基于光度立体的复杂结构件表面缺陷检测数据集
 为解决非平面零部件缺陷检测时,高低起伏的形貌所形成的阴影或表面反光导致的误报和漏检问题,作者提出了一种基于深度学习和光度立体的新型缺陷检测技术。
为解决非平面零部件缺陷检测时,高低起伏的形貌所形成的阴影或表面反光导致的误报和漏检问题,作者提出了一种基于深度学习和光度立体的新型缺陷检测技术。
摘要
为解决非平面零部件缺陷检测时,高低起伏的形貌所形成的阴影或表面反光导致的误报和漏检问题,作者提出了一种基于深度学习和光度立体的新型缺陷检测技术。该技术一共从如下几个方面做出了贡献:
- 基于光度立体原理设计了一套频闪光源成像系统(Strobe Illuminant Imaging Method,SIIM),采集并标注了一套大型铸造件缺陷检测数据集。数据集共9332张,涵盖8种缺陷类型。
- 基于KAN网络设计了一种泰勒级数通道混频器(Taylor Series Channel Mixer,TSCM),将多光源图像混合生成具有深度信息的RGB伪彩色图像,并使用HSV色相随机变换产生新图像。通过该方法能够在不需要移动物理光源的条件下,随机生成不同光照条件下的训练数据,从而缓解网络检测时,对小缺陷对照明角度极其敏感的问题。
- 设计了一种相位不变特征提取模块(Phase-Invariant Feature Module,PIFM),可以帮助模型学习对输入图像中照明的细微变化不敏感的特征,从而提高网络的抗光照影响能力。
- 基于上述研究内容,作者尝试将TSCM、PIFM作为目标检测网络的特征提取骨干网络(对应P1~P3阶段),分别验证了FCOS、YOLOv5、YOLOv8、RT-DETR等几种典型目标检测模型,实验结果表明PIFM 模块都带来了 4.1% 到 5.5% 的平均精度(mAP)提升。对于缺陷中位置变化大,受光源角度影响大的缺陷类别,其平均精度提高了 18.7%,准确率和召回率也有了显著提高。
[!NOTE]
论文地址:A dataset for surface defect detection on complex structured parts based on photometric stereo | Scientific Data
数据集:Metal Surface Defect Dataset
项目代码:https://github.com/Destinyia/Metal-Surface-Defect-Detection
频闪光源成像系统
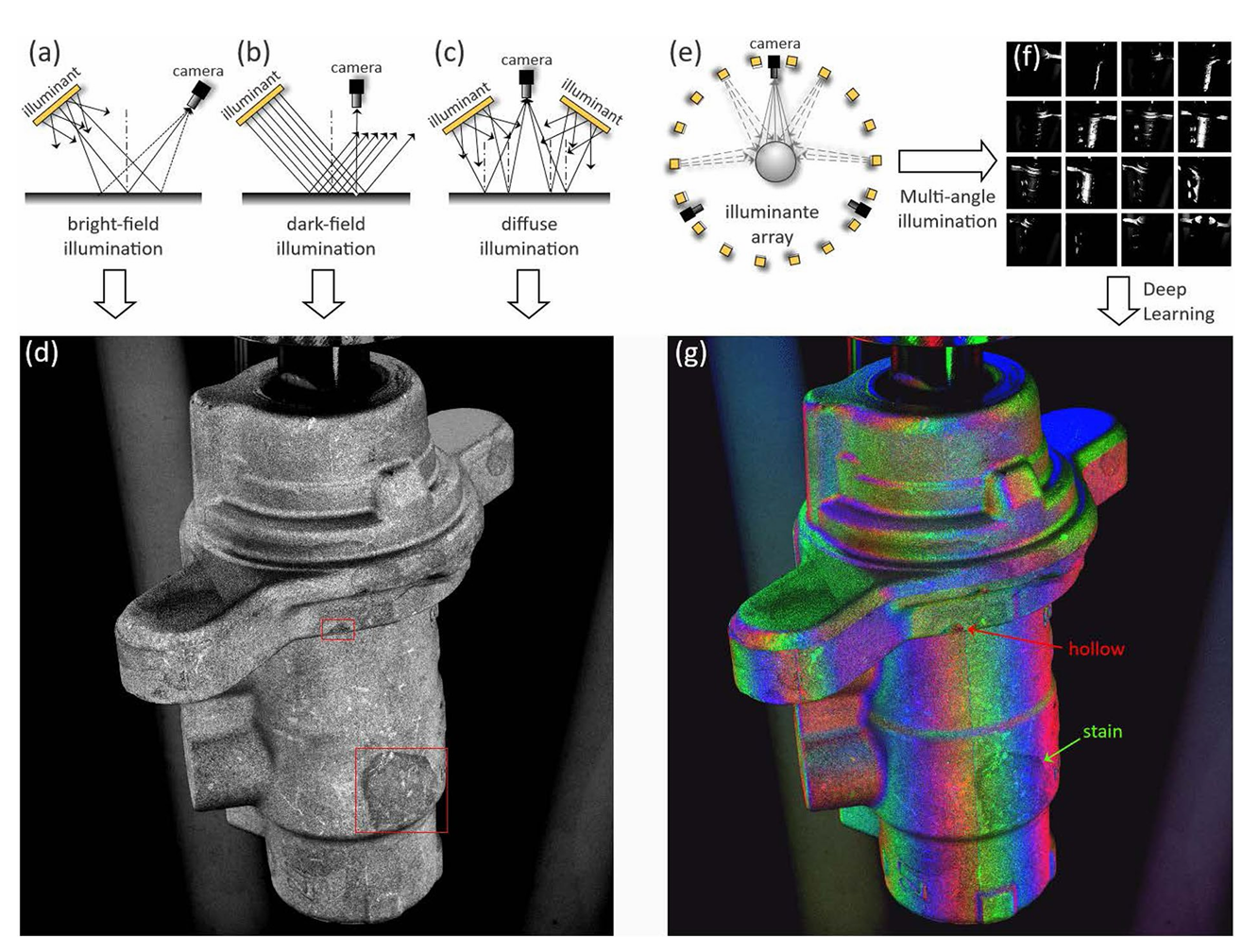
传统的打光方法[1]包括 “明场照明(a)”、“暗场照明(b)”、“漫反射照明(c)”,采集的图像效果如(d)所示。这些方法都属于2D成像方法。
本文中,作者将多个光源围绕被摄物一圈,并在四周布置相应的相机,通过PLC控制这些光源的频闪,以及相机采图,从而获得一些列不同视角下不同角度的光照条件下的图像。如(e)所示,采集的图像经深度学习网络可得到合成的伪彩色图像(g)。该方法与光度立体方法类似,属于3D成像方法。
该系统的相机采集帧率为 30 fps ,配合光源可实现 0.96s 内采集一个位姿下的全部图像。节拍上已足够满足典型铝合金铸造线上 300 pics/h 的生产周期要求。
作者对比了2D成像方法和3D成像方法的差异:
| 方面 | 2D 成像系统 | 3D 成像系统 |
|---|---|---|
| 示例图像 |  |
 |
| 成像原理 | 利用基于朗伯反射模型的亮度级别变化(例如,明场、暗场) | 利用深度信息和表面渐变(例如,光度立体、结构光、立体视觉) |
| 深度信息 | 缺乏准确识别缺陷所需的关键深度信息 | 捕获深度信息,以便更好地区分缺陷、阴影和污点 |
| 视野 | 捕获适用于平面的大面积 | 视野有限,通常需要扫描并难以处理大型或复杂的 3D 结构 |
| 表面复杂性 | 适用于平坦、简单的表面,适用于处理具有复杂几何形状或多种缺陷类型的零件 | 适用于更复杂和弯曲的表面,更擅长处理各种缺陷类型 |
| 速度 | 在图像捕获、处理和检查方面更快 | 由于需要扫描而变慢,限制了实时检测能力 |
| 实时应用 | 由于快速的图像捕获和处理,适用于实时应用 | 不太适合实时检测,因为扫描和重建过程较慢 |
| 成本 | 以更低的成本实现更简单、更便宜的硬件 | 由于硬件复杂且昂贵,成本较高 |
泰勒级数通道混频器
数据流
作者考虑到光度立体的基本原理是通过多角度光照条件下的多张图来恢复物体表明深度信息的,通常可以获得一张表面法向量RGB图像。因此在该SIIM系统下,也可以产生类似的伪彩色图像。
基于上述思路,作者结合KAN(Kolmogorov-Arnold Network)[2],设计了一种泰勒级数通道混频器(Taylor Series Channel Mixer,TSCM)。其工作原理如下:
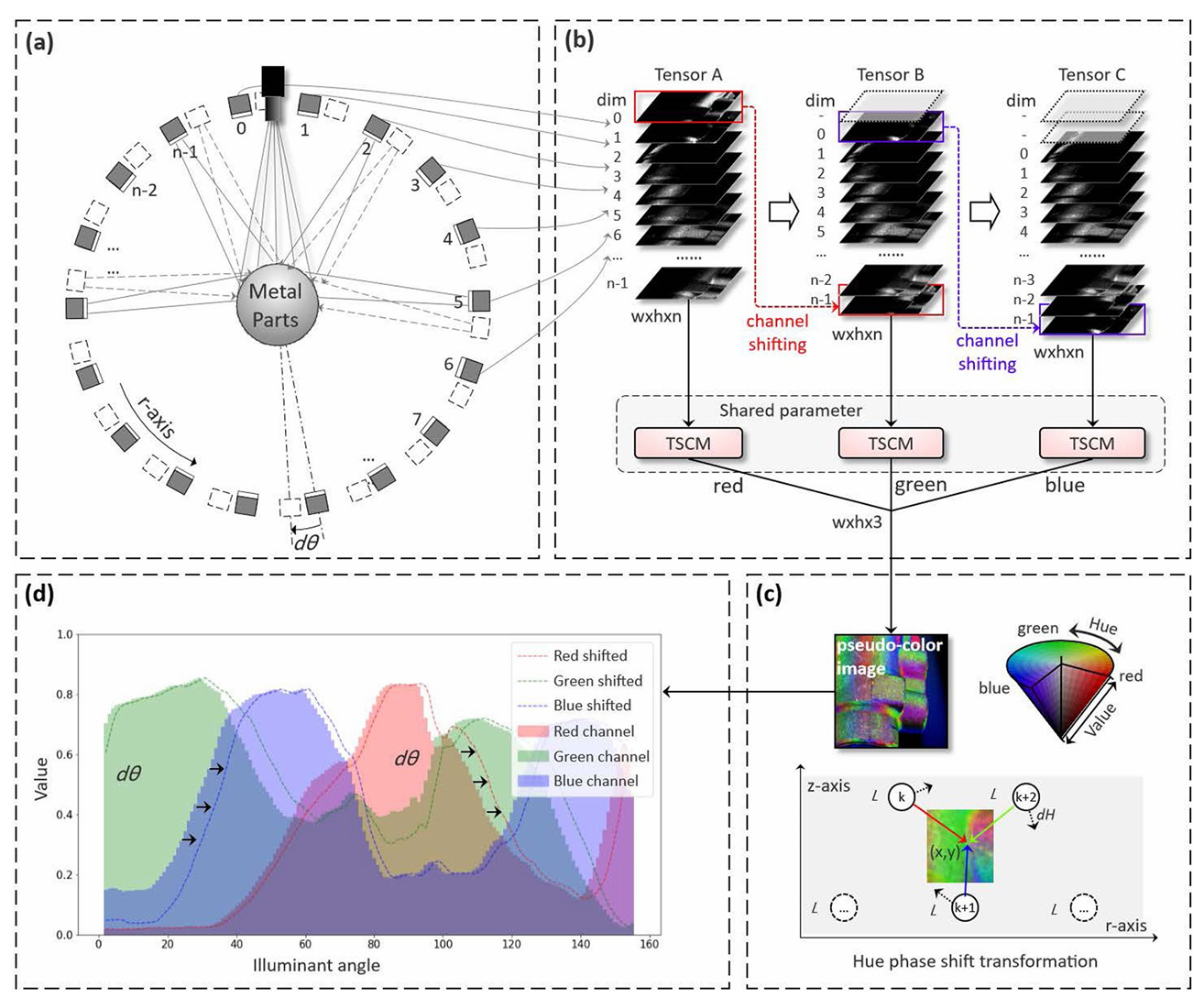
首先,在系统布局(a)下,一共可获得 n 张灰度图像,这些图像来自不同相机下的不同光照角度下所采集的图像。
然后,将这些图像堆叠在一起(注意是按照光源角度一圈顺序排列),形成大小为 w×h×n 的张量TensorA。然后将TensorA的第一张挪到最后,得到TensorB。同理,将TesnorB的第一张挪到最后,得到TensorC。以上操作称作“channel shifting”。
接着,TensorA、TesnorB、TensorC被送入一个叫做 “TSCM” 的模块,进行泰勒级数通道混合,分别输出大小为 w×h×1 的单通道图像,red、green、blue。将上述三个单通道合成三通道RGB图像,得到伪彩色图像。
对于RGB彩色图像,通过颜色空间变换,可转到HSV颜色空间,在色相(Hue) 通道中,可以通过下面的公式进行随机色相偏移。
其中,\({C}_{\max }=\max ({\rm{R}}{\prime} ,{\rm{G}}{\prime} ,{\rm{B}}{\prime} )\),\({C}_{\min }=\min ({\rm{R}}{\prime} ,{\rm{G}}{\prime} ,{\rm{B}}{\prime} )\) 。
由于色相实际上是由RGB通道图产生的,而RGB通道图又是通过 TSCM 生成的,TSCM又是由多角度光源图像堆叠通过 “channel shifting” 后产生的。因此,假设随机改变色相,实际上对应的是光源角度的改变,从而间接实现了在光源位置不发生移动的情况下,产生了不同光照条件下的图像。TSCM在输入值域[0,1]上能产生高精度的拟合效果,所以可以认为该模块可以生成任意光照下的图像。这无疑是给图像数据增加带来了极大的便利,网络也可以通过这种数据增强方法,学习到不受光照影响的本质特征。
TSCM 原理
TSCM 网络结构
根据泰勒级数展开定理,在点 \(a\) 处的四级泰勒展开可表述为:
输入的图像像素值在[0,1]区间上,因此四级泰勒展开已具备较高的拟合精度。

输入的多通道堆叠图像,分别输入给四级泰勒展开,然后再进行 channel shifting。
TSCM 网络训练
TSCM网络的本质是希望得到一个通道混合器,它可以拟合出反映出物体光照本质特征。而当光照发生变化时,用于特征提取的网络也应该不受光照的影响,因此对于光照的理解需要一个高纬度的特征空间进行解释,作者通过下面的网络结构进行训练。
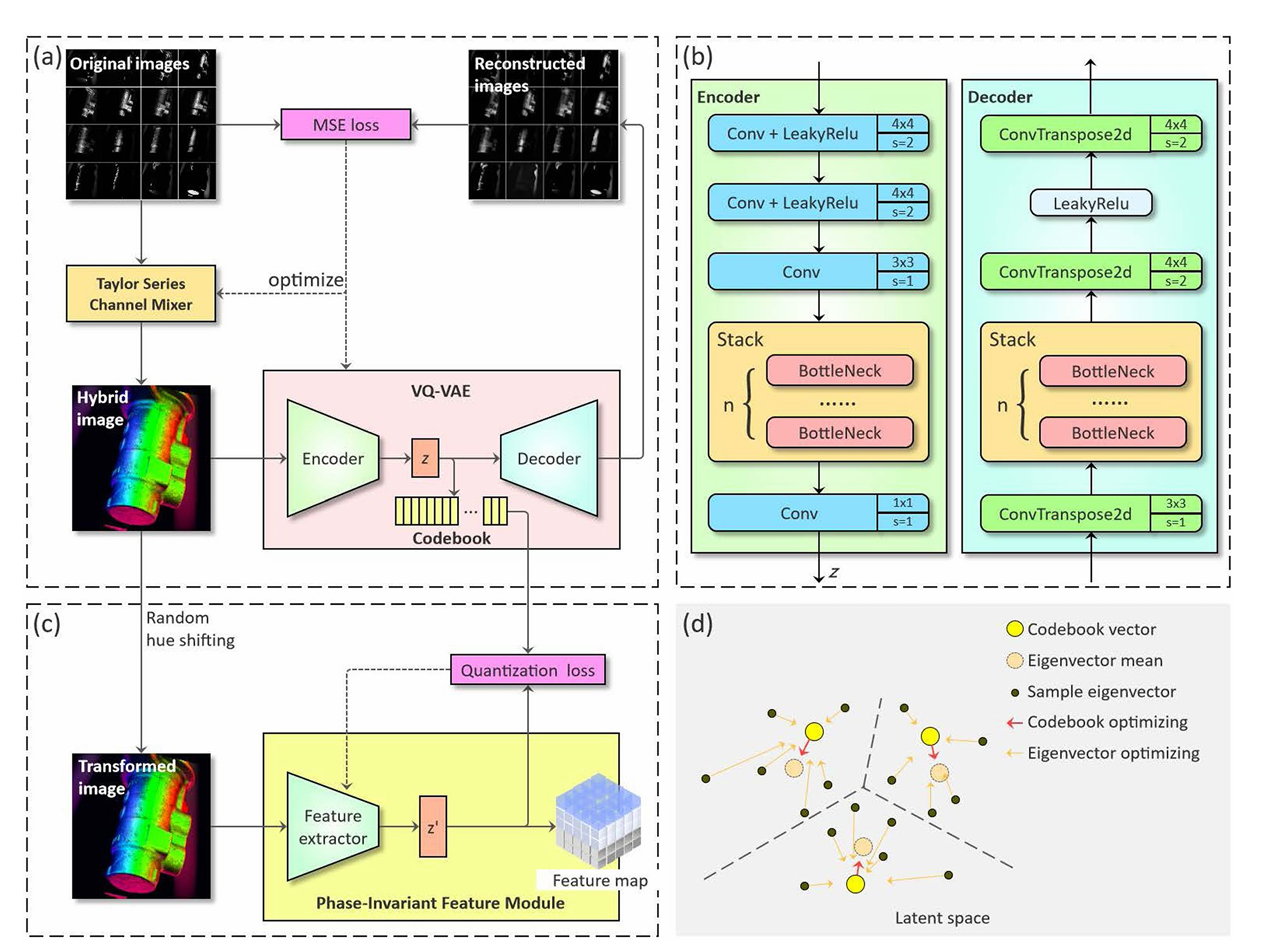
对于输入的多角度光源通道图像,经过TSCM模块输出伪彩色RGB图像(Hybrid image),该图像输入给向量量化变分自编码器(VQ-VAE)[3],通过编码器-解码器架构,可获得特征向量 \(z\) ,输出则是重建得到的原始多通道图像。通过优化原始图像和重建图像之间的 均方误差损失 (MSE Loss)来训练TSCM模块的参数,并获得一个可以解释光照特点的VQ-VAE。
其中编码器采用两个卷积层进行下采样,然后通过堆叠多个残差块得到编码向量 \(z\) ,解码器通过堆叠的多个残差块解码 \(z\) ,然后通过专职卷积上采样恢复分辨率。
当伪彩色图像通过色相随机偏移产生新的图像(Transformed image)时,图像被送入特征提取器中,得到特征向量 \(z'\) ,即特征图(Feature map)。此时获得的高维特征向量 \(z'\) 与前述 VQ-VAE 所获得的高维特征向量 \(z\) 之间应该由相似性,因为网络都需要对光照不变性进行理解。因此在训练特征提取器时,计算向量量化器损失 (Vector Quantizer Loss),以此来约束网络必须学习到光照不变性。
参与参数优化的损失一共有四个:
- MSE 损失(MSE Loss),最大限度地减少了图像混合后的信息损失。
- SSIM 损失(SSIM Loss),有助于消除重建图像中的“纱门”效果和细节模糊。
- 向量量化器损失(Vector Quantizer Loss),使码本向量 \(e\) 近似编码器输出的潜在变量 \(z\) 。
- 承诺损失(Commitment Loss),编码器输出的潜在变量 \(z\)近似于码本向量 \(e\)。
相位不变特征提取模块
该模块用于从图像中提取对色调变换不变的浅层特征信息,从而消除缺陷检测模型对照明角度的敏感性。该模块是非必要的。
与 VQ-VAE 不同,该方法直接使用潜在变量 z 重建图像以减少信息损失,同时使用 \(e\) 作为 PIFM 的学习目标。量化损失在自动编码器中起着至关重要的作用。通过构建一个离散而稳定的潜在空间,它可以帮助模型学习对输入图像中照明的细微变化不敏感的特征。通过将连续的潜在表示映射到有限的预定义码本空间,矢量化表示的离散向量降低了网络对照明角度变化的敏感性,从而鼓励网络在不同照明条件下学习一致、抽象和概念性的信息。这种模块化设计使 PIFM 模块能够轻松集成到其他物体检测网络中。该编码器被设计为一个独立的特征提取模块,负责从图像中提取不受光照角度影响的特征,可以直接替换许多目标检测网络的 P1 和 P2 层,使用常规方法训练网络。
数据集
数据集采集过程
作者指出,该数据集名为 MSDD (Metal Surface Defect Datase)。
该数据集收集了 1,507 个有缺陷的金属零件。六台相机在不同的照明条件下多次拍摄图像,从而产生了一个最初的大型数据集。这种方法利用高分辨率相机(高达 2560 × 1920 像素)来检测小至 0.5 毫米的缺陷。这些图像使模型能够有效地识别微小的缺陷特征。为了管理大图像尺寸,滑动窗口技术将图像分成 640 × 640 个色块,具有 15% 的重叠,以确保完整的缺陷检测。所有图像都经过轻微扭曲、缩放和剪切,以掩盖产品的真实尺寸和形状。此外,所有徽标和识别标记均已删除,以防止潜在的商业纠纷。实验结果表明,这些修改对缺陷检测性能没有显著影响。
数据集标注
数据注释过程由两名受过专业培训的检查员和一名质量主管完成。在开始之前,检查员手动确认零件上的缺陷,以避免光学增强方法的任何影响。然后,两名检查员收集了零件的图像,并独立对增强后的图像进行了注释。在两名检查员完成注释后,注释框的 IoU 用于确定是否需要质量主管进行审核。如果需要审查,质量主管会完成注释;否则,将两个注释框的平均值作为最终结果。
数据集预览
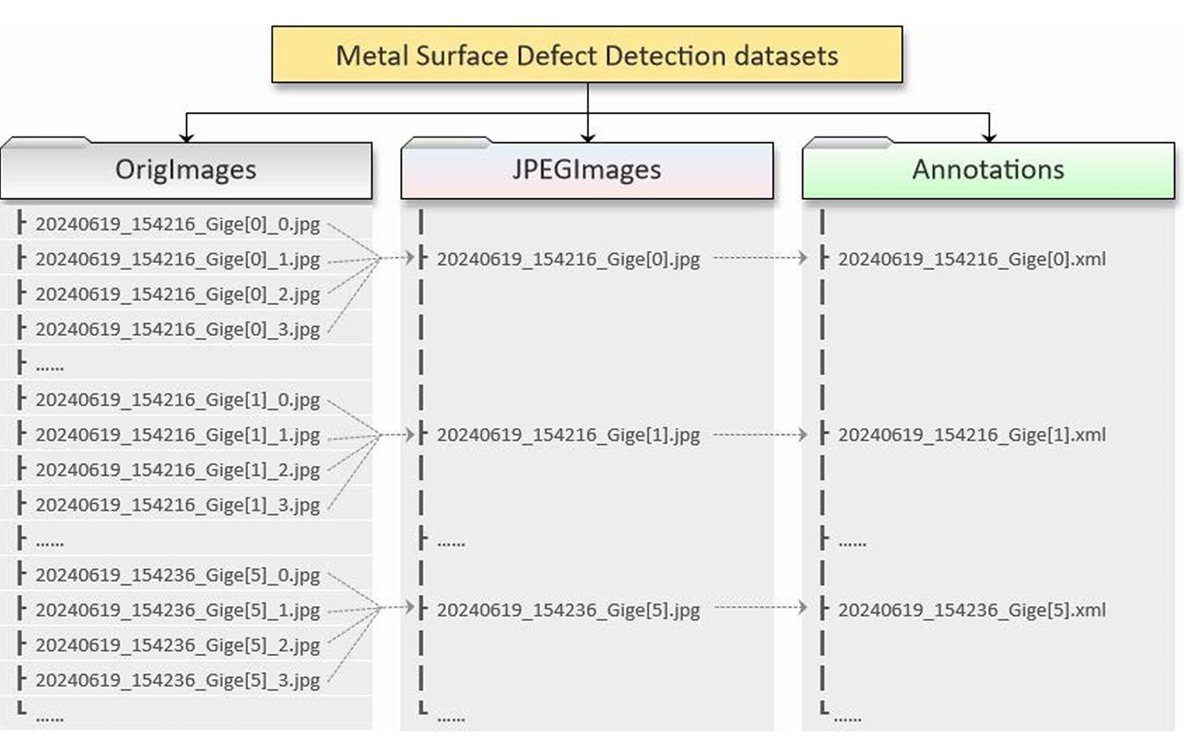
数据集下载后,结构如下:
├─Annotations // 目标检测框标签
├─ImageSets // 训练集与测试集图像路径
├─JPEGImages // 合成伪彩色图像
└─OrigImages // 原始图像
消融实验细节
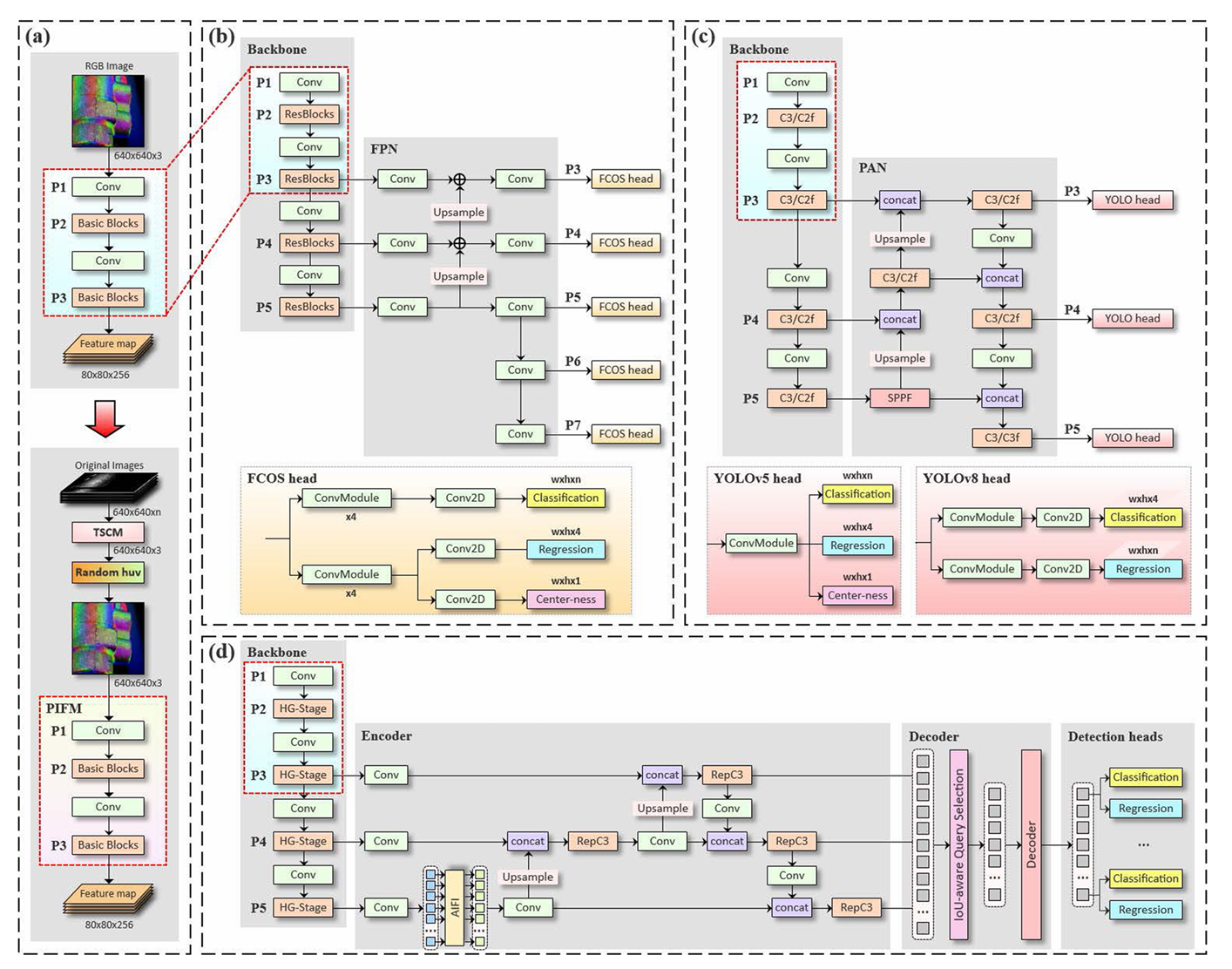
本研究中收集的图像可用于一般目标检测模型中的训练和检测,只需将 TSCM 混合的 RGB 伪彩色图像输入这些网络,类似于使用其他缺陷检测数据集的方式。为了整合 PIFM 并实现端到端优化,传统缺陷检测模型中主干的 P1-P3 阶段可以替换为 PIFM。此修改独立于对象检测模型架构,无论是无锚点、基于锚点还是基于 ViT。因此,我们在 FCOS 上测试了这种方法24(图 .5b)、YOLOv525、YOLOv826(图 .5c) 和 RT-DETR27(图 .5d). Ultralytics26框架被用来促进目标检测网络的快速构建,尽管它对我们的方法不是必需的。
泰勒级数通道混频器消融实验
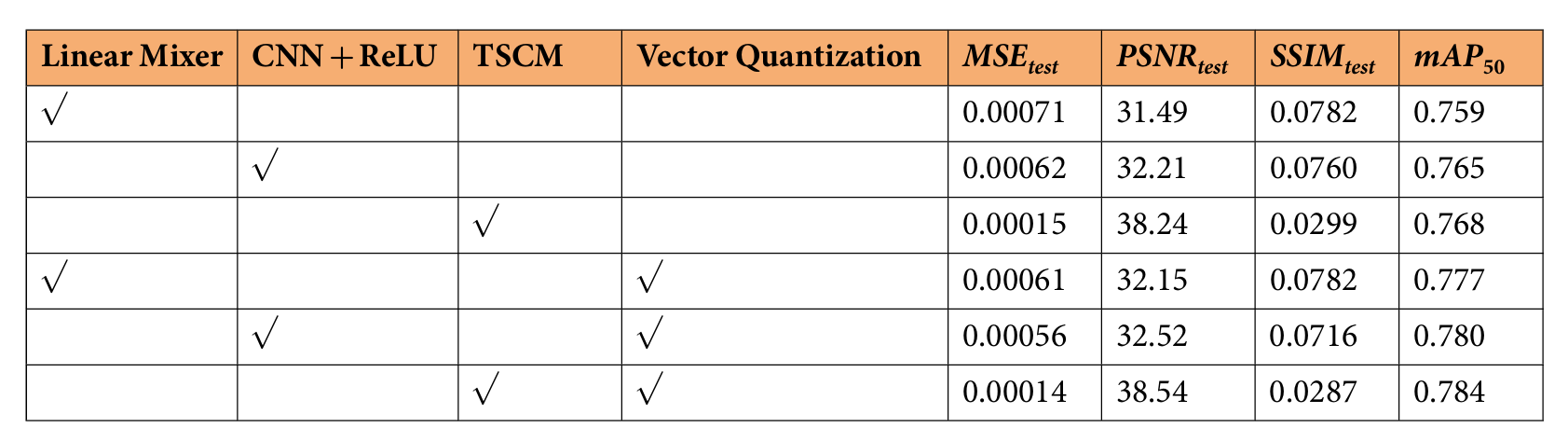
TSCM 采用了泰勒级数展开,因此对比了有传统线性混合、卷积混合、以及向量量化。可以看到TSCM+向量量化效果最好。
不同网络结构的消融实验
为了进一步验证这种方法的有效性,我们将其与最先进的通用目标检测网络进行了比较,包括 FCOS 、 YOLOv5 、 YOLOv8 和 RT-DETR 。基线版本使用静态图像混合方法,混合参数由自动编码器优化;改进版本使用端到端优化图像混合方法和基于梯度的随机相移变换进行数据增强。此外,作为对照,将模型输入通道修改为 n,将 n 通道原始图像直接输入到模型中进行训练,无需混合。
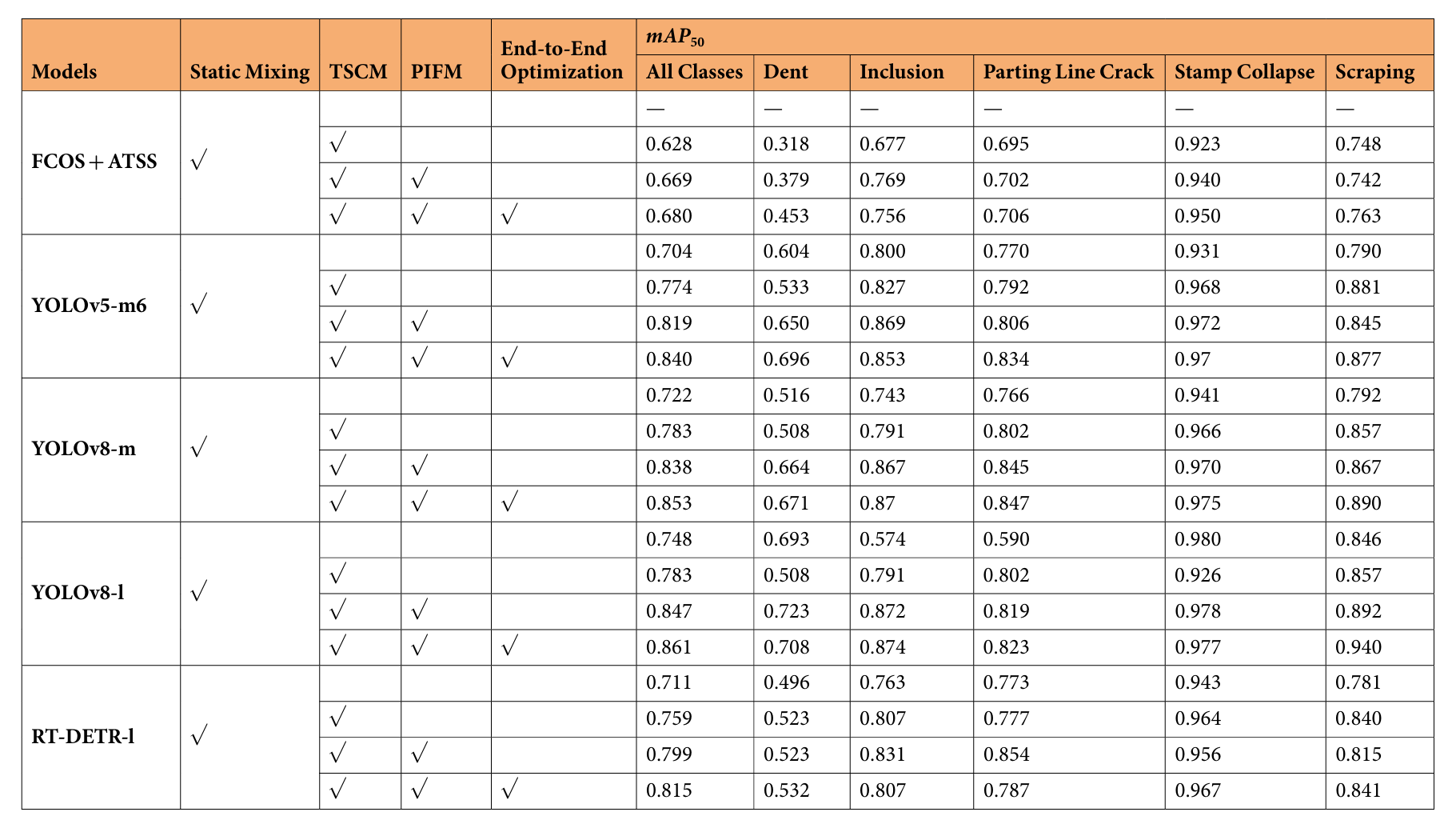
实验结果如表所示。由于跑偏和麻点缺陷的样本量小,没有统计学意义,实验只比较了五种类型的缺陷:凹痕、夹杂物、分型线裂纹、冲压塌陷和模具划伤。结果表明,使用静态混合 RGB 图像的缺陷检测方法明显优于没有混合的直接训练。无论使用何种目标检测网络,与静态混合方案相比,采用相移变换实现的 PIFM 模块都带来了 4.1% 到 5.5% 的平均精度提升。端到端优化的通道混频器提供了 1.1% 到 2.1% 的额外平均精度提升。YOLOv8-l 网络在 MSDDs 数据集上表现最佳,实现了 mAP50的 0.854,如图所示。YOLOv8-m 网络的准确率与 YOLOv8-l 几乎相同,但检测速度更快,是整体表现最好的。
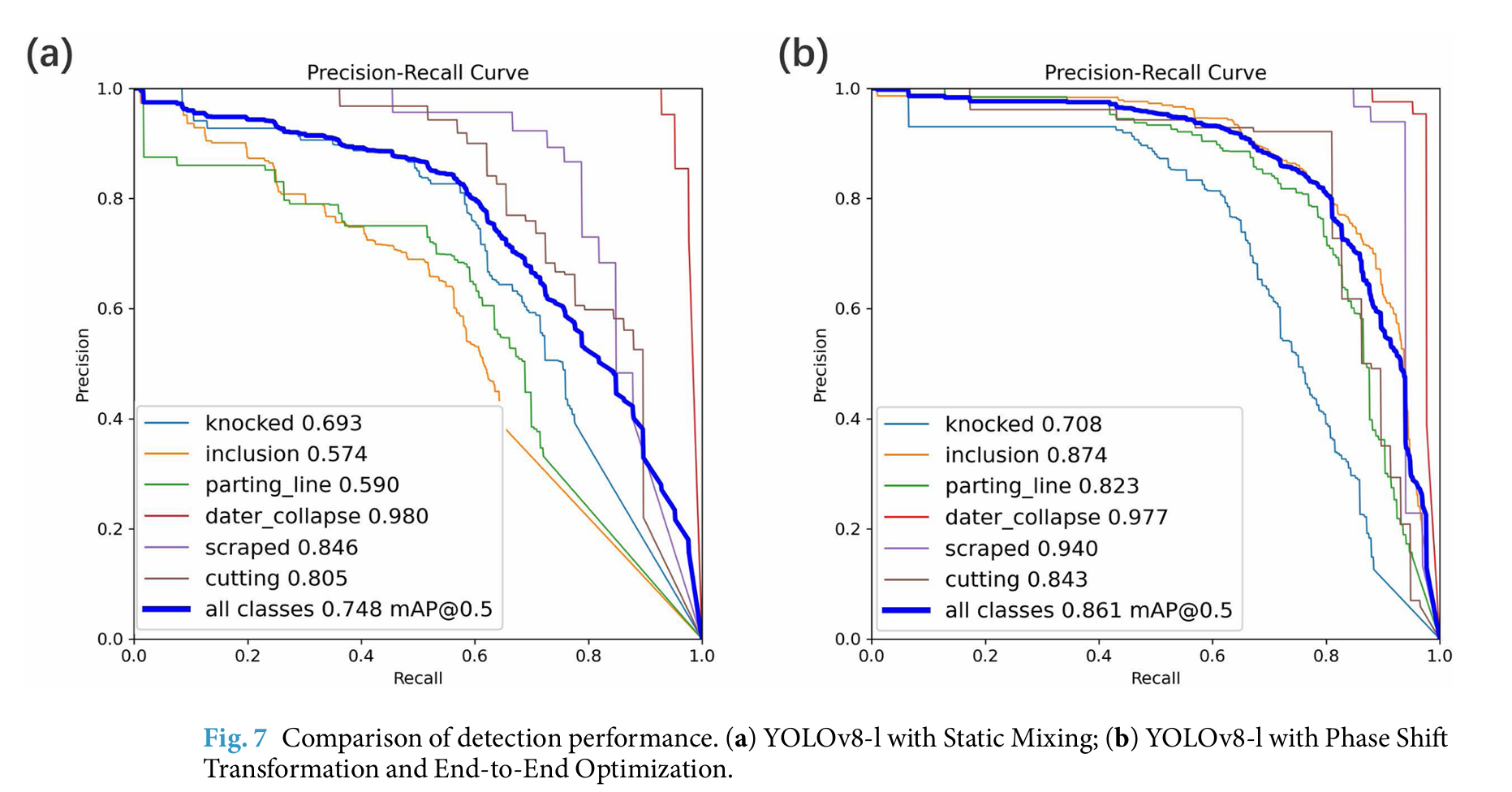
从具体缺陷类别来看,相移变换对冲压塌陷和分型线裂纹等缺陷的影响最小,仅提高了平均精度约 1%。这可能是因为这些缺陷发生在相对固定的位置,并且对光源角度不太敏感。然而,凹痕和夹杂物缺陷在零件上的位置可变,并且受光源角度的影响很大,平均精度提高了 18.7%,准确率和召回率也有了显著提高。

材料复杂的几何形状导致 100% 的样品受到阴影和遮挡的影响,从而显着影响检测性能。此外,由污渍引起的低反射率很难量化,因为污渍作为非缺陷,没有注释。然而,由于铝合金铸造毛坯通常存放在室外,它们会暴露在雨水和飓风等环境因素中,导致污渍的批量出现,从而导致在现实世界环境中出现大量错误检测。
其他缺陷检测数据集对比
| 方面 | NEU-DET | GC10-DET | MSDD |
|---|---|---|---|
| 示例图像 |  |
 |
 |
| 灰度图像 | 1800 | 2280 | 149312 |
| RGB 图像 | — | — | 9332 |
| 缺陷类型 | 龟裂, 夹杂物, 斑块, 凹坑表面, 卷曲鳞片, 划痕 | 裂纹、熔接线、夹杂物、划痕、凹坑、凸块、断裂、卷入刻度、油点、脏点 | 夹杂物、切割痕迹、压痕塌陷、霉菌擦伤、凹痕、麻点、分型线裂纹、跑偏 |
| 图像大小 | 200 × 200 | 2048 × 1000 | 640 × 640 |
| 结构复杂性 | 平面 | 平面 | 非平面 |

2D 成像系统与我们的方法的比较。(a) 左:凹形不清晰可见;右:使用我们的方法清楚地描绘了凹形;(b) 左:在传统方法中区分阴影和污渍具有挑战性;右:在伪彩色图像中更容易;(c) 左图:在 2D 图像中,可以看到两个黑点;右:只有一个是夹杂物(红色框),而另一个是由突起引起的阴影(绿色框);(d) 左:漫射光源降低了切割痕迹的对比度;右:在伪彩色图像中,剪切标记更加突出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号