scrapy使用二:一个简单的爬虫示例
爬虫项目过程:
- 创建一个scrapy项目
- 定义提取结构化数据item
- 编写 爬取网站的spider,并提出结构化数据item
- 编写 item piplines,来存储提取到的item,即结构化数据
一、创建一个简单的爬虫项目
1.创建scrapy项目:
在命令行下,
scrapy startproject mySpider
cd mySpider
2.目录结构,类似djano:
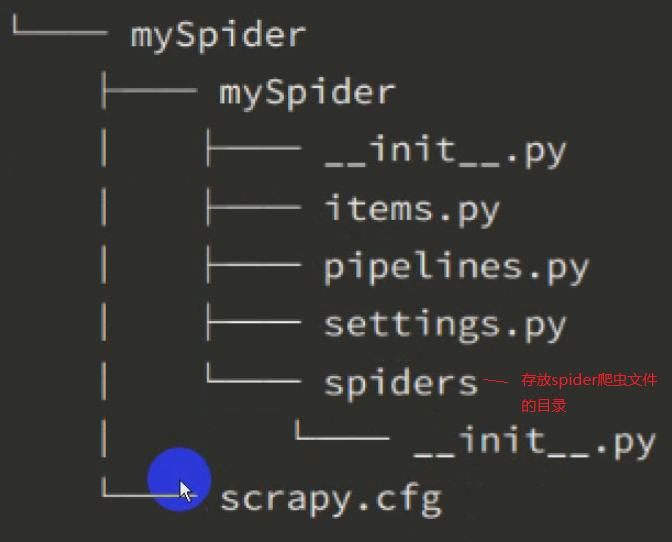
scrapy.cfg:项目的配置文件
myspider/:项目的python模块,将会从这里引用代码
mySpdier/items.py:项目的目标文件
mySpider/pipelines.py:项目的管道文件
mySpider/settings.py:项目的设置文件
mySpider/spiders/:存储爬虫代码的目录
2.创建爬虫文件:
cd mycast scrapy genspider 爬虫文件的名字 "爬虫的域,如htpp://www.baidu.com"
3.运行爬虫:
测试爬虫是否正常:
scrapy check 爬虫名称
运行爬虫:
scrapy crawl 爬虫名称
二、明确爬取目标
如,我们爬取http://www.itcast.cn/channel/teacher.shtml网站的所有讲师的姓名、职称和个人信息。
1.编辑mySpider目录下的items.py文件
2.item定义结构化数据字段,用来保存爬取到的数据,类似字典,但是 提供了一些额外的保护,以减少错误
3.通过创建一个继承自scrapy.Item的类,并且定义类型为scrapy.Field的类属性来定义一个item;类似于djanog中的model.py的ORM映射。
示例:MyspiderItem,和构造item模型model
class MyspiderItem(scrapy.Item): name = scrapy.Field() level = scrapy.Field() info = scrapy.Field()
三、制作爬虫
制作爬虫功能分两步:
1.爬数据:
cd mySpider:进入项目目录
创建xxx爬虫文件和xxxSpider.py爬虫类:
在当前目录下输入以下命令,将在mySpider/spider目录下创建一个名为itcast.py的爬虫,并指定爬取域的范围
scrapy genspider itcast "itcast.cn"

编写itcast.py文件,默认增加了下列代码。由以上命令生成的爬虫文件:
import scrapy class ItcastSpider(scrapy.Spider):
# 爬虫名称,启动爬虫时必需的参数 name = "itcast"
# 爬虫域范围,允许爬虫在这个域名下进行爬取,可选 allowed_domains = ["htpp://www.itcast.cn"]
# 爬虫列表:要爬取的url地址列表 start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
def parse(self, response): pass
当然, 以上爬虫文件,也可以自己创建,不由scrapy genspider生成。
要创建一个爬虫文件时,必须要有三个属性和一个方法,不论是由scrapy genspider生成的爬虫文件还是自定义生成的爬虫文件:
name:必选,爬虫的识别名称,必须是唯一的
allow_domains:可选,搜索的范围,即爬虫的约束区域;规定爬虫只爬取这个域名下的网页,不在此范围内的url会被忽略
start_urls:必选,爬取的url列表。当没有指定url时,爬虫从这里开始抓取数据,所以,第一次下载的数据将从这些urls开始。其它的子url将会从这些起始url中继承性生成。
parse(self, response):解析的方法,必选;每个初始url完成下载后将调用此方法,调用的时侯传入从每个url返回的response对象来作为唯一参数。主要作用如下:
- 负责解析返回的网页数据response.body,提取结构化数据(生成item)
- 生成需要下一页的url请求
修改start_urls的值为需要爬取的第一个url
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
修改parse()方法:
def parse(self, response): with open('teacher.html', 'w') as f: f.write(response.text)
2.取数据
观察页面源码,使用response.xpath提取数据。编写itcast.py的parse方法
筛选数据:这步是最重要的,需要在页面源码中观察
姓名 , //div[@class='li_txt']/h3
职称 , //div[@class='li_txt']/h4
个人介绍, //div[@class='li_txt']/p
import scrapy from mySpider.items import ItcastItem class ItcastSpider(scrapy.Spider): name = "itcast" allowed_domains = ["itcast.cn"] start_urls = ['http://www.itcast.cn/channel/teacher.shtml'] def parse(self, response): # 存放老师信息的列表 items = [] for each in response.xpath("//div[@class='li_txt']"): # item = ItcastItem()
item = {} #extract()方法,返回的都是unicode字符串 name = each.xpath("h3/text()").extract() title = each.xpath("h4/text()").extract() info = each.xpath("p/text()").extract() # xpath返回的是一个元素的列表 item['name'] = name[0] item['title'] = title[0] item['info'] = info[0] items.append(item) # 返回数据引擎,引擎判断判断不是item类型,将不会调用pipeline return items
注意:以上parse()方法,返回的items是列表,不是item类型,因此引擎不会调用pipeline管道。
当不使用管道时,scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件
# json格式,默认为unicode编码 scrapy crawl itcast -o teachers.json # json lines格式,默认为unicode编码 scrapy crawl itcast -o teachers.jsonl # csv文件,逗号隔开,可用excel打开 scrapy crawl itcast -o teachers.csv # xml格式 scrapy crawl itcast -o teachers.xml
查看爬虫名称列表:
scrapy list
执行爬虫:
scrapy craw itcast
注意:scrapy craw 后面是爬虫的名字
一个scrapy项目,可以包括多个爬虫。各个爬虫在执行时,按name属性区分。
如果运行后,打印日志出现[scrapy] INFO: Spider closed (finished),表示执行完成。
# 注意,python2默认的编码环境是ascii,当取回的数据不是ascii时,可能 会造成乱码
# 我们可以指定保存内容的编码格式,一般情况下,在代码最上方添加
import sys
reload(sys)
sys.setdefaultencodeing("utf-8")
python3编码默认是unicode,无需处理。
四、scrape.Spider源码:
import logging class Spider(object_ref): """所有爬虫的基类,用户定义的爬虫必须继承自之个类""" # name是spider最重要的属性,而且是必须的,唯一的;一般使用要爬取的网站名称来命令,可加可不加后缀 # name属性,定义了scrapy如何定位并初始化spider name = None custom_settings = None # 初始化,提取爬虫名字和start_urls def __init__(self, name=None, **kwargs): if name is not None: self.name = name elif not getattr(self, 'name', None): raise ValueError("%s must have a name" % type(self).__name__) # python对象或类型,通过内置成员__dict__来存储成员信息 self.__dict__.update(kwargs) # 要爬取的url地址列表。当没有指定的url时,spider将从该列表中开始进行爬取。 # 因此,第一个被获取到的页面的url将是该列表中第一个url if not hasattr(self, 'start_urls'): self.start_urls = [] # 该方法将读取start_urls内地址,并为每个地址生成一个Request对象 # 交给scrapy下载并返回Response;该方法仅调用一次 def start_requests(self): for url in self.start_urls: yield self.make_requests_from_url(url) # 实际生成Request对象;Request对象默认的回调函数为parse(),提交方式为get def make_requests_from_url(self, url): # dont_filter为True,不做去重处理; # 每个请求,会生成一个特征码,存储在内存; # 如果有相同的请求时,特征码将相同,就会根据此参数来判断是否要重复发送请求 return Request(url, dont_filter=True) # 默认的Request对象回调函数,处理返回的response # 生成item或Request对象。用户必须实现这个类。 def parse(self, response): raise NotImplementedError @property def logger(self): logger = logging.getLogger(self.name) return logging.LoggerAdapter(logger, {'spider': self}) def log(self, message, level=logging.DEBUG, **kw): self.logger.log(level, message, **kw)
...............
四、编写管道文件
用来处理item字段,写入数据库或文件中。
mySpider/pipelines.py
import json # 此类必须实现process_item(self, item, spider)方法 class ItcastPipeline(object): def __init__(self): self.f = open("itcast_pipeline.json", "w") def process_item(self, item, spider): # 处理每个item,来自ItcastSpider.parse()返回的 yield item # ensure_ascii为False,将处理中文 content = json.dumps(dict(item), ensure_ascii=False) self.f.write(content.encode("utf-8")) # 这里必须返回item,告诉引擎,我已经处理完了这个item return item def close_spider(self, spider): self.f.close()
同时必须在mySpider/settings.py中,启用ITEM_PIPELINES ,将以上管道类,加入其中
mySpider目录.pipelines文件.ItcastPipeline类:权限比重
ITEM_PIPELINES = {
'mySpider.pipelines.ItcastPipeline': 300,
}
要调用管道文件,还必须mySpider/itcast.py文件中的Itcastspider类的parse()方法返回的数据是item的类型
def parse(self, response): # 存放老师信息的列表 for each in response.xpath("//div[@class='li_txt']"): # 创建item字段对象,用来存储信息 item = ItcastItem() #xpath是对象;extract()方法,将xpath对象的data内容,转换为unicode字符串列表 name = each.xpath(".h3/text()").extract() title = each.xpath(".h4/text()").extract() info = each.xpath(".p/text()").extract() # xpath返回的是一个元素的列表 item['name'] = name[0] item['title'] = title[0] item['info'] = info[0] # items.append(item) #yield返回给引擎;如果yield的数据是item类型,则会引擎会将之返回给管道;因为yield,还会回来继承取for循环的数据 yield item
当item在spider中被收集之后,它将会被传递到item pipeline,这些item pipeline组件按定义的顺序处理item。
每个item pipeline都是实现了简单方法的python类,比如决定此item是丢弃还是存储。
以下是item pipeline的一些典型应用:
- 验证爬取的数据(检查item包含某些字段,比如说name字段)
- 查重(并丢弃)
- 将爬取结果保存到文件或者数据库中
import something class somethingPipelin(object): def __init__(self): """ 可选,做参数初始化等 """ def process_item(self, item, spider): """ 这个方法必须实现,每个item pipeline组件都需要调用该方法 这个方法必须返回一个item对象,被丢弃的item将不会被之后的pipeline组件所处理 :param item: Item对象,被爬取的item :param spider: Spider对象,爬取该item的spider :return: item,不返回的item将被丢弃 """ def open_spider(self, spider): """ 可选方法,当spider被开启时,这个方法被调用 :param spider: Spider对象,爬取该item的spider :return: """ def close_spider(self, spider): """ 可选方法,当spider被关闭时,这个方法被调用 :param spider: Spider对象,爬取该item的spider :return: """
五、scrapy shell,用于测试
用于检查一个网站的响应,返回response
在项目根目录下执行以下命令:
scrapy shell 网站
response.body,包体
response.headers,包头
response.selector,获取response初始化类的Selector对象,此时可用response.selector.xpath()或response.selector.css()来对response进行查询
新版的scrapy,直接 response.xpath()或者response.css()
六、Selectors选择器:
scrapy selectors内置了xpath和css selector表达式机制
Selector有四个基本的方法,最常用的还是xpath:
- xpath():传入xpath表达式,返回该表达式所对应的所有节点的selector list列表,语法同XPATH。需要extract()序列化。
- extract():序列化该节点为unicode字符串并返回list
- css():传入css表达式,返回该表达式所对应的所有节点的selector列表,语法同BS4。需要extract()序列化。
- re():根据传入的正则表达 式对数据进行提取,返回unicode字符串列表。不需要extract()转换
-
extract_first(""):title = response.xpath('//div[@class="entry-header"]/h1/text()').extract_first("")
七、xpath
XPath表达式的例子及对应的含义
/html/head/title:选择<html>文件中<head>标签内的<title>元素 /html/head/title/text():选择上面的<title>元素的文字 //td:选择所有的<td>元素 //div[@class='mine']:选择所有具有class='mine'属性的div元素
//定位根节点
/往下层查找
/text():提取文本内容
/@xxx:提取属性内容
xpath的特殊用法:
1.用相同的字符开头:starts-with(@属性名称,属性字符相同部分)
html = """ <body> <div id="test1">需要的内容1</div> < div id = "test2" > 需要的内容2 < / div > < div id = "test3" > 需要的内容3 < / div > </body>"""
selector = etree.HTML(html) content = selector.xpath('//div[starts-with(@id, "test")]/text()') print (content) # ['需要的内容1', '需要的内容2', '需要的内容3', ]
2.标签套标签:string(.)
html = """ <body> <div id="test">中国</div> <span id="ap" > 广东省 < ul> 深圳市 <li>福田区</li> </ul> </span> 华强北 </div> </body>"""
selector = etree.HTML(html) data = select.xpath('//div[@id="test"]')[0] info = data.xpath('string(.)') info = info.strip().replace(' ', '') print (info) # 中国广东省深圳市福田区华强北
3.xpath示例:
body # 选取所有body元素的所有子节点 /html # 选取根元素 body/a # 选取所有属于body的子元素的a元素 //div # 选取所有dic子元素(任意地方) body//div # 选取所有属于body元素的后代的div元素(body下任意位置) //@class # 选取所有名为class的属性 /body/div[1] # 选取属于body子元素的第一个div元素 /body/div[last()] # 选取属于body子元素的最后一个div元素 //div[@lang] # 选取所有拥有lang属性的div元素 //div[@lang='eng'] # 选取所有lang属性为eng的div元素 /div/* # 获取属于div元素的所有子节点 //* # 选取所有元素 //div[@*] # 获取所有带属性的div元素 /div/a|//div/p # 获取所有div的子元素a和p //span|ul # 选取文档中的span和ul元素 body/div/p|//span # 选取所有body下的div下的p元素和所有span元素 //span[contains(@class, 'vote-post-up')] # 寻找所有属性为class的值中包含vote-post-up的span标签
八、多进程爬取
map函数,一手包办了序列操作、参数传递、结果保存等一系统操作
from multiprocessing.dummy import Pool
pool = Pool(4)
results = pool.map(爬取函数,网址列表)
posted on 2018-10-04 16:55 myworldworld 阅读(430) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号