
学年论文——管理论文中的数据分析方法与可视化呈现
在管理类学年论文中,数据分析不仅是验证理论假设的关键步骤,更是连接模型构建与研究结论的核心纽带。随着数据意识与分析工具的普及,学生已不再满足于简单的描述统计,而是需要掌握从信度效度检验、相关分析、回归建模到中介调节效应的系统方法,进而提升论文的学术严谨性与实践解释力。同时,数据可视化作为沟通研究成果的重要手段,也越来越受到重视。通过图表展现样本特征、变量关系与模型效果,能够更清晰地传达研究发现,增强论文的表达力与说服力。
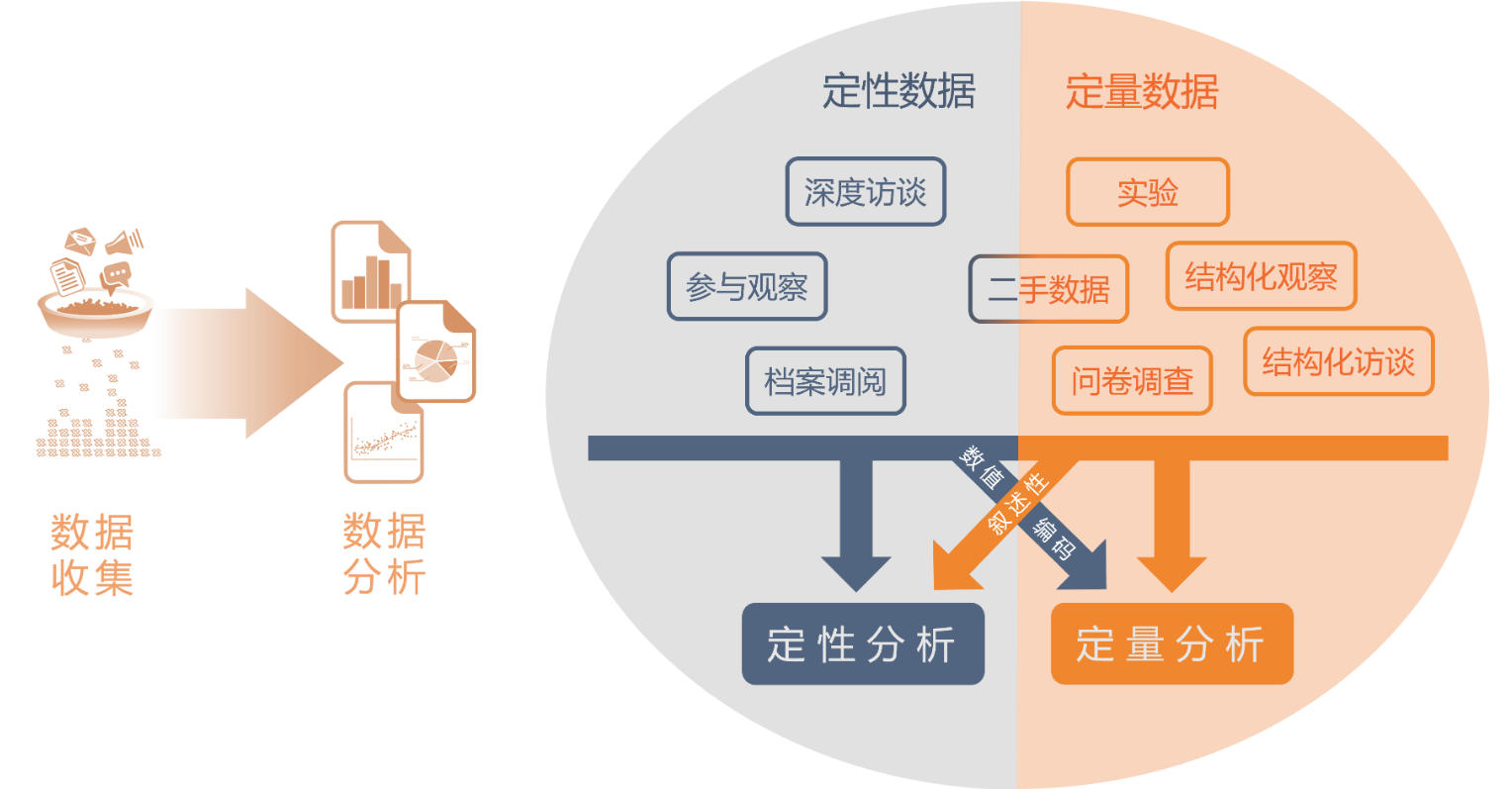
引言:从原始数据到研究发现的转化之路
完成问卷调查或数据采集后,研究工作才刚刚进入“实证分析”的核心阶段。数据分析不仅是技术操作的体现,更是验证研究假设、发现现象背后规律的重要过程。在管理类学年论文中,常见的数据分析方法涵盖描述性统计、信度与效度分析、相关性检验、回归分析、结构方程模型等。
本篇博客将以“从基本到深入”的逻辑,系统梳理管理论文中最常用的数据分析步骤与技术路线,结合R语言与Excel的实际操作展示,并配合图表可视化原则,帮助你完成从数据到结论的全过程,提供完整的操作路径与案例范式,助你迈过“从数据到结论”的关键门槛。
一、数据整理与编码:从问卷到可分析格式
1.1 数据清洗流程
| 步骤 | 内容 | 工具建议 |
|---|---|---|
| 1 | 导入数据(Excel/CSV格式) | R、SPSS、Excel |
| 2 | 删除空值/无效问卷 | 设置逻辑检查规则 |
| 3 | 变量重命名 | 统一英文编码,如 job_sat1/job_sat2 |
| 4 | 反向题项编码调整 | 将反向项得分处理为正向 |
| 5 | 类型转换 | 将文本型变量转换为数值型/因子型 |
1.2 示例:R语言导入与预处理代码
library(readr)
data <- read_csv("survey.csv")
data <- data[data$validity_check == 1, ] # 删除不符合逻辑项
names(data) <- c("gender", "age", "edu", "sat1", "sat2", "leave1")
data$sat2 <- 6 - data$sat2 # sat2为反向项
二、描述性统计:了解样本全貌
2.1 样本特征统计表
| 项目 | 方法 | 工具 |
|---|---|---|
| 性别分布 | 频数+百分比 | R: table() + prop.table() |
| 年龄均值 | 均值+标准差 | R: mean(), sd() |
| 学历分布 | 条形图展示 | ggplot2 / Excel图表 |
2.2 中心趋势与离散程度
summary(data$sat1)
sd(data$sat1)
2.3 可视化示例(R绘图)
library(ggplot2)
ggplot(data, aes(x=gender)) + geom_bar(fill="steelblue") + theme_minimal()
三、信度与效度分析:量表是否可靠?
3.1 信度分析(Cronbach’s α)
用于检验题项内部一致性,常用于李克特量表的多个维度。
library(psych)
alpha(data[, c("sat1", "sat2", "sat3")])
标准:
- α > 0.8:极好
- 0.7 < α < 0.8:良好
- < 0.7:需修正或剔除题项
3.2 效度分析(探索性因子分析)
- 检验题项聚合成维度的合理性
- 判断变量加载因子是否集中
library(psych)
factor <- fa(data[, 4:10], nfactors = 3, rotate = "varimax")
print(factor$loadings)
四、相关分析与显著性检验:变量是否相关?
4.1 皮尔森相关分析(适用于连续变量)
cor.test(data$sat1, data$leave1)
输出包括相关系数r值与p值,判断是否显著(p < 0.05)。
4.2 可视化展示
library(ggcorrplot)
corr_matrix <- cor(data[, c("sat1", "sat2", "leave1")])
ggcorrplot(corr_matrix, lab = TRUE)
五、回归分析:验证影响路径
5.1 多元线性回归(解释因变量)
model <- lm(leave1 ~ sat1 + sat2 + age + gender, data = data)
summary(model)
重点关注:
- 回归系数(估计值)
- 显著性水平(p值)
- R²值(模型解释力)
5.2 中介效应检验(进阶)
使用PROCESS宏或lavaan包:
library(lavaan)
model <- ' leave1 ~ b1*support + b2*sat
support ~ a1*sat '
fit <- sem(model, data = data)
summary(fit, fit.measures = TRUE)
六、可视化分析:让数据“说话”
6.1 常用图表类型匹配
| 图表类型 | 适用数据 | 工具建议 |
|---|---|---|
| 条形图 | 类别分布 | ggplot2/barplot |
| 散点图 | 两变量关系 | ggplot2/scatter |
| 箱线图 | 离群值检测 | ggplot2/boxplot |
| 回归图 | 拟合效果 | ggplot2 + geom_smooth() |
6.2 图表设计建议
- 所有图表需编号与标题(如“图1 员工满意度分布”)
- 坐标轴需标明变量名与单位
- 保持图形风格一致,避免颜色杂乱
七、结果解读与撰写建议
7.1 结果撰写的逻辑顺序
描述统计 → 信度效度 → 相关分析 → 回归分析
7.2 示例段落撰写参考
“本研究使用多元线性回归模型检验工作满意度对员工离职意愿的影响,结果显示,满意度对离职意愿具有显著负向影响(β = -0.43,p < 0.01),支持H1假设。”
“控制年龄与性别变量后,满意度的解释力依然显著(R²=0.37),说明模型具有较强的解释力。”
八、结语:数据分析的底层逻辑是“思维清晰”
数据分析不是纯技术过程,而是从研究逻辑出发的“思想演绎”过程。优秀的管理学论文往往不是使用了多少高级模型,而是是否清晰地回应了研究问题,是否合理地支持了研究假设。分析方法要“够用不滥”,图表呈现要“直观不炫技”,结论解释要“紧扣假设而不夸张”。
掌握一套数据分析的结构流程,是迈向严谨研究的重要一步,也是在论文写作中展示“思维力”的关键所在。
下一篇:如何撰写结论、建议与论文格式完整稿
✅ 本博客写作行动建议
完成问卷回收后,不要急于“跑模型”,而应按以下建议依次推进,确保数据分析的科学性、完整性与逻辑清晰:
1. 建立“数据分析任务清单表”
用Excel或Notion列出你计划进行的每一步分析,包括:
| 分析模块 | 操作内容 | 工具 | 是否完成 |
|---|---|---|---|
| 数据清洗 | 删除无效问卷、变量命名、反向题处理 | R/Excel | ✅/❌ |
| 描述性统计 | 性别/年龄/学历分布、变量均值与标准差 | R/SPSS | ✅/❌ |
| 信度分析 | Cronbach α 值计算与维度审查 | R(psych包) | ✅/❌ |
| 相关性检验 | Pearson相关系数与显著性检验 | R | ✅/❌ |
| 回归分析 | 回归系数、R²与p值输出 | R | ✅/❌ |
| 可视化输出 | 条形图、散点图、回归图、热力图 | ggplot2 | ✅/❌ |
→ 提前明确这些步骤,有助于你对整体分析过程心中有数,也便于后续写作时“顺图成章”。
2. 输出至少3张论文可用的图表
每位读者可尝试输出如下图表:
- 图1:样本基本特征分布图(如性别、学历条形图)
- 图2:主要变量相关矩阵热力图
- 图3:回归拟合线散点图或中介路径图(可选)
请为图表命名(图1/图2/图3)并附标题与简要说明,以便直接插入论文正文或附录。
3. 使用标准句式撰写结果段落
尝试使用如下标准结构,完成你的实证结果描述段:
“通过Pearson相关分析发现,变量X与Y之间存在显著正相关(r = 0.48,p < 0.01),初步支持H1假设。”
“进一步采用多元线性回归检验模型,X变量对Y变量影响显著(β = 0.32,p < 0.05),控制性别与年龄后模型解释力达到R² = 0.41。”
→ 标准化句式能提升论文表达的专业性,也有助于你快速聚焦分析核心。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号