


大数据Hadoop学习一
大数据概述:
分布式技术完成海量数据的处理
核心工作:从海量的高增长、多类别、低信息密度的数据中挖掘出高质量的结果
总结为三点:数据计算 数据存储 数据传输
大数据软件生态:
数据存储:
Apache Hadoop-HDFS(大数据体系中使用最为广泛的分布式存储技术)
Apache HBase(大数据体系中使用非常广泛的NoSQL KV型数据库技术,HBase是基于HDFS之上构建的)
Apache KUDU(使用较多的分布式存储引擎)
数据计算:
Apache Hadoop-MapReduce(最早一代的大数据分布式计算引擎)
Apache Hive(以SQL为要开发语言的分布式计算框架,底层使用了Hadoop的MapReduce技术)
Apache Spark(分布式内存计算引擎)
Apache Flink(分布式内存计算引擎,在实时计算也就是流计算领域,占据大多数国内市场)
数据传输:
Apache Kafka(分布式消息系统,可完成海量规模的数据传输工作)
Apache Pulsar(也是分布式的消息系统)
Apache Flume(流式数据采集工具,可以从众多数据源中完成数据的采集传输的任务)
Apache Sqoop(是一款ETL工具,可协助大数据体系和关系型数据库之间进行数据传输)
Apache Hadoop
可以部署在1台乃至成千上万服务器节点上协同工作
个人或者企业可以借助Hadoop构建大规模服务器集群,完成海量数据的存储和计算
三大功能:
分布式数据存储
分布式数据计算
分布式策源调度
为一体的整体解决方案
三个功能组件:
HDFS组件(分布式存储组件,可以构建分布式文件系统用于数据存储)
MapReduce组件(分布式计算组件,提供编程接口供用户开发分布式计算程序)
YARN组件(分布式资源调度组件 可供用户整体调度大规模集群的资源使用)
Hadoop HDFS分布式文件系统
为什么要使用分布式存储技术
数据量太大,单机存储能力有上限,需要靠数量解决问题,分布式组合在一起可以达到1+1>2的效果
例子:文件太大时,单台服务器无法承担,要靠数量取胜,多台服务器组合,完成存储任务
分布式存储技术不仅仅解决存的问题,多台服务器协同工作带来的是性能的横向拓展
例如:将一个文件分成三份,存入三台服务器,实现三倍的网络传输效率,三倍的磁盘写入效率(取出文件也是这样有三倍的网络传输效率和三倍的磁盘读取效率)
分布式的基础架构分析
分布式的基础架构:
大数据体系中,分布式的调度主要有两类架构模式:
去中心化模式
就是没有明确的中心,众多服务器之间基于特定规则进行同步协调
中心化模式
有明确中心,听一个服务器调度
主从模式
大数据框架中,多数的基础框架上,都是符合中心化模式的,即:有一个中心节点(服务器)来统筹其他的服务器工作,统一指挥,统一调派,避免混乱。
这种模式也称为:一主多从模式,简称主从模式
典型:公司企业管理、组织管理、行政管理
Hadoop是典型的主从模式架构的技术框架
HDFS的基础架构
HDFS以及其和hadoop的关系
HDFS是Hadoop技术栈内提供的分布式数据存储解决方案可以在多台服务器上构建存储集群,存储海量数据
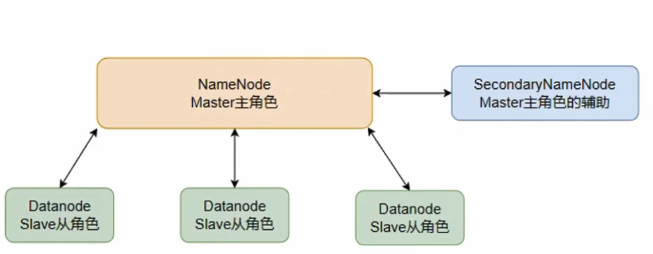
Hadoop HDFS分布式存储系统的基础架构角色
HDFS是一个典型的主从模式架构(中心化模式架构)
HDFS集群:
主角色:NameNode(发布命令)
基础架构
HDFS的集群环境部署
VMware虚拟机中部署
官网下载地址:
https://hadoop.apache.org/releases.html
集群规划:
三台虚拟机的硬件配置:
| 节点 | CPU | 内存 |
|---|---|---|
| node1 | 1核心 | 4GB |
| node2 | 1核心 | 2GB |
| node3 | 1核心 | 2GB |
服务规划:
| 节点 | 服务 |
|---|---|
| node1 | NameNode、DataNode、SecondaryNodeNode |
| node2 | DataNode |
| node | DateNode |
| 由此集群由一个主节点带领三个从节点构成 |
上传&解压
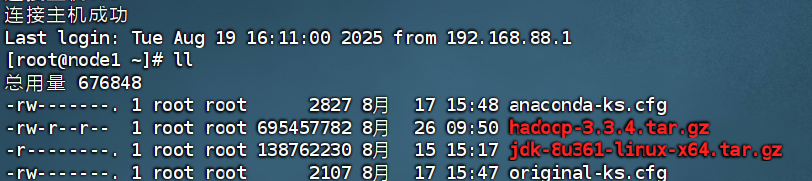
1.上传Haddop安装包到node1节点中
借助FinalShell完成上传(直接将压缩包拖拽到目录中即可)
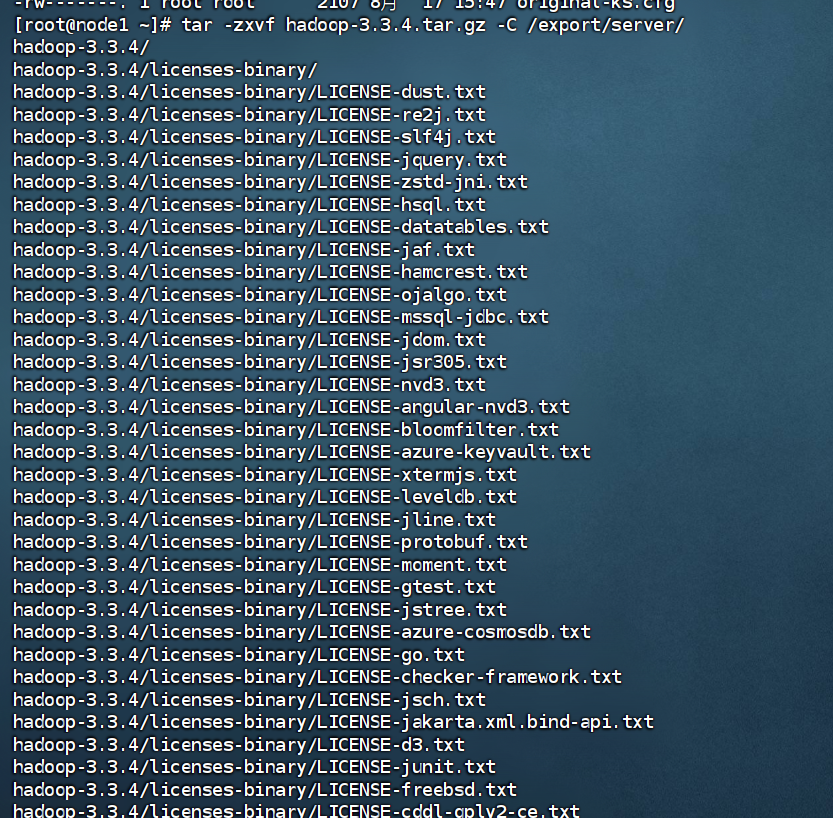
2.解压压缩包到/export/server/中
tar -zxvf hadoop-3.3.4.tar.gz -C/export/server
进行解压缩
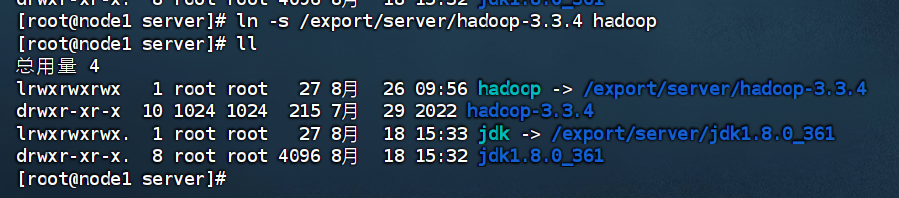
3.构建软链接
cd /export/server
ln -s /export/server/hadoop-3.3.4 hadoop
/export/server目录中存在hadoop

完成软链接构建
4.进入hadoop安装包内
cd hadoop
借助命令ls -l(或者ll)查看文件夹内部结构
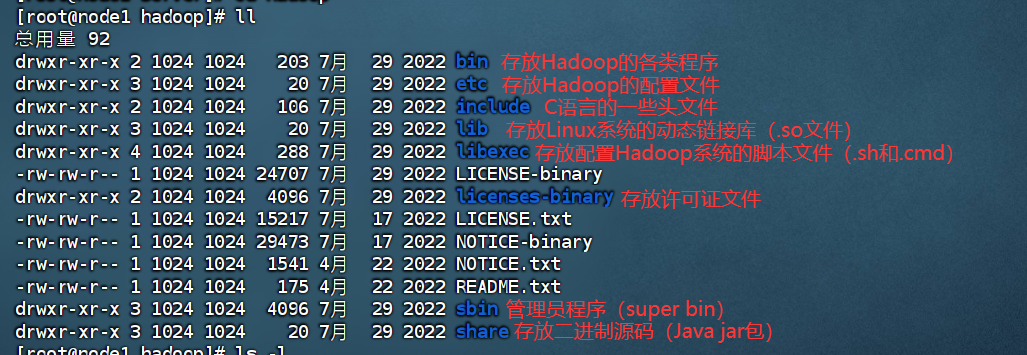
以上图片中重要的就是bin、etc(部署阶段重点关注)和sbin
修改配置文件,应用自定义设置
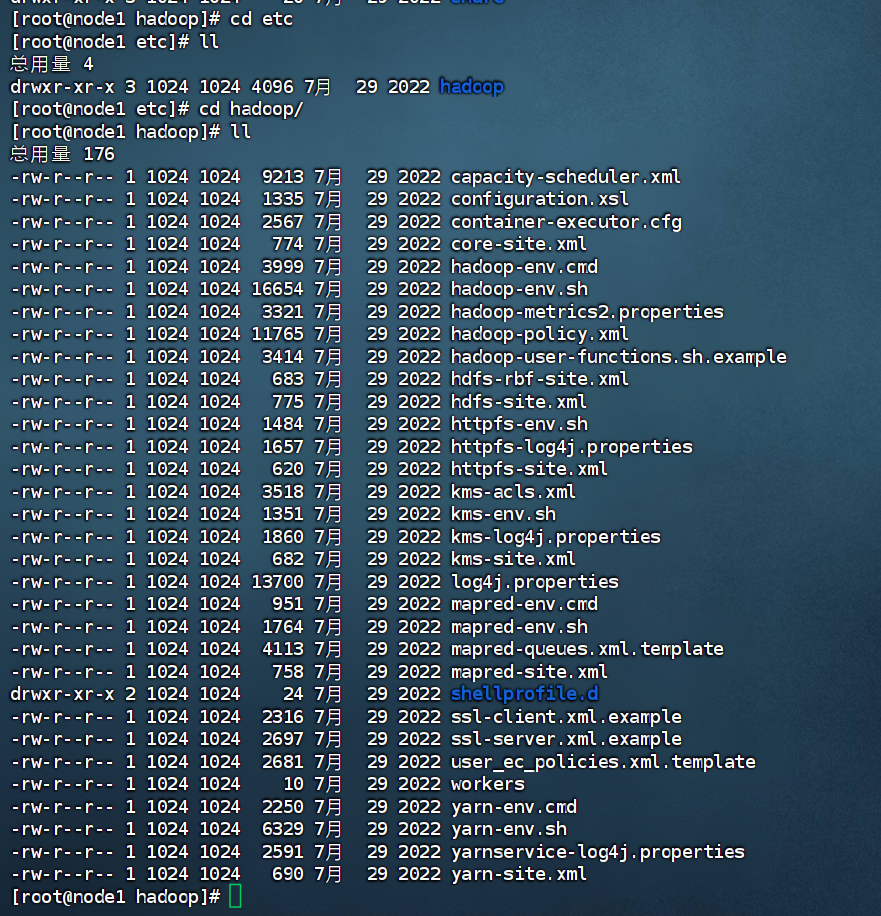
配置HDFS集群,涉及以下文件的修改:
以上文件存在于$HADOOP_HOME/etc/hadoop
ps:$HADOOP_HOME是后续要设置的环境变量,其代指Hadoop安装文件夹即/export/server/hadoop
#进入配置文件目录
cd etc/hadoop
#编辑workers文件
vim workers
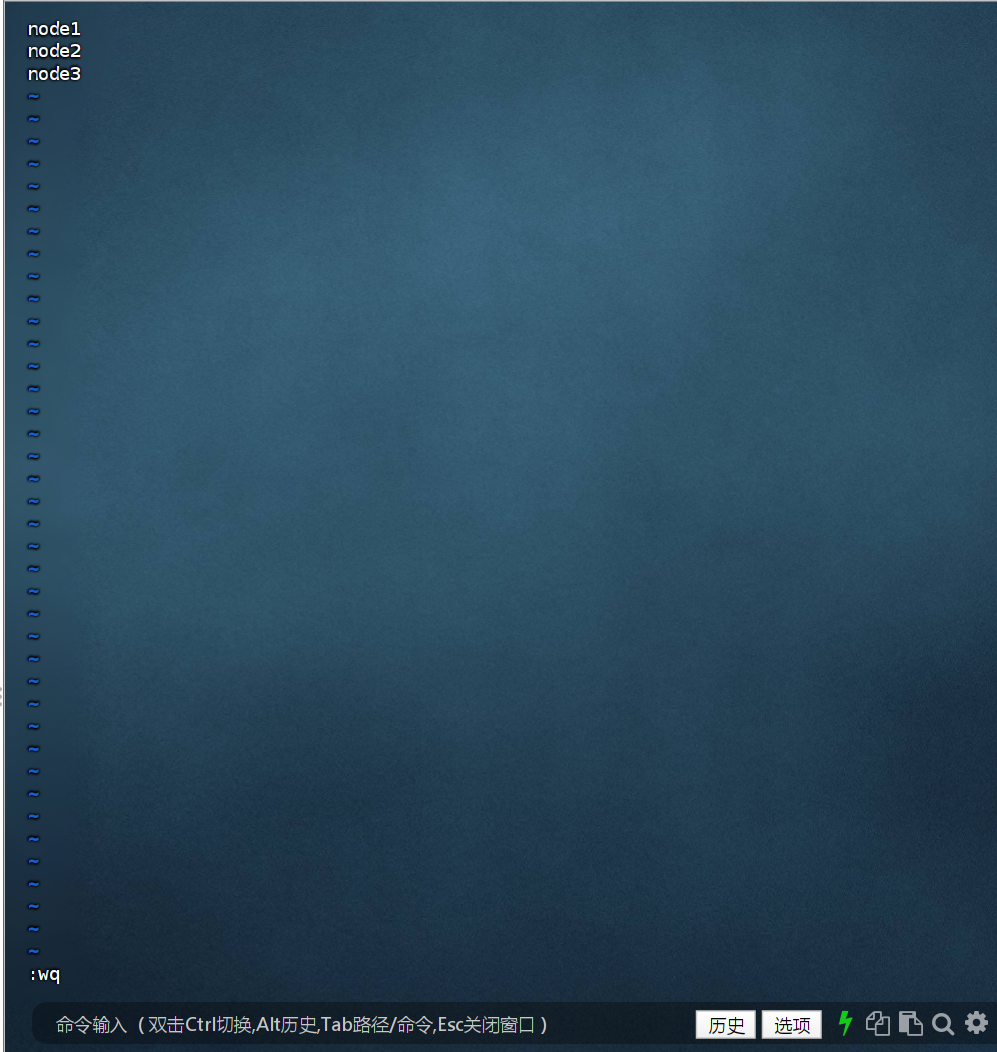
#填入如下内容
node1
node2
node3
填入的node1、node2、node3表明集群记录了三个从节点(DataNode)
服务规划:
| 节点 | 服务 |
|---|---|
| node1 | NameNode、DataNode、SecondaryNodeNode |
| node2 | DataNode |
| node | DateNode |
在以上的服务器划分中三个服务器都划分了DataNode,所以在workers文件中要填入三个node123服务器
进入workers文件内
按两下dd删除现有的内容再填入上述内容
然后点击Esc然后输入:wq保存
#填入如下内容
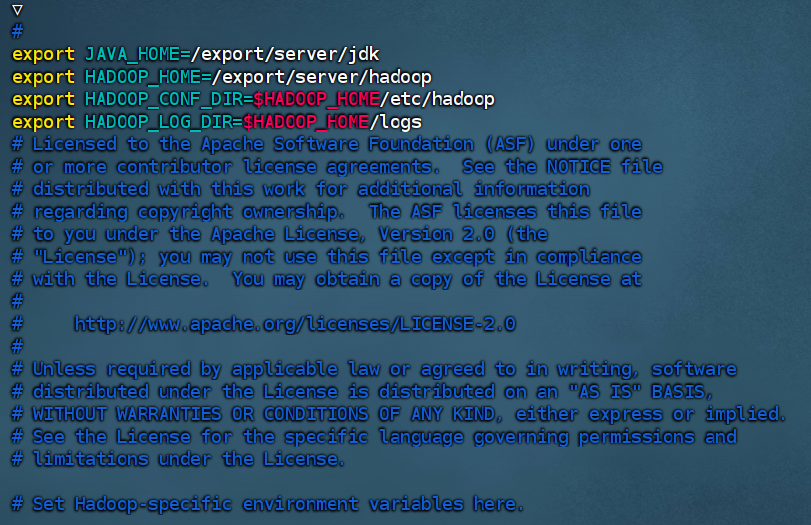
#JAVA_HOME指出JDK环境的位置
export JAVA_HOME=/export/server/jdk
#HADOOP_HOME指明Hadoop安装位置
export HADOOP_HOME=/export/server/hadoop
#HADOOP_CONF_DIR指明Hadoop配置文件目录位置
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#HADOOP_LOG_DIR指明Hadoop运行日志目录位置
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
输入vim hadoop-env.sh回车进入
接着填入上面提到的内容
通过记录这些环境变量,来指明上述运行的重要信息
#在文件中填入
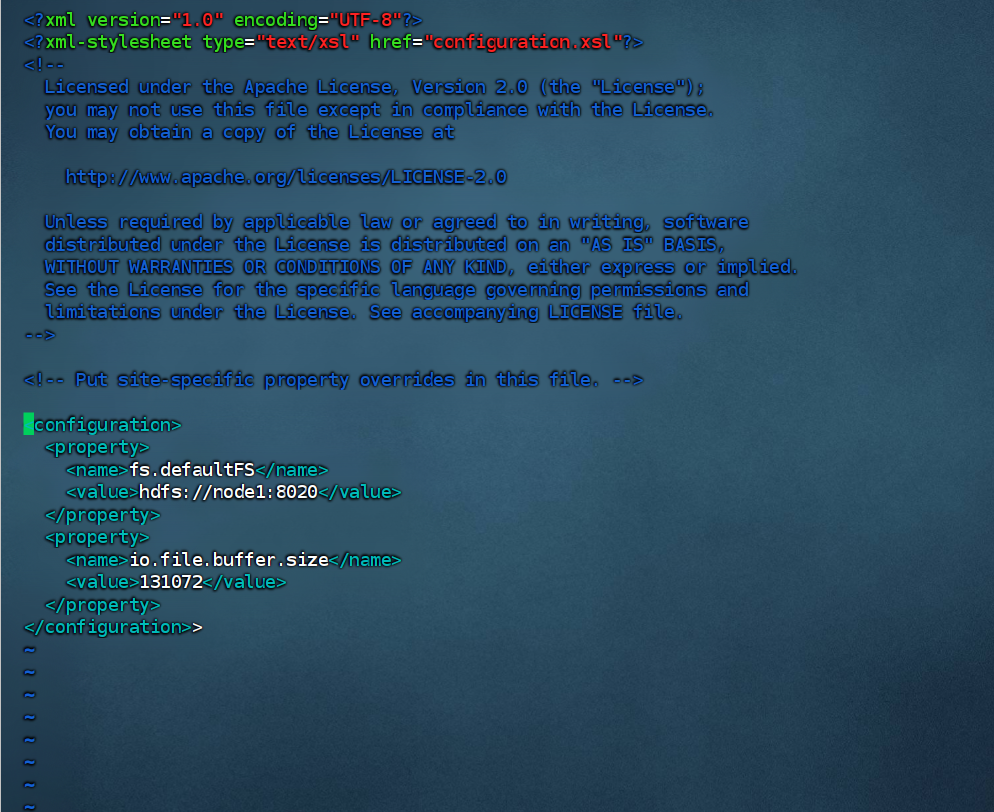
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
以上代码中
key:fs.defaultFS
含义:HDFS文件系统的网络通讯路径、
值:hdfs://node1:8020
key:io.file.buffer.size
含义:io操作文件缓冲区大小
值:131072bit
hdfs://node1:8020为整个HDFS内部的通讯地址,应用协议为hdfs://(Hadoop内置协议)
表明DataNode将和node1的8020端口通讯,node1是NameNode所在机器
此配置固定了node1必须启动NameNode进程
使用vim core-site.xml打开该文件
填入内容
#在文件内部填入如下内容\
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>
解释:
含义:hdfs文件系统,默认创建的文件权限设置(hadoop新建的文件默认权限为700的权限)
值:700,即:rwx------
含义:NameNode元数据的存储位置
值:/data/nn,在node1节点的/data/nn目录下
含义:NameNode允许那几个节点的DataNode连接(即允许加入集群)
值:node1、node2、node3,这三台服务器被授权(哪几个是被主机认证的)
含义:hdfs默认块大小
值:268435456(256MB)
含义:namenode处理的并发线程数
值:100,以100个并行度处理文件系统的管理任务
含义:从节点DataNode的数据存储目录
值:/data/dn,即数据存放在node1、node2、node3,三台机器的/data/dn内
准备数据目录
根据下述两个配置项:
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
namenode数据存放的node1的/data/nn
datanode数据存放node1、node2、node3的/data/dn
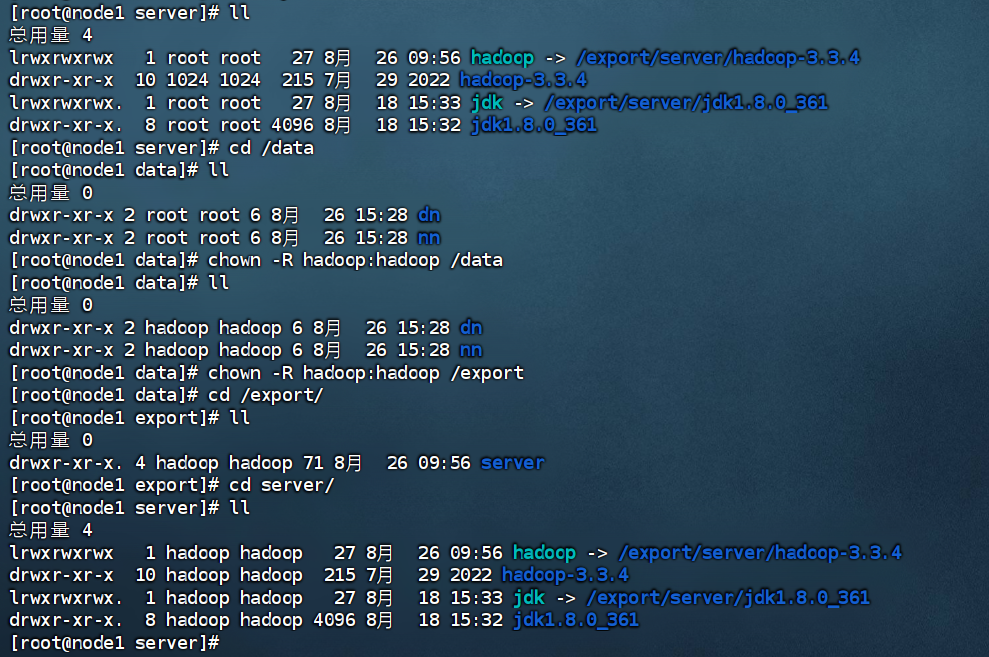
所以应该在node1节点:
mkdir -p /data/nn
mkair /data/dn
在node2和node3节点:
mkdir -p /data/dn

分发Hadoop文件夹
到此为止,已经基本完成Hadoop的配置操作,可以从node1将hadoop安装文件夹远程复制到node2、node3
#在node1执行如下命令
cd /export/server
scp -r hadoop-3.3.4 node2:`pwd`/
scp -r hadoop-3.3.4 node3:`pwd`/
scp操作需要大概五分钟左右
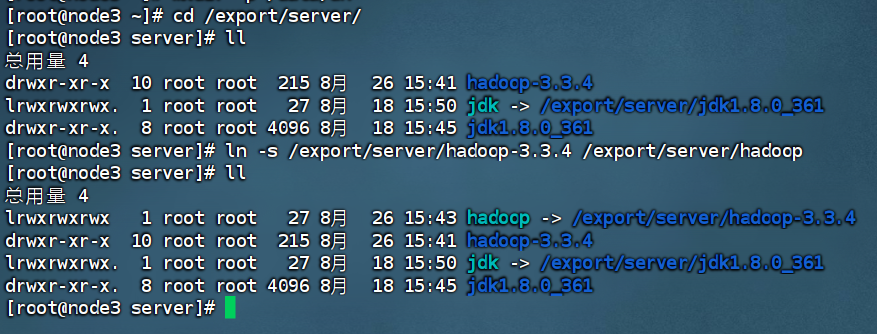
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop
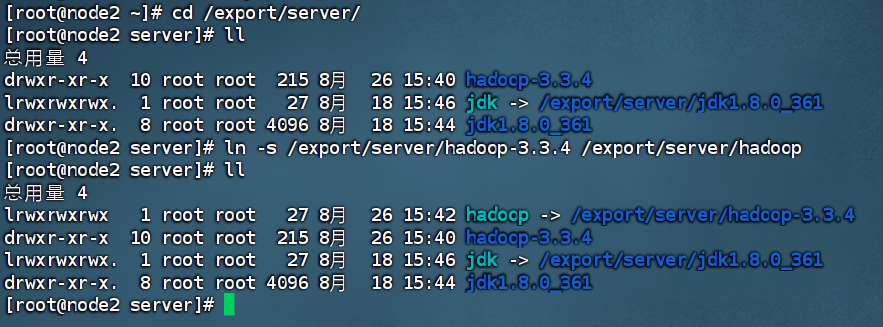
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop
配置环境变量
为了方便,可以将Hadoop的一些脚本、程序配置到PATH中,便于使用
在Hadoop文件夹中的bin、sbin两个文件夹内有许多的脚本和程序
1.vim /etc/profile
#在/etc/profile文件底部追加如下内容
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使用source /etc/profile刷新配置
2.在node2和node3配置同样的环境变量
授权为hadoop用户
为了安全,hadoop系统不以root用户启动,我们以普通用户hadoop来启动整个hadoop服务
所以要对文件权限进行授权
ps:确保已经创建好了hadoop用户,并配置好了hadoop用户之间的免密登录
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
格式化整个文件系统
前期准备全部完成,现在对整个文件系统执行初始化
#确保以hadoop用户执行
su - hadoop
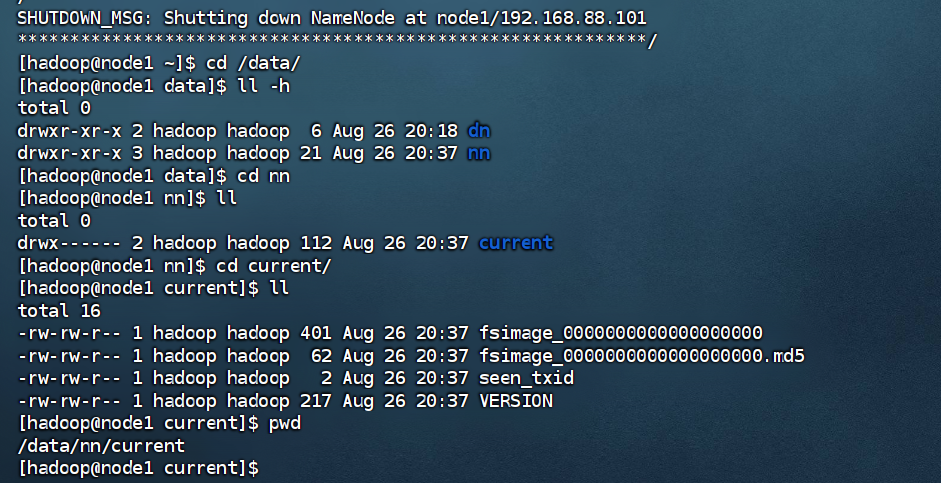
#格式化namenode
hadoop namenode -format
格式化成功验证
#一键启动hdfs集群
start-dfs.sh
#一键关闭hdfs集群
stop-dfs.sh
#如果遇到命令未找到的操作,表明环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh
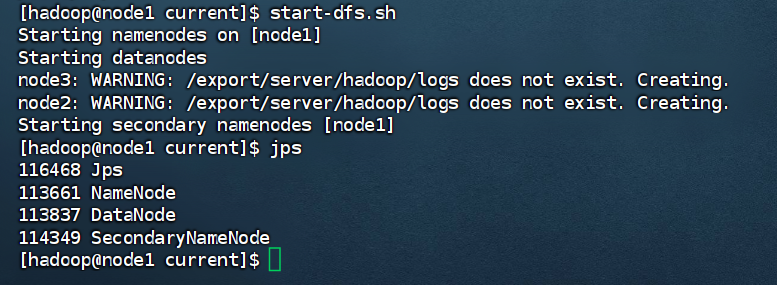
按照服务规划node1启动结果如下
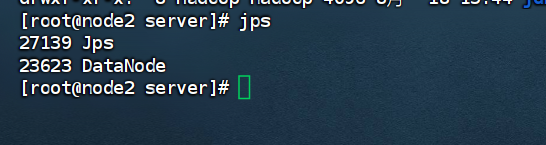
node2结果如下:
node3结果如下:

查看HDFS WEBUI
启动完成后,可以在浏览器打开:
http://node1:9870,即可查看到hdfs文件系统的管理网页
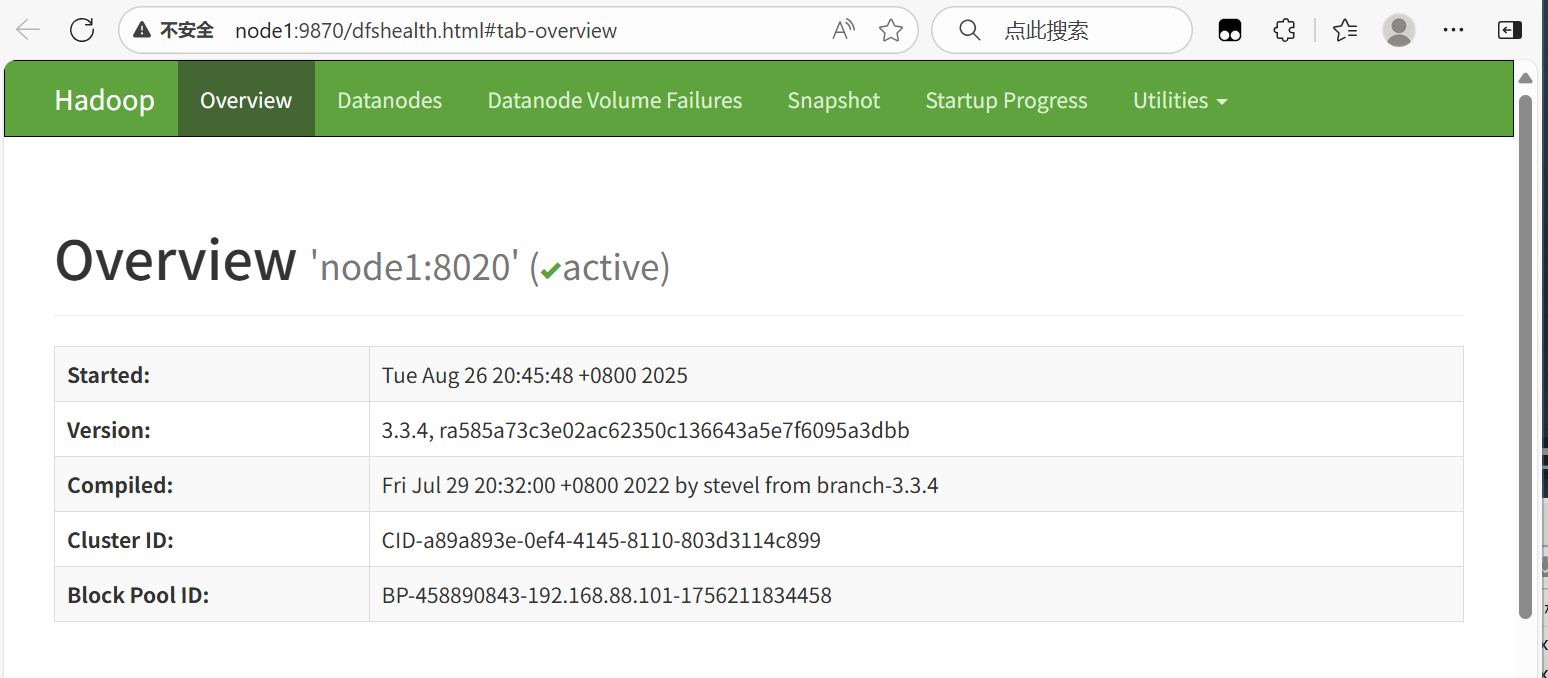
可以看见整个HDFS文件的详细信息
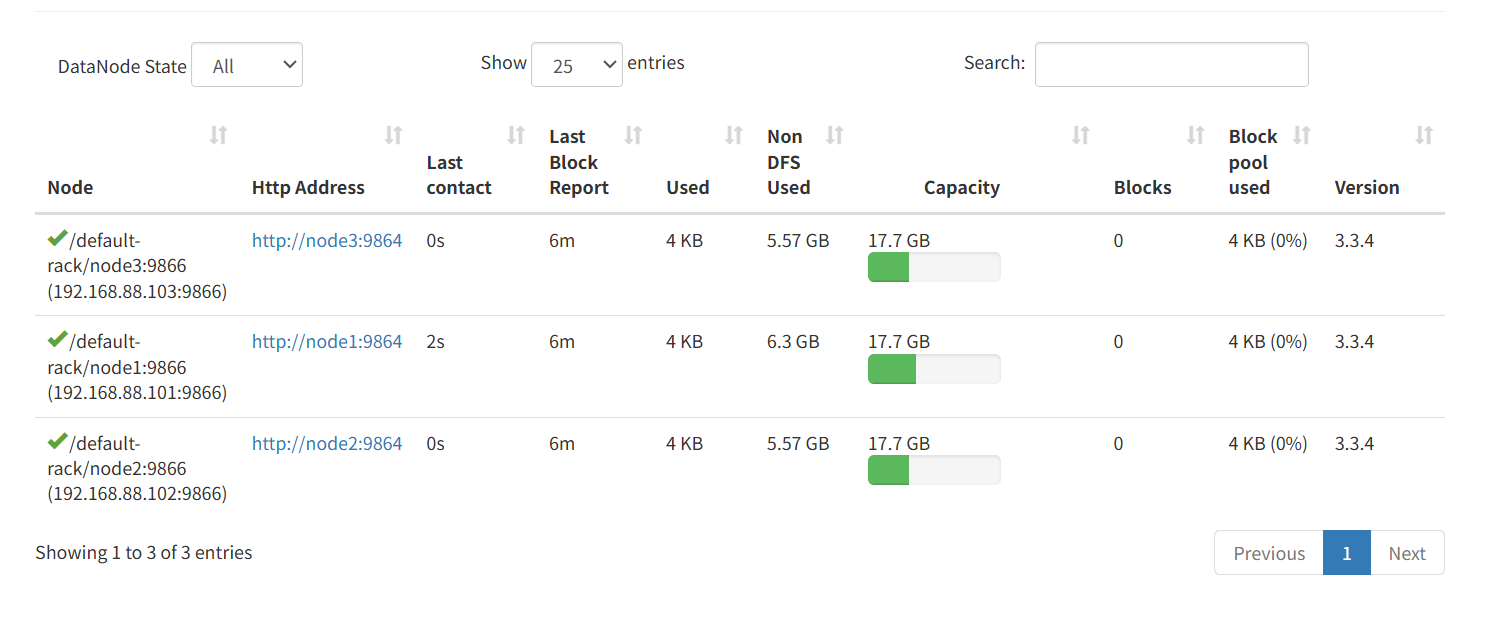
关闭集群:
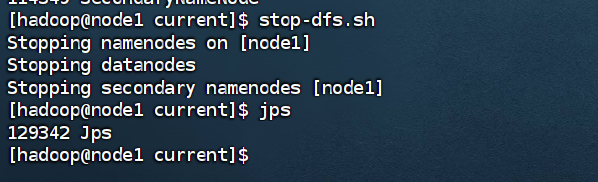
总结
遇到的问题:
如何更换目录返回使用cd命令
有时候连接会断开,需要重新连接
之前下载到电脑上的Hadoop压缩包存在问题,在虚拟机解压缩时文件存在损坏,导致hadoop不能使用,之后更换华为云镜像进行重新下载后重新配置了
wget https://mirrors.huaweicloud.com/apache/hadoop/common/hadoop-3.4.1/hadoop-3.4.1.tar.gz

 浙公网安备 33010602011771号
浙公网安备 33010602011771号