
CornerNet: Detecting Objects as Paired Keypoints
目前大部分常用的目标检测算法都是基于anchor的,比如Faster RCNN系列,SSD,YOLO(v2、v3)等,引入anchor后检测效果提升确实比较明显(比如YOLO v1和YOLO v2),但是引入anchor的缺点在于:1、正负样本不均衡。大部分检测算法的anchor数量都成千上万,但是一张图中的目标数量并没有那么多,这就导致正样本数量会远远小于负样本,因此有了对负样本做欠采样以及focal loss等算法来解决这个问题。2、引入更多的超参数,比如anchor的数量、大小和宽高比等。因此这篇不采用anchor却能有不错效果的CornerNet就省去了这几个额外的操作。
CornerNet算法整体框架
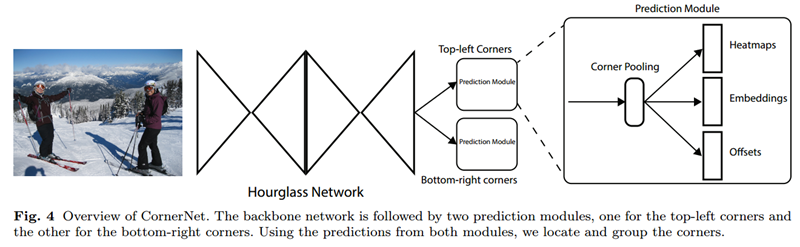
首先1个7×7的卷积层将输入图像尺寸缩小为原来的1/4(论文中输入图像大小是511×511,缩小后得到128×128大小的输出)。
然后经过特征提取网络(backbone network)提取特征,该网络采用hourglass network,该网络通过串联多个hourglass module组成(Figure4中的hourglass network由2个hourglass module组成),每个hourglass module都是先通过一系列的降采样操作缩小输入的大小,然后通过上采样恢复到输入图像大小,因此该部分的输出特征图大小还是128×128,整个hourglass network的深度是104层。
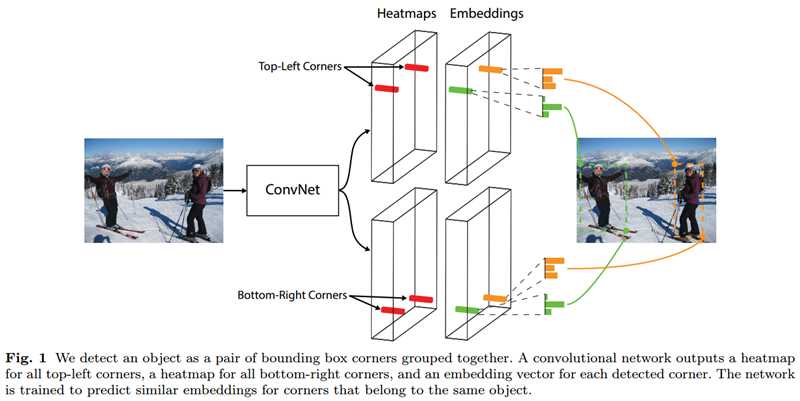
hourglass module后会有两个输出分支模块,分别表示左上角点预测分支和右下角点预测分支,每个分支模块包含一个corner pooling层和3个输出:heatmaps、embeddings和offsets。heatmaps是输出预测角点信息,可以用维度为C*H*W的特征图表示,其中C表示目标的类别(注意:没有背景类),这个特征图的每个通道都是一个mask,mask的每个值(范围为0到1,论文中写的该mask是binary mask,也就是0或1,个人感觉是笔误,预测值应该是0到1,否则后面公式1计算损失函数时就没有意思了)表示该点是角点的分数;embeddings用来对预测的corner点做group,也就是找到属于同一个目标的左上角角点和右下角角点;offsets用来对预测框做微调,这是因为从输入图像中的点映射到特征图时有量化误差,offsets就是用来输出这些误差信息。
网络会计算三个部分的loss,分别是左上角和右下角的heatmap部分的loss,下采样导致的量化误差offset部分的loss,和决定左上角点和右下角点是否都属于同一个bbox的embdding的loss。
- Heatmaps has C channels, where C is the number of categories.
- The heatmap represents the locations of keypoints of different categories and assigns a confidence score for each keypoint.
- a variant of focal loss
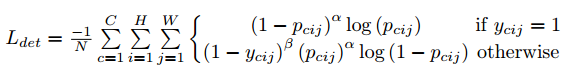
The offsets learn to remap the corners from the heatmaps to the input image.
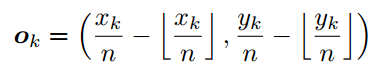
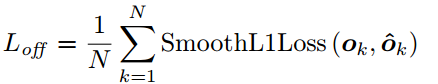
embedding (1 dimension ): determine if a pair of the top-left corner and bottom-right corner is from the same bounding box.
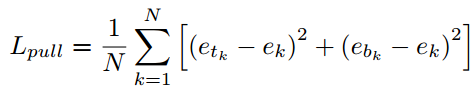
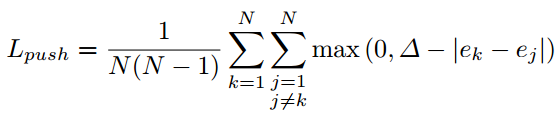
where ek is the average of etk and ebk and we set ∆ to be 1.
Corner Pooling
一般情况下,左上角点和右下角点都不在实际物体的轮廓内部,因此会缺少一些视觉上的特征,于是作者提出了corner pooling,具体的计算方法如下:
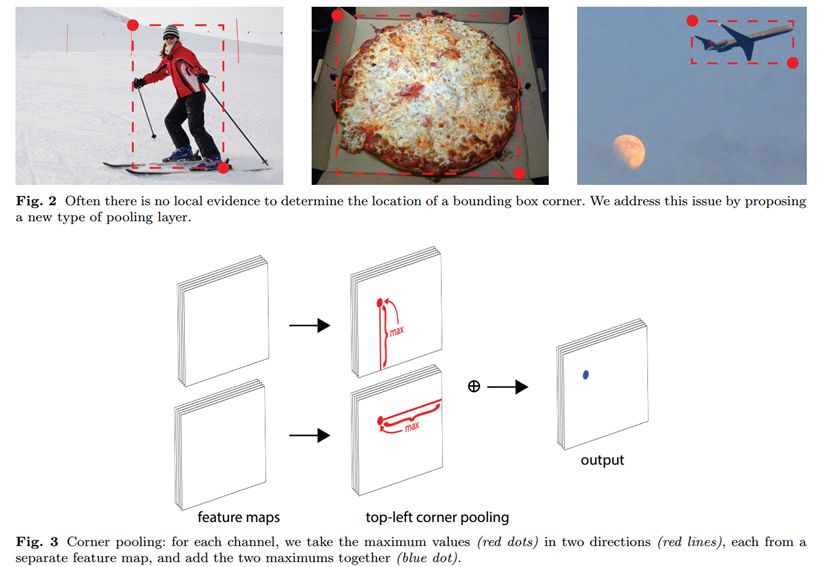
上图是针对左上角点做corner pooling的示意图,该层有2个输入特征图,特征图的宽高分别用W和H表示,假设接下来要对图中红色点(坐标假设是(i,j))做corner pooling,那么就计算(i,j)到(i,H)的最大值(对应Figure3上面第二个图),类似于找到Figure2中第一张图的左侧手信息;同时计算(i,j)到(W,j)的最大值(对应Figure3下面第二个图),类似于找到Figure2中第一张图的头顶信息,然后将这两个最大值相加得到(i,j)点的值(对应Figure3最后一个图的蓝色点)。右下角点的corner pooling操作类似,只不过计算最大值变成从(0,j)到(i,j)和从(i,0)到(i,j)。
参考链接:
CornerNet 算法笔记,原文链接:https://blog.csdn.net/u014380165/article/details/83032273

 浙公网安备 33010602011771号
浙公网安备 33010602011771号