ELK二:ES的数据组织
elasticsearch与关系型数据的对比:
| Relational DB | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types |
| 行(rows) | documents |
| 字段(columns) | 字段fields |
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)。
注意:在ES6之前的版本,一个索引可以有多个类型;但ES6之后,一个索引只能有一个类型。
逻辑设计:文档、类型、索引
一个索引类型中,包含多个文档,比如说文档1,文档2。
当我们索引一篇文档时,可以通过这样的顺序找到它:索引▷类型▷文档ID,通过这个组合我们就能索引到某个具体的文档。
文档:
elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要属性:
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含
key:value - 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
- 文档是无模式的,也就是说,字段对应值的类型可以是不限类型的。
类型:
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。
类型中对于字段的定义称为映射,比如name映射为字符串类型。
文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。
但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段与数据类型的映射,然后再使用。
索引:
索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。
物理设计:节点和分片:
一个集群包含至少一个节点,而一个节点就是一个elasticsearch进程。
节点内可以有多个索引。
一个索引,会有多个主分片,和多个副本;分别存储在不同的节点上。
示例:
默认的,如果你创建一个索引,那么这个索引将会有5个分片(primary shard,又称主分片)构成,而每个分片又有一个副本(replica shard,又称复制分片),这样,就有了10个分片。
那么这个索引是如何存储在集群中的呢?示例:
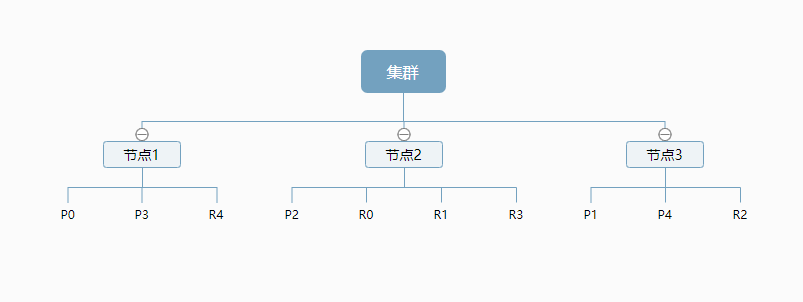
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。
实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。
倒排索引:
es将索引被分为多个分片,每份分片是一个Lucene的索引。所以一个elasticsearch索引是由多个Lucene索引组成的。
lasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
例如,假设我们有两个文档,每个文档的 content 域包含如下内容:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
为了创建倒排索引,我们首先将每个文档的 content 域拆分成单独的 词(我们称它为 词条 或 tokens ),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。结果如下所示:
Term Doc_1 Doc_2 ------------------------- Quick | | X The | X | brown | X | X dog | X | dogs | | X fox | X | foxes | | X in | | X jumped | X | lazy | X | X leap | | X over | X | X quick | X | summer | | X the | X | ------------------------
现在,如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:
Term Doc_1 Doc_2 ------------------------- brown | X | X quick | X | ------------------------ Total | 2 | 1
两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 ,那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
但是,我们目前的倒排索引有一些问题:
Quick和quick以独立的词条出现,然而用户可能认为它们是相同的词。fox和foxes非常相似, 就像dog和dogs;他们有相同的词根。jumped和leap, 尽管没有相同的词根,但他们的意思很相近。他们是同义词。
使用前面的索引搜索 +Quick +fox 不会得到任何匹配文档。(记住,+ 前缀表明这个词必须存在。)只有同时出现 Quick 和 fox 的文档才满足这个查询条件,但是第一个文档包含 quick fox,第二个文档包含 Quick foxes 。
我们的用户可以合理的期望两个文档与查询匹配。我们可以做的更好。需要词条规范为标准模式
倒排索引原理和实现:
关于倒排索引
搜索引擎通常检索的场景是:给定几个关键词,找出包含关键词的文档。
怎么快速找到包含某个关键词的文档就成为搜索的关键。这里我们借助单词——文档矩阵模型,
通过这个模型我们可以很方便知道某篇文档包含哪些关键词,某个关键词被哪些文档所包含。
单词-文档矩阵的具体数据结构可以是倒排索引、签名文件、后缀树等。
倒排索引源于实际应用中需要根据属性的值来查找记录,lucene是基于倒排索引实现的。
这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。
由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
倒排索引一般表示为一个关键词,然后是它的频度(出现的次数),位置(出现在哪一篇文章或网页中,及有关的日期,作者等信息),它相当于为互联网上几千亿页网页做了一个索引,好比一本书的目录、标签一般。读者想看哪一个主题相关的章节,直接根据目录即可找到相关的页面。不必再从书的第一页到最后一页,一页一页的查找。
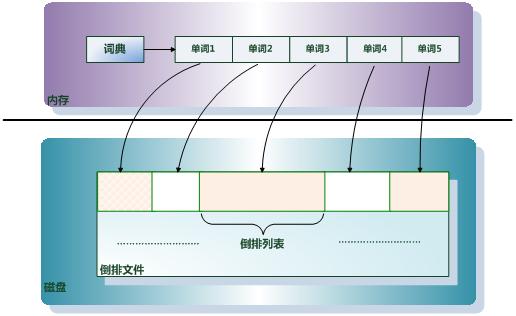
倒排索引由两个部分组成:单词词典和倒排文件。
倒排文件:
所有单词的倒排列表顺序的存储在磁盘的某个文件里,这个文件即被称为倒排文件,倒排文件是存储倒排索引的物理文件。
单词词典:
单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
单词词典是倒排索引中非常重要的组成部分,它是用来维护文档集合中所有单词的相关信息,同时用来记载某个单词对应的倒排列表在倒排文件中的位置信息。在支持搜索时,根据用户的查询词,去单词词典里查询,就能够获得相应的倒排列表。
对于一个规模很大的文档集合来说,可能包含了几十万甚至上百万的不同单词,
快速定位某个单词直接决定搜索的响应速度,所以我们需要很高效的数据结构对单词词典进行构建和查找。
常用的数据结构包含哈希加链表和树形词典结构。
Lucene倒排索引原理:
Lucerne使用的是倒排文件索引结构。该结构及相应的生成算法如下:
设有两篇文章1和2:
文章1的内容为:Tom lives in Guangzhou,I live in Guangzhou too.
文章2的内容为:He once lived in Shanghai.
<1>取得关键词
由于lucene是基于关键词索引和查询的,首先我们要取得这两篇文章的关键词,通常我们需要如下处理措施:
a.我们现在有的是文章内容,即一个字符串,我们先要找出字符串中的所有单词,即分词。英文单词由于用空格分隔,比较好处理。中文单词间是连在一起的需要特殊的分词处理。
b.文章中的”in”, “once” “too”等词没有什么实际意义,中文中的“的”“是”等字通常也无具体含义,这些不代表概念的词可以过滤掉
c.用户通常希望查“He”时能把含“he”,“HE”的文章也找出来,所以所有单词需要统一大小写。
d.用户通常希望查“live”时能把含“lives”,“lived”的文章也找出来,所以需要把“lives”,“lived”还原成“live”
e.文章中的标点符号通常不表示某种概念,也可以过滤掉
在lucene中以上措施由Analyzer类完成。 经过上面处理后,
文章1的所有关键词为:[tom] [live] [guangzhou] [i] [live] [guangzhou]
文章2的所有关键词为:[he] [live] [shanghai]
<2>建立倒排索引
有了关键词后,我们就可以建立倒排索引了。上面的对应关系是:“文章号”对“文章中所有关键词”。倒排索引把这个关系倒过来,变成: “关键词”对“拥有该关键词的所有文章号”。
文章1,2经过倒排后变成
关键词 文章号
guangzhou 1
he 2
i 1
live 1,2
shanghai 2
tom 1 通常仅知道关键词在哪些文章中出现还不够,我们还需要知道关键词在文章中出现次数和出现的位置,通常有两种位置:
a.字符位置,即记录该词是文章中第几个字符(优点是关键词亮显时定位快);
b.关键词位置,即记录该词是文章中第几个关键词(优点是节约索引空间、词组(phase)查询快),lucene中记录的就是这种位置。
加上“出现频率”和“出现位置”信息后,我们的索引结构变为:
关键词 文章号[出现频率] 出现位置
guangzhou 1[2] 3,6
he 2[1] 1
i 1[1] 4
live 1[2] 2,5,
2[1] 2
shanghai 2[1] 3
tom 1[1] 1 以live 这行为例我们说明一下该结构:live在文章1中出现了2次,文章2中出现了一次,它的出现位置为“2,5,2”这表示什么呢?我们需要结合文章号和出现频率来分析,文章1中出现了2次,那么“2,5”就表示live在文章1中出现的两个位置,文章2中出现了一次,剩下的“2”就表示live是文章2中第 2个关键字。
以上就是lucene索引结构中最核心的部分。我们注意到关键字是按字符顺序排列的(lucene没有使用B树结构),因此lucene可以用二分搜索算法快速定位关键词。
<3>实现
实现时,lucene将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件 (positions)保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
Lucene中使用了field的概念,用于表达信息所在位置(如标题中,文章中,url中),在建索引中,该field信息也记录在词典文件中,每个关键词都有一个field信息(因为每个关键字一定属于一个或多个field)。
<4>压缩算法
为了减小索引文件的大小,Lucene对索引还使用了压缩技术。
首先,对词典文件中的关键词进行了压缩,关键词压缩为<前缀长度,后缀>,例如:当前词为“阿拉伯语”,上一个词为“阿拉伯”,那么“阿拉伯语”压缩为<3,语>。
其次大量用到的是对数字的压缩,数字只保存与上一个值的差值(这样可以减小数字的长度,进而减少保存该数字需要的字节数)。例如当前文章号是16389(不压缩要用3个字节保存),上一文章号是16382,压缩后保存7(只用一个字节)。
<5>应用原因
下面我们可以通过对该索引的查询来解释一下为什么要建立索引。
假设要查询单词 “live”,lucene先对词典二元查找、找到该词,通过指向频率文件的指针读出所有文章号,然后返回结果。词典通常非常小,因而,整个过程的时间是毫秒级的。
而用普通的顺序匹配算法,不建索引,而是对所有文章的内容进行字符串匹配,这个过程将会相当缓慢,当文章数目很大时,时间往往是无法忍受的。
posted on 2018-03-30 11:05 myworldworld 阅读(325) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号