PP-OCR:实用的超轻量级OCR系统
 总结了PP-OCR论文。
总结了PP-OCR论文。
论文地址
https://ar5iv.labs.arxiv.org/html/2009.09941
PP-OCR 工作内容概述
在OCR任务中,通常需要经历如下几个阶段实现文本的识别:
- 文本检测:对于输入的图像,将包含文字的部分使用矩形框裁剪出来。
- 图像校正:受文字排版或拍摄角度的影响,上一步裁剪得到的图像通常不可以直接用于识别,需要将其矫正,使得图像中文字水平排列,无透视形变。
- 文本识别:识别图像中的文本内容。
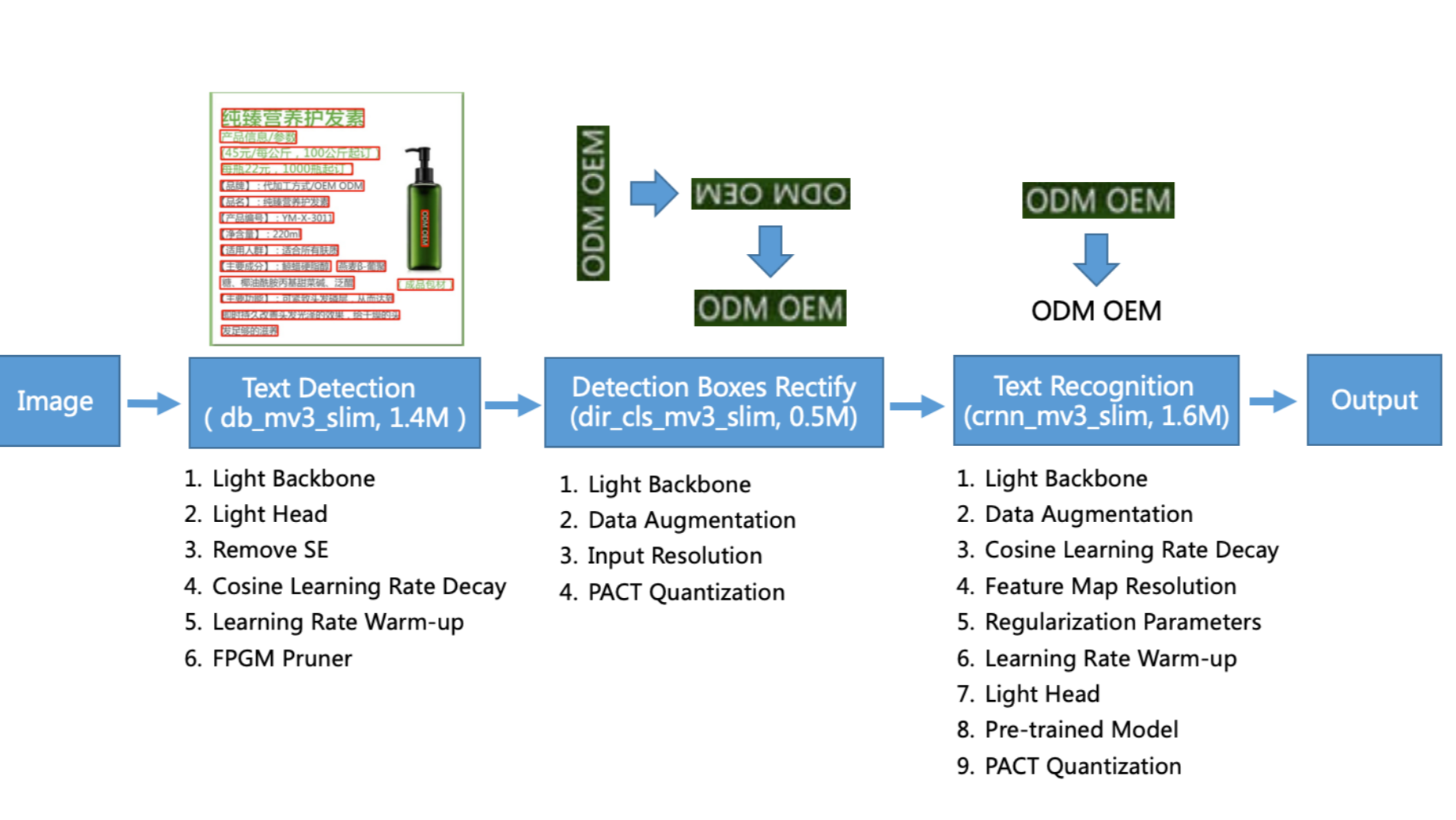
针对以上三阶段,PP-OCR 分别制定了相应的优化和改进策略,具体如下:
| 阶段 | 基础模型 | 改进策略 | 改进后模型大小 |
|---|---|---|---|
| 文本检测 | DBNet MobileNetV3_large_x0.5 |
1、轻量化Backbone 2、轻量化Head 3、移除SE模块 4、余弦学习率调整策略 5、学习率预热策略 6、FPGM模型剪枝 |
1.4M |
| 图像矫正 | MobileNetV3_small_x0.35 | 1、轻量化Backbone 2、数据增广 3、增大输入图像分辨率 4、PACT模型量化 |
0.5M |
| 文本识别 | CRNN MobileNetV3_small_x0.5 |
1、轻量化Backbone 2、数据增广 3、余弦学习率调整策略 4、特征图分辨率调整 5、模型参数正则化 6、学习率预热 7、轻量化Head 8、模型预训练 9、PATC模型量化 |
1.6M |
总体来说,飞桨团队对于OCR三个阶段的改进策略主要思路可以归纳为四方面。
模型改进:首先众多轻量化模型中,选择性能和大小合适的网络模型作为Backbone。然后结合任务适当调整模型结构,如在文本检测中移除了耗时但对精度提升不大的SE模块;在图像矫正中输入图像分辨率调整至更大以增强模型的文本方向判断能力;在文本识别中,调整了卷积核移动的步长来调整特征图的分辨率,令其学到更多的水平方向的信息。
训练方法改进:在训练过程中,通过学习率预热、余弦学习率调整策略、模型参数正则化等方法,有效控制网络参数逐步迭代至收敛状态。
模型轻量化:通过 FPGM 剪枝和 PATC 模型量化方法,在不降低模型性能的同时,尽可能减小模型参数量,以适应端侧部署。
数据增广:针对文本图像特有的属性,通过 BDA 和 TIA 等方法,对数据集进行增广,一定程度上也能增加模型的泛化能力,正所谓”见多识广”。
改进策略精读
文本检测
Backbone 轻量化
文本检测网络模型框架主要参考的是 DBNet,该网络将文本检测任务转化为图像分割问题,通过输出的概率图生成文本框。
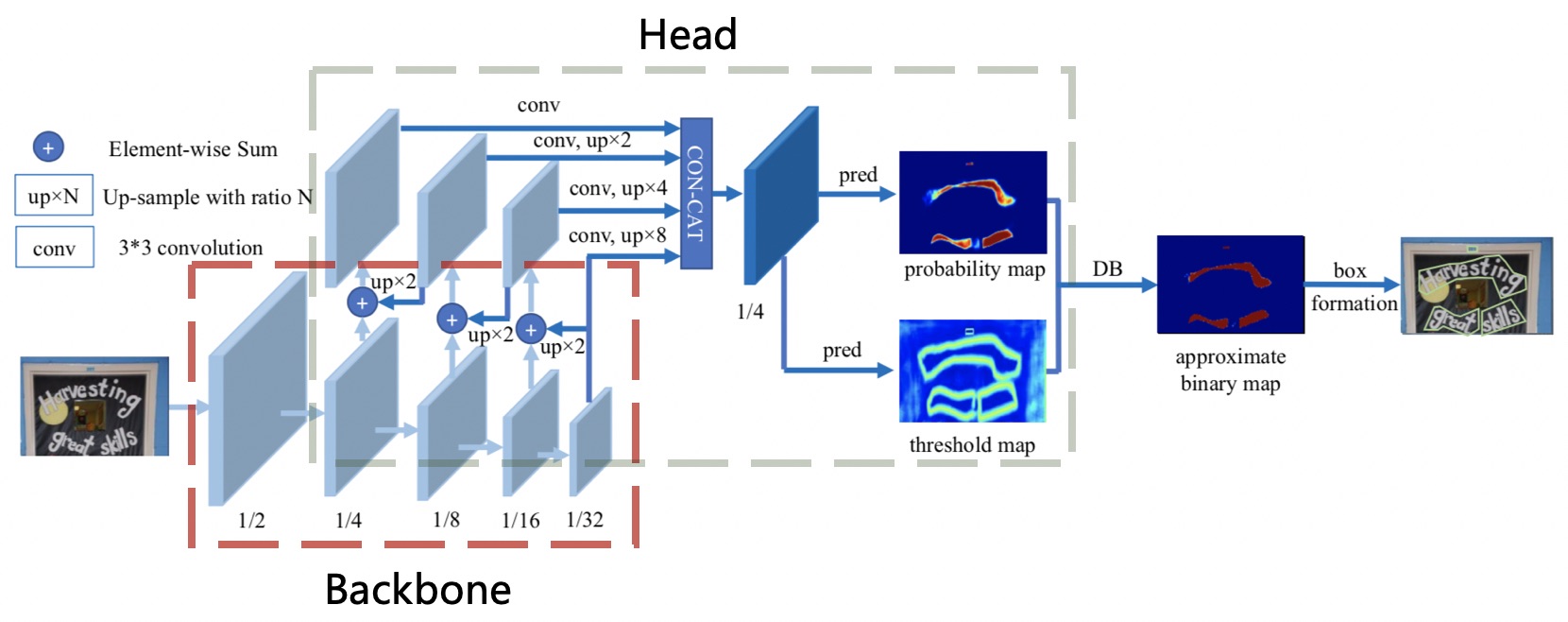
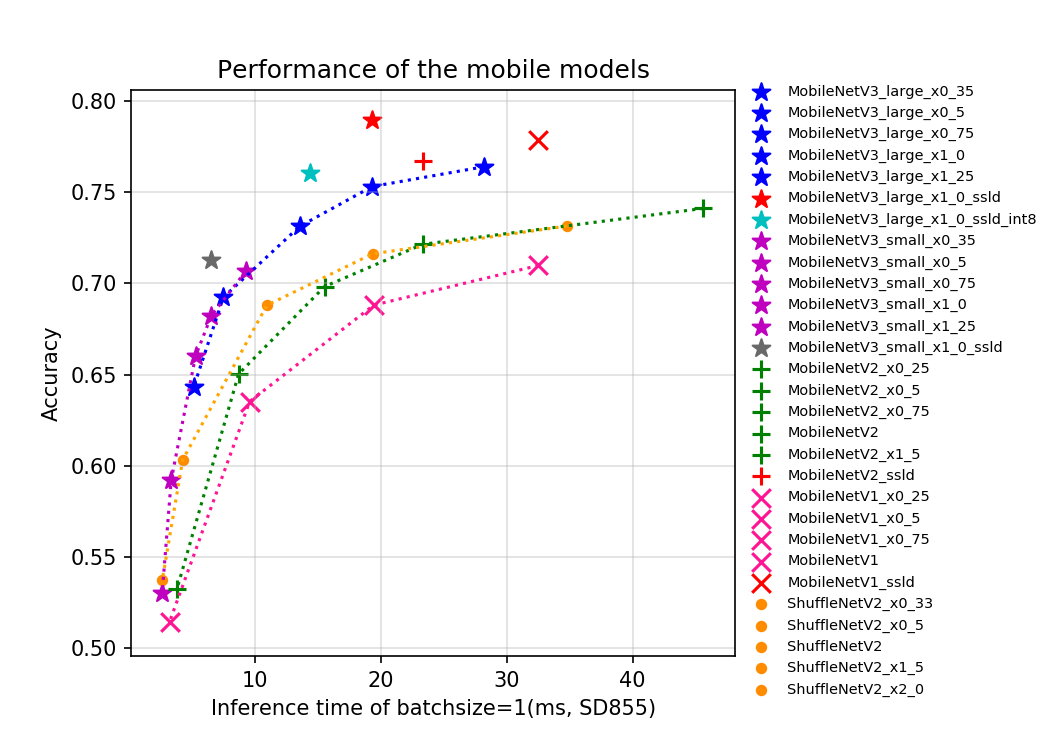
这里 Backbone 可替换成更轻量的模型,考虑MobileNetV1、MobileNetV2、MobileNetV3 和 ShuffleNetV2 等常用的轻量级网络中挑选。
| Backbone | HMean | Model Size (M) |
Inference Time (CPU,ms) |
|---|---|---|---|
| MobileNetV3_large_x1 | 0.6463 | 16 | 447 |
| MobileNetV3_large_x0.5 | 0.6127 | 7 | 406 |
| MobileNetV3_large_x0.35 | 0.5935 | 5.4 | 367 |
| MobileNetV3_small_x1 | 0.5919 | 7.5 | 380 |
对比后可基本确定,使用MobileNetV3系列比较合适,尺寸大小则需结合推理时间和HMean值来确定,很明显MobileNetV3_large_x1 不太经济,后面几个可作为备选。
Head 轻量化
DBNet的Head部分结构类似于FPN(多尺度特征金字塔),目的是希望网络能融合不同尺度的特征图,以提高对小文本区域检测的效果。侧边输出的多通道特征图将会Concat到一起,这里通过 1×1 卷积来实现通道数量的统一。在控制精度下降不大的条件下,通道数量(更多操作inner_channel)从256减少至96后,模型大小从7M下降值4.1M,
| inner_channel | Precision | Recall | HMean | Model Size (M) |
Inference Time (CPU,ms) |
|---|---|---|---|---|---|
| 256 | 0.6821 | 0.5560 | 0.6127 | 7 | 406 |
| 96 | 0.6677 | 0.5524 | 0.6046 | 4.1 | 213 |
删除SE模块
SE 是 squeeze-and-excitation 的缩写,该模块主要用于增强通道之间的交互。MobileNetV3 用到较多的SE模块,但团队发现当输入图像分辨率较大时(如640×640),该模块耗时长但精度提升却很有限,因此属于冗余设计,考虑删除。
当 SE 块从 backbone 中移除时,模型大小从 4.1M 减小到 2.5M,但精度没有影响。
| inner_channel of the head | Remove SE | Precision | Recall | HMean | Model Size (M) |
Inference Time (CPU,ms) |
|---|---|---|---|---|---|---|
| 96 | 0.6677 | 0.5524 | 0.6046 | 4.1 | 213 | |
| 96 | √ | 0.6952 | 0.5413 | 0.6087 | 2.6 | 173 |
学习率预热
学习率预热其实也是一种学习率调整策略。即在训练初期的时候,从非常小的学习率逐渐增大至目标初始学习率。然后再进行学习率衰减。学习率预热的目的是在训练的初期逐步提高学习率,从而提高训练的稳定性,防止刚开始训练时使用过大的学习率导致模型参数的剧烈变化,进而影响模型的训练效果。
| inner_channel of the head | Remove SE | Cosine Learning Rate Decay |
Learning Rate Warm-up |
Precision | Recall | HMean | Model Size (M) |
Inference Time (CPU,ms) |
|---|---|---|---|---|---|---|---|---|
| 96 | √ | 0.6952 | 0.5413 | 0.6087 | 2.6 | 173 | ||
| 96 | √ | √ | 0.7034 | 0.5404 | 0.6112 | 2.6 | 173 | |
| 96 | √ | √ | √ | 0.7349 | 0.5420 | 0.6239 | 2.6 | 173 |
FPGM 剪枝
剪枝是另一种提高神经网络模型推理效率的方法。为了避免模型剪枝导致的模型性能下降,团队使用了FPGM以查找原始模型中不重要的子网络。FPGM 使用几何中位数作为标准,卷积层中的每个滤波器被视为欧几里得空间中的一个点。然后计算这些点的几何中位数并删除具有相似值的滤波器。
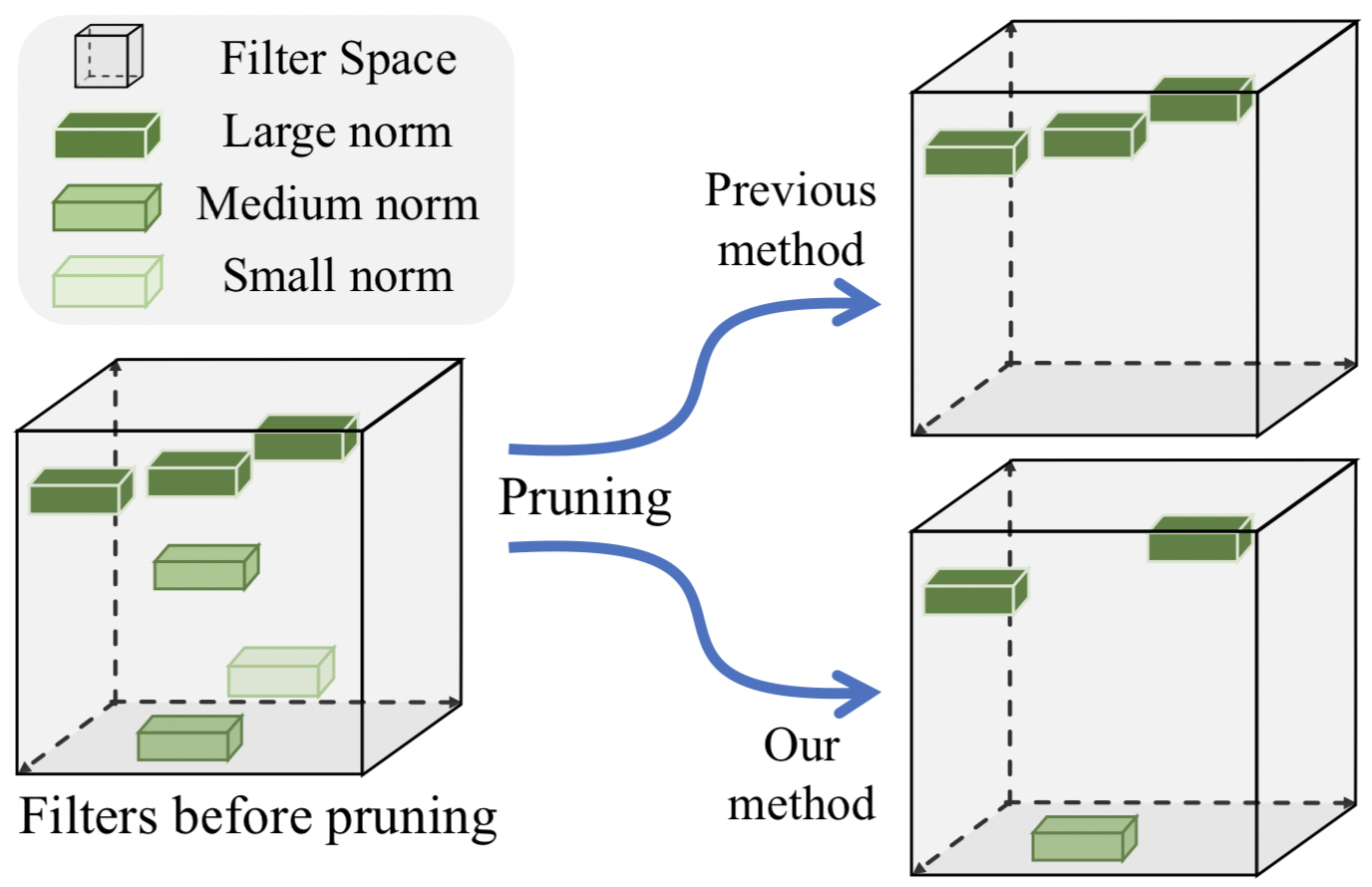
每层的压缩率对于修剪模型也很重要。均匀修剪每个层通常会导致性能显著下降。在 PP-OCR 中,根据《Pruning Filters For Efficient ConvNets》论文来剪枝。
| FPGM Pruner | HMean | Model Size (M) |
Inference Time (CPU,ms) |
|---|---|---|---|
| 0.6239 | 2.6 | 164 | |
| √ | 0.6169 | 1.4 | 133 |
图像矫正(方向分类)
在PP-OCR中,图像矫正主要是对图像中文本朝向进行分类。
Backbone 轻量化
与文本检测器相同。因为这个任务相对简单,所以我们使用 MobileNetV3_small_x0.35 来凭经验平衡准确性和效率。当使用较大的 backbone 时,准确性不会提高更多。
数据增广
对于文本图像进行旋转、透视失真、运动模糊、高斯噪声等常规基础增广方式叫做 BDA (Basic Data Augment)。对于新的增广方式,尝试了包括 AutoAugment、RandAugment、Cut、RandomErasing、HideAndSeek、GridMask、Mix,CutMix等多种方法,实验最终表明,除了 RandAugment 和 RandErasing,它们中的大多数都不适用于方向分类器训练。RandAugment 效果最佳。最终,我们将 BDA 和 RandAugment 添加到方向分类的训练图像中。
| Data Augmentation | Accuracy |
|---|---|
| NO | 0.8879 |
| BDA | 0.9134 |
| BDA+CutMix | 0.9083 |
| BDA+Mixup | 0.9104 |
| BDA+Cutout | 0.9081 |
| BDA+HideAndSeek | 0.8598 |
| BDA+GridMask | 0.9140 |
| BDA+RandomErasing | 0.9193 |
| BDA+AutoAugment | 0.9133 |
| BDA+RandAugment | 0.9212 |
增大输入图像分辨率
当标准化图像的输入分辨率增加时,准确性也会得到提高。由于方向分类器的主干很轻,适当提高分辨率不会明显增加计算时间。在前面的大多数文本识别方法中,标准化图像的高度和宽度设置为32和100。但是,在 PP-OCR 中,高度和宽度设置为48和192,以提高方向分类器的准确性。
| Input Resolution | PACT Quantization | Accuracy | Model Size (M) |
Inference Time (SD 855, ms) |
|---|---|---|---|---|
| 3×32×100 | 0.9212 | 0.85 | 3.19 | |
| 3×48×192 | 0.9403 | 0.85 | 3.21 |
PATC 量化
量化使神经网络模型具有更低的延迟、更小的体积和更低的计算功耗。目前,量化主要分为离线量化和在线量化两大类。离线量化是指使用 KL 散度和移动平均等方法来确定量化参数且不需要重新训练的定点量化方法。在线量化是在训练过程中确定量化参数,可以提供比离线量化模式更少的量化损失。
普通 PACT 方法的激活值的预处理基于 ReLU 函数。所有大于特定阈值的激活值都将被截断。但是,MobileNetV3 中的激活函数不仅是 ReLU,而且还是 hard swish。使用普通的 PACT 量化会导致更高的量化损失。因此,我们修改 activations 预处理的公式如下,以减少量化损失。
我们使用改进的 PACT 量化方法来量化方向分类器模型。此外,在 PACT 参数中添加了系数为 0.001 的 L2 正则化,以提高模型的鲁棒性。
| Input Resolution | PACT Quantization | Accuracy | Model Size (M) |
Inference Time (SD 855, ms) |
|---|---|---|---|---|
| 3×48×192 | 0.9403 | 0.85 | 3.21 | |
| 3×48×192 | √ | 0.9456 | 0.46 | 2.38 |
文本识别
文本识别的网络架构参考自 CRNN , 该网络首次将文本识别设计成端到端架构,在常规CNN后面接一个BiLSTM使得网络可以输出序列信息,再通过 CTCLoss 实现预测结果与文本标签的长度统一。
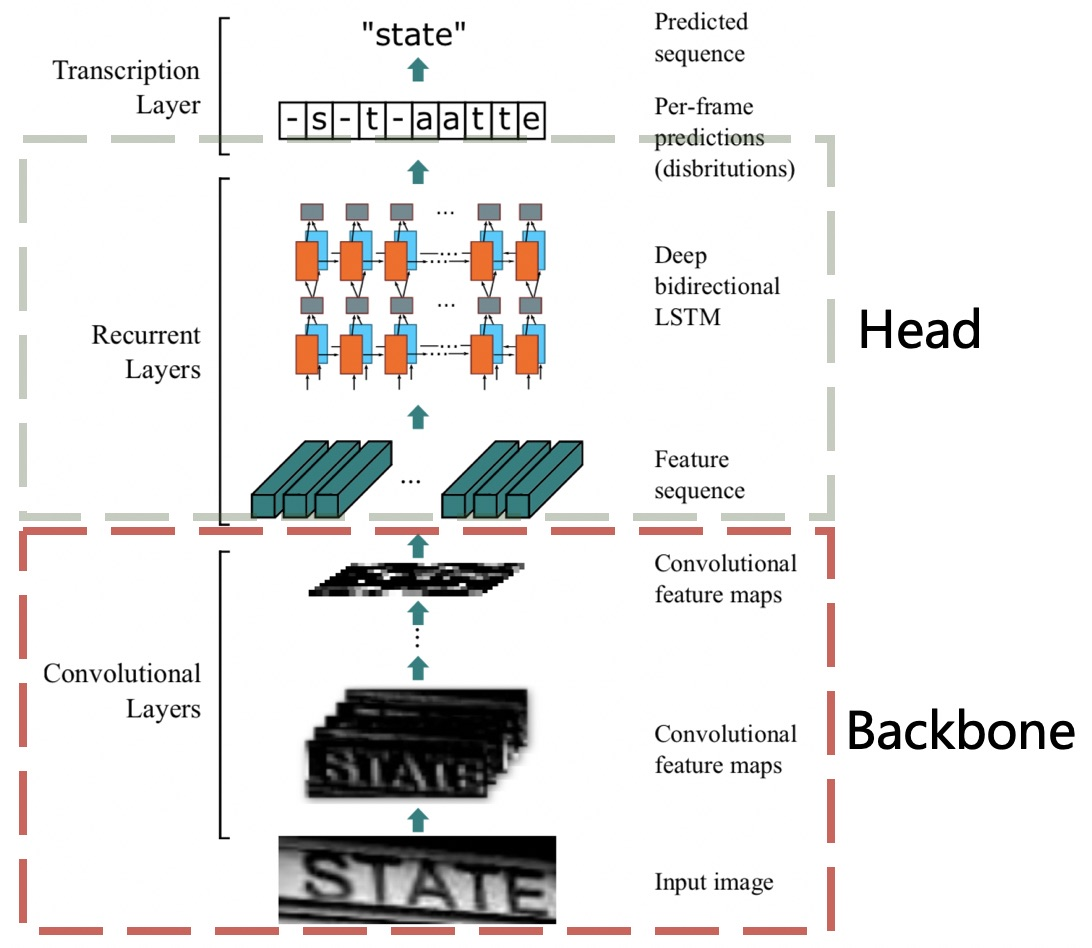
Backbone 轻量化
采用 MobileNetV3 作为文本识别器的主干,这与文本检测相同。选择 MobileNetV3_small_x0.5 是为了根据经验平衡准确性和效率。如果您对模型大小不是那么敏感,MobileNetV3_small_x1.0 也是一个不错的选择。模型尺寸仅增加了 2M,精度明显提升。
| Backbone | Accuracy | ModelSize (M) |
InferenceTime (CPU, ms) |
|---|---|---|---|
| MobileNetV3_small_x0.35 | 0.6288 | 22 | 17 |
| MobileNetV3_small_x0.5 | 0.6556 | 23 | 17.27 |
| MobileNetV3_small_x1 | 0.6933 | 28 | 19.15 |
数据增广
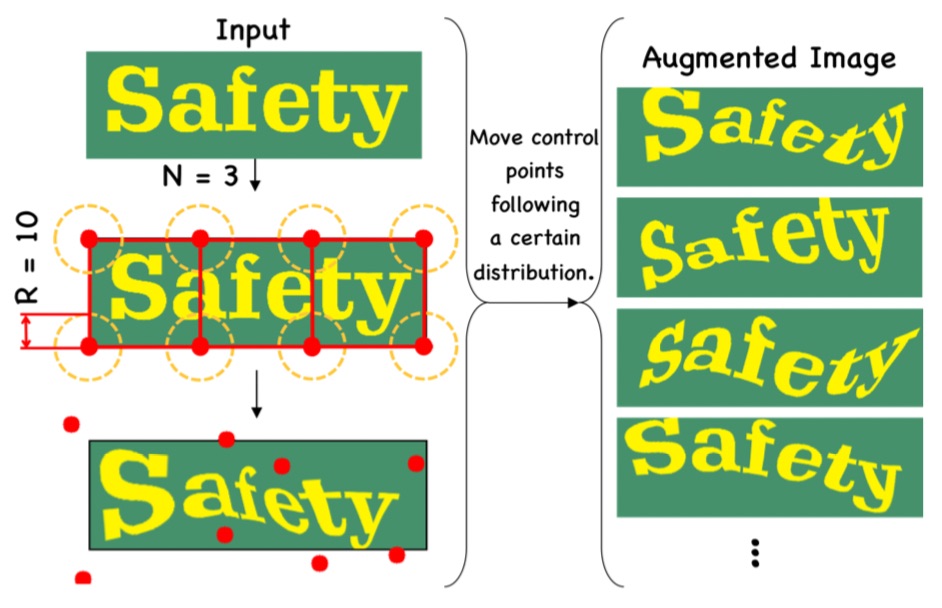
除了前面提到的经常用于文本识别的 BDA(基础数据增强)之外,TIA也是一种用于文本识别的有效数据增强方法。首先,在图像上初始化一组基准点。然后随机移动这些点,以生成具有几何变换的新图像。在 PP-OCR 中,将 BDA 和 TIA 添加到文本识别的训练图像中。
余弦学习率衰减
正如文本检测中提到的,余弦学习率衰减已成为首选的学习率降低方法。实验表明,余弦学习率衰减策略也有效地增强了模型对文本识别的能力。
特征图分辨率调整
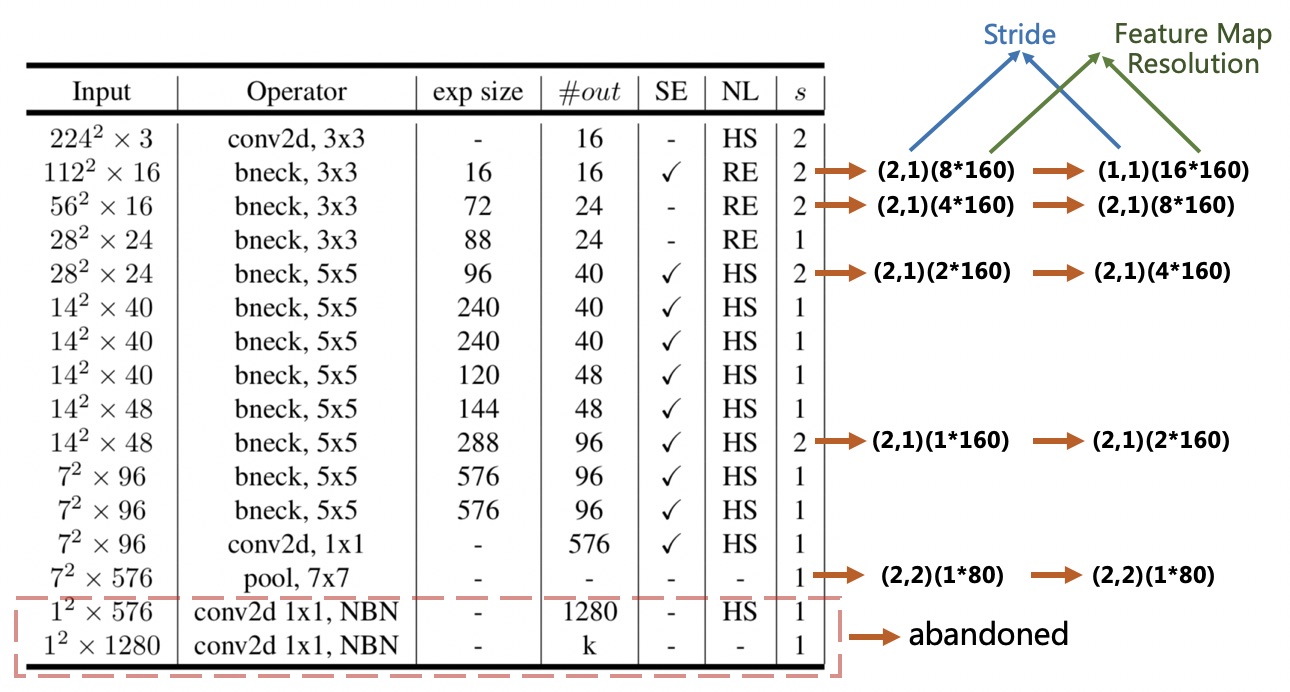
不同语言的文字其形状差异较大。为了适应多语言识别,尤其是在中文识别中,在 PP-OCR 中,CRNN 输入的高度和宽度设置为32和320,长宽比例不均衡。那么,原始 MobileNetV3 的步幅不适合文本识别,随着卷积的深入,垂直信息骤减,为了保留更多的垂直信息,我们将下采样特征图的步幅从 (2,2) 修改为 (2,1) 到 (2,1)。为了保留更多的垂直信息,我们进一步将第二个下采样特征图的步幅从 (2,1) 修改为(1,1)。因此,第二个下采样特征图的步幅s2极大地影响了整个特征图的分辨率和文本识别器的准确性。在 PP-OCR 中,s2设置为 (1,1) 以根据经验实现更好的性能。
正则化参数
过拟合是机器学习中的一个常用术语。一个简单的理解是,该模型在训练数据上表现良好,但在测试数据上表现不佳。为了避免过度拟合,已经提出了许多常规方法。其中,weight_decay是避免过拟合的广泛使用的方法之一。在最终的损失函数之后,将 L2 正则化 (L2_decay) 添加到损失函数中。在 L2 正则化的帮助下,网络的权重倾向于选择较小的值,最终整个网络中的参数趋向于 0,模型的泛化性能也相应提高。对于文本识别,L2_decay对准确性有很大影响。
学习率预热
与文本检测类似,学习率预热也有助于文本识别。对于文本识别,实验表明使用此策略也很有效。
| Strategy | DataAugmentation | Cosine LearningRate Decay | Stride | L2_decay | Learning RateWarm-up | Accuracy | Inference Time (CPU, ms) |
|---|---|---|---|---|---|---|---|
| S1 | NO | (2,1) | 0 | 0.5193 | 11.84 | ||
| S2 | BDA | (2,1) | 0 | 0.5505 | 11.84 | ||
| S3 | BDA | √ | (2,1) | 0 | 0.5652 | 11.84 | |
| S4 | BDA | √ | (1,1) | 0 | 0.6179 | 12.96 | |
| S5 | BDA | √ | (1,1) | 1e−5 | 0.6519 | 12.96 | |
| S6 | BDA | √ | (1,1) | 1e−5 | √ | 0.6581 | 12.96 |
| S7 | BDA+TIA | √ | (1,1) | 1e−5 | √ | 0.6670 | 12.96 |
Head 轻量化
全连接层用于将序列特征编码为普通的预测字符。序列特征的维度对文本识别器的模型大小有影响,尤其是对于字符超过 6000 的中文识别。同时,并不是维度越高,序列特征表示的能力就越强。在 PP-OCR 中,序列特征的维度根据经验设置为 48。
| the numberof channel | Accuracy | ModelSize (M) |
InferenceTime (CPU, ms) |
|---|---|---|---|
| 256 | 0.6556 | 23 | 17.27 |
| 96 | 0.6673 | 8 | 13.36 |
| 64 | 0.6642 | 5.6 | 12.64 |
| 48 | 0.6581 | 4.6 | 12.26 |
模型预训练
如果训练数据较少,请微调现有网络,这些网络是在 ImageNet 等大型数据集上训练的,以实现快速收敛和更高的准确性。图像分类和对象检测中的迁移学习表明,上述策略是有效的。在实际场景中,用于文本识别的数据通常是有限的。如果模型是用数千万个样本训练的,即使它们是合成的,使用上述模型也可以显著提高准确性。我们通过实验证明了这种策略的有效性。
PATC量化
采用了类似的方向分类量化方案来减小文本识别器的模型大小,除了跳过 LSTM 层。由于 LSTM 量化的复杂性,这些层目前不会被量化。
| PACTQuantization | Accuracy | ModelSize (M) |
InferenceTime (SD 855, ms) |
|---|---|---|---|
| 0.6581 | 4.6 | 12 | |
| √ | 0.674 | 1.5 | 11 |
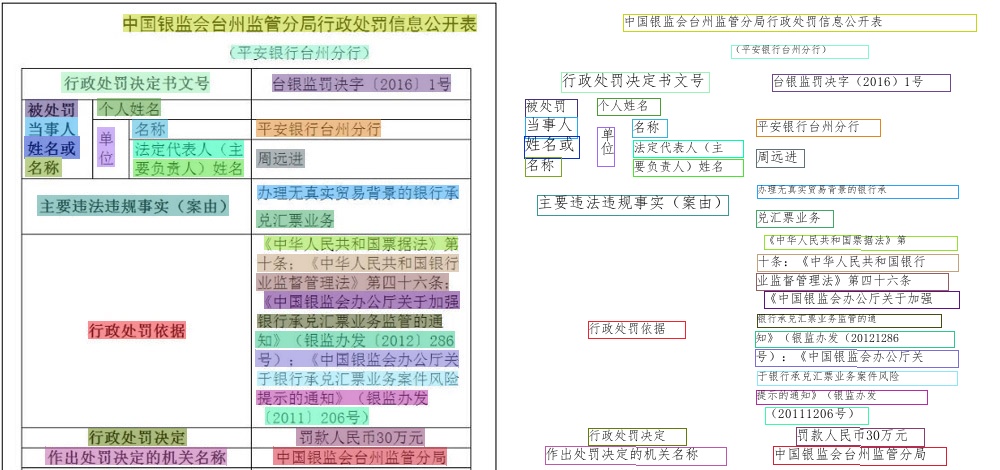
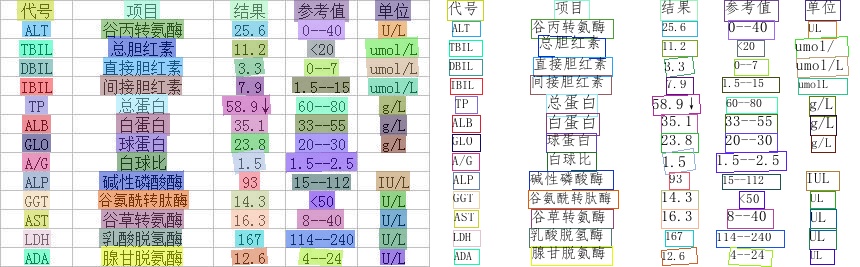
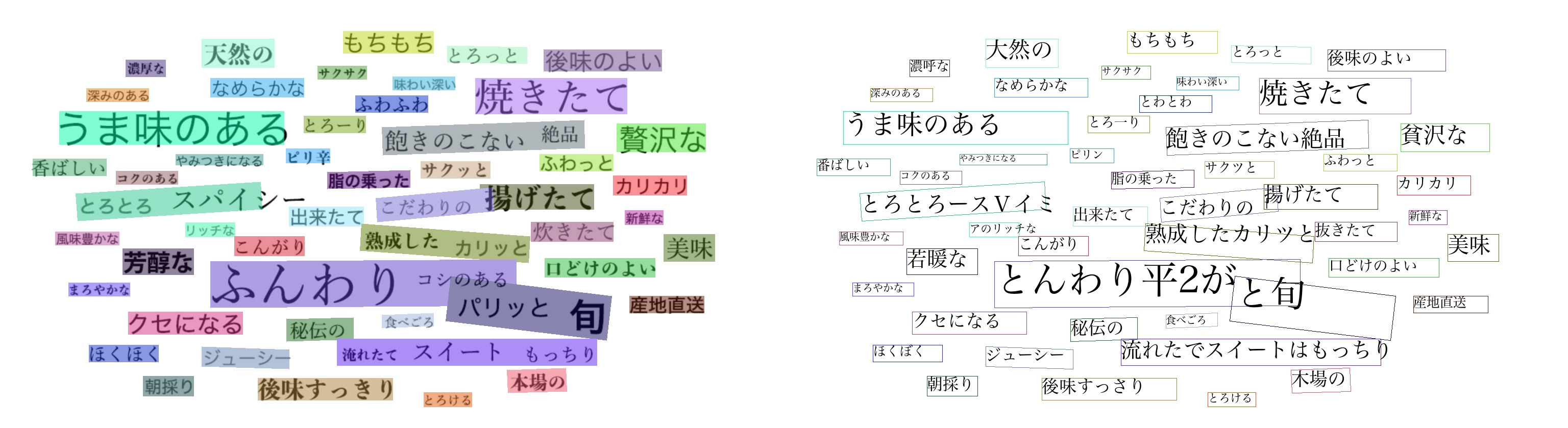
识别效果展示







 浙公网安备 33010602011771号
浙公网安备 33010602011771号