行锁死锁的两种场景和解决策略_redis的watch机制和setnx机制_实现分布式锁的三种实现_kafka和rabbitmq的区别_详解java NIO之Channel(通道)
行锁死锁的两种场景和解决策略
死锁的第一种场景:获取同一个记录产生死锁
由于在行锁中,锁是逐步得到的,主要分为两步:锁住主键索引,锁住非主键索引。如:当两个事务同时执行时,一个锁住了主键索引,在等待其余索引;另外一个锁住了非主键索引,在等待主键索引。这样便会发生死锁。InnoDB通常均可以检测到这种死锁,并使一个事务释放锁回退,另外一个获取锁完成事务。
5死锁、死锁检测
当并发系统中不同线程出现循环资源依赖,涉及的线程都在等待别的线程释放资源时,就会导致这几个线程进入无限等待的状态,称为死锁
。
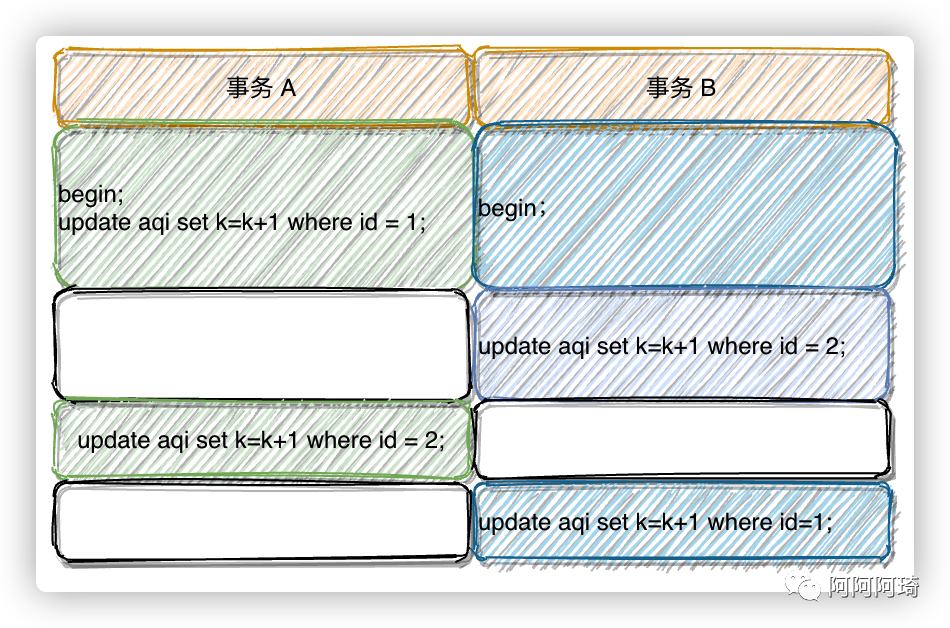
这时候,事务 A 在等待事务 B 释放 id=2 的行锁,而事务 B 在等待事务 A 释放 id=1 的行锁。事务 A 和事务 B 都在互相等待对方的资源释放,这就进入了死锁的状态。当出现死锁以后,有两种策略:
- 一种策略是,直接进入等待,直到超时。这个超时时间可以通过参数
innodb_lock_wait_timeout
来设置。 - 第二种策略是,发起死锁检测,检测到死锁后,主动回滚死锁链条中的某个事物,让其他事物得以继续执行。将参数
innodb_deadlock_delect
设置为on
,表示开启这个逻辑。
在 innodb 中,innodb_lock_wait_timeout 的默认值是 50s,意味着如果采用第一个策略,当出现死锁以后,第一个被锁住的线程要过 50s 才会超时退出,然后其他线程才有可能继续执行。对于一个在线服务来说,这个等待时间往往是无法接受的。
但如果把这个时间设置成一个很小的值,又会有误伤。
所以正常情况下一般采用第二种策略 -- 主动死锁检测,而且 innodb_deadlock_detect
默认 on
。主动检测发生死锁时,是能够快速发现并进行处理的,但它也有额外负担。
按照上面第二种的话,每当一个事务被锁的时候,就要看看它所依赖的线程有没有被别人锁住,如此循环,最后判断是否出现了循环等待 -- 死锁。
那么每个新来的被堵住的线程,都要判断会不会由于自己的加入导致了死锁,这是一个时间复杂度是 O(n)的操作。
假设有 1000 个并发线程要同时更新同一行,那么死锁检测操作就是 100 万这个量级的。虽然最终检测的结果是没有死锁,但是期间要消耗大量的 CPU 资源。因此,就会看到 CPU 利用率很高,但是每秒却执行不了几个事务。
这种热点行更新导致的性能问题症结在于,死锁检测要耗费大量的 CPU 资源,解决策略有以下几种:
- 降低并发度
- 拆行,一行拆多行
- Server 层限流,即同一时间进入更新的线程数
- 关闭死锁监测(关闭的弊端是可能超时较多)
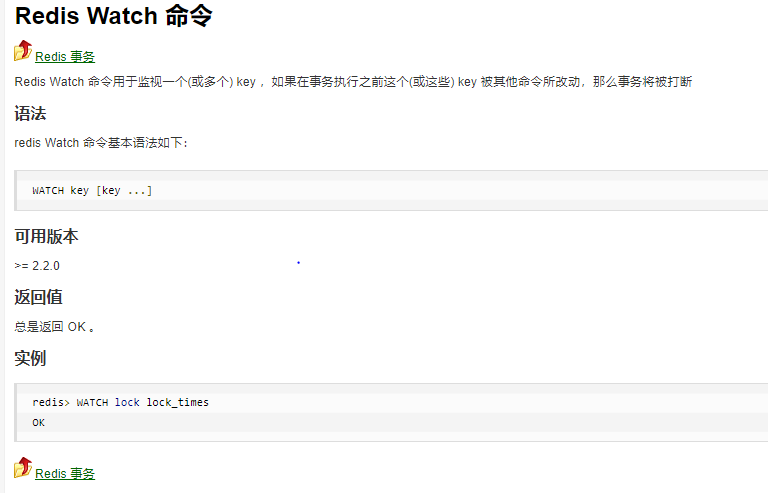
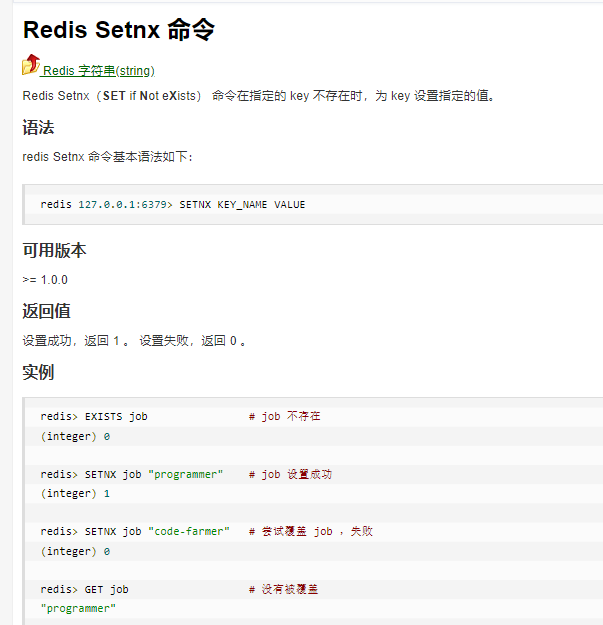
实现分布式锁的三种实现



kafka和rabbitmq的区别
(1)开发语言不同
1、RabbitMQ是高并发的erlanng语言开发。
2、kafka是基于Scala和Java语言开发,主要用于处理活跃的流式数据,大数据量的数据处理上。
(2)结构不同
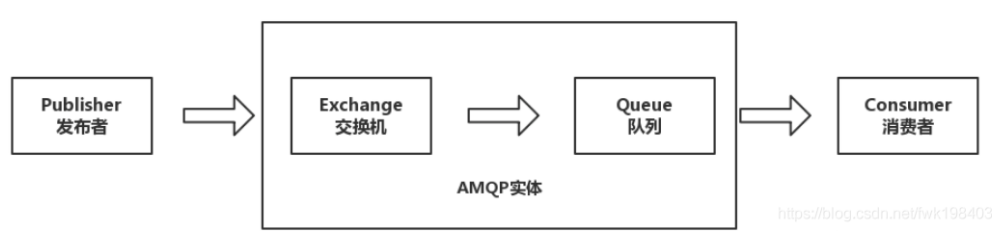
1、RabbitMQ采用AMQP(Advanced Message Queuing Protocol,高级消息队列协议)是一个进程间传递异步消息的网络协议。RabbitMQ的broker由Exchange,Binding,queue组成
2、kafka采用mq结构:broker 有part 分区的概念
(3)Brokerr与Consume交互方式不同
1、RabbitMQ 采用push的方式
2、kafka采用pull的方式
(4)集群负载均衡的区别
1、rabbitMQ的负载均衡需要单独的loadbalancer进行支持。
2、kafka采用zookeeper对集群中的broker、consumer进行管理
(5)使用场景不同
1、rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。
2、kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作

(6条消息) 详解java NIO之Channel(通道)_平凡的java梦的博客-CSDN博客_java 的channel

 浙公网安备 33010602011771号
浙公网安备 33010602011771号