曹工杂谈:分布式事务解决方案之基于本地消息表实现最终一致性
曹工杂谈:分布式事务解决方案之基于本地消息表实现最终一致性
前言
为什么写这个?其实我这边的业务场景,严格来说,不算是典型的分布式事务,需求是这样说的:因为我这边负责的一个服务消费者consumer,是用户登录的入口;正常情况下,登录时候要走用户中心,这是个单独的服务;如果用户中心挂了,我这边自然是没法登录的。
现在的需求就是说,假设用户中心挂了,也要可以正常登录。因为我这个consumer其实也是缓存了用户的数据的,在本地登录也可以的,如果在我本地登录的话,我就得后续等用户中心恢复后,再把相关状态同步过去。
基于这样一个需求,我这边的实现方案是:
1.配置文件里维护一个开关,表示是否开启:故障转移模式。暂不考虑动态修改开关(如果要做,简单做就提供个接口来改;复杂做,就放到配置中心里,我们现在用的nacos,可以改了后推送到服务端)
2.如果开关是打开的,表示需要进行故障转移,则登录、退出登录等各种需要访问用户中心的请求,都存储到数据库中;数据库会有一张表,用来存放这类请求。大致如下:
CREATE TABLE `cached_http_req_to_resend` (
`http_req_id` bigint(20) NOT NULL COMMENT '主键',
`req_type` tinyint(4) NOT NULL COMMENT '请求类型,1:推送待处置结果给第三方系统',
`third_sys_feign_name` varchar(30) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '第三方系统的名称,和feignClient的保持一致',
`http_req_body` varchar(4000) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '请求体',
`current_state` tinyint(4) DEFAULT NULL COMMENT '该请求当前状态,1:成功;2:失败;3:待处理;4:失败次数过多,放弃尝试',
`fail_count` tinyint(4) DEFAULT NULL COMMENT '截止目前,失败次数;超过指定次数后,将跳过该请求',
`success_time` datetime DEFAULT NULL COMMENT '请求成功发送的时间',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`related_entity_id` bigint(21) DEFAULT NULL COMMENT '相关的实体的id,比如在推送待处置警情时,这个id为处警id',
PRIMARY KEY (`http_req_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
3.单独开一个schedule线程,定时去扫这个表,发现有需要处理的,就去重新发送请求就行了,成功了的,直接更新状态为success。
这个模式,其实就算是分布式事务中的:本地消息表方案了。
本地消息表,有一个注意的点,就是要把保存消息的操作和业务相关操作,放到同一个事务中,这样可以确保,业务成功了,消息肯定是落库了的,很可靠。然后再开启个定时任务,去扫描消息表即可。
我这边不是发消息,而是发请求,道理是类似的。
下面开始基于代码demo来讲解。
代码结构
这边就是简单的几个module,基于spring cloud开发了一个服务提供者和一个服务消费者。服务提供者对外暴露的接口,通过api.jar的形式,提供给消费者,这种算是强耦合了,有优点,也有缺点,这里就不讨论了。
消费者通过feign调用服务提供者。有人会问,不需要eureka这些东西吗,其实是可以不需要的,我们直接在ribbon的配置中,把服务对应的:ip和端口写死就完了。
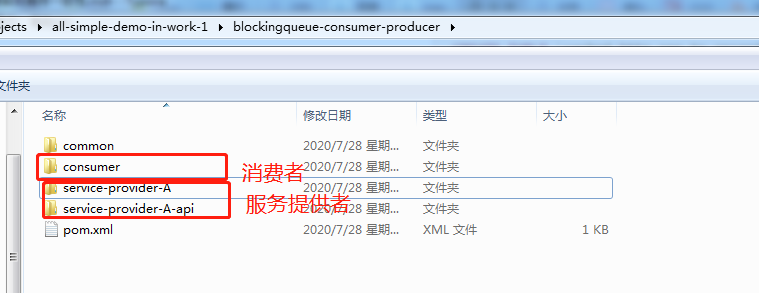
我们这里就是,消费者访问服务提供者,正常情况下直接访问就行了;但我们这里,模拟的就是服务A访问不了的情况,所以会直接把请求落库,后续由定时线程去处理。
服务提供者-api
我们看看服务提供者api,里面仅有一个接口:
public interface FeignServiceA {
/**
*
* @return
*/
@RequestMapping("/login")
public Message<LoginRespVO> login(@RequestBody LoginReqVO loginReqVO);
}
服务提供者的逻辑
其中,逻辑如下:
@RestController
@Slf4j
public class DemoController extends BaseController implements FeignServiceA {
// 1
@Override
public Message<LoginRespVO> login(@RequestBody LoginReqVO loginReqVO) {
log.info("login is ok,param:{}", loginReqVO);
LoginRespVO vo = new LoginRespVO();
vo.setUserName(loginReqVO.getUserName());
vo.setAge(11);
vo.setToken(UUID.randomUUID().toString());
return successResponse(vo);
}
}
这里1处就是提供了一个接口,接口里返回一点点信息。测试一下:

服务消费者之正常请求服务提供者
pom.xml中依赖服务提供者的api
<dependency>
<groupId>com.example</groupId>
<artifactId>service-provider-A-api</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
feign client代码
我们需要写一个接口,继承其feign api。
@FeignClient(value = "SERVICE-A")
public interface RpcServiceForServiceA extends FeignServiceA {
}
要调用的时候,怎么弄呢? 直接注入该接口,然后调用对应的方法就行了,这样就可以了。
@Autowired
private RpcServiceForServiceA rpcServiceForServiceA;
Message<LoginRespVO> message = rpcServiceForServiceA.login(reqVO);
但是,我们好像没有配置注册中心之类的东西,这个我们可以绕过,因为最终发起调用的是,ribbon这个组件。
ribbon提供了几个接口,其中一个,就是用来获取服务对应的实例列表。
这里要说的,就是下面这个接口:
package com.netflix.loadbalancer;
import java.util.List;
/**
* Interface that defines the methods sed to obtain the List of Servers
* @author stonse
*
* @param <T>
*/
public interface ServerList<T extends Server> {
public List<T> getInitialListOfServers();
/**
* Return updated list of servers. This is called say every 30 secs
* (configurable) by the Loadbalancer's Ping cycle
*
*/
public List<T> getUpdatedListOfServers();
}
这个接口,有多个实现,ribbon自带了几个实现,然后eureka 、nacos的客户端,都自己进行了实现。
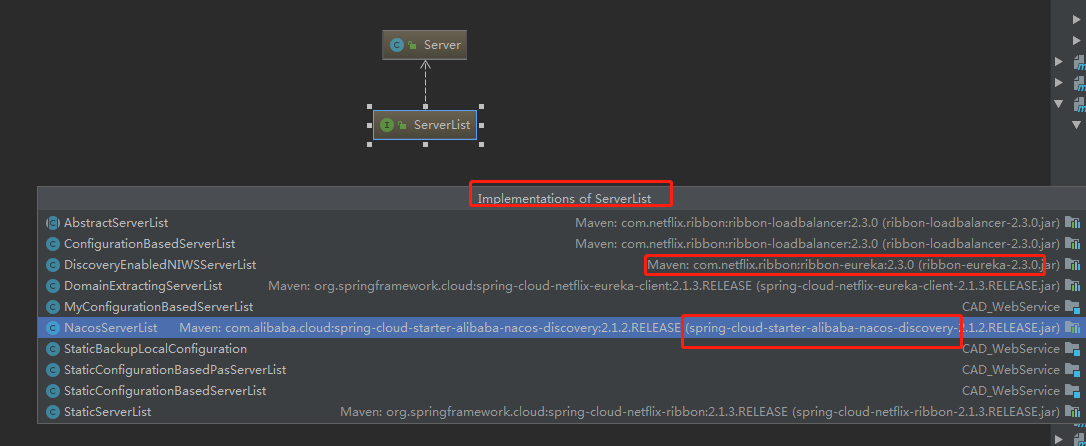
ribbon自带的实现中,有一个叫做:
public class ConfigurationBasedServerList extends AbstractServerList<Server> {
private IClientConfig clientConfig;
...
@Override
public List<Server> getUpdatedListOfServers() {
// 1
String listOfServers = clientConfig.get("listOfServers");
return derive(listOfServers);
}
1处可以看到,它获取服务对应的实例,就是通过去配置文件里获取listOfServers这个key中配置的那些。
总之,最终我们向下面这样配置就行了:
SERVICE-A.ribbon.ReadTimeout=3000
SERVICE-A.ribbon.listOfServers=localhost:8082
SERVICE-A.ribbon.NIWSServerListClassName=com.netflix.loadbalancer.ConfigurationBasedServerList
这里的前缀,SERVICE-A和之前下面这个地方一致就行了:
@FeignClient(value = "SERVICE-A")
public interface RpcServiceForServiceA extends FeignServiceA {
}
正常情况下,就说完了,直接调用就行,和httpclient调用没啥本质差别。只不过ribbon提供了负载均衡、重试等各种功能。
设计表结构,在使用故障转移模式时,保存请求
表结构我前面已经贴了,这里就展示下数据吧(可点击放大查看):

保存请求的代码很简单:
@Override
public LoginRespVO login(LoginReqVO reqVO) {
boolean failOverModeOn = isFailOverModeOn();
/**
* 故障转移没有开启,则正常调用服务
*/
if (!failOverModeOn) {
...
return ...;
}
/**
* 1 使用本地数据进行服务,并将请求保存到数据库中
*/
iCachedHttpReqToResendService.saveLoginReqWhenFailOver(reqVO);
/**
* 返回一个 dummy 数据
*/
return new LoginRespVO();
}
上面的1处,就会保存请求到数据库。
定时线程消费逻辑
概览
定时线程这边,我设计得比较复杂一点。因为实际场景中,上面的表中,会存储多个第三方服务的请求;比如service-A,service-B。
所以,这里的策略是:
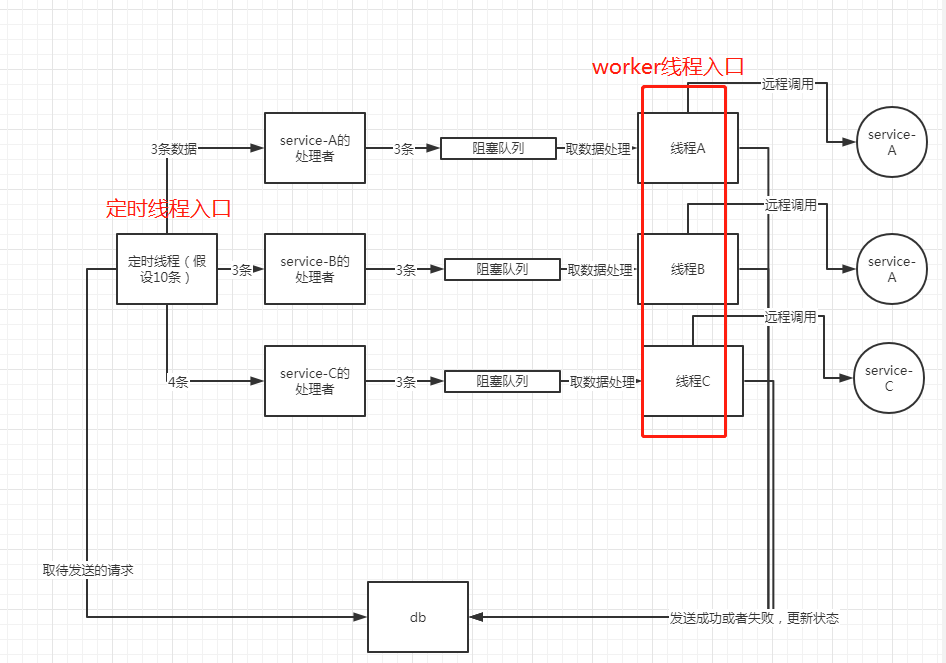
简单来说,就是定时线程,拿到任务后,按照第三方服务的名字来进行group by操作,比如,要发送到service-A的请求放一起,按时间排好序;要发送给service-B的放一起,排好序。
然后找到service-A,service-B各自对应的处理器,然后把数据丢给这些处理器;处理器拿到后,就会放到阻塞队列里;
然后此时worker线程就会被阻塞队列给唤醒,唤醒后,就去开始处理这些请求,包括发起feign调用,并且更新结果到数据库中。
定时线程入口
@Scheduled(cron = "0/30 * * * * ? ")
public void sendCachedFeignReq() {
Thread.currentThread().setName("SendCachedFeignReqTask");
log.info("start sendCachedFeignReq");
/**
* 1、获取锁
*/
boolean success = iCommonDistributedLockService.tryLock(DISTRIBUTED_LOCK_ENUM.SEND_CACHED_FEIGN_REQ_TO_REMOTE_SERVER.lockName, DISTRIBUTED_LOCK_ENUM.SEND_CACHED_FEIGN_REQ_TO_REMOTE_SERVER.expireDurationInSeconds);
/**
* 进行业务逻辑处理
*/
iCachedHttpReqToResendService.processCachedFeignReqForLoginLogout();
...
}
这里还加了个分布式锁的操作,用数据库实现的,还没经过充分测试,可能会有点小问题,不过不是重点。
下面看看业务逻辑:
@Override
public void processCachedFeignReqForLoginLogout() {
// 1
String[] feignClients = {EFeignClient.SERVICE_A.getName()};
// 2
for (String feignClient : feignClients) {
/**
* 3 从数据库获取要发送到该服务的请求
*/
List<CachedHttpReqToResend> recordsFromDb = getRecordsFromDb(feignClient);
if (CollectionUtils.isEmpty(recordsFromDb)) {
continue;
}
/**
* 4 根据feign client,找到对应的处理器
*/
CachedHttpReqProcessor cachedHttpReqProcessor = cachedHttpReqProcessors.stream().filter(item -> item.support(feignClient)).findFirst().orElse(null);
if (cachedHttpReqProcessor == null) {
throw new RuntimeException();
}
/**
* 5 利用对应的处理器,处理该部分请求
*/
cachedHttpReqProcessor.process(recordsFromDb);
}
}
- 1,定义一个数组,数组中包括所有要处理的第三方系统
- 2,遍历
- 3,根据该serviceName,比如,根据service-A,去数据库查询对应的请求(这里可能和前面的图有点出入,以这里的代码为准)
- 4,根据该service-A,找到对应的处理器
- 5,利用第四步找到的处理器,来处理第三步中查到的数据
怎么找到service-A对应的处理器
我们先看看处理器这个接口:
public interface CachedHttpReqProcessor {
/**
* 该处理器是否支持处理该service
* @param feignClientName
* @return
*/
boolean support(String feignClientName);
/**
* 具体的处理逻辑
* @param list
*/
void process(Collection<CachedHttpReqToResend> list);
/**
* worker线程的名字
* @return
*/
String getThreadName();
}
然后看看针对service-A的处理器,是怎么实现的:
@Service
public class CachedHttpReqProcessorForServiceA extends AbstractCachedHttpReqProcessor {
// 1
@Override
public boolean support(String feignClientName) {
return Objects.equals(EFeignClient.SERVICE_A.getName(), feignClientName);
}
@Override
public String getThreadName() {
return "CachedHttpReqProcessorForServiceA";
}
1处,判断传入的feign客户端,是否等于EFeignClient.SERVICE_A,如果是,说明找到了对应的处理器。
我们这里将这个service,注册为了bean;在有多个serviceA,serviceB的时候,就会有多个CachedHttpReqProcessor处理器。
我们在之前的上层入口那里,就注入了一个集合:
@Autowired
private List<CachedHttpReqProcessor> cachedHttpReqProcessors;
然后在筛选对应的处理器时,就是通过遍历这个集合,找到合适的处理器。
具体的,大家可以把代码拉下来看看。
CachedHttpReqProcessor的处理逻辑
对于serviceA,serviceB,service C,由于处理逻辑很大部分是相同的,我们这里提取了一个抽象类。
@Slf4j
public abstract class AbstractCachedHttpReqProcessor implements CachedHttpReqProcessor {
private LinkedBlockingQueue<CachedHttpReqToResend> blockingQueue = new LinkedBlockingQueue<>(500);
private AtomicBoolean workerInited = new AtomicBoolean(false);
Thread workerThread;
@Override
public void process(Collection<CachedHttpReqToResend> list) {
if (CollectionUtils.isEmpty(list)) {
return;
}
/**
* 1 直到有任务要处理时(该方法被调用时),才去初始化线程
*/
if (workerInited.compareAndSet(false, true)) {
// 2
workerThread = new Thread(new InnerWorker());
workerThread.setDaemon(true);
workerThread.setName(getThreadName());
workerThread.start();
}
/**
* 放到阻塞队列里
*/
blockingQueue.addAll(list);
}
我们这里1处,给每个处理器,定义了一个工作线程,且只在本方法被调用时,才去初始化该线程;为了防止并发,使用了AtomicBoolean,保证只会初始化一次。
2处,给线程设置了Runnable,它会负责实际的业务处理。
然后3处,直接把要处理的任务,丢到阻塞队列即可。
Worker的处理逻辑
任务已经是到了阻塞队列了,那么,谁去处理呢,就是worker了。如果大家忘了整体的设计,可以回去看看那张图。
public abstract boolean doProcess(Integer reqType, CachedHttpReqToResend cachedHttpReqToResend);
/**
* 从队列取数据;取到后,调用子类的方法去处理;
* 子类处理后,返回处理结果
* 根据结果,设置成功或者失败的状态
*/
public class InnerWorker implements Runnable {
@Override
public void run() {
while (true) {
// 1
boolean interrupted = Thread.currentThread().isInterrupted();
if (interrupted) {
log.info("interrupted ,break out");
break;
}
// 2
CachedHttpReqToResend cachedHttpReqToResend;
try {
cachedHttpReqToResend = blockingQueue.take();
} catch (InterruptedException e) {
log.info("interrupted,e:{}", e);
break;
}
// 3
Integer reqType = cachedHttpReqToResend.getReqType();
if (reqType == null) {
continue;
}
try {
/**
* 4 使用模板方法设计模式,交给子类去实现
*/
boolean success = doProcess(reqType, cachedHttpReqToResend);
// 5
if (!success) {
cachedHttpReqToResend.setFailCount(cachedHttpReqToResend.getFailCount() + 1);
} else {
cachedHttpReqToResend.setCurrentState(CachedHttpReqToResend.CURRENT_STATE_SUCCESS);
cachedHttpReqToResend.setSuccessTime(new Date());
}
// 6
boolean count = iCachedHttpReqToResendService.updateById(cachedHttpReqToResend);
if (count) {
log.debug("update sucess");
}
} catch (Throwable throwable) {
log.error("e:{}", throwable);
continue;
}
}
}
}
- 1,判断是否被中断了,这样可以在程序关闭时,感知到;避免线程泄漏
- 2,从阻塞队列中,获取任务
- 3,判断请求类型是否为null,这个是必须要的
- 4,使用模板方法设计模式,具体逻辑,具体怎么发请求,谁去发,交给子类实现
- 5、6,根据结果,更新这条数据的状态。
子类中的具体逻辑
我们这里贴个全貌:
@Service
@Slf4j
public class CachedHttpReqProcessorForServiceA extends AbstractCachedHttpReqProcessor {
@Autowired
private FeignServiceA feignServiceA;
@Autowired
private ObjectMapper objectMapper;
@Override
public boolean support(String feignClientName) {
return Objects.equals(EFeignClient.SERVICE_A.getName(), feignClientName);
}
@Override
public String getThreadName() {
return "CachedHttpReqProcessorForServiceA";
}
/**
* 1 根据请求type字段,我们就知道是要发送哪一个请求
* @param reqType
* @param cachedHttpReqToResend
* @return
*/
@Override
public boolean doProcess(Integer reqType, CachedHttpReqToResend cachedHttpReqToResend) {
switch (reqType) {
// 2
case CachedHttpReqToResend.REQ_TYPE_LOGIN_TO_SERVICE_A: {
// 3
String httpReqBody = cachedHttpReqToResend.getHttpReqBody();
try {
// 4
LoginReqVO loginReqVO = objectMapper.readValue(httpReqBody, LoginReqVO.class);
/**
* 5 发起登录
*/
Message<LoginRespVO> message = feignServiceA.login(loginReqVO);
boolean success = FeignMsgUtils.isSuccess(message);
return success;
} catch (Throwable e) {
log.error("e:{}", e);
return false;
}
}
}
return true;
}
}
- 1,这个类就是实现了父类中的抽象方法,这里体现的就是模板方法设计模式
- 2,根据请求type,判断要访问哪个接口
- 3,4,将请求体进行反序列化
- 5,发起请求,调用feign。
代码如何使用
具体的代码,我放在了:
https://gitee.com/ckl111/all-simple-demo-in-work-1/tree/master/blockingqueue-consumer-producer
建表语句:
服务提供者A的访问入口:
curl -i -X POST \
-H "Content-Type:application/json" \
-d \
'{
"userName": "zhangsan",
"password":"123"
}' \
'http://localhost:8082/login'
服务消费者的application.properties中:
failover.mode=true
这个为true时,就是故障转移模式,访问如下接口时,请求会落库
http://localhost:8081/login.do
为false的话,就会直接进行feign调用。
代码中的bug
其实这个代码是有bug的,因为我们是定时线程,假设每隔30s执行,那假设我一开始取了10条出来,假设全部放到队列了,阻塞队列此时有10条,假设worker处理特别慢,30s内也没执行完的话,定时线程会再次取出状态没更新的那个任务,又丢到队列里。
任务就被重复消费了。
大家可以想想怎么处理这个问题,通过这个bug,我也发现,blockingqueue是一种比较彻底的解耦方式,但是,我们这里的业务,解耦了吗,如果业务不是解耦的,用这个方式,其实是有点问题。
过两天我再更新这部分的方案,生产者和消费者,这里还是需要通信的,才能避免任务重复消费的问题。
总结
要实现一个本地消息表最终一致性方案,有一定开发量,而且我这里,消费过程中,强行引入了多线程和生产者、消费者模式,增加了部分复杂度。
不过,代码不就是要多折腾吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号