scrapy使用十:图片的抓取和下载
1.目标:http://car.bitauto.com/qichepinpai
2.创建爬虫项目
$ sudo scrapy startproject car $ cd car $ sudo scrapy genspider carphoto car.bitauto.com/qichepinpai
3.items.py
import scrapy class CarItem(scrapy.Item): image_urls = scrapy.Field() # 图片网址 images = scrapy.Field() # 影像信息 alt = scrapy.Field()
image_urls ,images这2个字段是请求图片的默认字段,必须要有的,建议使用默认。
准确的说,使用本文 的图片下载方法,必须要使用默认字段 :在本文中,并没有写爬虫文件。
alt,自定义的字段
4.分析:
这里我们先使用火狐浏览器的Firefinder插件找找我们需要提取的图片,图片如下: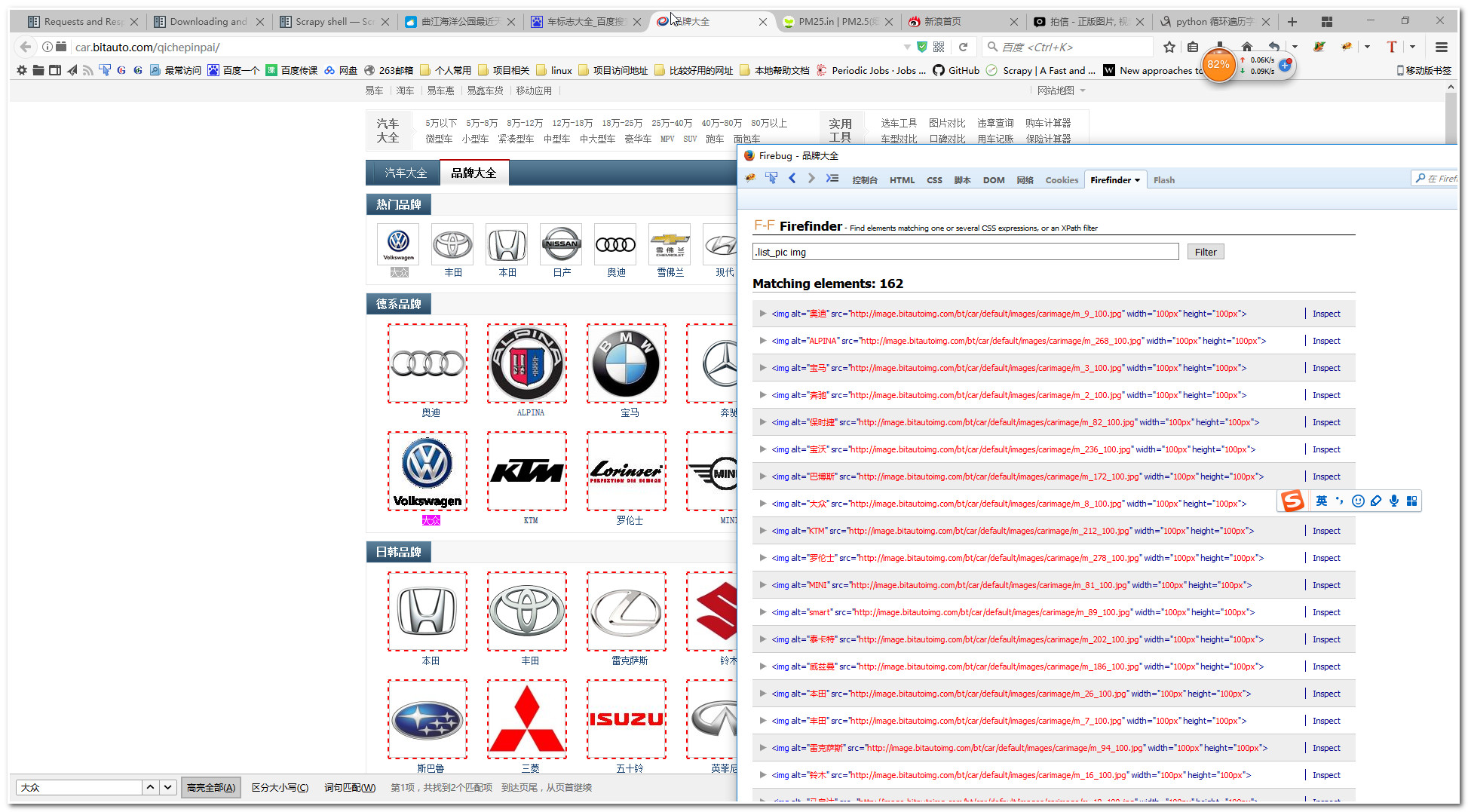
5.未写爬虫文件
6.pipelines.py文件
# -*- coding: utf-8 -*- class CarPipeline(object): def process_item(self, item, spider): return item from scrapy.contrib.pipeline.images import ImagesPipeline import os import scrapy # 使用scrapy的ImangesPipiline类,爬取图片 # 重写父类的以下两个方法,即可 class MyImangePipeline(ImagesPipeline): def file_path(self, request, response=None, info=None): alt_name = request.meta['alt'] return 'full/%s%s' % (alt_name, os.path.splitext(request.url)[-1]) def get_media_requests(self, item, info): yield scrapy.Request(item['image_urls'][0], meta={'alt': item['alt']})
代码简介:通常我们使用官方的那个imagepipeline导出的文件是SHA1 hash 你的url作为文件名,很难区别啊,这里使用到了request方法的meta参数,把我们的图片的alt属性传递过去,这样我们返回文件名的时候就可以使用这个alt的名字来区别了。(但是如果alt重复又替换了原来的图片的)
注意,firefinder这个插件依赖与firebug的,你可以在你的浏览器找类似firefinder的工具。
7.settings.py配件文件 :
ITEM_PIPELINES = { 'car.pipelines.MyImagePipeline': 300, } IMAGES_STORE = '/tmp/images/'
8.运行爬虫
$ scrapy crawl carphoto
posted on 2018-10-30 18:09 myworldworld 阅读(115) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号