
YOLOv4: Optimal Speed and Accuracy of Object Detection
Abstract
目前有很多方法来提升CNN的精度。有些方法或者特征只适用于特定的模型或者特定的问题或者小规模的数据集;但是有些方法比如 batch-normalization和residual-connections适用于大多数模型、任务和数据集。我们假定这些通用的特征或者方法包括 Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP), Cross mini-Batch Normalization (CmBN), Self-adversarial-training (SAT)
和 Mish激活函数。我们使用了 WRC, CSP, CmBN, SAT, Mish activation, Mosaic data augmentation, CmBN, DropBlock regularization, and CIoU loss,最终在COCO数据集上达到state-of-art的结果,AP达到43.5%,在Tesla V100上的速度达到65FPS。源代码: https://github.com/AlexeyAB/darknet
1. Introduction
本文的主要目标是在生产系统中设计一个快速运行的目标检测器,并优化并行计算,而不是设计一个拥有低计算量理论指标(BFLOP)的模型。我们希望设计的检测器可以很容易的被训练和使用,即任何人都可以使用一个常见的GPU来训练和测试一个可以达到实时、高精度的目标检测器。YOLOV4的结果如下图:
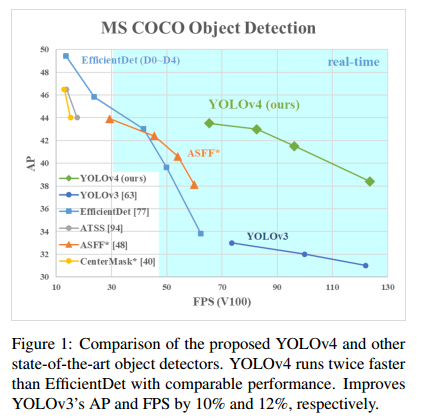
本文的贡献总结如下:
-
我们设计了一个高效的目标检测模型。任何人都可以使用1080Ti或者2080Ti训练一个超级快速和精确的目标检测器。
-
我们在训练目标检测器时,验证了 Bag-ofFreebies 和 Bag-of-Specials方法对模型的影响
-
我们修改了一些方法,如CBN,PAN,SAM等,这使得可以更容易在单GPU上训练模型。
2. Related work
2.1. Object detection models
一个检测器通常包含两个部分,backbone部分(一般在ImageNet上预训练)和head部分(用于预测类别和物体框)。一般在GPU上运行的检测器的backbone可以采用VGG,ResNet,ResNeXt或者DenseNet。在CPU上运行的检测器的backbone可以采用SqueezeNet,MobileNet或者Shufflenet。对于head部分,通常可以分为两类,一阶段检测器( one-stage object detector)和二阶段检测器( two-stage object detector)。比较有代表性的二阶段检测器有RCNN系列(包括RCN,fast RCNN,faster RCNN,RFCN和Libra RCNN);RepPoints是一个二阶段anchor-free的目标检测器。对于一阶段的目标检测器,比较有代表性的有YOLO、SSD和RetinaNet。一阶段anchor free的检测器有CenterNet,CornerNet和FCOS等。另外,目标检测器也会在backbone和head中间插入一些层,称为neck,主要作用是收集不同阶段(stage)的feature map。一般,neck包括若干的 bottom-up paths和 bottom-up paths;比较有代表性的方法有 Feature Pyramid Network (FPN) , Path Aggregation Network (PAN) , BiFPN, and NAS-FPN。另外,一些研究人员也会直接设计一个新的backbone(如DetNet和DetNAS)或者新的模型(SpineNet,HitDetector)。
总结来说,一个普通的目标检测模型由以下几个部分组成:
-
Input: Image, Patches, Image Pyramid
-
Backbones: VGG16, ResNet-50, SpineNet,EfficientNet-B0/B7 , CSPResNeXt50, CSPDarknet53
-
Neck:
-
Additional blocks: SPP, ASPP, RFB, SAM
-
Path-aggregation blocks: FPN, PAN,NAS-FPN, Fully-connected FPN, BiFPN, ASFF, SFAM
-
Heads:
-
Dense Prediction (one-stage):
-
RPN, SSD, YOLO, RetinaNet (anchor based)
-
CornerNet, CenterNet, MatrixNet, FCOS (anchor free)
-
Sparse Prediction (two-stage):
-
Faster R-CNN , R-FCN , Mask RCNN (anchor based)
-
RepPoints (anchor free)
2.2. Bag of freebies
我们将那些仅仅改变训练策略或者增加训练成本的方法称为“bag of freebies”
We call these methods that only change the training strategy or only increase the training cost as “bag of freebies.”
-
数据增强(data augmentation)(增加输入图像的多样性,使得对不同环境下的输入图像有更高的鲁棒性)
-
photometric distortions
-
亮度(brightness)、对比度(contrast)、色调(hue)、饱和度(saturation)、图像噪声(noise of an image)
-
geometric distortions
-
随机放大缩小、裁剪、翻转和旋转等( random scaling, cropping, flipping, and rotating)
-
模拟目标遮挡的情况
-
随机擦除(random erase)和CutOut:随机选择一个长方形区域,然后将该区域填充为随机值或者0
-
hide-and-seek和grid mask:在图像中随机或均匀的选择多个长方形区域,然后将这些区域填充为0
-
也可以将上述想法应用在feature map,如DropOut、DropConnect和DropBlock
-
使用多幅图像
-
MixUp:利用不同的系数叠加两幅图像和对应的label
-
CutMix
-
style transfer GAN: reduce the texture bias learned by CNN
-
解决 semantic distribution( there is a problem of data imbalance between different classes)
-
hard negative example mining
-
online hard example mining(只能用于two-stage的检测器)
-
Focal Loss:解决类间数据不平衡
-
label smoothing
-
knowledge distillation
-
Bounding Box(BBox) regression
-
Mean Square Error(MSE) (缺点:与bbox的尺度相关,随着尺度的变大,loss会变大)
-
预测中心点坐标和bbox的宽高,或者bbox的左上角点和右下角点
-
对于anchor-based的方法,一般是预测偏移offset
-
IoU loss ( scale invariant representation)
-
GIoU loss
-
DIoU: it additionally considers the distance of the center of an object
-
CIoU: simultaneously considers the overlapping area, the distance between center points, and the aspect ratio. CIoU can achieve better convergence speed and accuracy on the BBox regression problem.
2.3. Bag of specials
For those plugin modules and post-processing methods that only increase the inference cost by a small amount but can significantly improve the accuracy of object detection, we call them “bag of specials”.
主要作用是增强模型某一方面的属性,如增大感受野( receptive field),引入attention机制,增强特征整合容量( feature integration capability)
-
增加感受野的模块
-
SPP ( Spatial pyramid pooling in deep convolutional networks for visual recognition)
-
ASPP ( DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs)
-
RFB ( Receptive field block net for accurate and fast object detection)
-
Attention模块。在目标检测中的主要用于: divided into channel-wise attention and pointwise attention
-
Squeeze-and-Excitation (SE) ( Squeeze-and-excitation networks)
-
Spatial Attention Module (SAM) ( CBAM: Convolutional block attention module)
-
feature integration
-
integrate lowlevel physical feature to high-level semantic feature
-
skip connection( Fully convolutional networks for semantic segmentation)
-
hyper-column( Hypercolumns for object segmentation and fine-grained localization)
-
multi-scale prediction(FPN), integrate different feature pyramid
-
SFAM( M2det: A single-shot object detector based on multi-level feature pyramid network.): use SE module to execute channelwise level re-weighting on multi-scale concatenated feature maps
-
ASFF( Learning spatial fusion for single-shot object detection): uses softmax as point-wise level reweighting and then adds feature maps of different scales
-
BiFPN( EfficientDet: Scalable and efficient object detection): the multi-input weighted residual connections is proposed to execute scale-wise level re-weighting, and then add feature maps of different scales
-
good activation function: A good activation function can make the gradient more efficiently propagated, and at the same time it will not cause too much extra computational cost.
-
ReLU: solve the gradient vanish problem which is frequently encountered in traditional tanh and sigmoid activation function.
-
LReLU、PReLU: solve the problem that the gradient of ReLU is zero when the output is less than zero.
-
ReLU6、 hard-Swish: specially designed for quantization networks.
-
Scaled Exponential Linear Unit (SELU): self-normalizing a neural network
-
Swish、Mish: continuously differentiable activation function
-
post-processing method、
-
soft NMS
-
DIoU NMS( Distance-IoU Loss: Faster and better learning for bounding box regression.)
3. Methodology
基本的目标是提高生产系统中神经网络的运行速度和并行计算的优化,而不是一个低计算量的理论指标(BFLOP)。
-
对于GPU来说,我们在卷积层中使用少量的组(group)(1-8): CSPResNeXt50 / CSPDarknet53
-
对于VPU来说,我们使用grouped-convolution,但是我们避免使用 Squeeze-and-excitement (SE) blocks,尤其包括如下模型: EfficientNet-lite / MixNet [76] / GhostNet [21] / MobileNetV3
3.1. Selection of architecture
我们的目标是在输入网络分辨率( input network resolution),卷积层数量( the convolutional layer number),参数量(the
parameter number (filter size^2 * filters * channel / groups)),输出层的卷积核数量( the number of layer outputs (filters))中找到一个最优的平衡。举个例子,我们大量的研究证明,在ILSVRC2012(ImageNet)物体分类数据集上, CSPResNext50要好于 CSPDarknet53。但是,相反,在MS COCO目标检测数据集上, CSPDarknet53要好于 CSPResNext50。
接下来的目标是选择额外的blocks来增加感受野以及来自不同backbone levels(用于不同检测器levels)的最佳参数聚合方法,如FPN,PAN,ASFF,BiFPN。( The next objective is to select additional blocks for increasing the receptive field and the best method of parameter aggregation from different backbone levels for different detector levels: e.g. FPN, PAN, ASFF, BiFPN.)
一个在分类上最优的模型并不总是在检测上也是最优的。相比于分类器,检测器需要如下的要求:
-
网络的输入尺寸或者分辨率需要更大( Higher input network size (resolution)):用于检测小尺寸目标
-
更多层( More layers):需要得到一个更高的感受野来覆盖增大的输入网络
-
更多参数( More parameters):为了使用模型在一幅图像中检测多个不同大小物体的能力更大。
假设说,我们假设一个拥有更大感受野(含有大量的3x3卷积)和更大参数量的模型应该被选择作为backbone。表格1展示了 of CSPResNeXt50, CSPDarknet53, 和 EfficientNet B3相关信息。

CSPResNext50网络包含16个3x3卷积层,425x425的感受野和20.6M的参数量; CSPDarknet53包含29层3x3的卷积层,725x725的感受野和27.6M的参数。上述理论依据,加上我们大量的实验,显示 CSPDarknet53网络结构是两个结构中的用于检测器的最优模型。
不同大小感受野的影响总结如下:
-
达到目标物体的大小:可以看到整个物体( Up to the object size - allows viewing the entire object)
-
达到网络的大小:可以看到物体周围的内容( Up to network size - allows viewing the context around the object)
-
超出网络的大小:增加图像点和最终激活之间的连接数量( Exceeding the network size - increases the number of connections between the image point and the final activation)
我们在 CSPDarknet53上增加了SPP block,因为它显著增加了感受野,分离出最重要的上下文特征,并且几乎没有降低网络的运行速度。我们使用PANet作为不同主干网络层的参数聚合方法,用于不同的检测器层,而不是YOLOV3中的FPN层。
最后,我们选择 CSPDarknet53作为backbone,SPP additional module, PANet path-aggregation neck和 YOLOv3 (anchor based) head等结构,称为YOIOv4。
我们不使用 Cross-GPU Batch Normalization (CGBN or SyncBN)或者昂贵的专业设备。这可以使得任何人在一个常见的GPU如GTX 1080Ti或者RTX 2080Ti上复现我们最优的结果。
3.2. Selection of BoF and BoS
为了提高目标检测的训练,CNN通常使用如下的方法:
-
Activations: ReLU, leaky-ReLU, parametric-ReLU,ReLU6, SELU, Swish, or Mish
-
Bounding box regression loss: MSE, IoU, GIoU, CIoU, DIoU
-
Data augmentation: CutOut, MixUp, CutMix
-
Regularization method: DropOut, DropPath [36], Spatial DropOut [79], or DropBlock
-
Normalization of the network activations by their mean and variance: Batch Normalization (BN) [32], Cross-GPU Batch Normalization (CGBN or SyncBN) [93], Filter Response Normalization (FRN) [70], or Cross-Iteration Batch Normalization (CBN) [89]
-
Skip-connections: Residual connections, Weighted residual connections, Multi-input weighted residual connections, or Cross stage partial connections (CSP)
对于训练激活函数,由于PReLU和SELU更难训练,ReLU6是针对量化网络训练的,因此将从候选列表中移除上述激活函数。对于正则化,提出DropBlock的人比较了其他正则化方法,得出该方法更好一些;因此我们使用DropBlock作为我们的正则化方法。另外,由于我们的训练技巧专注于只在一个GPU上,因此我们不考虑使用syncBN。
3.3. Additional improvements
为了使设计的检测器更适合在单GPU上训练,我们进行了如下的额外设计和改进。
-
我们引入了一个新的数据增强方法 Mosaic和 Self-Adversarial Training (SAT)
-
我们使用遗传算法选择最优的超参数
-
我们修改了目前存在的算法使得更适合于高效的训练和检测:修改了SAM,PAN和 Cross mini-Batch Normalization (CmBN)
Mosaic数据增强方法混合了4张不同的训练图像,因此混合了4个不同的内容。而CutMix只混合了两张输入图像。这允许检测物体正常上下文之外的对象。另外,在同一层, batch normalization可以在4个不同的图像上计算激活统计数据。
自对抗训练( Self-Adversarial Training (SAT))也是一种数据增强方法。该方法有2个阶段,第1阶段是神经网络改变原始图像而不是网络的权值;通过这种方式,神经网络对自己进行了对抗性的攻击,改变原始图像来制造图像上没有需要的对象的假象。在第2阶段,神经网络使用正常的方法在这个修改后的图像上训练来检测物体。
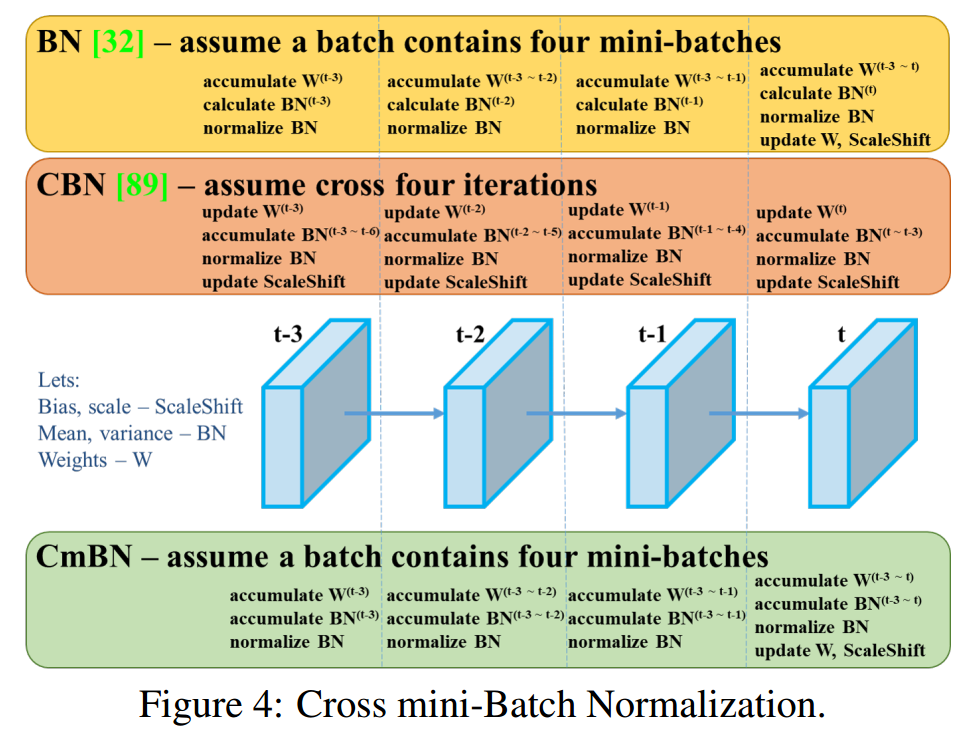
CmBN( Cross mini-Batch Normalization)是CBN的一个修改后的版本,如Figure 4所示。 This collects statistics only between mini-batches within a single batch.
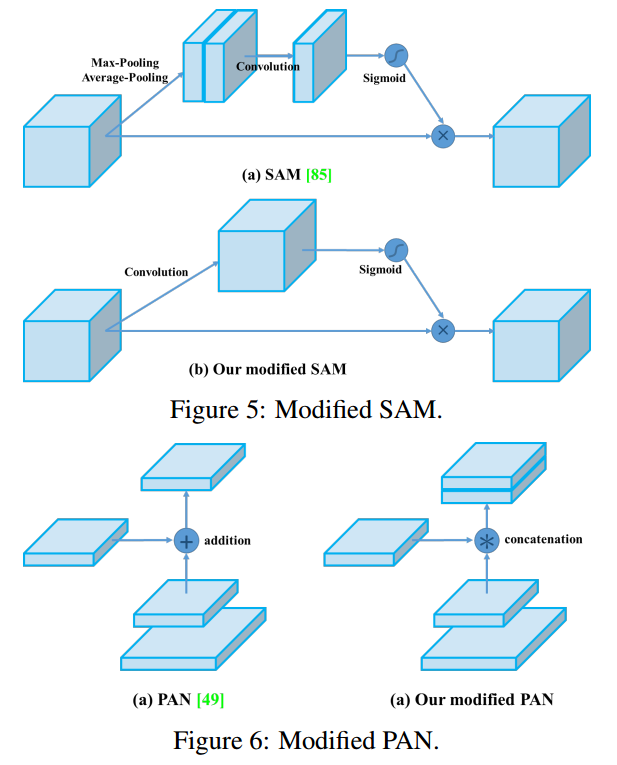
我们也修改了SAM,将 spatial-wise attention修改成 point-wise attention,将PAN的shortcut连接修改成 concatenation。如Figure 5和Figure 6所示。
3.4. YOLOv4
下面介绍YOLOV4的细节。
YOLOV4包含:
-
Backbone: CSPDarknet53
-
Neck: SPP [25], PAN [49]
-
Head: YOLOv3 [63]
YOLOV4使用:
-
Bag of Freebies (BoF) for backbone: CutMix and Mosaic data augmentation, DropBlock regularization, Class label smoothing
-
Bag of Specials (BoS) for backbone: Mish activation, Cross-stage partial connections (CSP), Multiinput weighted residual connections (MiWRC)
-
Bag of Freebies (BoF) for detector: CIoU-loss, CmBN, DropBlock regularization, Mosaic data augmentation, Self-Adversarial Training, Eliminate grid sensitivity, Using multiple anchors for a single ground truth, Cosine annealing scheduler [52], Optimal hyperparameters, Random training shapes
-
Bag of Specials (BoS) for detector: Mish activation, SPP-block, SAM-block, PAN path-aggregation block, DIoU-NMS
4. Experiments
4.2. Influence of different features on Classifier training
下面介绍不同的特征在分类器上训练的影响。具体结果如Table2和Table3所示。从下表中可以看出,对分类器的精度有提升的方法有:CutMix和Mosaic数据增强方法,Class label smoothing和Mish激活函数。


4.3. Influence of different features on Detector training
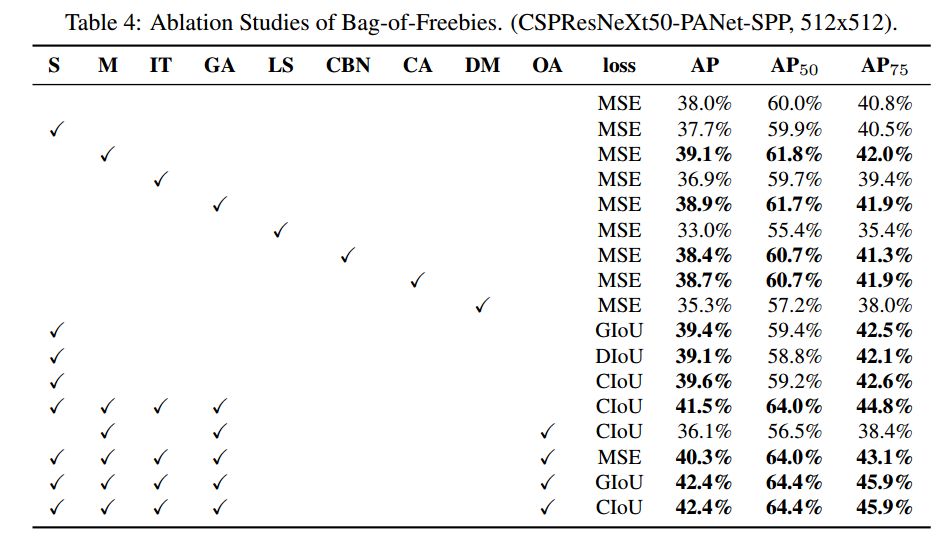
下面介绍不同的 Bag-of-Freebies对训练检测器精度的影响。在不影响速度FPS的情况来,我们研究了不同的特征来提高检测器的准确率。分别如下:
-
S: Eliminate grid sensitivity the equation bx = σ(tx)+cx; by = σ(ty)+ cy, where cx and cy are always whole numbers, is used in YOLOv3 for evaluating the object coordinates, therefore, extremely high tx absolute values are required for the bx value approaching the cx or cx + 1 values. We solve this problem through multiplying the sigmoid by a factor exceeding 1.0, so eliminating the effect of grid on which the object is undetectable.
-
M: Mosaic data augmentation - using the 4-image mosaic during training instead of single image
-
IT: IoU threshold - using multiple anchors for a single ground truth IoU (truth, anchor) > IoU threshold
-
GA: Genetic algorithms - using genetic algorithms for selecting the optimal hyperparameters during network training on the first 10% of time periods
-
LS: Class label smoothing - using class label smoothing for sigmoid activation
-
CBN: CmBN - using Cross mini-Batch Normalization for collecting statistics inside the entire batch, instead of collecting statistics inside a single mini-batch
-
CA: Cosine annealing scheduler - altering the learning rate during sinusoid training
-
DM: Dynamic mini-batch size - automatic increase of mini-batch size during small resolution training by using Random training shapes
-
OA: Optimized Anchors - using the optimized anchors for training with the 512x512 network resolution
-
GIoU, CIoU, DIoU, MSE - using different loss algorithms for bounded box regression
使用上述方法,实验结果如Table 4:
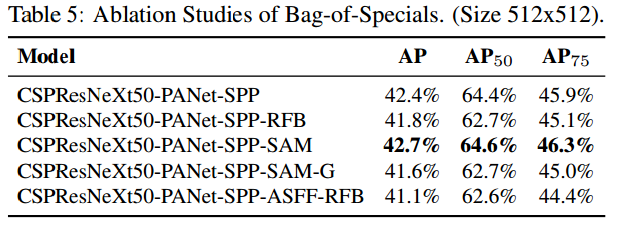
另外,也研究了不同的 Bagof-Specials (BoS-detector)对检测器训练精度的影响,包括PAN,RFB,SAM、 Gaussian YOLO (G)和ASFF,实验结果如Table 5所示,最终使用SPP,PAN和SAM可以取得最好的结果。
4.4. Influence of different backbones and pretrained weightings on Detector training
下面研究不同backbone对检测器精度的影响,实验结果如Table 6所示。

从上面的实验结果中可以看出,在分类上取得最好精度的模型并不一定在检测上也会取得最好的精度。首先,尽管 CSPResNeXt50比 CSPDarknet53在分类上取得更高的准确率,但是 CSPDarknet53模型在检测上反而取得更高的准确率。其次,在 CSPResNeXt50模型中,使用 BoF和Mish可以提高分类的准确率,但是使用这个pre-trained的权值来训练检测时,检测的精度会下降;然而,对于 CSPDarknet53模型,使用 BoF和Mish可以使得分类器和检测器(使用分类器的pre-trained模型)的精度可以得到提高。因此在检测中, CSPDarknet53比 CSPResNeXt50更加合适。
4.5. Influence of different mini-batch size on Detector training
最后,我们分析使用不同的mini-batch size对结果的影响。实验结果如Table 7所示。

从上面的表格中可以看出,使用BoF和BoS之后,mini-batch的大小几乎对检测器的精度没有什么影响。因此,有了BoF和BoS之后,就没有必要使用昂贵的GPU来训练了,任何人都可以使用一个GPU来训练一个优秀的检测器。
5. Results
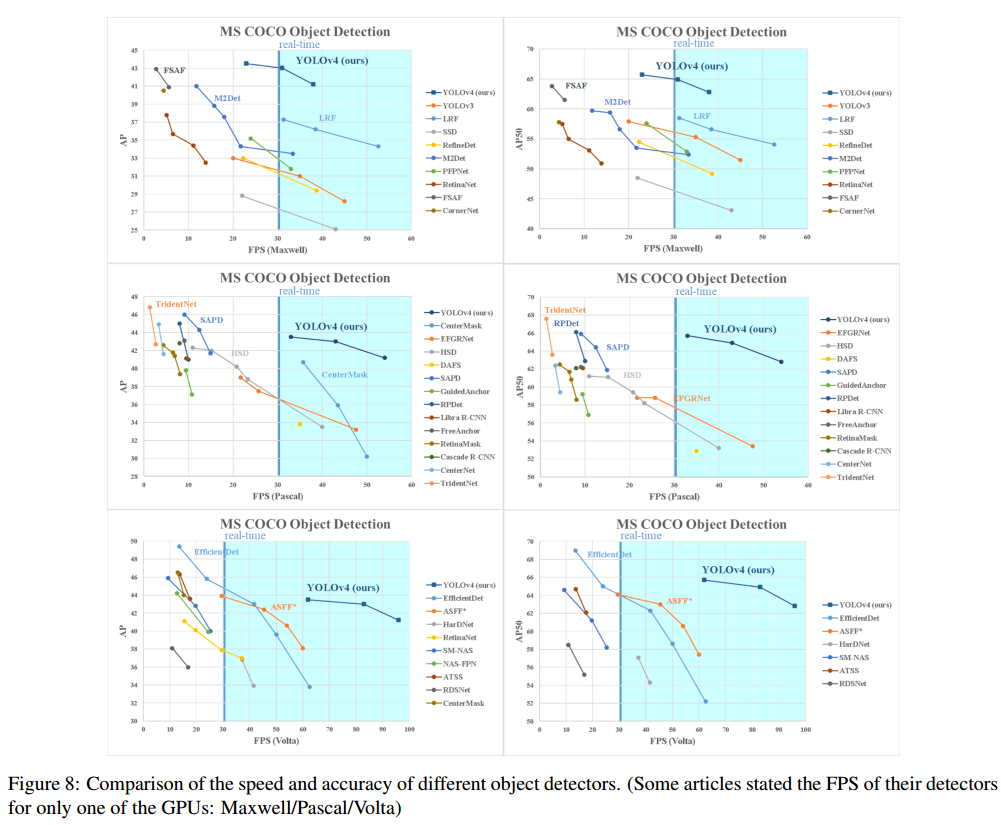
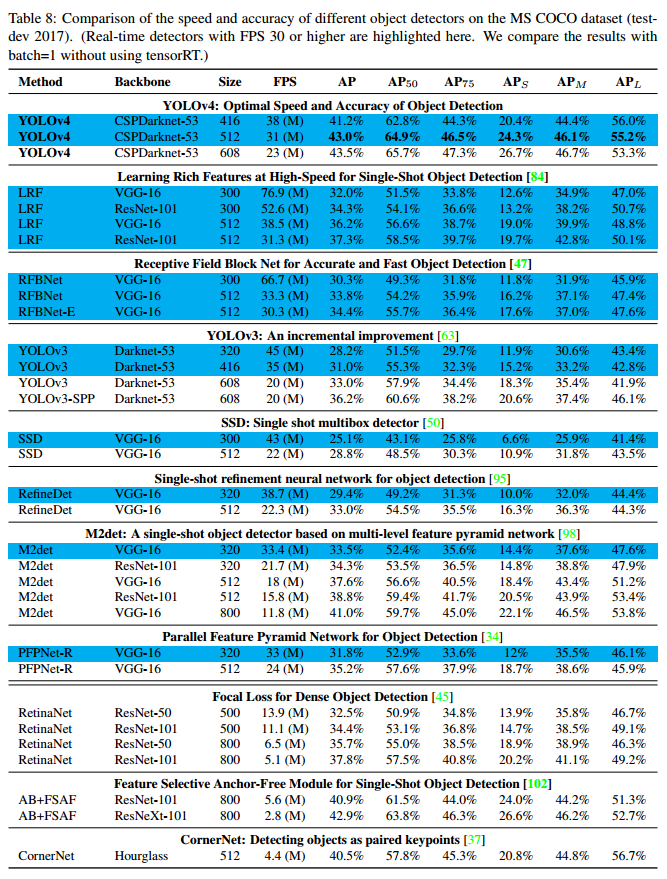
YOLOV4与其他state-of-the-art的目标检测算法比较如Figure 8所示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号