
KingbaseES数据库瓶颈排查实战指南:从实例到语句的全维度解析
在高并发、海量数据的业务场景下,数据库性能直接决定了应用系统的响应速度和稳定性,而瓶颈排查则是性能调优的核心前提——只有精准定位问题根源,才能避免盲目调参、优化无效的内耗。KingbaseES作为国产数据库中的优秀代表,在政务、金融、企业级应用中广泛部署,其瓶颈排查有一套标准化、可落地的方法论,核心可分为「实例级别」和「语句级别」两个层次,覆盖从整体到局部的全场景排查需求。

本文将基于KingbaseES的性能排查特性,结合实操命令、工具使用和典型场景案例,详细拆解每一种排查手段的使用方法、参数配置和结果分析,帮助技术从业者快速掌握从整体健康度诊断到单条SQL优化的全流程技巧,真正实现“排查有方向、优化有依据”。
一、实例级别排查:搞定数据库整体性能瓶颈
实例级别排查的核心目标是分析数据库实例的整体健康状况,判断是否存在系统负载过高、IO瓶颈、内存不足、连接异常等全局性问题,适用于压测场景优化、上线前全量调优、业务整体响应缓慢等场景——比如当用户反馈“整个系统卡顿,所有接口响应都超过3秒”时,优先从实例级别入手,排除全局性问题后,再深入局部语句。
KingbaseES提供了KWR、KSH、KDDM、KWR DIFF四大核心工具,搭配系统视图补充分析,形成了完整的实例级排查体系,每一种工具都有其专属场景和优势,无需重复使用,可根据问题场景精准选择。
1.1 KWR报告:实例健康度的“全景体检报告”
KWR(Kingbase Workload Repository)报告是实例级别排查的首选工具,相当于给数据库做了一次“全景体检”,能够全面采集系统负载、等待时间、IO使用、内存消耗、Top SQL等核心指标,通过对比不同时间点的快照数据,清晰呈现数据库的性能变化趋势,是判断整体健康状况的最直观手段。
不同于简单的指标查询,KWR报告能够将分散的性能数据进行汇总分析,自动识别高消耗资源的操作,帮助我们快速锁定“哪些操作占用了最多CPU”“IO瓶颈出在哪里”“哪些SQL是性能拖油瓶”,为后续优化提供明确方向。需要注意的是,KWR依赖sys_kwr扩展,且需要提前配置相关参数,确保数据采集的完整性。
KWR的使用分为「参数配置→生成快照→生成报告」三步,所有操作均无需重启数据库,修改参数后reload即可生效,降低了线上环境的使用风险。
第一步:启用sys_kwr扩展并配置参数
-- 查看已安装扩展,确认sys_kwr是否已启用
\dx
-- 安装sys_kwr扩展(若未安装)
Create extension sys_kwr;
-- 配置核心参数(修改kingbase.conf后执行reload)
track_sql = on -- 开启SQL跟踪,必配
track_instance = on -- KWR 1.3版本新增,跟踪实例整体状态
track_wait_timing = on -- 跟踪等待事件时间,默认开启
track_counts = on -- 跟踪统计信息,默认开启
track_io_timing = on -- 跟踪IO操作时间,必配
track_functions = 'all' -- 跟踪所有函数执行,可选
sys_stat_statements.track = 'top' -- 跟踪Top SQL,与KWR联动
-- 执行参数重载,无需重启数据库
select sys_reload_conf();
第二步:生成快照(快照是KWR报告的核心数据来源,需在关键时间点生成)
-- 生成第一个快照(比如业务低峰期,作为基准)
SELECT * FROM perf.create_snapshot(); -- 获得快照1(快照ID自动递增)
-- 执行一些业务操作(或等待业务运行一段时间,比如10分钟)
CREATE TABLE IF NOT EXISTS t1(id int); -- 示例:创建测试表
SELECT count(*) FROM t1; -- 示例:执行简单查询
-- 生成第二个快照(比如业务高峰期,或出现性能问题时)
SELECT * FROM perf.create_snapshot(); -- 获得快照2
第三步:生成KWR报告(支持TEXT和HTML两种格式,HTML格式更直观,推荐线上使用)
-- 生成TEXT版本报告(适合命令行快速查看)
SELECT * FROM perf.kwr_report(1,2); -- 1为起始快照ID,2为结束快照ID
-- 生成HTML版本报告(适合详细分析,带图表和格式化展示)
SELECT * FROM perf.kwr_report(1,2, 'html');
-- 补充:报告自动保存路径——DATA目录下的sys_log子目录,可直接下载查看
很多人生成KWR报告后无从下手,其实重点关注3个部分即可:
- 系统负载概况:查看数据库整体CPU、内存、IO使用率,判断是否存在资源耗尽的情况;
- 等待事件分析:重点关注“等待时间占比最高”的事件,比如IO等待过高,说明存在磁盘读写瓶颈;锁等待过高,说明存在事务阻塞;
- Top SQL列表:定位执行时间最长、消耗资源最多的SQL语句,这些语句往往是实例性能的“拖油瓶”,后续可重点优化。
1.2 KSH:业务卡顿瞬间的“高清抓拍器”
如果说KWR是“定期体检”,那么KSH(Kingbase Session History)就是“应急抓拍”——当业务出现突发卡顿、响应缓慢,但KWR报告无法捕捉到瞬间的性能波动时,KSH就能发挥作用。它以每秒1次的频率采样会话和数据,将采集到的信息存入内存的Ringbuf队列,采集频率远高于KWR,能够精准捕捉到突发性能问题的细节。
需要注意的是,KSH采集频率高、产生的数据量大,对系统资源有一定消耗,因此不建议长期开启,仅在业务出现卡顿的时间段临时开启,采集完成后立即关闭,避免影响数据库正常运行。此外,旧版本KingbaseES中KSH是独立扩展,新版本(如V8R6B24及以上)已集成到sys_kwr扩展中,无需单独安装,简化了使用流程。
-- 1. 确保sys_kwr扩展已启用(若未启用,执行Create extension sys_kwr;)
-- 2. 开启KSH采集(无需重启,reload即可生效)
set sys_kwr.collect_ksh = on;
select sys_reload_conf();
-- 3. 查看采集的数据(内存中实时数据和数据库历史数据分开查看)
-- 查看内存中Ringbuf的实时数据(最新采集的会话信息)
SELECT * FROM perf.session_history;
-- 查看数据库中保存的历史数据(已落盘的采样数据)
SELECT * FROM perf.ksh_history;
-- 4. 生成KSH报告,分析卡顿原因
SELECT perf.ksh_report(start_ts, duration, slot_width, write_to_file);
-- 参数说明:start_ts(采集开始时间)、duration(采集时长)、slot_width(采样间隔)、write_to_file(是否写入文件)
-- 5. 业务恢复后,立即关闭KSH采集,降低资源消耗
set sys_kwr.collect_ksh = off;
select sys_reload_conf();
1.3 KDDM:性能问题的“智能诊断医生”
对于经验不足的技术从业者来说,最头疼的不是采集性能数据,而是分析数据、找到优化方向——KWR和KSH能给出数据,但需要人工判断优化方案,而KDDM(Kingbase Diagnostic and Debugging Manager)则完美解决了这个问题,它相当于一个“智能诊断医生”。
KDDM基于KWR快照采集的性能指标和数据库时间模型(DB Time),自动分析等待事件、IO、网络、内存和SQL执行时间等问题,直接给出针对性的优化建议,无需人工深入分析数据,极大提升了排查效率。其核心优势在于“诊断+建议”一体化,尤其适合新手使用,同时也能为资深工程师提供优化参考。
-- 1. 启用sys_kwr扩展(KDDM依赖KWR快照数据)
Create extension sys_kwr;
-- 2. 生成两个快照(与KWR快照生成方式一致,覆盖问题时间段)
SELECT * FROM perf.create_snapshot(); -- 快照1(基准)
INSERT INTO t1 SELECT generate_series(1, 1000000); -- 模拟业务操作(大批量插入)
SELECT * FROM perf.create_snapshot(); -- 快照2(问题时段)
-- 3. 生成KDDM诊断报告(TEXT格式)
SELECT * FROM perf.kddm_report(1,2); -- 1为起始快照ID,2为结束快照ID
-- 4. 生成报告到指定文件(方便保存和分享,推荐使用)
SELECT * FROM perf.kddm_report_to_file(1, 2, '/home/test/kddm_1_2.txt');
-- 5. 生成指定SQL的诊断报告(针对性分析某条异常SQL)
SELECT * FROM perf.kddm_sql_report(1, 2, 5473583404117387630); -- 最后一个参数为SQL ID
示例优化建议:KDDM报告中可能会出现“建议调整work_mem参数至128MB,以减少磁盘排序”“建议为t1表的id字段创建索引,避免全表扫描”等明确提示,直接按照建议调整即可,无需再反复测试参数。
1.4 KWR DIFF:性能变化的“差异对比镜”
在数据库运维过程中,我们经常会遇到这样的场景:参数调整后,性能是否有提升?业务高峰期和低谷期的性能差异根源是什么?此时,KWR DIFF报告就能发挥作用,它相当于一个“差异对比镜”,通过分析两个KWR报告之间的差异,精准定位性能变化的原因,验证优化效果。
KWR DIFF的核心是“对比两个时间段的KWR数据”,需要生成4个快照(两个KWR报告各需2个快照),通过对比两个报告的指标变化,比如CPU使用率下降了多少、Top SQL执行时间缩短了多久、等待事件占比变化等,判断优化操作是否有效,或找到性能退化的根源。
-- 1. 启用sys_kwr扩展
Create extension sys_kwr;
-- 2. 生成4个快照(两个KWR报告,每个报告2个快照)
-- 第一个KWR报告(比如优化前,快照1-2)
SELECT * FROM perf.create_snapshot(); -- 快照1(优化前基准)
CREATE TABLE t1(a int);
INSERT INTO t1 SELECT generate_series(1, 1000000);
SELECT * FROM perf.create_snapshot(); -- 快照2(优化前问题时段)
-- 第二个KWR报告(比如优化后,快照3-4)
INSERT INTO t1 SELECT generate_series(1, 1000000); -- 模拟优化后的业务操作
SELECT * FROM perf.create_snapshot(); -- 快照3(优化后基准)
INSERT INTO t1 SELECT generate_series(1, 1000000);
SELECT * FROM perf.create_snapshot(); -- 快照4(优化后业务时段)
-- 3. 生成KWR DIFF报告(保存为HTML格式,方便对比查看)
SELECT * FROM perf.kwr_diff_report_to_file(1, 2, 3, 4,'/home/test/kwr_diff_rpt_00.html');
参数解读:
- snap_1:第一个KWR报告的起始快照ID(优化前基准);
- snap_2:第一个KWR报告的结束快照ID(优化前问题时段);
- snap_3:第二个KWR报告的起始快照ID(优化后基准);
- snap_4:第二个KWR报告的结束快照ID(优化后业务时段)。
1.5 Kbbadger:日志分析的“高效工具”
当数据库出现异常,但上述工具无法定位问题时,日志分析就成为了最后的突破口——KingbaseES的日志文件中记录了所有SQL执行、连接、错误等信息,而Kbbadger则是一款专门用于分析KingbaseES日志的工具,能够高效解析大型日志文件,自动识别日志格式,生成可缩放的图表,突出显示异常SQL,极大提升日志分析效率。
Kbbadger支持解析syslog、stderr、csvlog、jsonlog等多种日志格式,能够过滤指定时间段、指定类型的日志,排除无效信息,精准定位异常操作,尤其适合排查“偶发性能问题”“日志量过大无法手动分析”的场景。
使用Kbbadger前,需先配置日志参数,确保日志信息完整且可解析:
-- 1. 配置日志参数(修改kingbase.conf后reload)
log_min_duration_statement = 0 -- 记录所有SQL语句的执行时间,必配(需reload)
log_statement = off -- 禁止开启,默认关闭(开启后日志量过大,影响解析)
lc_messages='en_US.UTF-8' -- 日志语言必须设为英文,否则Kbbadger无法解析
-- 2. 重载参数
select sys_reload_conf();
常用Kbbadger命令(覆盖大部分日志分析场景):
# 1. 解析单个日志文件
kbbadger /var/log/kingbase.log
# 2. 解析多个日志文件(包括压缩文件)
kbbadger /var/log/kingbase.log.2.gz /var/log/kingbase.log.1.gz /var/log/kingbase.log
# 3. 解析指定时间段的日志(-b开始时间,-e结束时间)
kbbadger -b "2024-06-25 10:56:11" -e "2024-06-25 10:59:11" /var/log/kingbase.log
# 4. 排除指定类型的SQL(比如排除COPY、COMMIT语句,聚焦查询语句)
kbbadger --exclude-query="^(COPY|COMMIT)" /var/log/kingbase.log
# 5. 从标准输入解析日志(适合管道操作)
cat /var/log/kingbase.log | kbbadger -
# 6. 多CPU并行解析(加快大型日志文件解析速度,-j后接CPU核心数)
kbbadger -j 8 /sys_log/kingbase-10.1-main.log
# 7. 解析指定前缀格式的日志(适配不同的日志配置)
kbbadger --prefix '%t [%p]: user=%u,db=%d,client=%h' /sys_log/kingbase-2024-08-21*
1.6 核心系统视图:补充排查的“关键抓手”
除了上述四大工具,KingbaseES还提供了多个系统视图,用于补充排查实例级问题,尤其是在定位具体资源消耗、连接异常、锁阻塞等场景时,视图查询更加便捷、精准,常用视图如下(附核心查询场景):
1. sys_stat_statements 视图:SQL执行情况的“明细台账”
该视图是排查SQL层面资源消耗的核心视图,能够详细记录所有SQL语句的执行情况,当KWR报告定位到Top SQL后,可通过该视图查看具体明细,为SQL优化提供依据。
可查询核心内容:
- 语句内容:具体的SQL语句文本;
- 执行统计:执行次数、解析次数、解析时间;
- 内存使用:shared_buffer使用情况(磁盘读/缓存命中);
- 其他内存:temp_buffer、work_mem、maintenance_mem的命中情况(通过local字段排查)。
示例查询:查看执行次数最多、消耗时间最长的前10条SQL
SELECT queryid, query, calls, total_time, mean_time
FROM sys_stat_statements
ORDER BY total_time DESC
LIMIT 10;
2. sys_stat_activity 视图:数据库连接的“实时监控台”
当业务出现“连接超时”“无法连接数据库”“会话阻塞”等问题时,可通过该视图查看当前数据库的所有连接信息,定位异常连接。
可查询核心内容:
- 连接状态:是否有等待事件、锁信息;
- 连接明细:连接方式、客户端地址;
- 时间信息:连接开始时间、事务开始时间、查询开始时间;
- 执行信息:当前正在执行的查询语句。
示例查询:查看所有处于等待状态的连接
SELECT pid, usename, client_addr, wait_event, query
FROM sys_stat_activity
WHERE wait_event IS NOT NULL;
3. IO分析视图:sys_stdio_user_tables + sys_stdio_user_indexes
这两个视图用于排查IO瓶颈,能够详细记录表和索引的读写情况,判断IO压力是否来自表数据读取或索引读取。
可查询核心内容:
- 表数据:读盘次数、内存命中次数;
- 索引数据:读盘次数、内存命中次数;
- Toast表:读盘次数、内存命中次数(Toast表用于存储大字段数据,易被忽略)。
4. sys_locks 视图:锁信息的“明细清单”
当数据库出现“事务阻塞”“死锁”等问题时,可通过该视图查看所有锁的持有和等待情况,定位阻塞源,快速解锁。
示例查询:查看所有锁等待情况,定位阻塞进程
SELECT locktype, database, relation, pid, mode, granted
FROM sys_locks
WHERE granted = false;
二、语句级别排查:精准优化单条SQL的“瓶颈点”
当实例级别排查排除了全局性问题,或定位到具体的高消耗SQL后,就需要进入语句级别排查——聚焦单条SQL语句(或批量跑批语句),分析其执行过程,定位具体的性能瓶颈,比如全表扫描、磁盘排序、索引失效等,这是性能优化的“最后一公里”。
语句级别排查的核心工具是「执行计划」,KingbaseES中通过explain命令查看执行计划,这是最常用、最直接的SQL优化手段——执行计划能够清晰呈现SQL语句的执行路径,比如“如何扫描表”“如何连接表”“是否排序”“是否使用索引”等,通过分析执行计划,就能快速找到SQL的性能瓶颈。
2.1 explain命令详解:看懂执行计划的“说明书”
explain命令的核心作用是“模拟SQL执行,输出执行路径和成本估算”,无需实际执行SQL(除非加上analyze选项),不会对数据库产生业务影响,可放心在生产环境使用。
命令格式与可选参数
explain [option] statement;
其中option为可选项,支持5种参数的组合使用,核心参数说明如下(重点掌握前4个):
- analyze:执行SQL并显示实际执行时间(默认false),能够对比“估算成本”和“实际成本”,精准定位偏差;
- verbose:显示附加信息(如计划树每个节点的输出字段名),默认false,适合深入分析执行细节;
- costs:显示执行计划的成本(CPU成本+IO成本),默认true,成本越高,执行效率越低;
- buffers:显示缓冲区使用信息(共享块、本地块、临时读写块),默认false,前置条件是开启analyze;
- format:指定输出格式(TEXT/XML/JSON/YAML),默认TEXT,JSON格式适合程序解析,TEXT格式适合人工查看。
常用命令组合(生产环境高频使用)
-- 1. 基础查看执行计划(仅估算成本,不执行SQL)
explain SELECT count(*) FROM t1 WHERE id > 1000;
-- 2. 查看实际执行情况(执行SQL,显示实际时间和缓冲区使用,推荐使用)
explain analyze buffers SELECT count(*) FROM t1 WHERE id > 1000;
-- 3. 查看详细执行细节(附加字段信息,适合复杂SQL分析)
explain verbose analyze SELECT count(*) FROM t1 WHERE id > 1000;
2.2 执行计划分析思路:3步找到瓶颈点
很多人看不懂执行计划,核心是没有掌握分析思路——执行计划的分析无需逐行阅读,重点遵循“找成本→找步骤→找问题”的3步思路,快速定位瓶颈。
第一步:找总体成本,判断SQL执行效率
执行计划开头通常会显示“总估算成本”(Total runtime)。这个数值越大,说明SQL运行得越慢。对于简单的查询,最好让成本保持在1000以下;而对于复杂的查询,则应尽量控制在10000以内。如果成本超过了这些范围,就需要仔细分析一下了。
第二步:找高成本步骤,定位性能瓶颈点
在执行计划里,每个步骤都会标出它自己的“成本”和到这一步为止的“总成本”。你需要特别注意那些“总成本”占大头的步骤,因为这些通常是拖慢你SQL查询速度的地方。常见的可能拖慢速度的操作有:全表扫描、磁盘上的排序操作、以及在处理大量数据时使用的嵌套循环连接等。
第三步:分析步骤细节,找到优化方向
针对高成本步骤,围绕3个核心点分析,找到优化方向:
- scan方式(扫描方式):是否使用索引扫描(Index Scan),若使用全表扫描(Seq Scan),需判断是否合理(比如表数据量极小,全表扫描比索引扫描更快则合理,否则需优化索引);
- 连接方式(多表关联场景):多表关联时,是否使用了合适的连接方式(Hash Join适合大数据量,Nested Loop适合小数据量,Merge Join适合有序数据);
- 其他操作:是否存在磁盘排序、临时表创建等耗时操作,这些操作往往是性能瓶颈的核心原因。
三、实战案例:统计信息不准确导致索引失效
现象:t1表的id字段已创建索引,但查询语句仍使用全表扫描,执行效率低下,执行计划如下:
explain analyze SELECT * FROM t1 WHERE id = 10000;
-- 执行计划关键信息:
-- Seq Scan on t1 (cost=0.00..1000.00 rows=1 width=100) (actual time=500.00..800.00 ms)
-- Filter: (id = 10000)
-- Total runtime: 800.50 ms
分析:虽然id字段已经建了索引,但查询时还是用了全表扫描。主要原因就是统计信息不准。KingbaseES的优化器会根据这些统计信息来决定要不要用索引。如果数据大量增删后没有更新统计信息,优化器就会误判数据分布情况,从而导致索引没被用上。
验证:查看执行计划中“估算行数”与“实际行数”的差异,若差异较大,说明统计信息不准确:
上述执行计划中,估算行数(rows=1)与实际行数(假设实际返回1行)差异不大,但仍未使用索引,进一步查看统计信息:
-- 查看t1表的统计信息更新时间
SELECT relname, last_analyze FROM pg_stat_user_tables WHERE relname = 't1';
若last_analyze时间较早,说明统计信息过时,需手动更新。
优化方案:更新表的统计信息,让优化器准确判断数据分布:
-- 更新t1表的统计信息
ANALYZE t1;
-- 重新查看执行计划,已使用索引扫描(Index Scan using t1_id_idx on t1)
explain analyze SELECT * FROM t1 WHERE id = 10000;
-- 优化后执行时间:5ms以内
四、总结
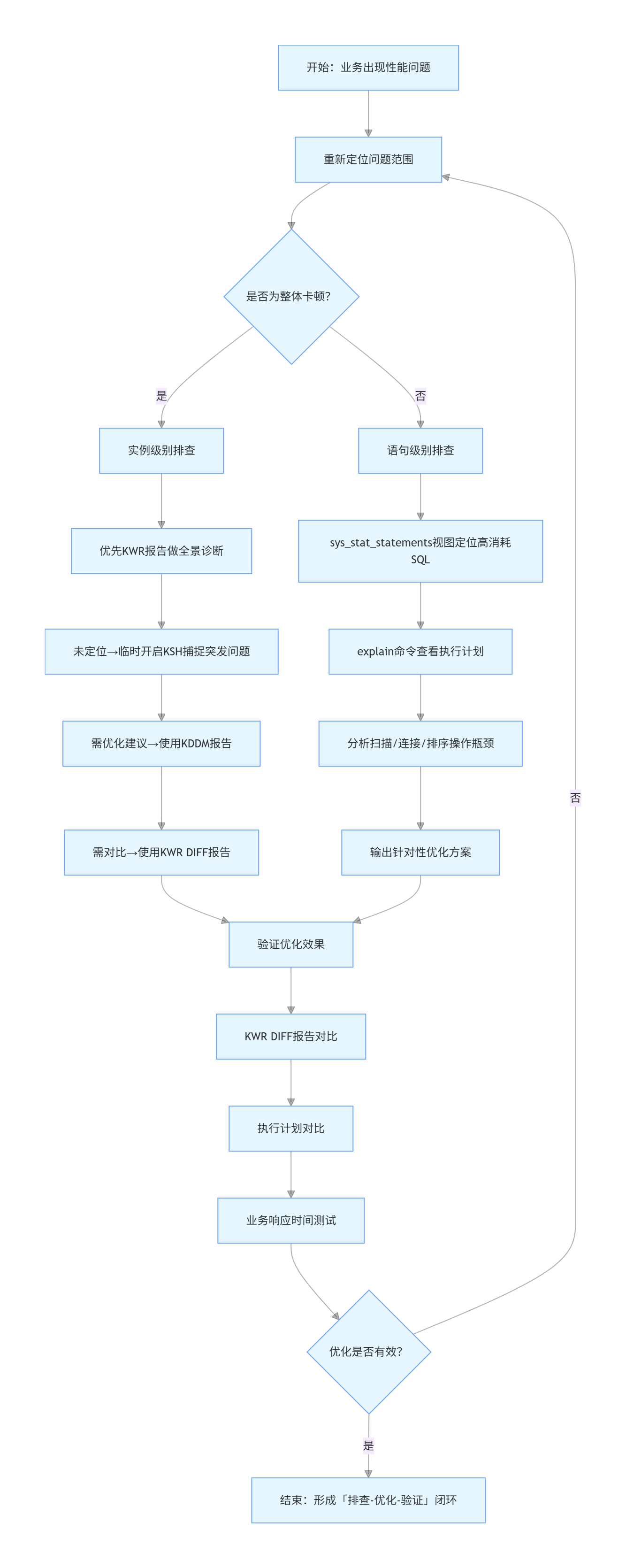
排查数据库瓶颈这事儿,对搞技术的人来说特别重要,特别是现在国产数据库用得这么广泛。要是你能搞定排查方法,那就能迅速解决性能问题,让系统更稳、用户体验更好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号