基于深度学习的单目深度估计综述
注: 研究方向为depth estimation,欢迎同一个方向的加入QQ群(602708168)交流。
1. 论文简介
论文题目:Deep Learning-Based Monocular Depth Estimation Methods—A State-of-the-Art Review
Paper地址:https://www.mdpi.com/1424-8220/20/8/2272
2. Abstract
本综述基于深度学习方法展开,分别包括了数据集、SOTA方法。以及未来研究导向。

3. Introduction
单目深度估计在机器人技术、场景理解、3D重建和医学成像方面具有潜在的应用;
目前仍然具有挑战性,因为从单一图像中没有可靠的线索来感知深度;
因为单一图像缺少时间信息和立体对应;
经典的深度估计方法严重依赖于多视图几何,如立体图像;
这些方法需要校准和校准程序,这对于多摄像头或多传感器深度测量系统很重要;
多视角方法利用视觉线索和不同的摄像机参数获取深度信息。

多目深度估计具有计算复杂度高,所需存储大的问题。

深度学习技术促进了depth estimation的发展,并提升了depth estimation的性能。


4. An Overview of Monocular Depth Estimation
深度估计的概念是指利用摄像机捕捉到的二维信息来保存场景的三维信息的过程;
单目解决方案往往只使用一张图像就能实现这一目标;
单目估计方案降低了时间复杂度,能取代现有设备和方法;
市场上depth estimation设备不足例子:
Kinect等传感器通常用于消费设备;
这些类型的传感器被归类为飞行时间( Time-of-Flight,ToF),其中深度信息是通过计算光线从光源到物体并返回到传感器所需的时间来获得的;
ToF传感器更适合于室内环境和近距离(< 2m)深度传感。
另一方面,基于激光的扫描仪(LiDAR)通常用于室外环境的3D测量;
激光雷达传感器的主要优点是高分辨率、精度、低光性能和速度;
然而,激光雷达是昂贵的设备,需要大量的电力资源,这使得它们不适合消费产品。

SOTA方法具有高性能,低时间消耗;

4.1 Problem Representation
输入为一幅二维的RGB图像I,经过一个CNN(监督、半监督、无监督),输出深度图D。

4.2 Traditional Methods for Depth Estimation
传统的depth estimation依赖于对场景空间和时间观察的假设(例如,立体或多视图,来自运动的结构),有两类:主动和被动;
主动方法通过与物体和环境的交互来计算场景的深度:
- 基于光照的depth estimation (light-based),它使用主动光照明来估计到不同物体的距离;
- 超声和TOF(Ultrasound and Time-of-Fight),已知速度与声波到达图像感知器(Sensors)的时间计算距离;
被动方法利用捕获图像的光学特征;这些方法包括利用计算图像提取深度信息过程:
多目depth estimation(multi-view),如立体匹配(stereo match);
单目深度估计(monocular depth estimation);
总的来说,传统depth estimation主要聚焦在多视野几何。


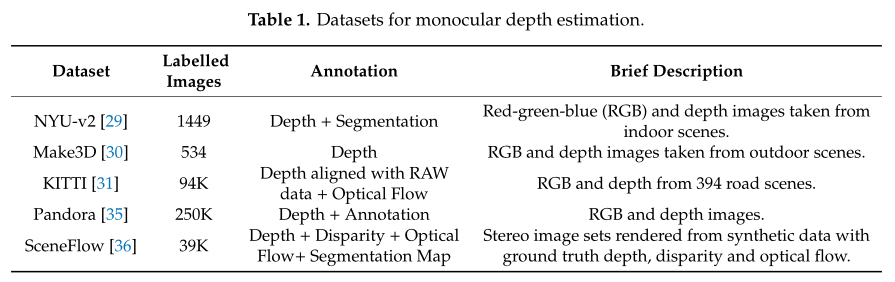
4.2 Datasets for Depth Estimation
深度估计数据集:NYU-v2,Make3D,KITTI,Pandora,SceneFlow。

5. Deep Learning and Monocular Depth Estimation
现有的深度估计根据训练策略可以划分为supervised,semi-supervised,Self-supervised。
![]()


5.1 Supervised methods
监督方法的具体介绍,细节看原文。




5.2 Self-supervised methods
自监督方法的具体介绍,细节看原文。
![]()



5.3 Semi-supervised methods
半监督方法的具体介绍,细节看原文。

6. Evaluation Matrices and Criteria
depth estimation的指标有:
绝对相对差(AbsRel),均方根误差(RMSE), RMSE (log)和平方相对误差(SqRel)。

对比方法的一些细节:输入输出尺寸,模型大小。

Table 4展示了性能对比结果,DeepV2D整体上性能最好。

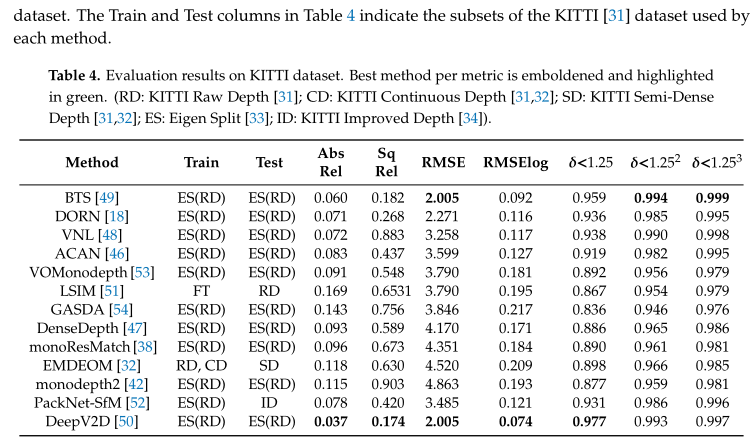
Table5展示了在NYU-V2数据集上的性能对比,DeepV2D仍然取得最好的结果。
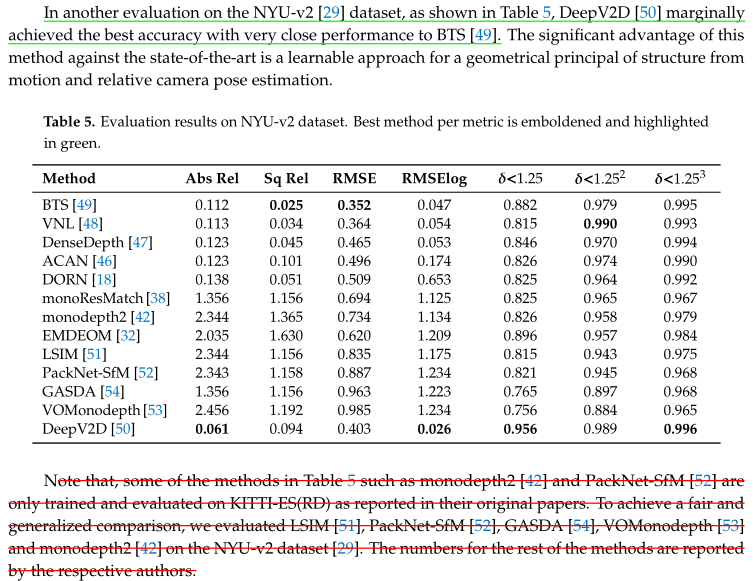
Table 6展示了各个方法的平均计算时间。
![]()

部分方法的主观结果呈现在Figure 1中。

7. Future Research Directions
- 未来研究导向:
- 降低模型复杂的问题
- 提升性能
- 实时应用
- 更大可用的数据集


8. 总结
我比较喜欢本Survey的Introduction和An overview of monocular depth estimation两部分;
第一部分提到一些传统方法的问题;
第二部分也说明了一些之前方法的不足,另外提供了数据集介绍;
对于之后的几个小节,个人感觉可读性比较少,对比的方法还是略微偏少。
9. 结语
努力去爱周围的每一个人,付出,不一定有收获,但是不付出就一定没有收获! 给街头卖艺的人零钱,不和深夜还在摆摊的小贩讨价还价。愿我的博客对你有所帮助(*^▽^*)(*^▽^*)!
如果客官喜欢小生的园子,记得关注小生哟,小生会持续更新(#^.^#)(#^.^#)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号