基于密度的聚类算法—DBSCAN
参考的文章:
(66条消息) 聚类方法:DBSCAN算法研究(1)--DBSCAN原理、流程、参数设置、优缺点以及算法_XianenZhou的博客-CSDN博客_dbscan算法
(66条消息) DBSCAN算法python实现(附完整数据集和代码)_Joyce_Ff的博客-CSDN博客_dbscan算法python实现
Visualizing DBSCAN Clustering (naftaliharris.com)DBSCAN聚类可视化网站
一、算法由来
基于距离的聚类算法的聚类结果是球状的簇,当数据集中的聚类结果是非球状结构时,基于距离的聚类算法的聚类效果并不好。与基于距离的聚类算法不同的是,基于密度的聚类算法可以发现任意形状的聚类。
DBSCAN具有以下特点:
- 基于密度,对远离密度核心的噪声鲁棒
- 无需知道聚类簇的数量
- 可以发现任意形状的聚类簇
- 通常适合于对低维数据进行聚类分析

二、DBSCAN算法原理
1.一个核心思想
基于密度。直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。
2.两个算法参数
邻域半径Eps和最少点数目MinPoints;
当邻域半径R内的点的个数大于最少点数目MinPoints时,就是密集。
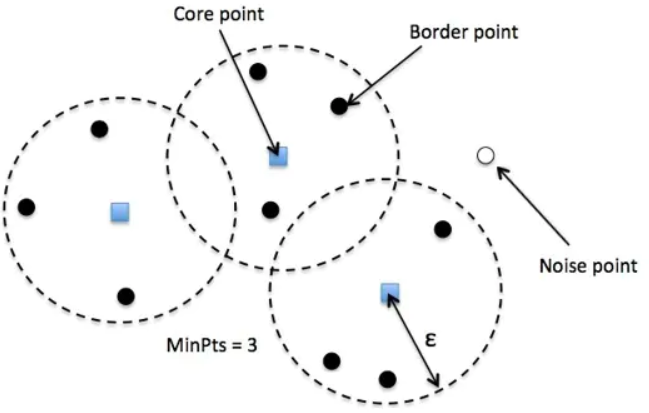
3.三种点的类别
核心点,边界点和噪声点;
邻域半径EPS内样本点的数量大于等于minpoints的点叫做核心点。
不属于核心点但在某个核心点的邻域内的点叫做边界点。
既不是核心点也不是边界点的是噪声
4.四种点的关系
密度直达,密度可达,密度相连,非密度相连。
如果P为核心点,Q在P的邻域内,那么称P到Q密度直达。任何核心点到其自身密度直达,密度直达不具有对称性,如果P到Q密度可达,那么Q到P不一定密度可达。
如果存在核心点P2,P3,……,Pn,且P1到P2密度直达,P2到P3密度直达,……,P(n-1)到Pn密度直达,Pn到Q密度直达,则P1到Q密度可达。密度可达也不具有对称性。
如果存在核心点S,使得S到P和Q都密度可达,则P和Q密度相连。密度相连具有对称性,如果P和Q密度相连,那么Q和P也一定密度相连。密度相连的两个点属于同一个聚类簇。
如果两个点不属于密度相连关系,则两个点非密度相连。非密度相连的两个点属于不同的聚类簇,或者其中存在噪声点。
三、算法步骤
先找到一个未访问的点p,若该点是核心点,则创建一个新的簇C,将其邻域中的点放入该簇,并遍历其邻域中的点;
若其邻域中有点q为核心点,则将q的邻域内的点也划入簇C;
直到C不再扩展;
直到最后所有的点都标记为已访问。
标记点是否被访问:设置了两个列表,一个存放未访问的点unvisited,一个存放已访问的点visited。每次访问一个点,unvisited列表remove该点,visited列表append该点,以此来实现点的标记改变。
四、伪代码
输入:数据集D,最小邻域点数:MinPts,邻域半径:Eps
输出:簇集合

五、时空复杂度
1.时间复杂度
(1)DBSCAN的基本时间复杂度是 O(N*找出Eps领域中的点所需要的时间), N是点的个数。最坏情况下时间复杂度是O(N2)
(2)在低维空间数据中,有一些数据结构如KD树,使得可以有效的检索特定点给定距离内的所有点,时间复杂度可以降低到O(NlogN)
2.空间复杂度:
低维和高维数据中,其空间都是O(N),对于每个点它只需要维持少量数据,即簇标号和每个点的标识(核心点或边界点或噪音点)
六、优缺点
1.优点
(1)聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类;
(2)与K-MEANS比较起来,不需要输入要划分的聚类个数;
(3)聚类簇的形状没有偏倚;
(4)可以在需要时输入过滤噪声的参数。
2.缺点
(1)当数据量增大时,要求较大的内存支持I/O消耗也很大;
(2)当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差,因为这种情况下参数MinPts和Eps选取困难。
(3)算法聚类效果依赖于距离公式选取,实际应用中常用欧式距离,对于高维数据,存在“维数灾难”。
七、参数设计
DBSCAN共包括3个输入数据:数据集D,最小邻域点数:MinPts,邻域半径:Eps,其中Eps和MinPts需要根据具体应用人为设定。
1.Eps
Eps的值可以使用绘制k-距离曲线(k-distance graph)方法得当,在k-距离曲线图明显拐点位置为对应较好的参数。若参数设置过小,大部分数据不能聚类;若参数设置过大,多个簇和大部分对象会归并到同一个簇中。
K-距离:给定K邻域参数k,对于数据中的每个点,计算对应的第k个最近邻域距离,并将数据集所有点对应的最近邻域距离按照降序方式排序,称这幅图为排序的k距离图,选择该图中第一个谷值点位置对应的k距离值设定为Eps。
一般将k值设为4。
2.MinPts
MinPts的选取有一个指导性的原则(a rule of thumb),MinPts≥dim+1,其中dim表示待聚类数据的维度。MinPts设置为1是不合理的,因为设置为1,则每个独立点都是一个簇,MinPts≤2时,与层次距离最近邻域结果相同,因此,MinPts必须选择大于等于3的值。若该值选取过小,则稀疏簇中结果由于密度小于MinPts,从而被认为是边界点儿不被用于在类的进一步扩展;若该值过大,则密度较大的两个邻近簇可能被合并为同一簇。因此,该值是否设置适当会对聚类结果造成较大影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号