

第3次作业:卷积神经网络
1.卷积神经网络
1.加载数据(MNIST)
PyTorch里包含了 MNIST, CIFAR10 等常用数据集,调用 torchvision.datasets 即可把这些数据由远程下载到本地。
Dataset是一个包装类,用来将数据包装为Dataset类,然后传入DataLoader中,再使用DataLoader这个类来更加快捷的对数据进行操作。其中getitem方法支持从0到len(self)的索引。
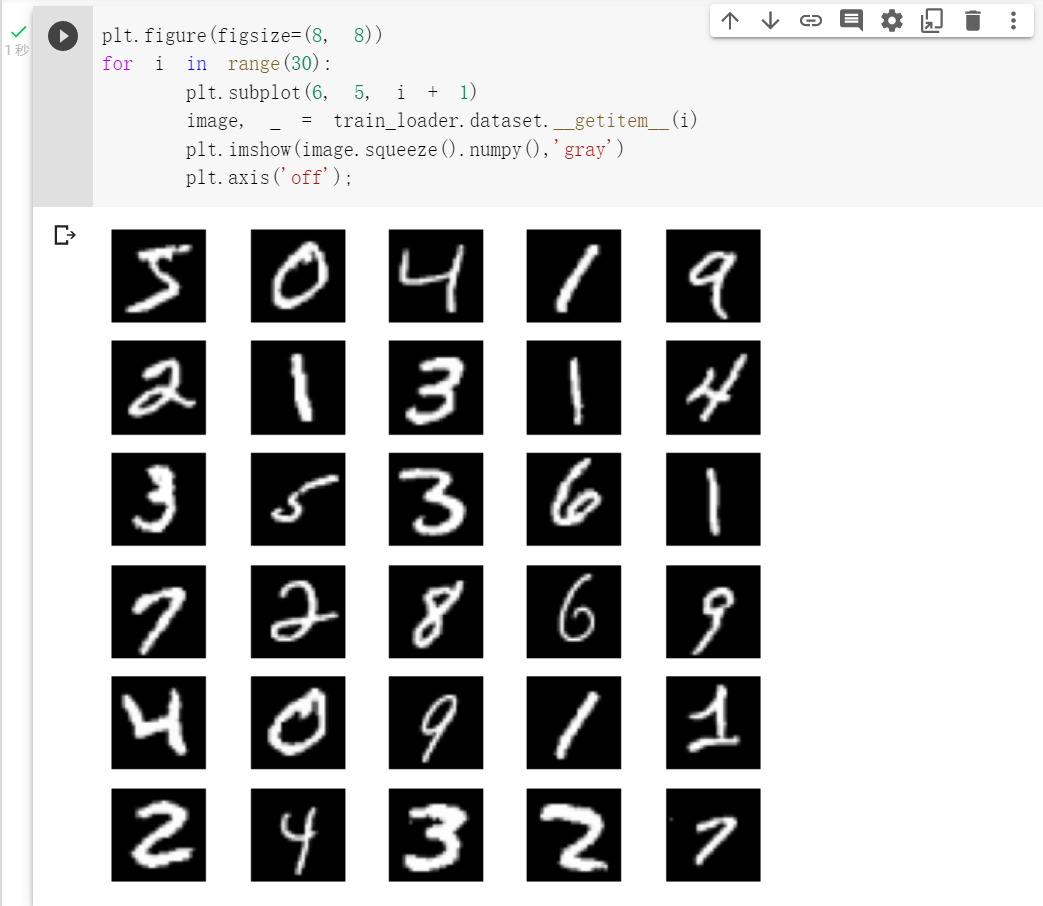
显示数据中部分图像:
plt.subplot(x,y,i)让图像呈矩阵显示,x表示行,y表示列,i表示第几个图像。
plt.axis('off')表示不显示坐标轴
2.创建网络
nn.Sequential是一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数,将网络的层组合在一起。
nn.Linear(a,b)用于设置网络中的全连接层,第一个参数表示输入的二维张量的大小,第二个参数表示输出的二维张量的大小,同时也代表全连接层的神经元个数
nn.ReLu()使用ReLu激活函数,加快收敛,防止梯度消失。
下图是全连接神经网络的实现。

forward方法的具体流程,以一个Module为例:
1. 调用module的call方法
2. module的call里面调用module的forward方法
3. forward里面如果碰到Module的子类,回到第1步,如果碰到的是Function的子类,继续往下
4. 调用Function的call方法
5. Function的call方法调用了Function的forward方法。
6. Function的forward返回值
7. module的forward返回值
8. 在module的call进行forward_hook操作,然后返回值。
下图是卷积神经网络的实现。

定义训练函数和测试函数,训练使用BP算法


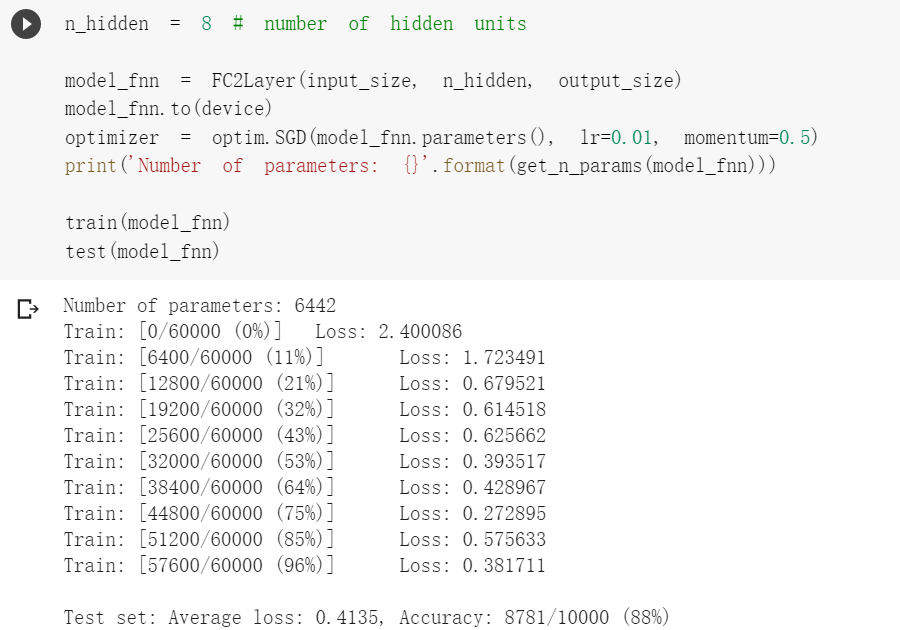
3.在小型全连接网络上训练
4.在卷积神经网络上训练
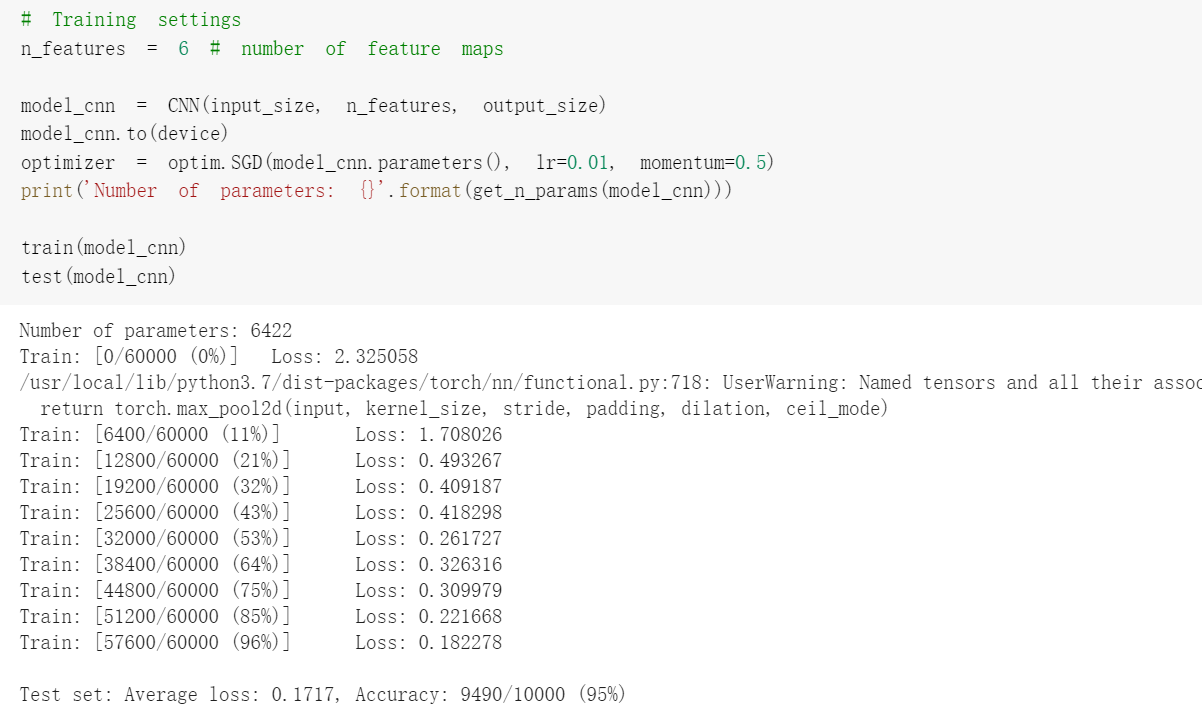
对比两个结果会发现,在参数相同的情况下,CNN能够更准确的对图片中的数字进行识别,这是因为CNN利用卷积和池化能够更好的挖掘图片中的有效信息,CNN可以更好地利用图片的局部信息,但是全连接网络却做不到。为了验证这个结论,接下来将图片的像素顺序打乱,训练和测试函数也基本相同,只是对data加入了打乱顺序操作,然后会发现CNN的准确率大幅度下降,而全连接神经网络的准确率没有变化。
2.CIFAR10 数据集分类
1.加载并归一化 CIFAR10
使用 torchvision ,torchvision 数据集的输出是范围在[0,1]之间的 PILImage,我们将他们转换成归一化范围为[-1,1]之间的张量 Tensors。
import torch import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np import torch.nn as nn import torch.nn.functional as F import torch.optim as optim # 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # 注意下面代码中:训练的 shuffle 是 True,测试的 shuffle 是 false # 训练时可以打乱顺序增加多样性,测试是没有必要 trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=8, shuffle=False, num_workers=2) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
2.展示部分图像及其标签
img = img / 2 + 0.5 的作用是让图片归一化。图像归一化使得图像可以抵抗几何变换的攻击,它能够找出图像中的那些不变量,从而得知这些图像原本就是一样的或者一个系列的,还可以保证输出数据中数值小的不被吞食。
def imshow(img): plt.figure(figsize=(8,8)) img = img / 2 + 0.5 # 转换到 [0,1] 之间 npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show() # 得到一组图像 images, labels = iter(trainloader).next() # 展示图像 imshow(torchvision.utils.make_grid(images)) # 展示部分图像的标签 for j in range(20): print(classes[labels[j]])
部分标签展示如下:

3.定义网络、损失函数和优化器
nn.Conv2d函数参数的意义:class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
nn.Conv2d(3, 6, 5)中3表示输入三个频道(即RGB),6是6张特征图,5是卷积核的尺寸,输出结果为28*28*6;
nn.MaxPool2d(2, 2)采用最大值池化,窗口大小为2x2,输出结果是14*14*6;
nn.Conv2d(6, 16, 5):输入是14*14*6,计算(14 - 5)/ 1 + 1 = 10,那么通过conv2输出的结果是10*10*16;
nn.Linear(16 * 5 * 5, 120) :定义fc1(fullconnect)全连接函数1为线性函数:y = Wx + b,并将16*5*5个节点连接到120个节点上;
nn.Linear(120, 84) : 定义fc2(fullconnect)全连接函数2为线性函数:y = Wx + b,并将120个节点连接到84个节点上;
nn.Linear(84, 10) # 定义fc3(fullconnect)全连接函数3为线性函数:y = Wx + b,并将84个节点连接到10个节点上;
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 网络放到GPU上
net = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
4.训练网络
for epoch in range(10): # 重复多轮训练 for i, (inputs, labels) in enumerate(trainloader): inputs = inputs.to(device) labels = labels.to(device) # 优化器梯度归零 optimizer.zero_grad() # 正向传播 + 反向传播 + 优化 outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 输出统计信息 if i % 100 == 0: print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item())) print('Finished Training')
5.识别准确率
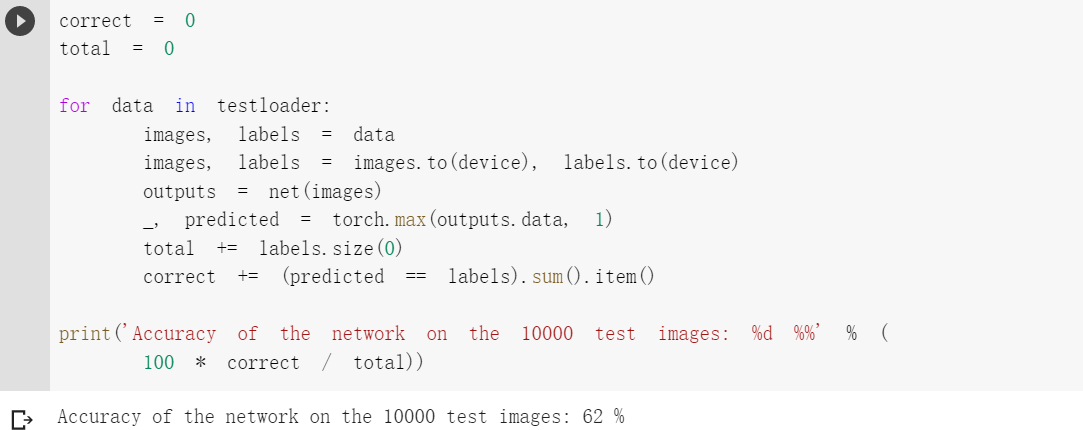
3.使用 VGG16 对 CIFAR10 分类
1.VGG定义
class VGG(nn.Module): def __init__(self): super(VGG, self).__init__() self.cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'] self.features = self._make_layers(cfg) self.classifier = nn.Linear(2048, 10) def forward(self, x): out = self.features(x) out = out.view(out.size(0), -1) out = self.classifier(out) return out def _make_layers(self, cfg): layers = [] in_channels = 3 for x in cfg: if x == 'M': layers += [nn.MaxPool2d(kernel_size=2, stride=2)] else: layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1), nn.BatchNorm2d(x), nn.ReLU(inplace=True)] in_channels = x layers += [nn.AvgPool2d(kernel_size=1, stride=1)] return nn.Sequential(*layers)
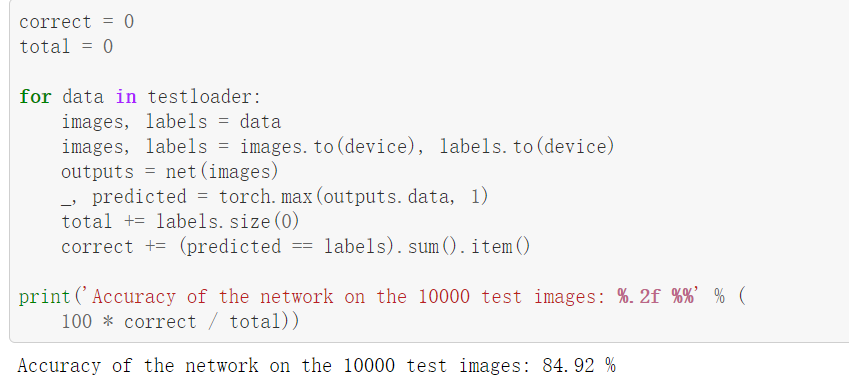
2.图片识别结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号