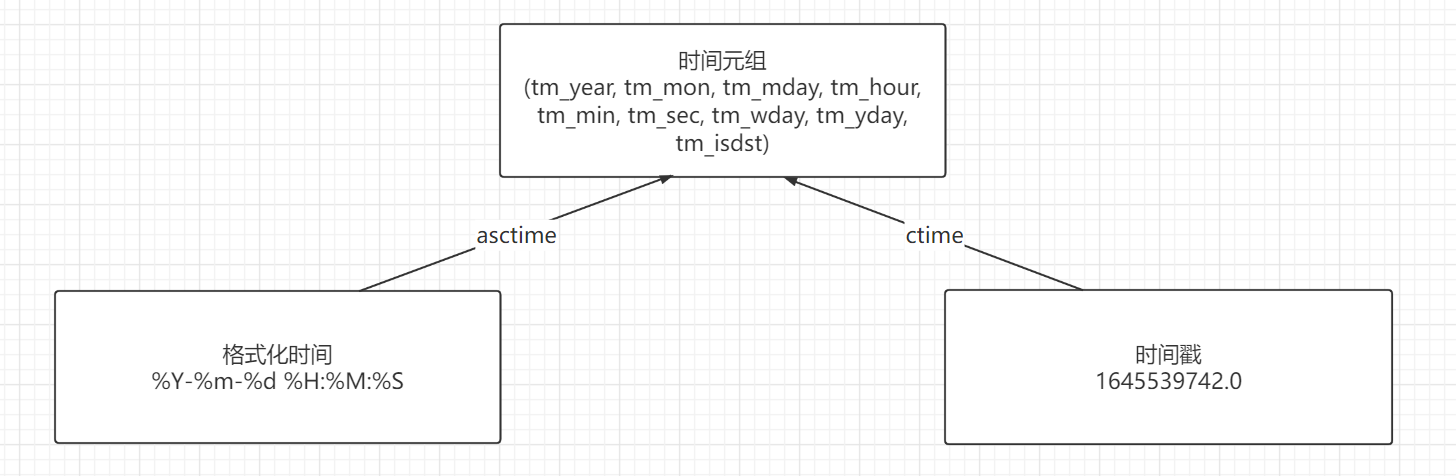
时间元组(struct_time)
时间元组,共有九个代表时间各个单位的成员,是元祖类型。所以只支持两个元祖之间的比较运算。时间元组的格式如下:
time.struct_time(tm_year=2022, tm_mon=2, tm_mday=22, tm_hour=22, tm_min=22, tm_sec=29, tm_wday=1, tm_yday=53, tm_isdst=0)
| 关键字 | 描述 | 格式 |
|---|---|---|
| tm_year | 年 | 四位数年份 |
| tm_month | 月 | 1 - 12 |
| tm_day | 日 | 1 - 31 |
| tm_hour | 时 | 0 - 23 |
| tm_min | 分 | 0 - 59 |
| tm_sec | 秒 | 0 - 61 |
| tm_wday | 周几 | 0 - 6 |
| tm_yday | 年中第几天 | 1 - 366 |
| tm_isdst | 夏令时 | 默认为-1,值为1时是夏令时,值为0时不是夏令时 |
代码:
import time
"""获取本地时间元组"""
timestamp = time.localtime()
print(timestamp)
# time.struct_time(tm_year=2022, tm_mon=2, tm_mday=22, tm_hour=22, tm_min=22, tm_sec=35, tm_wday=1, tm_yday=53, tm_isdst=0)
"""根据指定秒时间戳获取对应时间元祖"""
time_tuple = time.localtime(1645539742.0) # 1695539742.0
print(time_tuple)
# time.struct_time(tm_year=2022, tm_mon=2, tm_mday=22, tm_hour=22, tm_min=22, tm_sec=22, tm_wday=1, tm_yday=53, tm_isdst=0)
"""根据时间元祖获取对应时间戳"""
time_tuple = (2022,2,22,22,22,22,1,0,0)
timestamp = time.mktime(time_tuple)
print(timestamp)
# 1645539742.0
"""获取本地时间字符串"""
str_time = time.asctime()
print(str_time)
# Tue Feb 22 22:23:00 2022
"""通过指定时间元组,获取本地时间字符串"""
time_tuple = (2022,2,22,22,22,22,1,0,0)
str_time = time.asctime(time_tuple)
print(str_time)
# Tue Feb 22 22:22:22 2022
"""获取UTC(世界标准时间/GMT)的时间元组"""
# 获取当前UTC的时间元祖
gmt = time.gmtime()
print(gmt)
# time.struct_time(tm_year=2022, tm_mon=2, tm_mday=22, tm_hour=14, tm_min=23, tm_sec=0, tm_wday=1, tm_yday=53, tm_isdst=0)
# 获取时间戳(timestamp, epoch, 纪元)的起始时间点
ret = time.gmtime(0)
print(ret)
# time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=1, tm_isdst=0)
"""获取指定标准时间的时间元组"""
gmt = time.gmtime(1645539742.0)
print(gmt)
# time.struct_time(tm_year=2022, tm_mon=2, tm_mday=22, tm_hour=14, tm_min=22, tm_sec=22, tm_wday=1, tm_yday=53, tm_isdst=0)
格式化时间(format time)
格式化时间(format time),以格式化字符串的方式让时间更具可读性。支持固定格式和自定义格式,是字符串类型。python中time模块的strftime函数实际上就是C语言的strftime,所以两者一致。以下只是部分格式化占位符:
| 格式占位符 | 描述 | 值范围和举例 |
|---|---|---|
| %Y | 年份 | 0000 - 9999 |
| %m | 月份 | 01 - 12 |
| %d | 日期,一个月中的第几天 | 01 - 31 |
| %H | 小时(24小时制),一天中的第几个小时 | 00 - 23 |
| %I | 小时(12小时制),一天中的第几个小时 | 01 - 12 |
| %p | 上午/下午 | AM,PM |
| %M | 分钟 | 00 - 59 |
| %S | 秒 | 00 - 61 |
| %A | 完整星期名称 | Monday - Sunday |
| %a | 简写星期名称 | Mon - Sun |
| %B | 完整月份名称 | January - December |
| %b | 简写月份名称 | Jan - Dec |
| %j | 一年中的第几天 | 001-366 |
| %U | 一年中的第几周,以第1个星期日作为第1周的第1天。 | 00 - 53 |
| %w | 一个星期中的第几天(0是星期天) | 0-6 |
| %x | 日期表示法 | 月/日/年 |
| %X | 时间表示法 | 时:分:秒 |
| %Z | 时区的名称或缩写,如果不存在为空字符 | 中国标准时间 |
| %% | %字符 | % |
注意:time模块支持获取微秒时间戳,但并不支持格式化微秒,如果要格式化微秒,在后面所学的datetime模块中有格式化%f占位符,用于格式化微秒。
代码:
import time
"""格式化当前日期时间"""
ts = time.strftime("%Y-%m-%d %H:%M:%S")
print(ts)
# 2022-02-22 22:24:32
"""指定自定义格式化日期转秒时间戳"""
dt = '2022-02-22 22:22:22'
ts = int(time.mktime(time.strptime(dt, "%Y-%m-%d %H:%M:%S")))
print(ts)
# 1645539742
# 从复杂文本中提取时间,文本内容和格式化字符串要匹配一致,不能缺少字符。
dt = "今年是2022年,2月22号22点22分22秒:宜婚嫁"
format = "今年是%Y年,%m月%d号%H点%M分%S秒:宜婚嫁"
tuple_time = time.strptime(dt, format)
print(tuple_time)
# time.struct_time(tm_year=2022, tm_mon=2, tm_mday=22, ....)
# 时间元祖转格式化日期时间
str_time = time.strftime("%Y-%m-%d %H:%M:%S", tuple_time)
print(str_time)
# 2022-02-22 22:22:22
"""指定秒时间戳转格式化日期时间"""
ts = 1645539742.456123
dt = time.strftime("%Y-%m-%d %H:%M:%S %Z", time.localtime(ts))
print(dt)
# 2022-02-22 22:22:22 中国标准时间
日期时间模块(Datetime)
datatime模块是python内置的加强版time模块,提供更多关于日期(date)、时间(time)、日期时间(datetime)、时间差(timedelta)、时区信息(timezone)等操作。
| 对象 | 描述 |
|---|---|
| time | 时间对象, 基本不使用 |
| date | 日期对象,基本不使用 |
| datetime | 日期时间对象,常用的属性有hour, minute, second, microsecond |
| timedelta | 时间差,即两个时间点之间的距离或长度 |
| timezone | 时区信息对象,基本不使用 |
datetime.time
| 方法 | 描述 |
|---|---|
| strftime(fmt) | 自定义格式化时间 |
代码:
import datetime
"""创建一个指定time对象"""
d = datetime.time(10, 40, 20)
print(d, type(d), str(d)) # 10:40:20 <class 'datetime.time'> 10:40:20
"""对time对象进行自定义格式化"""
d = datetime.time(10, 40, 20).strftime("%H时%M分%S秒")
print(d) # 10时40分20秒
datetime.date
| 方法 | 描述 | 格式 |
|---|---|---|
| today() | 获取本地系统时间的当天日期对象 | YYYY-mm-dd |
| fromtimestamp(t) | 根据时间戳t获取日期对象 | YYYY-mm-dd |
| timetuple() | 把datetime模块的date日期对象转换time模块的时间元组 | time.struct_time对象 |
| weekday() | 获取指定日期对象是星期几 | 周日是0,周一是1 |
| isocalendar() | 根据指定日期对象获取日期元组 | (YYYY, m, d) |
| strftime(fmt) | 自定义格式化日期 |
代码:
# from datetime import date
import datetime
"""获取本地系统时间的当天date对象"""
# td = datetime.date.today()
# print(td, type(td)) # 2022-04-07 <class 'datetime.date'>
"""获取指定事件的date对象"""
# d1 = datetime.date(2023, 2, 22)
# print(d1, type(d1)) # 2022-02-22 <class 'datetime.date'>
"""根据时间戳获取date对象"""
# ts = 1647087904
# d1 = datetime.date.fromtimestamp(ts)
# print(d1, type(d1)) # 2022-03-12 <class 'datetime.date'>
"""把datetime模块的date对象转换time模块的时间元组"""
# td = datetime.date.today()
# tp = td.timetuple()
# print(tp)
# # time.struct_time(tm_year=2022, tm_mon=4, tm_mday=7, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=97, tm_isdst=-1)
"""获取指定date对象是星期几,周一是0, 周日是6"""
# td = datetime.date.today()
# w = td.weekday()
# print(w) # 3,周四
# 可以指定一个过去或将来的日期
# od = datetime.date(2022,2,22)
# ret = od.weekday()
# print(ret) # 1,周二
"""根据指定date对象获取日期元组(年月日组成的元组)"""
# ret6 = datetime.date.today().isocalendar()
# print(ret6) # datetime.IsoCalendarDate(year=2022, week=14, weekday=4)
# print(tuple(ret6)) # (2022, 14, 4)
"""对date对象进行自定义格式化"""
# ret = datetime.date.today().strftime("%Y年%m月%d日")
# print(ret) # 2022年04月07日
"""datetime.date对象不仅可以支持比较运算,还支持数学运算,数学运算的结果是一个时间差(timedelta)对象"""
d1 = datetime.date(2022,2,22)
d2 = datetime.date(2022,5,1)
td = d2 - d1
print(td) # 68 days, 0:00:00
print(type(td)) # <class 'datetime.timedelta'>
print(td.days) # 68 时间差的天数
print(td.seconds) # 0 时间差除了天数以外的剩余秒数
print(td.total_seconds()) # 5875200.0 时间差的总秒数
datetime.datetime
| 方法 | 描述 | 格式 |
|---|---|---|
| today() | 获取当前本地系统时间的datetime对象 | YYYY-mm-dd HH:MM:SS.ffffff |
| now(tz=None) | 获取当前本地系统时间的datetime对象,可指定时区 | YYYY-mm-dd HH:MM:SS.ffffff |
| utcnow() | 获取当前零时区的datetime对象 | YYYY-mm-dd HH:MM:SS.ffffff |
| fromtimestamp(t, tz=None) | 通过时间戳t获取datetime对象,可指定时区 | YYYY-mm-dd HH:MM:SS |
| strptime(date_string, format) | 对字符串date_string按format格式化字符串转成datetime对象 | YYYY-mm-dd HH:MM:SS |
| strftime(fmt) | 对datetime对象根据fmt格式化转成字符串 | YYYY-mm-dd HH:MM:SS |
| timetuple() | 把datetime对象转换成时间元组 | time.struct_time对象 |
代码:
import datetime
"""通过指定日期来创建datetime对象"""
# dt = datetime.datetime(2022, 2, 22)
# print(dt, type(dt)) # 2022-02-22 00:00:00 <class 'datetime.datetime'>
"""通过指定日期时间来创建datetime对象"""
# dt = datetime.datetime(2022, 2, 22, 10, 30, 42)
# print(dt, type(dt), str(dt)) # 2022-02-22 10:30:42 <class 'datetime.datetime'> 2022-02-22 10:30:42
"""获取当前本地系统时间的datetime对象"""
# # 通过today获取
# td = datetime.datetime.today()
# print(td, type(td)) # 2022-04-07 09:39:01.976394 <class 'datetime.datetime'>
# # 通过now获取
# now = datetime.datetime.now()
# print(now, type(now)) # 2022-04-07 09:39:01.977392 <class 'datetime.datetime'>
"""获取当前零时区的datetime对象 东加西减,我们处于东八区"""
# utcnow = datetime.datetime.utcnow()
# print(utcnow) # 2022-04-07 01:40:52.713571
"""通过时间戳获取datetime对象"""
# dt = datetime.datetime.fromtimestamp(1643772213.713571)
# print(dt) # 2022-02-02 11:23:33.713571
"""datetime对象转时间戳"""
# ts = datetime.datetime.now().timestamp()
# print(ts) # 1649295751.951564
"""datetime对象与日期时间字符串的格式化转换"""
# dt = datetime.datetime.strptime("2022-02-22 12:21:21","%Y-%m-%d %H:%M:%S")
# print(dt, type(dt)) # 2022-02-22 12:21:21 <class 'datetime.datetime'>
# # 获取对应的时间戳
# print(dt.timestamp()) # 1645503681.0
"""需注意:strptime的第一个参数与第二个参数,除了时间数值与格式化占位符对应以外,其他字符必须一致,否则报错!"""
# dt = datetime.datetime.strptime("2022-02-22 12:21:21","%Y/%m/%d %H:%M:%S") # 这里会报错!~
"""将datetime对象格式化为日期时间字符串"""
# fdt = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# print(fdt) # 2022-04-07 09:45:50
# fdt = datetime.datetime.strftime(datetime.datetime.now(), "%Y-%m-%d %H:%M:%S.%f")
# print(fdt) # 2022-04-07 09:46:43.943401
"""datetime对象与时间元组的转换"""
# # datetime.datetime
# tp = datetime.datetime.now().timetuple()
# print(tp)
# # time.struct_time(tm_year=2022, tm_mon=4, tm_mday=7, tm_hour=9, tm_min=47, tm_sec=40, tm_wday=3, tm_yday=97, tm_isdst=-1)
# print(tuple(tp)) # (2022, 4, 7, 9, 47, 56, 3, 97, -1)
# 也可以还原
# tt = (2022, 2, 2, 11, 31, 16, 2, 33, -1)[:6]
# dt = datetime.datetime(*tt)
# print(dt) # 2022-02-02 11:31:16
"""datetime对象,不仅支持比较,也支持数学运算,数学运算的结果是一个时间差对象(timedelta)"""
# 例如:有个清明节亲子郊游活动,活动报名截止时间是:2022-04-10 00:00:00,根据当前时间,得到剩余的报名时间
now = datetime.datetime.now()
end = datetime.datetime.strptime("2022-04-10 00:00:00", "%Y-%m-%d %H:%M:%S")
td = end - now
print(td, type(td)) # 2 days, 14:06:14.479526 <class 'datetime.timedelta'>
print(td.days, td.seconds) # 2 50856 2天50856秒
print(td.total_seconds()) # 223645.374982 总秒数
datetime.timedelta
timedelta对象,也叫时间差或时间距离。使用timedelta可以很方便的在日期上做周weeks,天days,小时hours,分钟minutes,秒seconds,毫秒milliseconds,微妙microseconds的时间差计算。
| 单位 | 描述 |
|---|---|
| 1 days = 24 hours = 24 * 3600 seconds = 86400 seconds | 1天 = 24小时 = 86400秒 |
| 1 hour = 60 minutes = 3600 seconds | 1小时 = 60分钟 = 3600秒 |
| 1 minute = 60 seconds | 1分钟 = 60秒 |
| 1 second = 1000 millisecond | 1秒 = 1000毫秒 |
| 1 millisecond = 1000 microseconds | 1毫秒 = 1000 微秒 |
| 1 microseconds = 1000 nanoseconds | 1 微妙 = 1000 纳秒 |
基本使用
from datetime import timedelta
"""
# 创建一个时间差对象
timedelta(
days=天,
seconds=秒,
microseconds=微秒,
milliseconds=毫秒,
minutes=分,
hours=时,
weeks=周
)
"""
# 2周的时间差对象
delta = timedelta(weeks=2)
print(delta) # 14 days, 0:00:00
# 1周半的时间差对象
delta = timedelta(weeks=1.5)
print(delta) # 10 days, 12:00:00
delta = timedelta(weeks=1, days=3, hours=12)
print(delta) # 10 days, 12:00:00
# 3天的时间差对象
delta = timedelta(days=3)
print(delta) # 3 days, 0:00:00
# 3天半的时间差对象
delta = timedelta(days=3.5)
print(delta) # 3 days, 12:00:00
delta = timedelta(days=3, hours=12)
print(delta) # 3 days, 12:00:00
# 6小时的时间差对象
delta = timedelta(hours=6)
print(delta) # 6:00:00
# 6.5小时的时间差对象
delta = timedelta(hours=6.5)
print(delta) # 6:30:00
delta = timedelta(hours=6, minutes=30)
print(delta) # 6:30:00
# 12分钟的时间差对象
delta = timedelta(minutes=12)
print(delta) # 0:12:00
# 30秒的时间差对象
delta = timedelta(seconds=30)
print(delta) # 0:00:30
# 20分15秒的时间差对象
delta = timedelta(minutes=20, seconds=15)
print(delta) # 0:20:15
注意:如果要做年years,月months的时间差计算,则可以使用datetime的增强版python-dateutil模块的relativedelta对象来实现。dateutil是一个非官方的第三方模块,需要进行安装才可以使用。
常用操作
| 方法 | 描述 | 用法1 | 用法2 |
|---|---|---|---|
__eq__(…) |
等于 | x.__eq__(y) |
x == y |
__ge__(…) |
大于等于 | x.__ge__(y) |
x >= y |
__gt__(…) |
大于 | x.__gt__(y) |
x > y |
__le__(…) |
小于等于 | x.__le__(y) |
x <= y |
__lt__(…) |
小于 | x.__lt__(y) |
x < y |
__ne__(…) |
不等于 | x.__ne__(y) |
x != y |
__sub__(…) |
减法 | x.__sub__(y) |
x - y |
__add__(...) |
加法 | x.__add__(y) |
x + y |
__mul__(...) |
乘法 | x.__mul__(y) |
x * y |
__truediv__(...) |
除法 | x.__truediv__(y) |
x / y |
__floordiv__(...) |
整除 | x.__floordiv__(y) |
x // y |
__mod__(...) |
取模 | x.__mod__(y) |
x % y |
__divmod__(...) |
除法取模 | x.__divmod__(y) |
(x // y, x % y) |
注意:上面所有操作中,time对象只支持比较操作,date、datetime等对象支持任意比较与加减运算操作,timedelta对象支持所有操作。
代码:
import datetime
"""获取3天前的datetime对象"""
# # 先创建3天的时间差对象
# delta = datetime.timedelta(days=3)
# # 再生成当前datetime时间对象
# now = datetime.datetime.now()
# 过去的时间就是当前时间 - 时间差
# dt = now - delta
# print(dt) # 2022-04-04 10:07:46.542835
"""获取25天后的datetime对象"""
# # 先创建25天的时间差对象
# delta = datetime.timedelta(days=25)
# # 当前datetime对象
# now = datetime.datetime.now()
# # 未来的时间 = 当前时间 +时间差
# dt = now + delta
# print(dt) # 2022-05-02 10:09:55.940294
"""计算当前时间距离未来某个时间的剩余时间"""
# # 计算当前时间距离五一劳动节还有多久?
# now = datetime.datetime.now()
# future = datetime.datetime(2022, 5, 1)
# # 未来时间 - 当前时间
# delta1 = future - now
# print(delta1) # 23 days, 13:48:23.861568
#
# # 当前时间 - 未来时间
# delta2 = now - future
# print(delta2) # -24 days, 10:12:14.123377
"""计算当前时间距离过去某个时间的逝去时间"""
# # 如果当前时间是2022-03-02 22:11:29,那么小红看到了小明在2022-01-02 12:30:00发布的一个微信动态距离当前时间过去多久了?
# dt1 = datetime.datetime.strptime("2022-01-02 12:30:00", "%Y-%m-%d %H:%M:%S")
# dt2 = datetime.datetime.strptime("2022-03-02 22:11:29", "%Y-%m-%d %H:%M:%S")
# # dt2 = datetime.datetime.now()
#
# # 当前时间 - 过去时间
# delta = dt2 - dt1
# print(delta) # 59 days, 9:41:29
#
# # 过去时间 - 当前时间
# delta = dt1 - dt2
# print(delta) # -60 days, 14:18:31
datetime.timezone
代码:
import datetime
"""北京时间(东八区) 转 伦敦时间(中时区)"""
# now = datetime.datetime.now()
# print(now) # 2022-04-07 10:23:32.834242
# # 中时区
# tz = datetime.timezone(datetime.timedelta(hours=0))
# print(tz) # UTC
# 转中时区时间
# utc_london = now.astimezone(tz)
# print(utc_london) # 2022-04-07 02:25:24.844142+00:00
"""北京时间(东八区) 转 纽约时间(西五区)"""
# now = datetime.datetime.now()
# print(now) # 2022-04-07 10:23:32.834242
#
# # 西五区时间差
# tz = datetime.timezone(datetime.timedelta(hours=-5))
#
# NewYork = now.astimezone(tz)
# print(NewYork) # 2022-04-06 21:28:01.863718-05:00
"""
练习:假设现在是北京时间:2022-04-06 13:00:00,日本东京处于东九区,那么计算下日本的当前时间?
"""
now = datetime.datetime.strptime("2022-04-06 13:00:00", "%Y-%m-%d %H:%M:%S")
tz = datetime.timezone(datetime.timedelta(hours=+9))
jp = now.astimezone(tz)
print(jp) # 2022-04-06 14:00:00+09:00
事实上,时区转换在开发中一般常用的是第三方模块-pytz模块。
日历模块(calendar)
常用操作
| 方法 | 描述 |
|---|---|
| calendar(theyear, w=2, l=1, c=6, m=3) | 按指定年份返回字符串格式的一整年的日历,左起周一 |
| month(self, theyear, themonth, w=0, l=0) | 按指定年月返回字符串格式的一整月的日历,左起周一 |
| monthcalendar(year, month) | 按指定年月返回列表格式的日历信息,左起周一 |
| isleap(year) | 判断指定年份是否是闰年(能被4整除的 or 不能为100整除能被400整除的) |
| leapdays(y1, y2) | 指定从某年到某年范围内的润年个数 |
| monthrange(year, month) | 获取指定年月的信息,返回值是元组(当月首日在周几[周一是0,周日是6],当月总天数) |
| weekday(year, month, day) | 获取指定日期是星期几,周一是0,周日是6 |
| timegm(tuple) | 将时间元组转化为时间戳 |
代码演示
import calendar
import time
"""
获取指定年份的日历字符串 (年份, w日期间的宽度=2,l日期间的高度=1, c月份间的横向间距=6, m一行显示几个月份=3)
"""
data = calendar.calendar(2022, w=0, l=0, c=5, m=4)
print(data)
# 2022
#
# January February March April
# Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
# 1 2 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3
# 3 4 5 6 7 8 9 7 8 9 10 11 12 13 7 8 9 10 11 12 13 4 5 6 7 8 9 10
# 10 11 12 13 14 15 16 14 15 16 17 18 19 20 14 15 16 17 18 19 20 11 12 13 14 15 16 17
# 17 18 19 20 21 22 23 21 22 23 24 25 26 27 21 22 23 24 25 26 27 18 19 20 21 22 23 24
# 24 25 26 27 28 29 30 28 28 29 30 31 25 26 27 28 29 30
# 31
#
# May June July August
# Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
# 1 1 2 3 4 5 1 2 3 1 2 3 4 5 6 7
# 2 3 4 5 6 7 8 6 7 8 9 10 11 12 4 5 6 7 8 9 10 8 9 10 11 12 13 14
# 9 10 11 12 13 14 15 13 14 15 16 17 18 19 11 12 13 14 15 16 17 15 16 17 18 19 20 21
# 16 17 18 19 20 21 22 20 21 22 23 24 25 26 18 19 20 21 22 23 24 22 23 24 25 26 27 28
# 23 24 25 26 27 28 29 27 28 29 30 25 26 27 28 29 30 31 29 30 31
# 30 31
#
# September October November December
# Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
# 1 2 3 4 1 2 1 2 3 4 5 6 1 2 3 4
# 5 6 7 8 9 10 11 3 4 5 6 7 8 9 7 8 9 10 11 12 13 5 6 7 8 9 10 11
# 12 13 14 15 16 17 18 10 11 12 13 14 15 16 14 15 16 17 18 19 20 12 13 14 15 16 17 18
# 19 20 21 22 23 24 25 17 18 19 20 21 22 23 21 22 23 24 25 26 27 19 20 21 22 23 24 25
# 26 27 28 29 30 24 25 26 27 28 29 30 28 29 30 26 27 28 29 30 31
# 31
"""获取指定年月的日历字符串 (年份,月份,w日期之间的宽度=0,l日期之间的高度=0)"""
data = calendar.month(2022, 10, w=0, l=0)
print(data)
# October 2022
# Mo Tu We Th Fr Sa Su
# 1 2
# 3 4 5 6 7 8 9
# 10 11 12 13 14 15 16
# 17 18 19 20 21 22 23
# 24 25 26 27 28 29 30
# 31
"""获取指定年月的信息列表 (年份,月份) 左起周一"""
ret = calendar.monthcalendar(2022, 10)
print(ret)
# [
# [0, 0, 0, 0, 0, 1, 2],
# [3, 4, 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14, 15, 16],
# [17, 18, 19, 20, 21, 22, 23],
# [24, 25, 26, 27, 28, 29, 30],
# [31, 0, 0, 0, 0, 0, 0]
# ]
"""判断指定年份是否是闰年(能被4整除的 or 不能为100整除能被400整除的)"""
ret = calendar.isleap(2020)
print(ret) # True
ret = calendar.isleap(2022)
print(ret) # False
"""指定从某年到某年范围内的润年个数"""
ret = calendar.leapdays(2000, 2022)
print(ret) # 6
"""获取指定年月的信息,返回值是元组(当月首日在周几[周一是0,周日是6],当月总天数)"""
ret = calendar.monthrange(2022, 2)
print(ret) # (1, 28)
"""获取指定日期是星期几,周一是0,周日是6"""
ret = calendar.weekday(2022, 5, 1)
print(ret) # 6
"""将时间元组转化为时间戳"""
tp = time.localtime()
ts = calendar.timegm(tp)
print(ts) # 1649133150
数据转换
在数据存储和读取过程中,一般需要数据转换,因为不管网络传输也好,还是保存数据到文件也罢,都只支持保存字符串或者二进制bytes类型数据,因此很多时候,针对python中如列表,元组,字典等数据类型,我们都需要进行格式转换,而格式转换过程中就涉及到两个概念了。
# 序列化
把不可直接存储的数据格式变成可存储数据格式,这个过程就是序列化过程。例如:字典/列表/对象等 => 字符串。
# 反序列化
把可存储数据格式进行格式还原,这个过程就是反序列化过程。例如:字符串还原成字典/列表/对象等。
在python中用于对数据类型进行格式化转换的方法有很多,内置模块有:json,pickle,base64等,第三方模块有:marshmallow等。
json模块
JSON(JavaScript Object Notation,译作:javascript对象表示法) 是一种轻量级的数据交换格式,易于人阅读和编写,常用于不同平台,不同编程语言之间进行数据传输,也常用于对编程开发过程中的数据存储结构或项目配置文件。
json起源于编程语言javascrpt,但独立于编程语言,在非常多的语言里面都有对应的模块或者语法支持。python中用于操作json的模块:json,rjson。
注意:在python中默认就是符合json语法的字符串数据。我们可以基于json相关的操作模块,可以实现json字符串转换成字典/列表,反之,也可以
基本语法
JSON 文件的文件类型是 ".json"。JSON 文本的网络MIME类型是 "application/json"或"text/json"。
在 JSON 中,数据的值必须是以下数据类型之一:
| json类型 | 等价于python的类型 | 语法 | 举例 |
|---|---|---|---|
| 字符串(string) | 字符串(str) | 字符串必须使用双引号包含。 | "hello" |
| 数值(number) | 整型(int), 浮点型(float) |
数值,只支持十进制,也不支持表达式。 | 1 1.3 |
| 布尔值(boolean) | 布尔型(bool) | 单词必须全部小写 | true false |
| 对象(object) | 字典(dict) | json对象由键值对成员组成,使用花括号嵌套, 成员间使用逗号隔开,最后一个成员不能加逗号。 键必须使用字符串,而值可以是任意json数据类型。 键和值之间使用英文冒号映射起来。 |
{"name":"xiaoming", "age": 16} |
| 数组(array) | 列表(list), 元组(tuple), 集合(set) |
数组成员使用逗号隔开,最后一个成员不能加逗号。 数组成员的值可以是任意json数据类型。 |
["A", "B", "C"] [1, 3, 4] |
| 空(null) | None | 空,代表没有值, | null |
注意:一般一个json文件中,要门就是一个对象,要么就是一个数组。
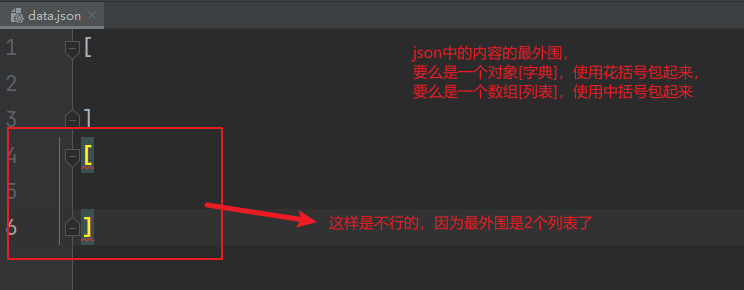
data.json,代码:
{
"name": "小明",
"age": 16,
"lve": ["football", "basketball", "TVgame"],
"sex": true,
"friends": [
{"name": "小黑", "age": 16, "sex": true},
{"name": "小白", "age": 15, "sex": true},
{"name": "小红", "age": 15, "sex": false}
]
}
demo.json,代码:
[
{"id":10, "title": "浪潮之巅", "price": 87.5},
{"id":2, "title": "编程珠玑", "price": 100},
{"id":3, "title": "代码大全", "price": 55},
{"id":4, "title": "人月神话", "price": 62},
{"id":7, "title": "代码之髓", "price": 90}
]
json模块常用操作
| 方法 | 描述 |
|---|---|
| json.dump(obj, fp, indent=None, ensure_ascii=True) | 把数据obj序列化转换格式为json字符串并写入到fp文件对象中 |
| json.dumps(obj, indent=None, ensure_ascii=True) | 把数据obj序列化转换格式为json字符串 |
| json.loads(s) | json格式字符串反序列化还原数据格式 |
| json.load(s) | 从指定文件fp中读取内容并反序列化还原数据格式 |
代码:
import json
"""
json在python中就是字符串类型,但是该字符串必须符合json语法。
序列化方法
json.dump(obj, fp, indent=None, ensure_ascii=True)
把数据obj转换格式为json字符串并写入到fp文件对象中.
如果指定indent,则按长度缩进写入
如果指定ensure_ascii=True,则对多字节字符转换成unicode编码
json.dumps(obj, indent=None, ensure_ascii=True)
把数据obj转换格式为json字符串
如果指定indent,则按长度缩进写入
如果指定ensure_ascii=True,则对多字节字符转换成unicode编码
"""
"""写入数据到json文件中"""
# data = {"name": "小明", "age": 13}
# fp = open("data.json", "w", encoding="utf-8")
# json.dump(data, fp, indent=None, ensure_ascii=False)
# """字典数据转换json格式字符串"""
# data = [1,2,3, "小明"]
# json_str = json.dumps(data, indent=4, ensure_ascii=False)
# print(json_str)
# # [
# # 1,
# # 2,
# # 3,
# # "小明"
# # ]
# """json格式字符串反序列化还原数据格式"""
# json_str = """
# [
# 1,
# 2,
# 3,
# "小明"
# ]
# """
# data = json.loads(json_str)
# print(data, type(data)) # [1, 2, 3, '小明'] <class 'list'>
"""从指定文件中读取json数据并反序列化"""
data = json.load(open("data.json", "r", encoding="utf-8"))
print(data) # {'name': '小明', 'age': 13}
pickle模块
json提供了json字符串与其他数据格式之间的序列化和反序列化操作,而pickle与json不同的是,pickle模块实现了用于对Python对象结构进行 序列化 和 反序列化 的二进制协议。所以pickle处理过的数据是二进制安全bytes类型,而且仅能被python所处理。当然,因为pickle类型处理数据后的数据是二进制的,所以对于数据相对于json格式而言,更加紧凑,性能更好。
| 方法 | 描述 |
|---|---|
| dumps | 把任意对象序列化成一个bytes |
| dump | 把对象序列化后写入到file-like Object(即文件对象) |
| loads | 把任意bytes反序列化成原来数据 |
| load | 把file-like Object(即文件对象)中的内容拿出来,反序列化成原来数据 |
代码:
import pickle
"""
pickle
"""
"""序列化一个数据成bytes类型"""
data = {"name": "小明", "age": 13}
ret = pickle.dumps(data)
print(ret) # b'\x80\x04\x95\x1d\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x04name\x94\x8c\x06\xe5\xb0\x8f\xe6\x98\x8e\x94\x8c\x03age\x94K\ru.'
"""序列化一个数据成bytes类型并写入指定文件"""
data = {"name": "小明", "age": 13}
fp = open("1.db", "wb")
pickle.dump(data, fp)
"""把数据反序列化还原格式"""
bs = b'\x80\x04\x95\x1d\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x04name\x94\x8c\x06\xe5\xb0\x8f\xe6\x98\x8e\x94\x8c\x03age\x94K\ru.'
data = pickle.loads(bs)
print(data, type(data)) # {'name': '小明', 'age': 13} <class 'dict'>
"""从指定文件中读取数据并反序列化还原格式"""
fp = open("1.db", "rb")
data = pickle.load(fp)
print(data, type(data)) # {'name': '小明', 'age': 13} <class 'dict'>
"""pickle的强大之处在于,除了能处理8种基本数据类型以外,针对后面所学的面向对象的数据类型也支持"""
class People(object):
def __init__(self, name, age):
self.name = name
self.age = age
def introduction(self):
return f"我叫{self.name},今年已经{self.age}岁"
p1 = People("小明", 13)
print(p1)
data = pickle.dumps(p1)
print(data)
# b'\x80\x04\x957\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x06People\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94\x8c\x06\xe5\xb0\x8f\xe6\x98\x8e\x94\x8c\x03age\x94K\rub.'
data = b'\x80\x04\x957\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x06People\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94\x8c\x06\xe5\xb0\x8f\xe6\x98\x8e\x94\x8c\x03age\x94K\rub.'
p2 = pickle.loads(data)
print(p2)
print(p2.name)
print(p2.age)
print(p2.introduction())
json模块对比pickle模块
1. json模块常用于将Python数据转换为通用的json格式传递给其它系统或客户端,常见于web开发,测试开发,运维开发。
pickle模块常用于将python数据转换为二进制格式数据,其序列化之后的数据只能被Python识别,因此只能用于Python系统内部。
2. json序列化后的数据本质上还是字符串,所以明文显示,没有任何保密性,数据存储不够紧凑,存在空间浪费
pickle序列化后的数据是二进制安全bytes类型,不会明文显示,具有一定保密性,数据存储格式紧凑,性能优越。
3. 都是内置模块,所以都有更优的替代方案。
内置的json模块采用C语言编写,针对于海量数据转换来说,可以考虑rust开发的rjson模块。
内置的pickle模块,虽然性能较好,但是保密性不足,跨平台性不足,此时可以考虑采用itsdangrous模块。
安全加密
hashlib模块
hash,译作哈希,散列。哈希是一种不可逆的映射过程,实现了这个映射过程的函数,叫哈希函数,也叫散列函数或杂凑函数。
哈希的本质,就是把任意长度的输入内容,通过Hash算法变成不可逆的固定长度的输出内容(哈希值,散列值,消息摘要),输出内容通常用16进制的字符串表示。
哈希的过程是单向的,只有加密,没有解密。因此你可以把字符串进行哈希获取哈希值,但无法从哈希值逆转获取原始字符串。
哈希常用于信息加密,开发中的常见应用场景有:数据加密,数据校验,复杂均衡等。
自定义一个简单的哈希算法。自定义哈希函数通常可利用除留余数、移位、循环哈希、平方取中等方法。
# 假设存储散列长度为8,则排列空间是:0, 1, 2, 3, 4, 5, 6, 7
def my_hash(num):
return num % 7 ^ 2 # 取模,异或
print(my_hash(1)) # 3
print(my_hash(2)) # 0
print(my_hash(4)) # 6
print(my_hash(7)) # 2
print(my_hash(8)) # 3, 散列值与1重复了。
上面实现的哈希函数比较简单,所以可以看到,存储的数据值超过散列空间以后,就出现散列值重复的情况了。
对于hash函数,不同的数据应该生成不同的哈希值。如果两个不同的数据经过Hash函数计算得到的Hash值一样,就称为哈希碰撞(collision,也叫哈希冲突)。哈希碰撞无法被完全避免。只能采用各种方法来尽量避免,降低发生的概率。当然,虽然我们实现的哈希函数不行,但是python里面提供了比我们声明的要更好的内置函数hash()。
print(hash(14)) # 14
print(hash(100014)) # 100014
print(hash(False)) # 0
print(hash("")) # 0
print(hash(465258685558744706)) # 465258685558744706
print(hash(1000000000000000000000000000000)) # 465258685558744706
可以发现,即便是python内置的hash函数在某些值存储过程中,还是出现了哈希冲突。这时候,我们就应该采用更加安全,更加可靠的hashlib模块了。hashlib主要提供字符加密功能,将md5和sha模块整合到了一起,支持md5,sha1, sha224, sha256, sha384, sha512等算法。
import hashlib
"""md5加密"""
content = "hello world"
md5 = hashlib.md5()
md5.update(content.encode('utf-8')) # hash是基于字节的,所以需要注意编码问题
res = md5.hexdigest()
print(f"加密结果:{res}") # 5eb63bbbe01eeed093cb22bb8f5acdc3
"""针对大数据的哈希计算,可以分多次哈希,最终的哈希值是一样的"""
md5 = hashlib.md5()
md5.update('welcome to python! welcome to beijing!'.encode('utf-8'))
print(md5.hexdigest()) # a1b89154c1e7274499530cd8b3e7f278
md5 = hashlib.md5()
md5.update('welcome to python! '.encode('utf-8'))
print(md5.hexdigest()) # 891a55288ee147f8d5725bf22c956a9f
md5.update('welcome to beijing!'.encode('utf-8'))
print(md5.hexdigest()) # a1b89154c1e7274499530cd8b3e7f278
"""sha1加密"""
content = "hello world"
sha1 = hashlib.sha1()
sha1.update(content.encode('utf-8'))
res = sha1.hexdigest()
print(f"加密结果:{res}") # 2aae6c35c94fcfb415dbe95f408b9ce91ee846ed
"""sha256"""
content = "hello world"
sha256 = hashlib.sha256()
sha256.update(content.encode('utf-8'))
res = sha256.hexdigest()
print(f"加密结果:{res}") # b94d27b9934d3e08a52e52d7da7dabfac484efe37a5380ee9088f7ace2efcde9
"""sha384"""
content = "hello world"
sha384 = hashlib.sha384()
sha384.update(content.encode('utf-8'))
res = sha384.hexdigest()
print(f"加密结果:{res}")
# fdbd8e75a67f29f701a4e040385e2e23986303ea10239211af907fcbb83578b3e417cb71ce646efd0819dd8c088de1bd
"""sha512"""
content = "hello world"
sha512= hashlib.sha512()
sha512.update(content.encode('utf-8'))
res = sha512.hexdigest()
print(f"加密结果:{res}")
# 309ecc489c12d6eb4cc40f50c902f2b4d0ed77ee511a7c7a9bcd3ca86d4cd86f989dd35bc5ff499670da34255b45b0cfd830e81f605dcf7dc5542e93ae9cd76f
hmac模块
哈希是一种单向固定映射过程,所以同样的内容通过Hash算法得出的哈希值是一样的,在一些需要安全要求更高的领域中,例如用户的登陆密码等场景下,hash就变得有点呆滞愚蠢了。这时候如果黑客通过彩虹表(rainbow table,一种密码破解的工具)根据哈希值反推原始登陆密码,那么用户在服务器中的数据就变得不安全。所以,需要使用hmac等安全级别更高的加密模块。hmac是一种基于Hash函数和密钥进行消息认证的方法,使用hmac函数比标准hash函数更安全,只要改动秘钥(盐值),同样的数据,也会产生不同的哈希值。
代码:
import hmac, secrets, string
message = "123456"
characters = string.ascii_letters + string.digits
key = "".join(secrets.choice(characters) for i in range(6))
h = hmac.new(key.encode(encoding="utf-8"), message.encode(encoding="utf-8"), digestmod='SHA1')
print(h.hexdigest())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号