没有 GPU,还能跑大模型吗?vLLM vs llama.cpp 实测对比
没有 GPU,还能跑大模型吗?vLLM vs llama.cpp 实测对比
在没有 GPU 的情况下,大模型还能不能“真正可用”?本文基于 GPUStack,对 vLLM-CPU 与 llama.cpp 进行完整实测,对比两者在纯 CPU 环境下的部署方式、推理性能、高并发表现与实际适用场景。
关注🌟⌈GPUStack⌋ 💻
一起学习 AI、GPU 管理与大模型相关技术实践。
当大家讨论大模型部署时,焦点通常都集中在 GPU、显存和多卡集群上。但在很多实际场景里,用户真正拥有的,可能只有一台普通 CPU 机器。
而随着近两年模型持续进化,小模型的实际能力也在快速提升:不仅文本模型效果越来越强,多模态模型也开始逐渐向端侧与低资源环境演进。不少轻量级模型即使仅依赖 CPU,也已经能够完成本地开发、Demo 演示以及基础推理等任务,这让“纯 CPU 跑大模型”开始从“能跑”逐渐走向“可用”。
vLLM 从 v0.16.0 开始正式提供预编译的 CPU Docker 镜像,镜像名为:
vllm/vllm-openai-cpu
这意味着,vLLM 除了 GPU 推理之外,也开始支持更加开箱即用的纯 CPU 部署方式。
而另一边,长期以来被广泛用于 CPU 推理的 llama.cpp,则凭借 GGUF、量化模型以及较低的资源占用,已经成为本地推理领域的“常驻选手”。
那么问题来了:
同样是在纯 CPU 环境下,vLLM 和 llama.cpp 的实际表现究竟如何?
这篇文章将基于 GPUStack 进行完整实测,对比两者在 CPU 场景下的部署与推理表现。
测试环境使用三台同规格服务器,配置均为 4 vCPU + 16GB 内存。其中:
- 1 台作为 GPUStack Server
- 1 台用于部署 vLLM-CPU
- 1 台用于部署 llama.cpp
两组测试分别运行在独立 Worker 节点上,尽量减少相互干扰带来的性能影响。
全文分为以下几个部分:
- 安装 GPUStack,并初始化集群
- 添加 vLLM-CPU 自定义后端
- 部署模型并测试
- 启用 llama.cpp 社区后端
- 部署 GGUF 模型并测试
- 更多模型实测
- 高性能 CPU 环境实测
- 压测结果分析
- 小结
安装 GPUStack,并初始化集群
在开始测试之前,需要先完成 GPUStack 的安装与集群初始化。
考虑到这部分内容此前已经进行过较为完整的介绍,这里不再重复展开。如果你是第一次接触 GPUStack,可以先阅读下面这篇安装教程:
<这里留空,会插入公众号已发表的文章-GPUStack v2.1.2 安装教程>
添加纯 CPU Worker 节点
前文演示的是 NVIDIA GPU 节点的添加流程,而本文主要测试纯 CPU 推理,因此这里额外介绍如何实际添加一个 CPU Worker 节点。
示例命令如下:
docker run -d --name gpustack-worker \
-e "GPUSTACK_RUNTIME_DEPLOY_MIRRORED_NAME=gpustack-worker" \
-e "GPUSTACK_TOKEN=gpustack_8a9deabfdce64e0b_d5394d64567d6a304eaaa8d627e494db" \
--restart=unless-stopped \
--privileged \
--network=host \
--volume /var/run/docker.sock:/var/run/docker.sock \
--volume gpustack-data:/var/lib/gpustack \
gpustack/gpustack:v2.1.2 \
--server-url http://100.109.241.71 \
--worker-ip 100.101.65.74
与 GPU 节点不同,这里省略了
--runtime参数。
命令中的关键参数说明如下,可根据实际环境进行调整:
GPUSTACK_TOKEN:Worker 与 Server 之间的认证 Token,可在 UI 中生成添加 Worker 的命令时获取。--server-url:GPUStack Server 服务地址。--worker-ip:Server 与 Worker 通信的 IP 地址。如果机器有多个网卡,或者默认 IP 不是期望值,需要手动指定。
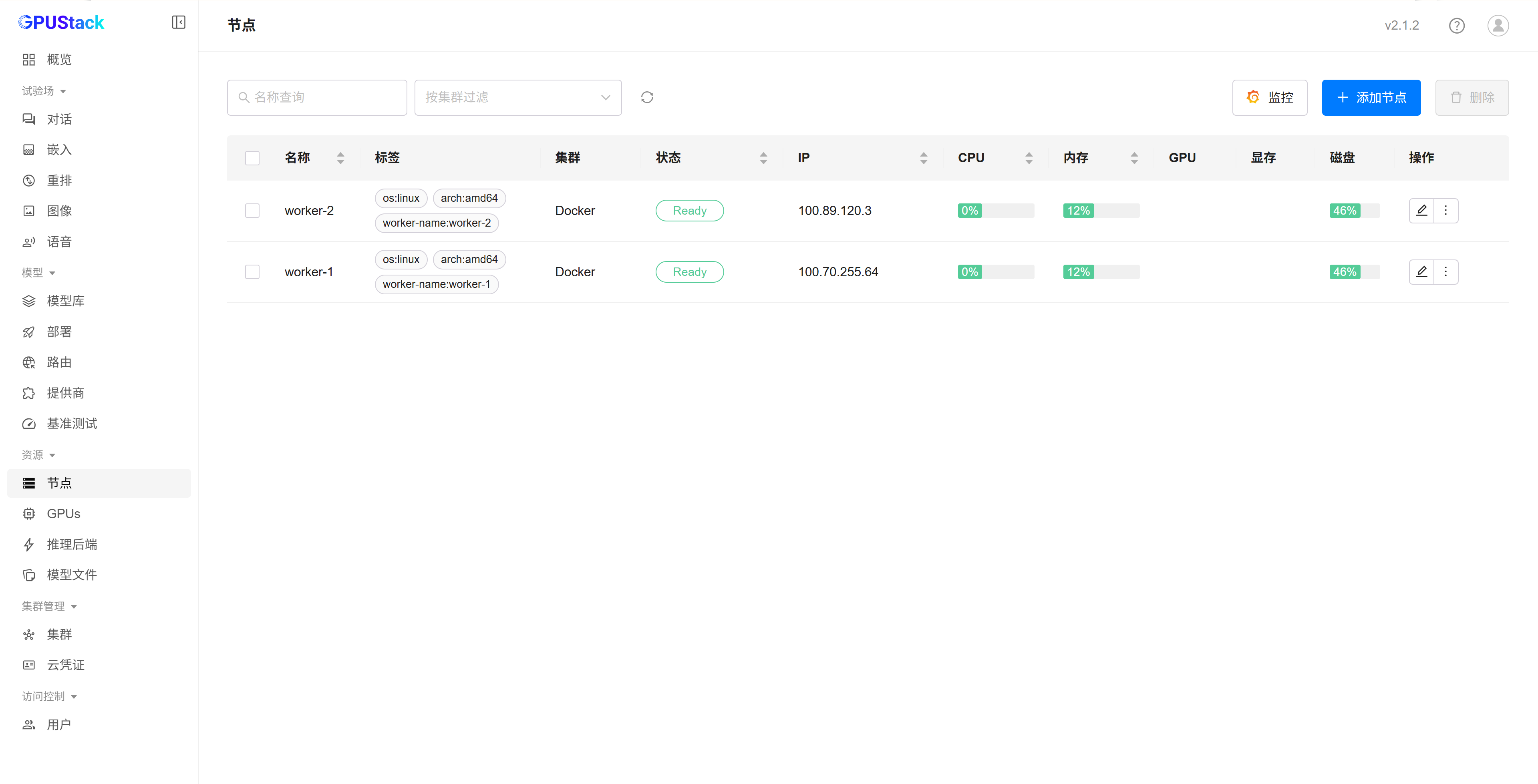
节点添加完成后,可在 GPUStack 控制台查看对应 Worker 是否已成功上线:
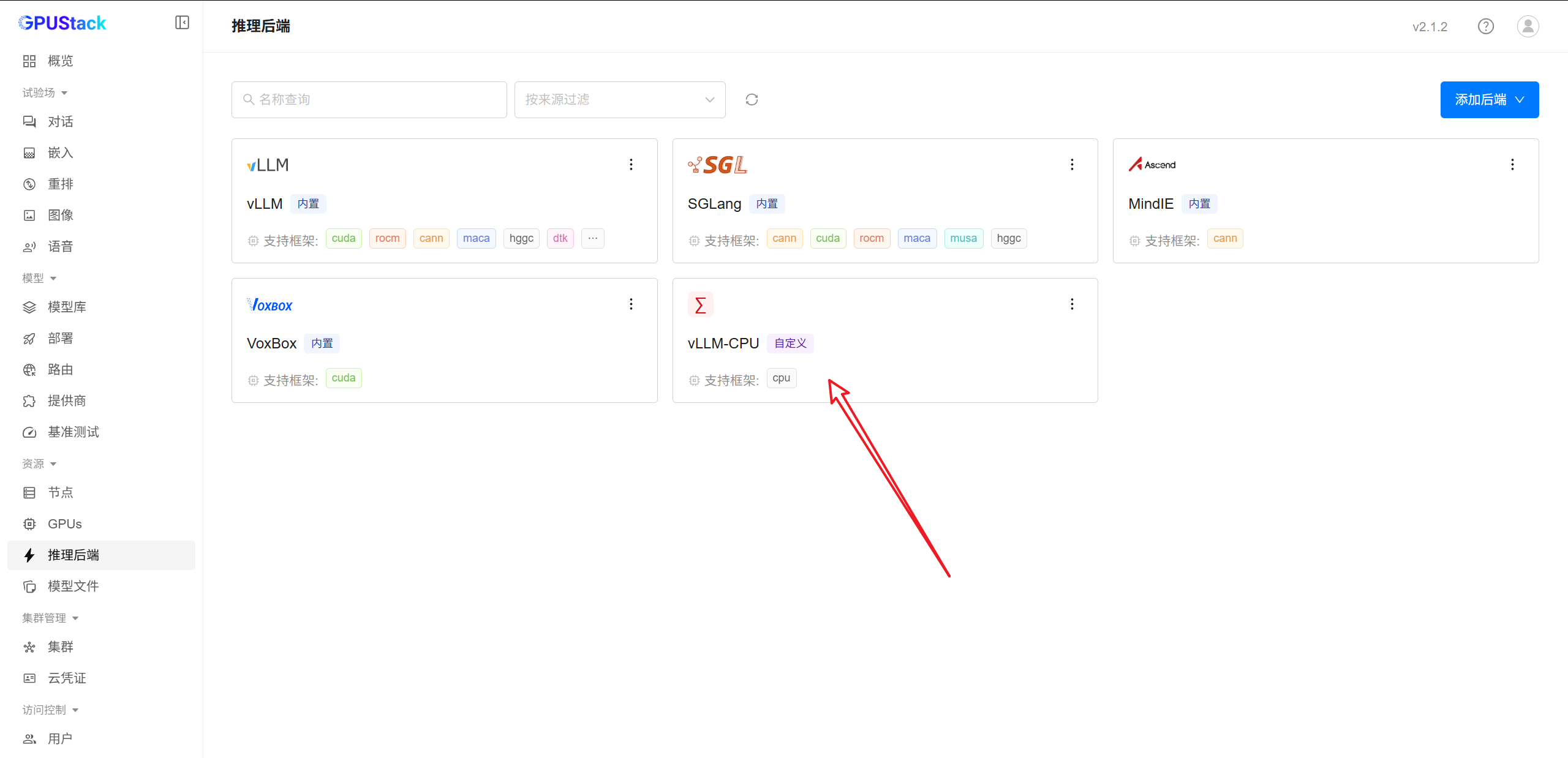
添加 vLLM-CPU 自定义后端
目前 GPUStack 默认提供的是 GPU 版本 vLLM,因此这里需要手动添加 CPU 版本后端。
暂不支持直接在内置 vLLM 后端中通过添加自定义版本实现,这会导致模型部署 Pending。
进入 GPUStack 控制台(Web UI)后,在左侧边栏中导航到推理后端:
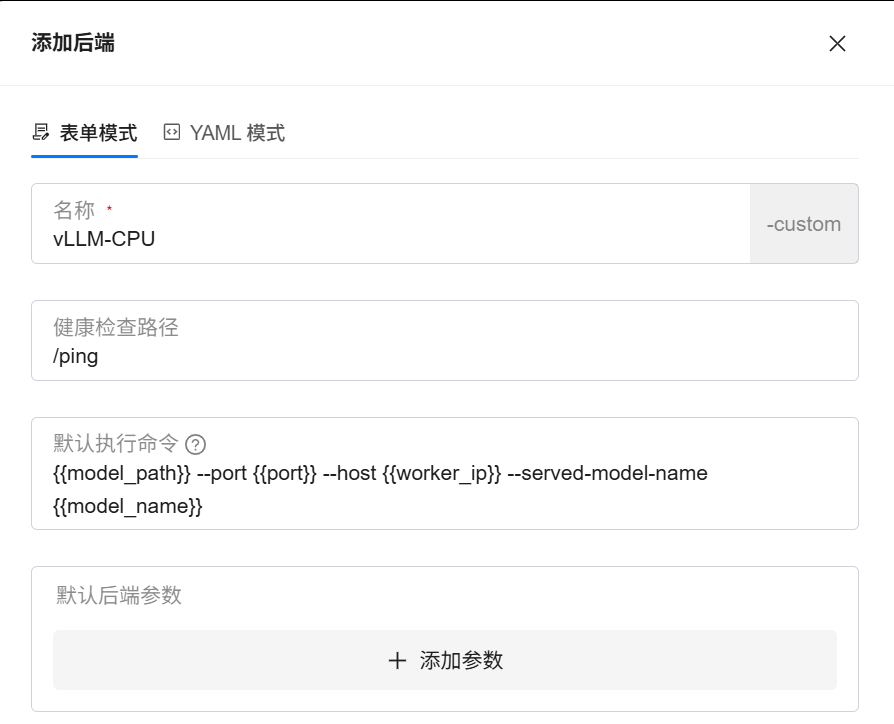
按下图所示填写配置:
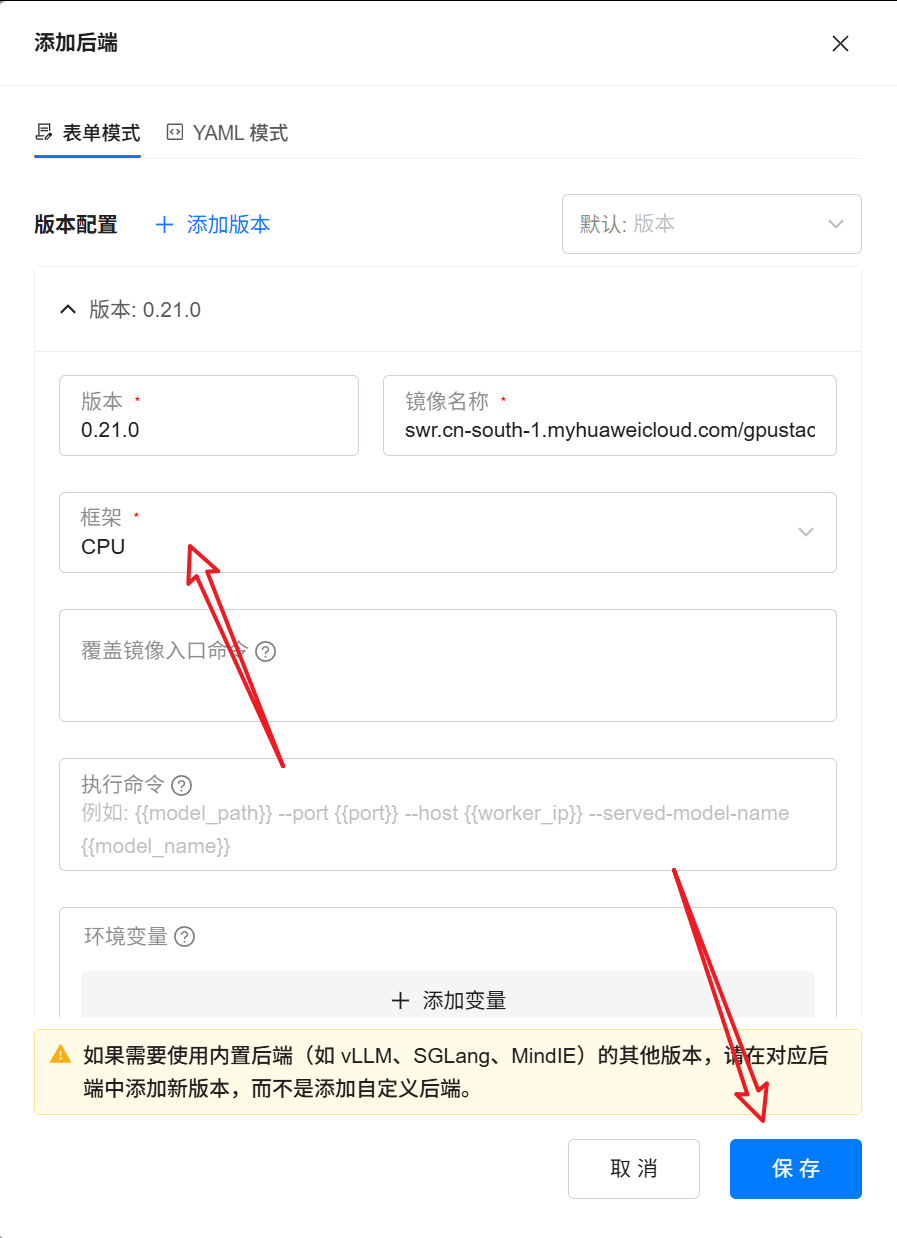
或者使用 YAML模式,填入以下内容:
backend_name: vLLM-CPU-custom
health_check_path: /ping
default_run_command: "{{model_path}} --port {{port}} --host {{worker_ip}} --served-model-name {{model_name}}"
version_configs:
0.21.0:
image_name: swr.cn-south-1.myhuaweicloud.com/gpustack/vllm-openai-cpu:v0.21.0
custom_framework: cpu
从微信公众号复制出的内容可能包含特殊符号,可直接使用我们准备好的 yaml 文件:https://gpustack-cn-blogs.oss-cn-shanghai.aliyuncs.com/assets/cpu/vllm-cpu.yml
实际配置使用的国内镜像,vLLM 官方原版镜像地址为:
vllm/vllm-openai-cpu:v0.21.0
添加完成后,效果如图所示:
部署模型并测试
这里我们选择最近发布的 openbmb/MiniCPM5-1B 作为测试模型。
作为一款 1B 级别的小模型,MiniCPM5-1B 在轻量化场景下表现较为突出,近期一直位于 Hugging Face 热门模型榜单前列,因此比较适合作为本次纯 CPU 推理测试对象。
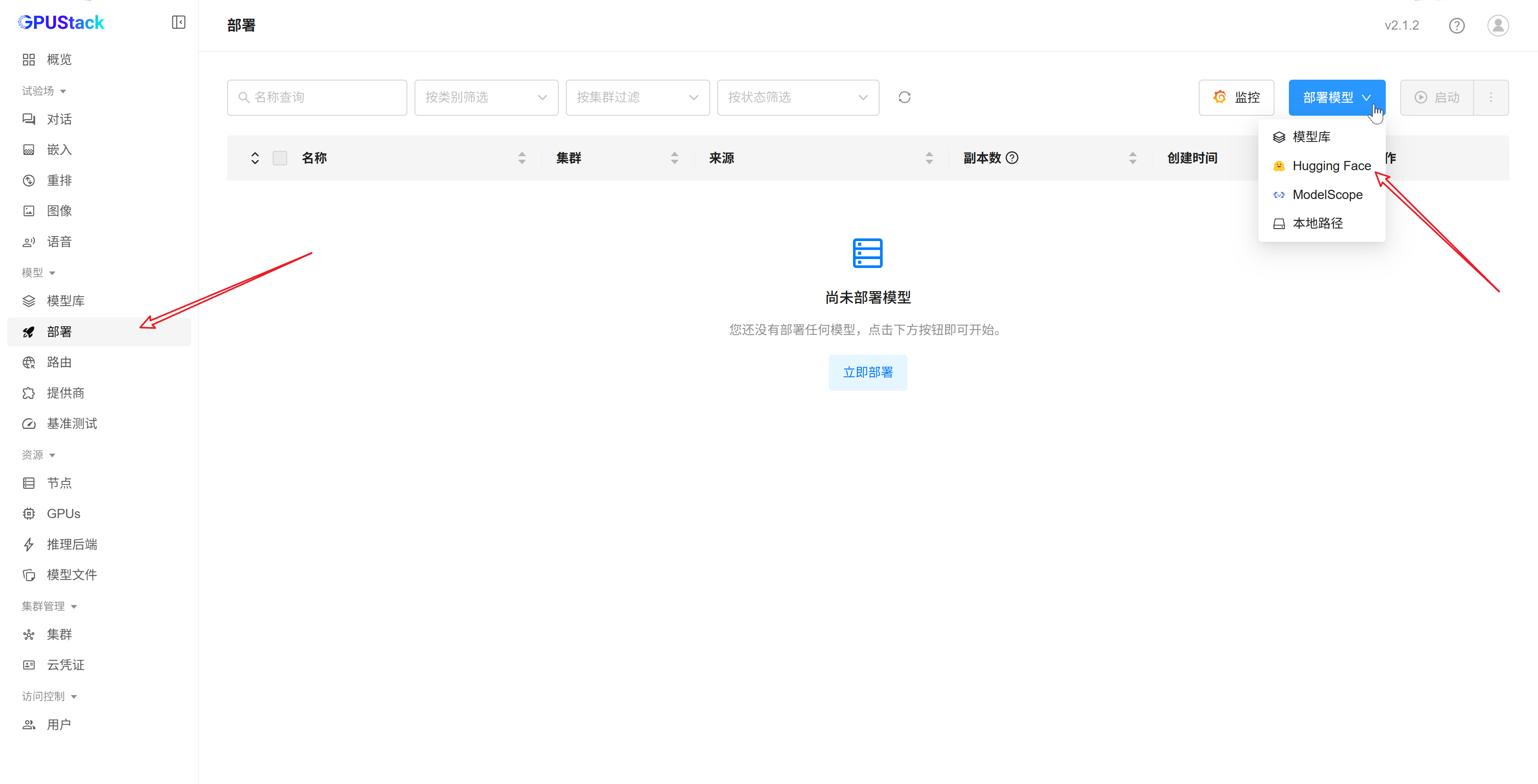
打开 部署 页面,在右上角 部署模型 菜单中选择 Hugging Face 或 ModelScope:
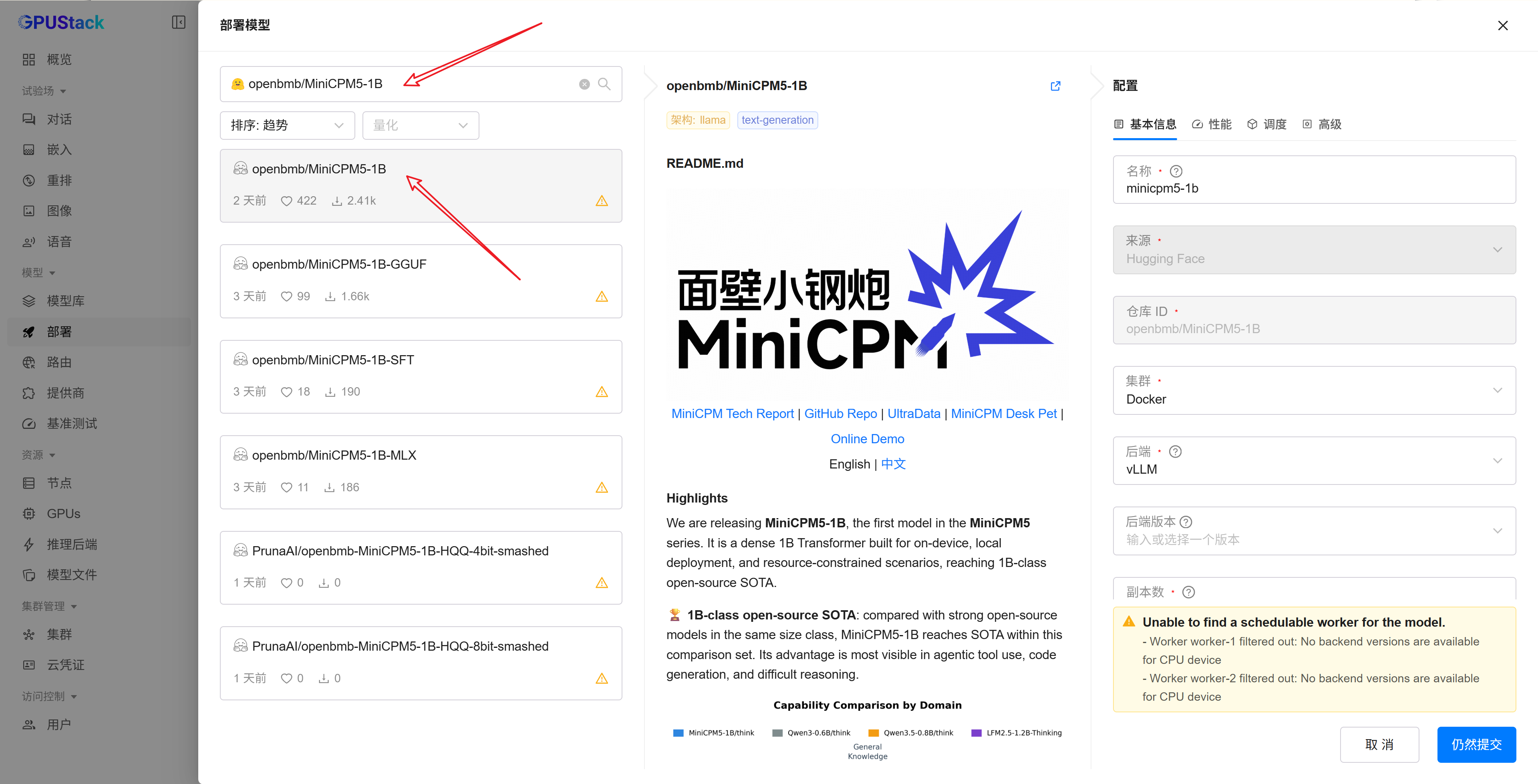
随后在弹出的模型窗口中搜索:
openbmb/MiniCPM5-1B
调整部署参数
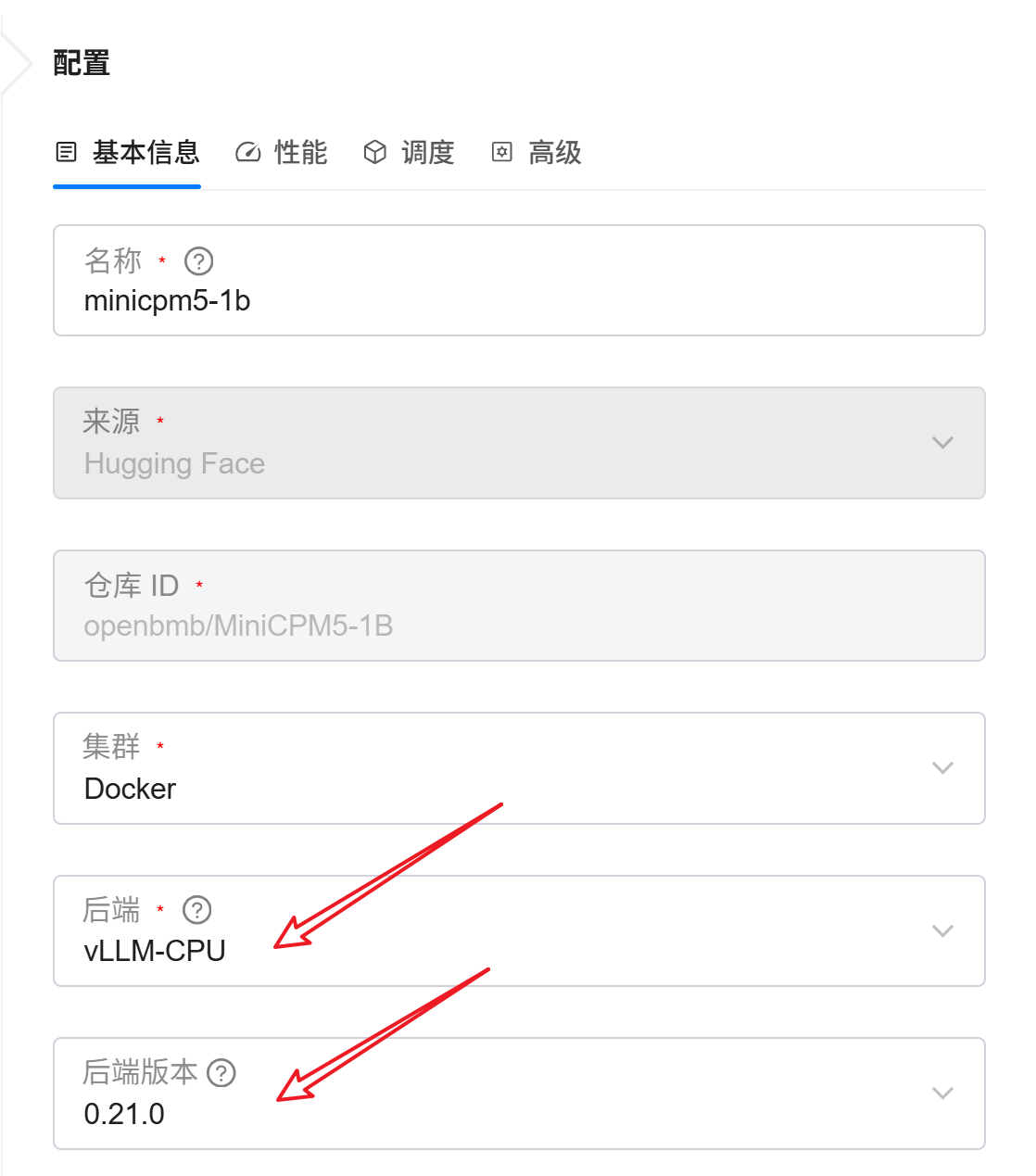
1. 调整推理引擎
将推理后端切换为前面创建的:
vLLM-CPU
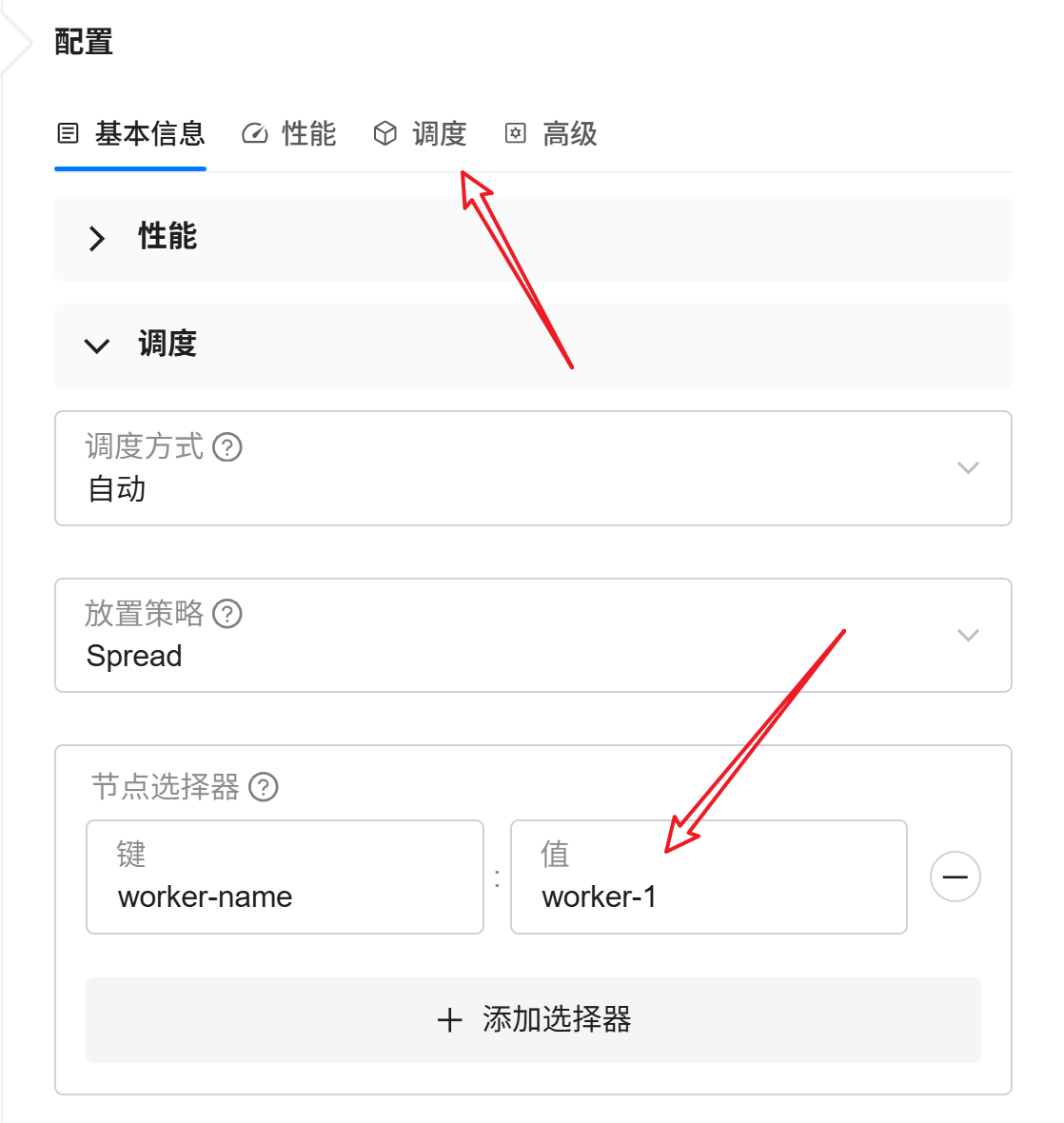
2. 绑定调度节点
由于本文分别使用独立 Worker 节点测试 vLLM 与 llama.cpp,因此这里需要手动绑定对应 Worker。
3. 调整启动参数与环境变量
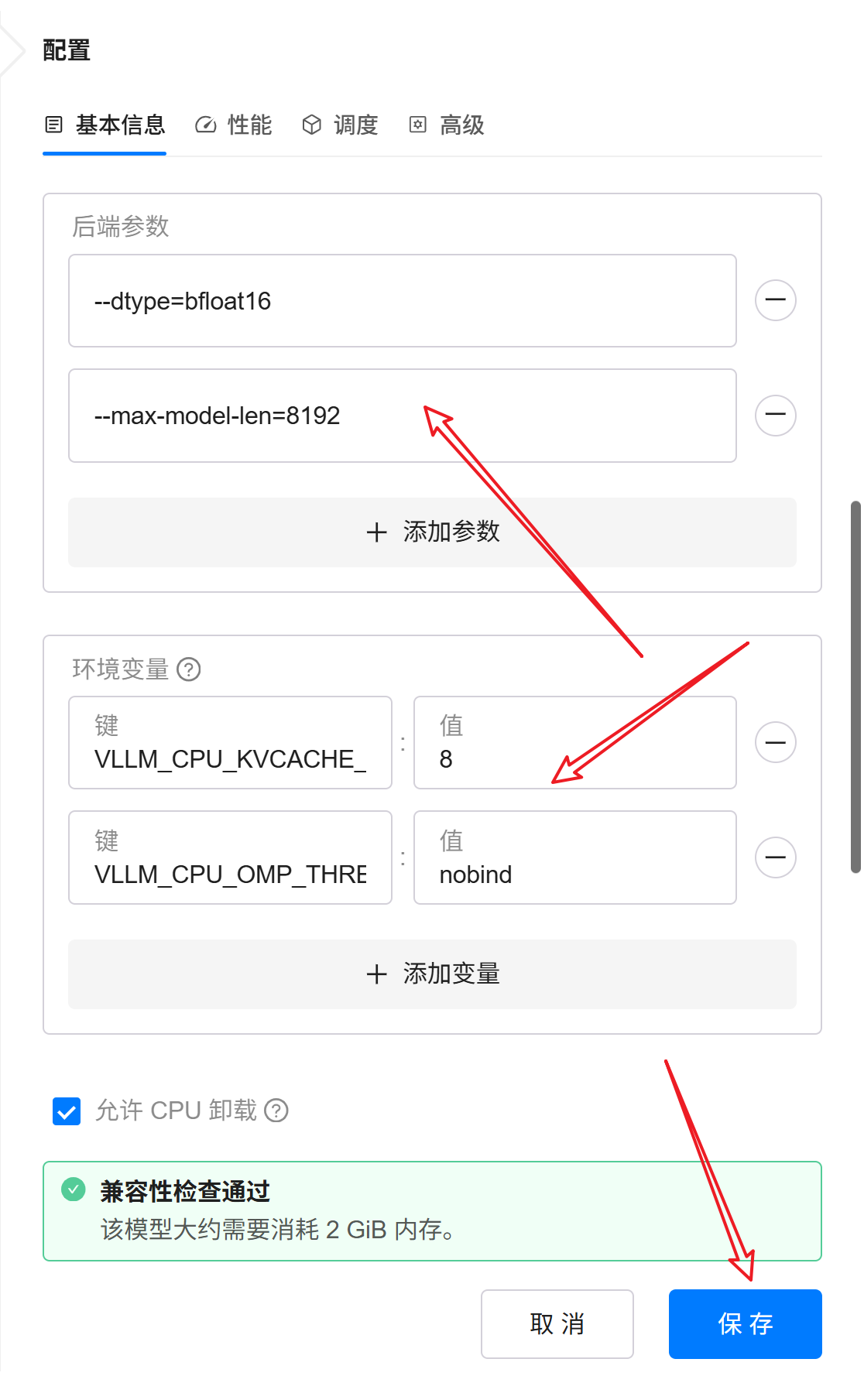
这里使用的关键参数如下:
-
--dtype=bfloat16由于 PyTorch CPU 对
float16的支持并不稳定,因此这里显式指定bfloat16,避免出现性能异常或精度问题。 -
--max-model-len=8192本次测试机器配置较低,因此这里适当降低上下文长度,减少内存压力。后续 llama.cpp 测试中也会保持一致,以尽量保证测试条件统一。
-
VLLM_CPU_KVCACHE_SPACE=8指定 CPU KV Cache 可使用容量,单位为 GB。这里设置为
8,表示允许 vLLM 使用约 8GB 内存作为 KV Cache。 -
VLLM_CPU_OMP_THREADS_BIND=nobind禁用 OpenMP 线程绑定到固定 CPU 核心,实际测试中通常能够提高 CPU 利用率,并减少部分场景下的线程调度限制。
更多配置选项请访问 vLLM CPU 官方文档:https://docs.vllm.ai/en/stable/getting_started/installation/cpu/
参数配置完成后,点击保存按钮即可开始部署模型。
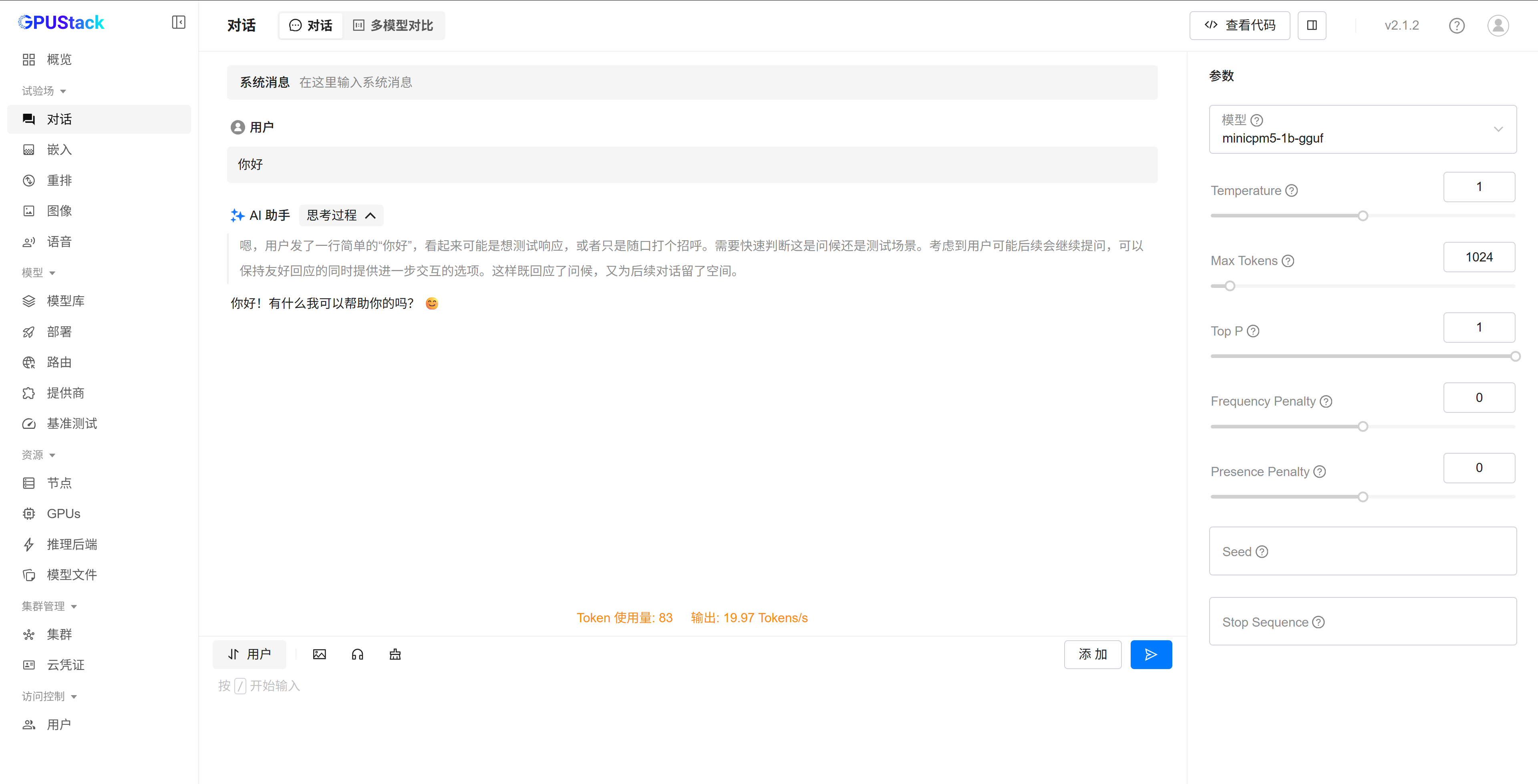
试验场测试
测试时的系统资源检测情况:
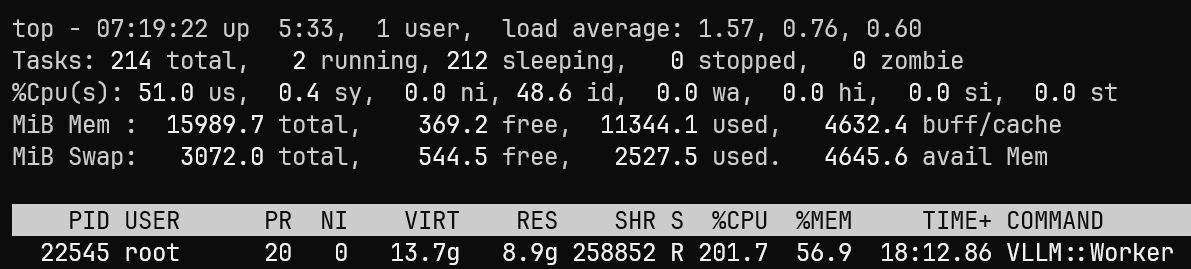
启用 llama.cpp 社区后端
相比 vLLM,llama.cpp 在 CPU 推理领域已经发展多年。
其核心特点包括:
- 原生 CPU 优化
- GGUF 量化生态成熟
- 内存占用较低
- 非常适合边缘设备
- 模型服务启动迅速
GPUStack 社区后端已经支持 llama.cpp,因此这里只需要启用即可。
部署 GGUF 模型
接下来部署 GGUF 格式的 MiniCPM5-1B 模型:
openbmb/MiniCPM5-1B-GGUF
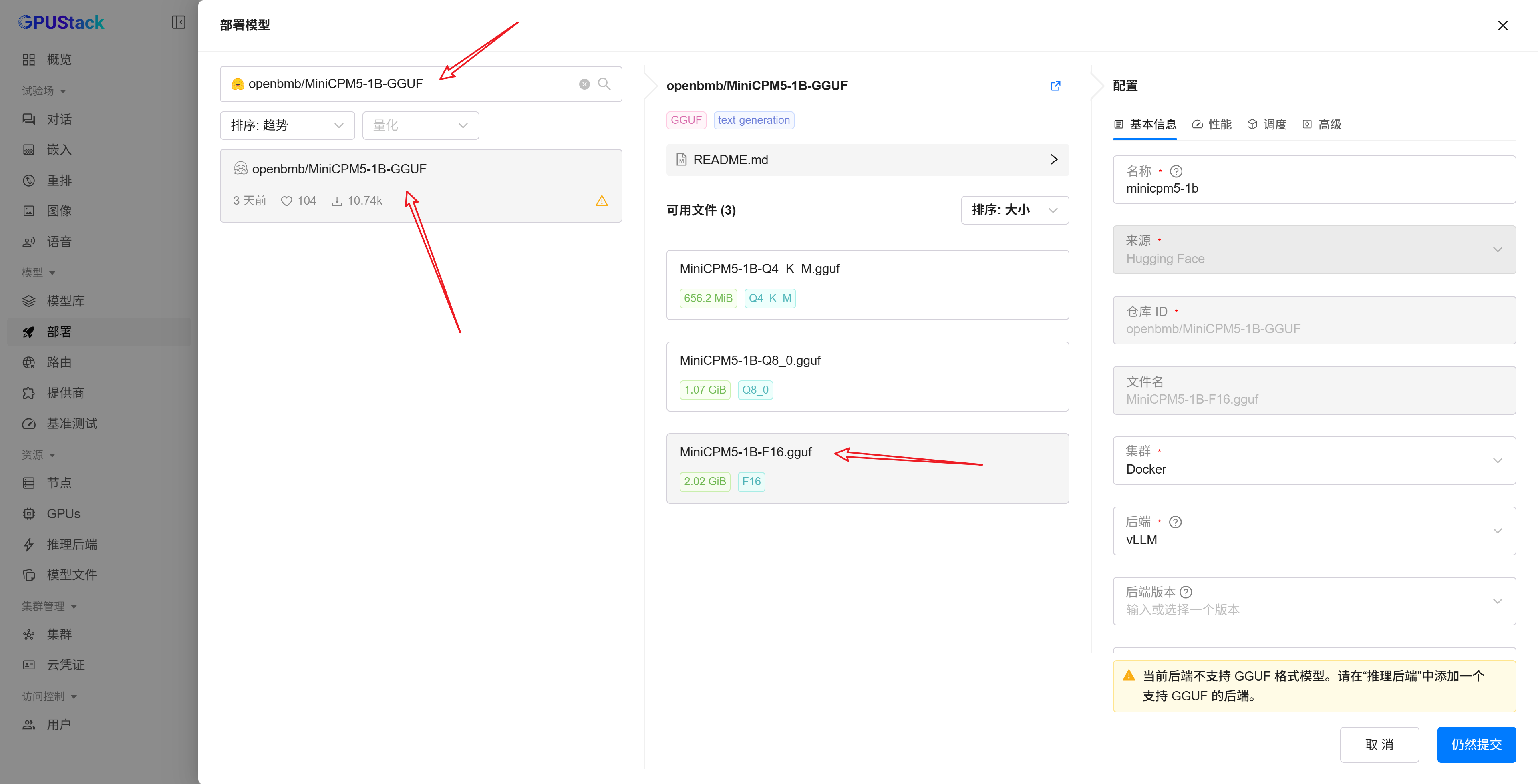
为了尽量保证测试条件一致,这里选择与 vLLM-CPU 相同规格的
MiniCPM5-1B-F16.gguf,而没有使用更小体积的量化版本。
调整部署参数
1. 调整推理引擎
将推理后端切换为:
llama.cpp
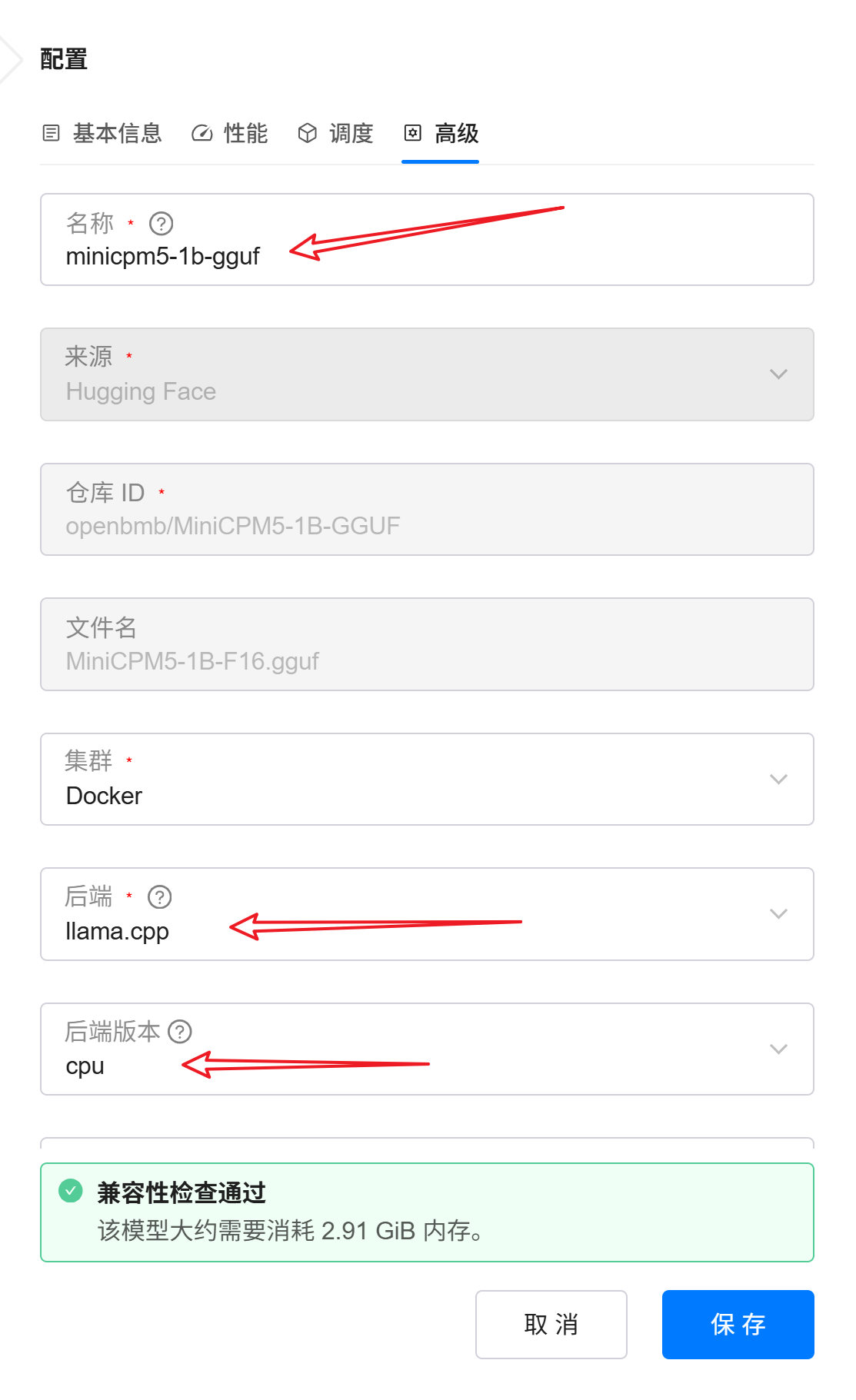
2. 绑定调度节点
这里同样绑定到独立 CPU Worker 节点,避免与 vLLM 测试环境互相影响。
3. 调整启动参数与环境变量
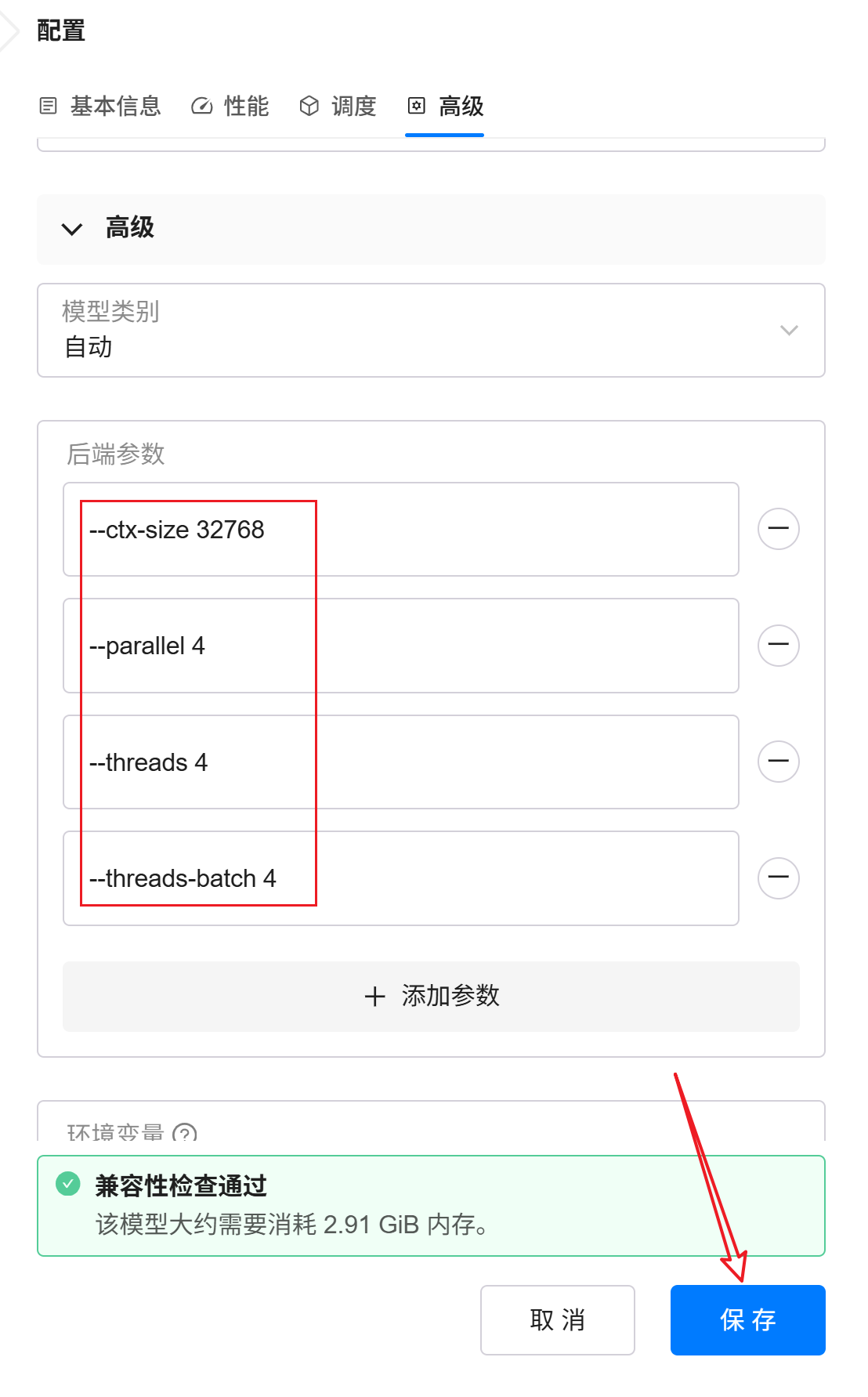
本文测试使用的核心参数如下:
-
--ctx-size 32768设置 KV Cache 可用的总上下文容量。由于本文测试中
--parallel设置为4,因此这里将总上下文设置为32768,相当于为每个并发请求预留约8192上下文长度,以尽量与 vLLM-CPU 测试中的--max-model-len=8192保持一致。
注意:llama.cpp 的
--ctx-size并不是为每个并发请求严格独立分配的,更接近于多个请求共享同一块 KV Cache 容量。
-
--parallel 4设置并行请求槽位数量为
4,允许 llama.cpp 同时处理多个请求。 -
--threads 4设置生成阶段使用的 CPU 线程数。当前测试机器为
2C4T,因此这里直接使用全部逻辑线程。 -
--threads-batch 4设置 Batch 处理阶段线程数,与
--threads保持一致。
更多配置选项请访问 llama.cpp 官方文档:https://github.com/ggml-org/llama.cpp/blob/master/tools/server/README.md
参数配置完成后,点击 保存 即可开始部署模型。
试验场测试 GGUF 模型
测试时的系统资源检测情况:
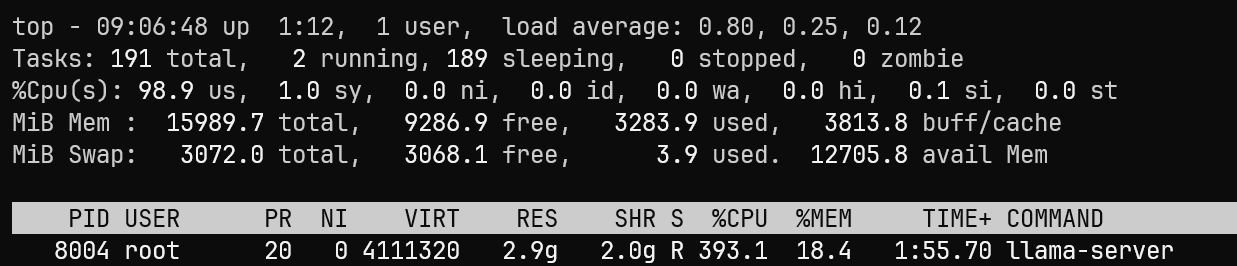
从 CPU 占用情况来看,llama.cpp 基本能够持续占满全部逻辑核心,整体 CPU 利用率相比 vLLM-CPU 更高。
更多模型实测
除了 MiniCPM5-1B 之外,这里也额外测试了几个较为热门的小模型,用于观察不同模型在纯 CPU 环境下的实际表现。
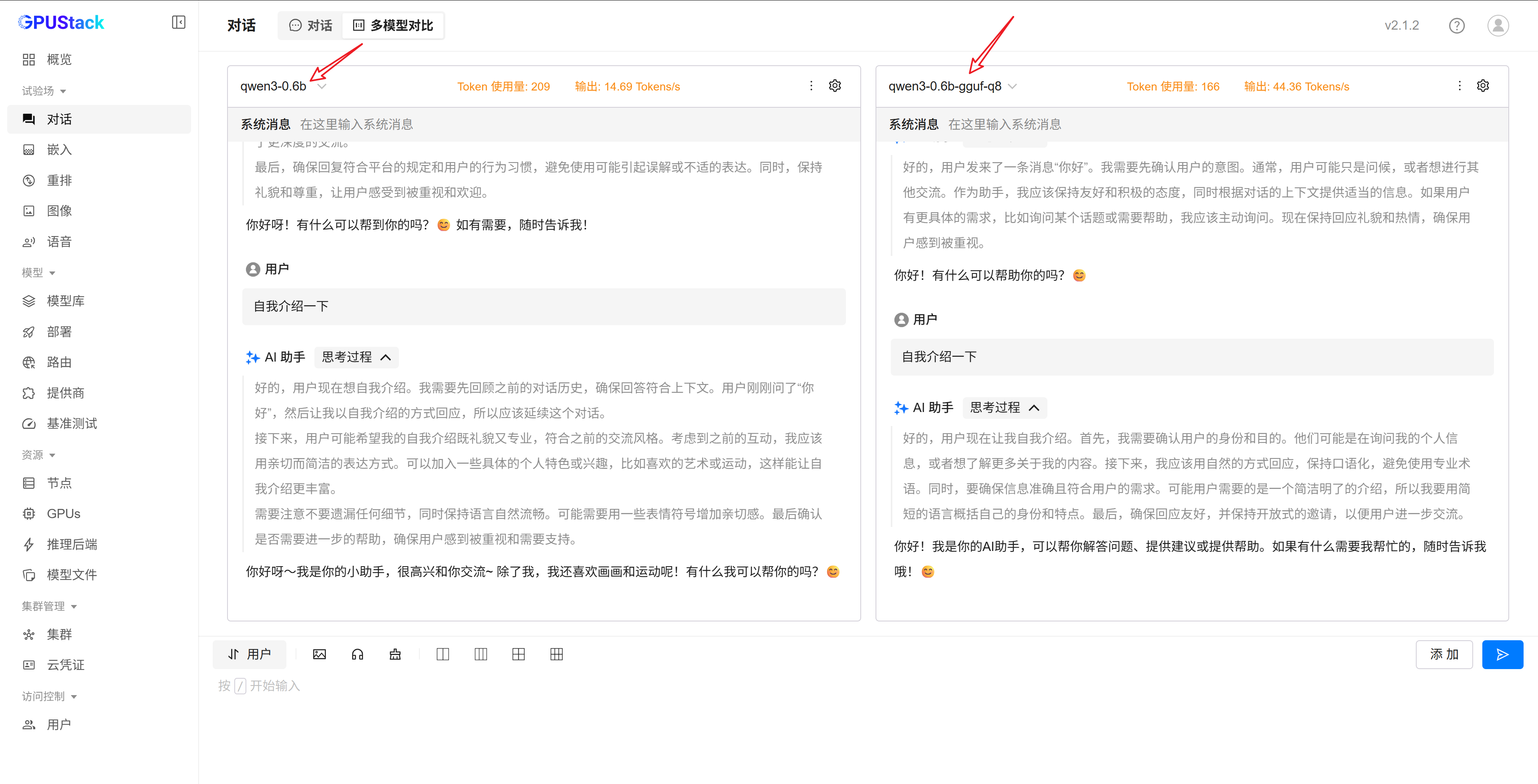
Qwen3-0.6B & Qwen3-0.6B-GGUF
Qwen3.5-0.8B & Qwen3.5-0.8B-GGUF
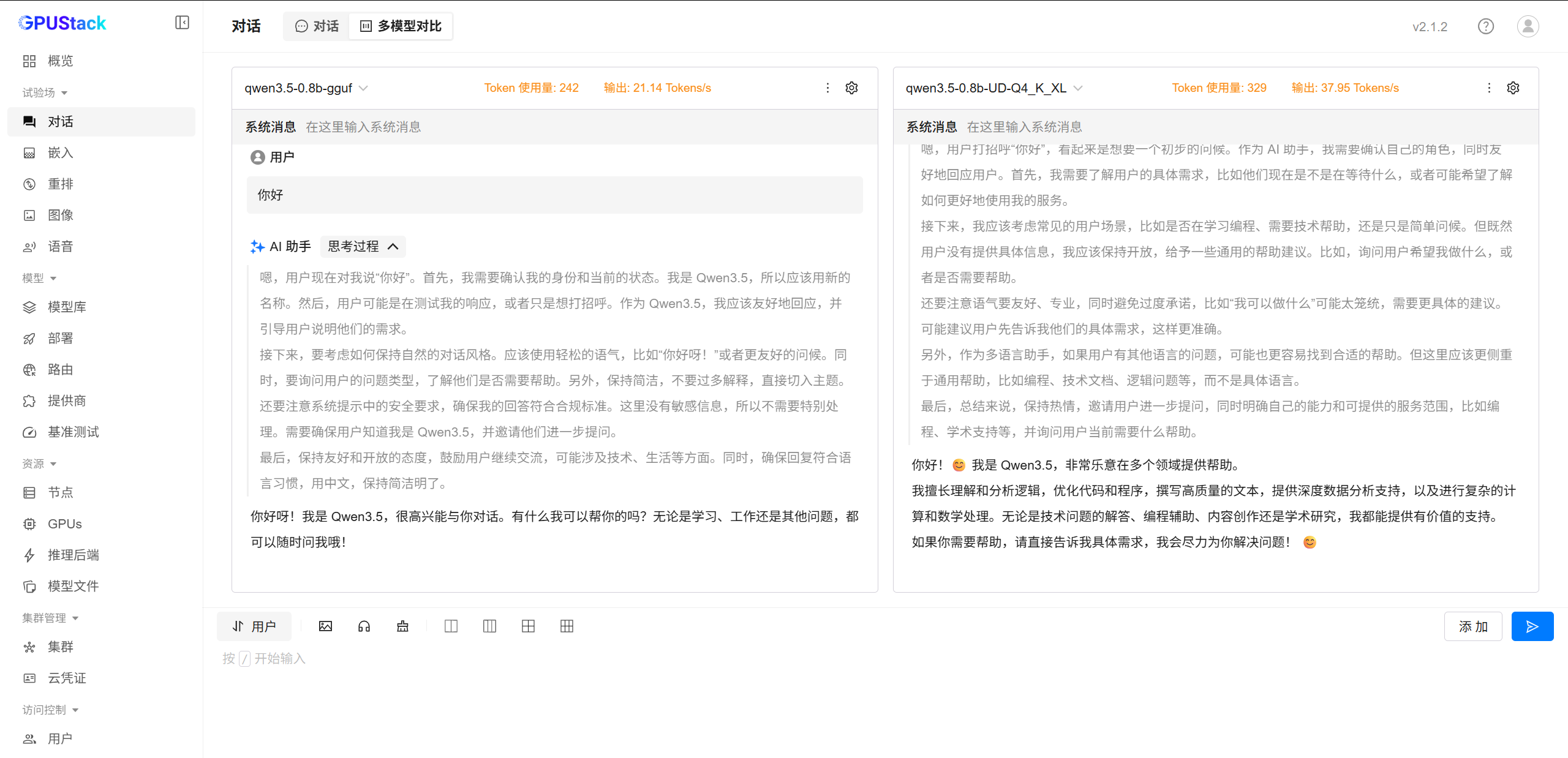
本轮测试中,vLLM-CPU 在当前
2C4T + 16GB测试环境下未能成功启动Qwen3.5-0.8B。后续切换到本地配置更高的测试机器后,模型可以正常运行。从实际体验来看,vLLM-CPU 对 CPU 核数、内存容量以及整体资源余量相对更加敏感,在资源更充足的环境中运行会更加稳定。
gemma-4-E2B-it-GGUF
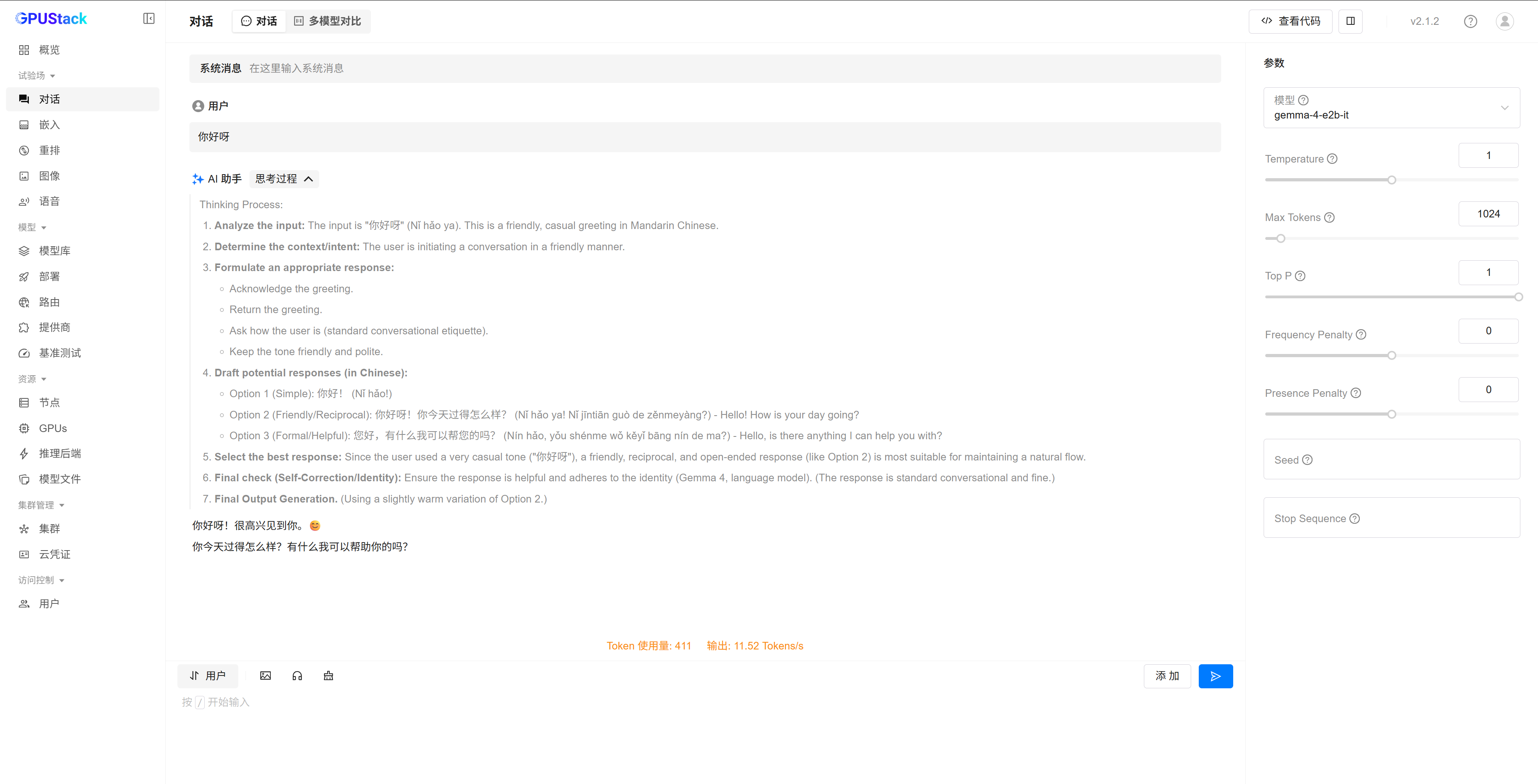
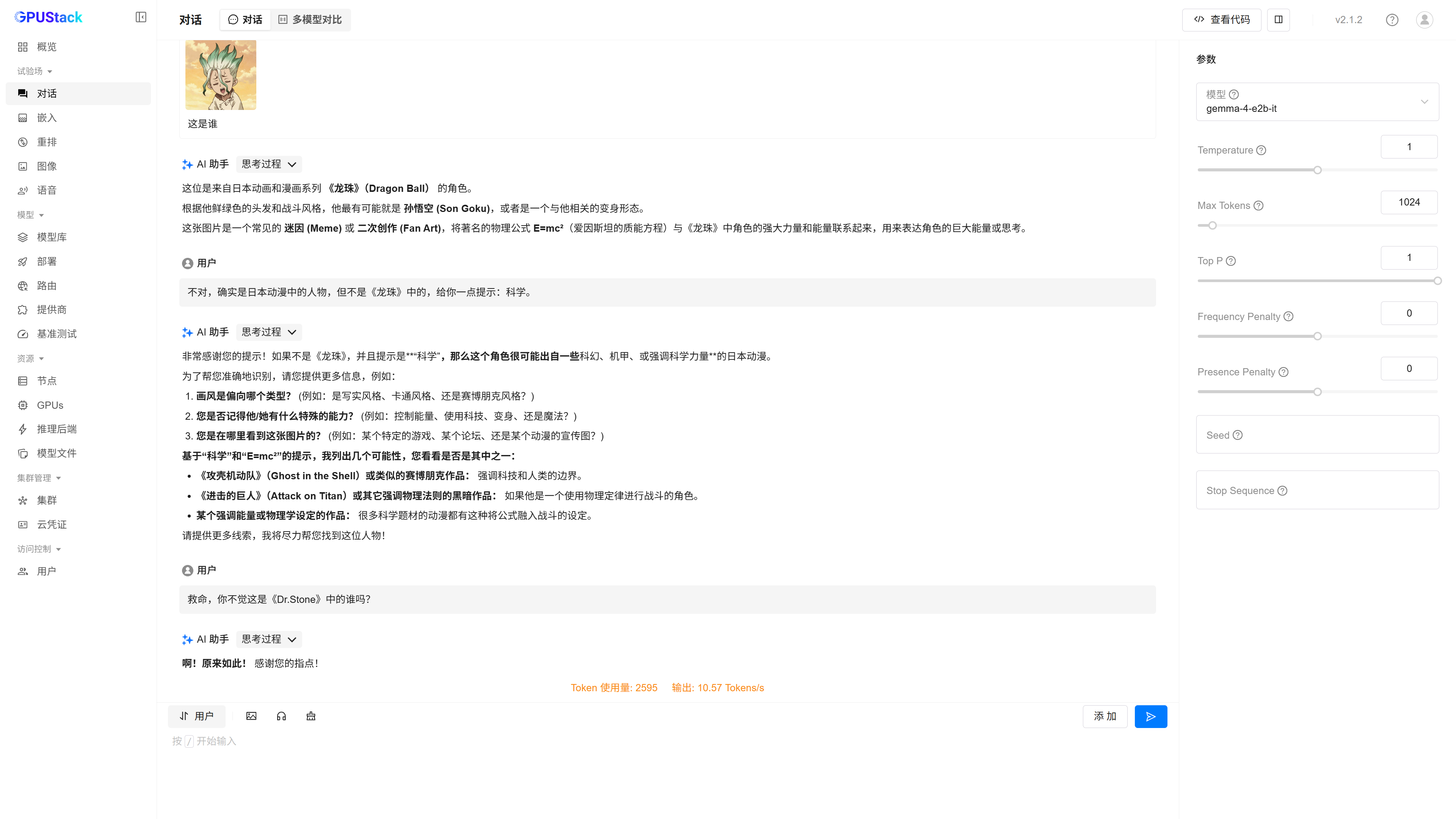
高性能 CPU 环境实测
为了观察纯 CPU 推理在更充足资源下的表现,我们将测试环境升级为:
- CPU:AMD EPYC Genoa 32 vCPUs
- 内存:128 GiB
- 操作系统:Ubuntu 24.04 LTS
- 特性支持:AVX-512F 指令集
相较于之前的 2C4T + 16GB 环境,这套高性能环境能够充分发挥 CPU 并行能力,同时支持高级向量化指令,对 vLLM-CPU 和 llama.cpp 的推理性能都有一定提升。
本次测试以 Qwen3-0.6B 模型为对象,分别在 vLLM-CPU 与 llama.cpp 后端上进行部署和实测。
部署方式与前文一致,只是在 CPU 资源配置上充分利用新机器:
- vLLM-CPU:自动调度多线程,充分利用全部 32 逻辑核心,并启用 AVX-512F 优化
- llama.cpp:设置
--threads 32,--parallel 32,以及--ctx-size按并发总和调整,以保证 KV Cache 足够
通过这样的配置,可以观察到两者在高并发、多核心环境下的真实吞吐能力。
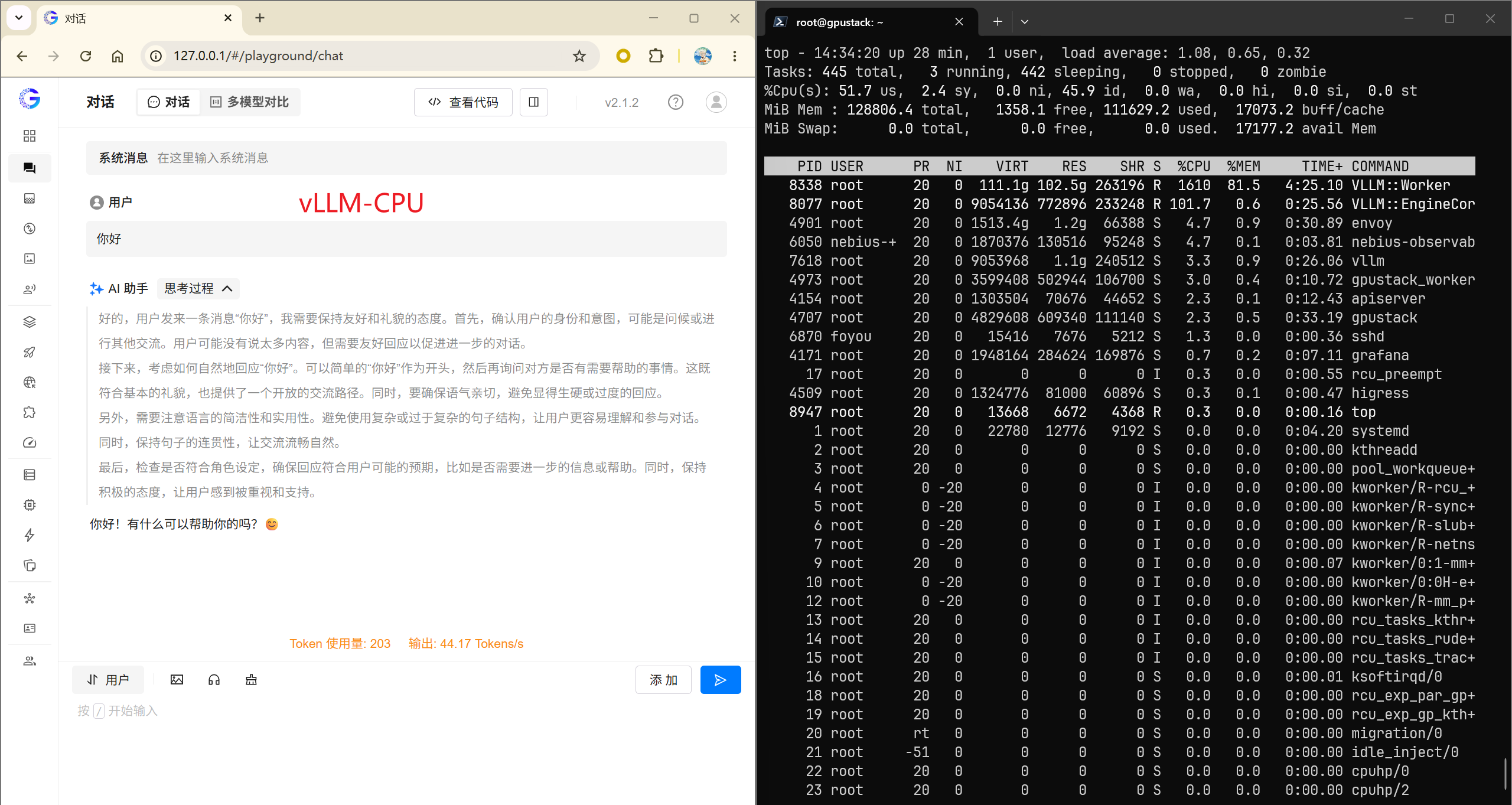
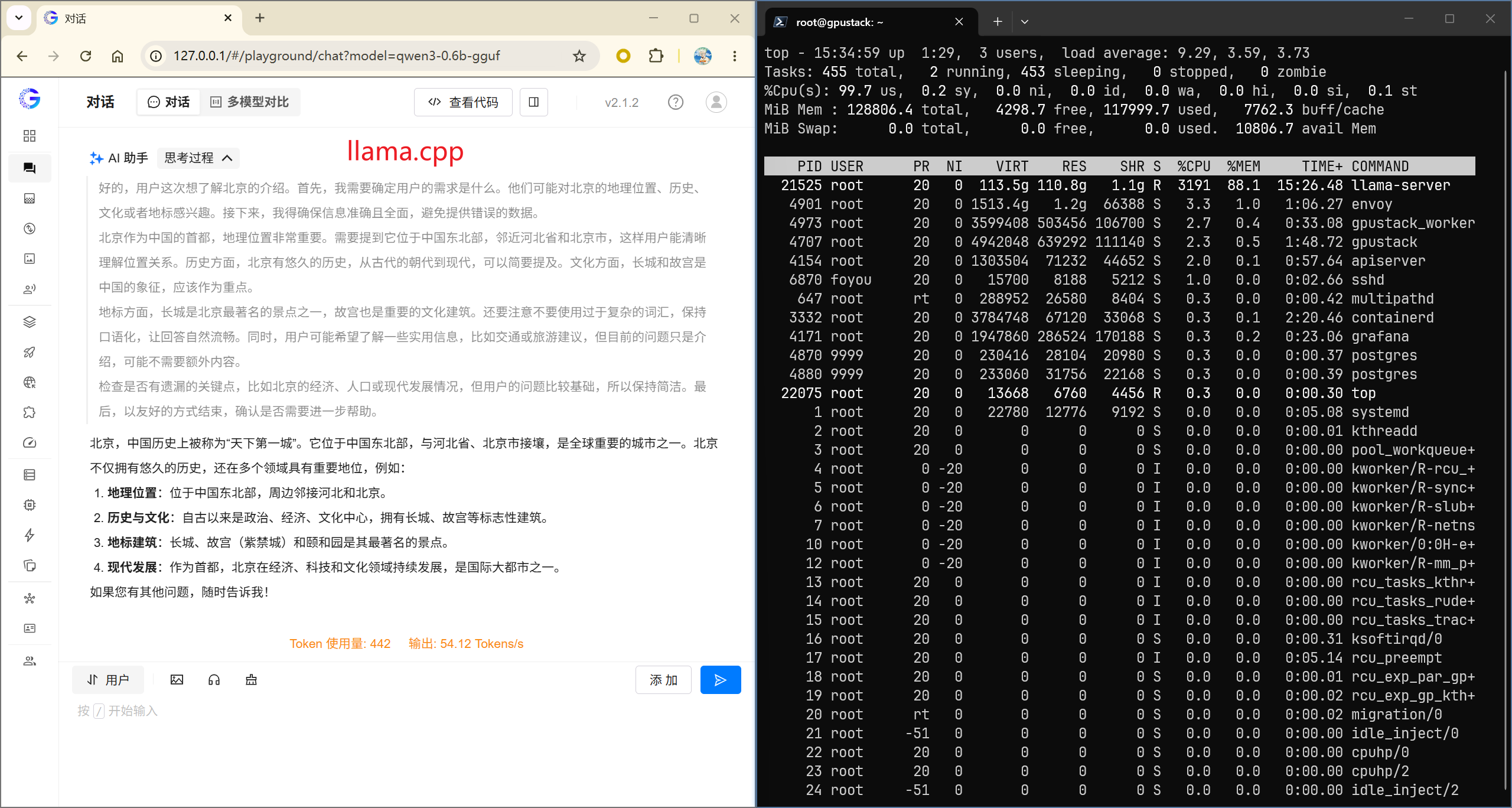
实测图显示,vLLM-CPU 的利用率仅为一半。这是 vLLM 为保障推理性能而采用的物理核绑定机制——通过规避超线程引发的 L1/L2 缓存竞争,确保底层矩阵运算的高效执行。
从上面的测试结果来看,llama.cpp 在单并发场景中依然占据一定优势。下面进一步来看高并发压测场景下的表现。
GPUStack 当前内置的基准测试功能暂不支持 llama.cpp 部署的 GGUF 模型实例,因此这里统一使用 evalscope 进行压测,测试命令如下:
evalscope perf \
--url "http://10.96.0.98:40021/v1/chat/completions" \
--api openai \
--model "qwen3-0.6b" \
--tokenizer-path "Qwen/Qwen3-0.6B" \
--dataset random \
--min-prompt-length 1024 \
--max-prompt-length 1024 \
--max-tokens 128 \
--extra-args '{"ignore_eos": true}' \
--seed 42 \
--rate -1 \
--number 200
压测结果分析
压测参数保持一致:
- 并发:不限
- 输入长度:1024 tokens
- 输出长度:128 tokens
- 请求数:200
vLLM-CPU 测试结果
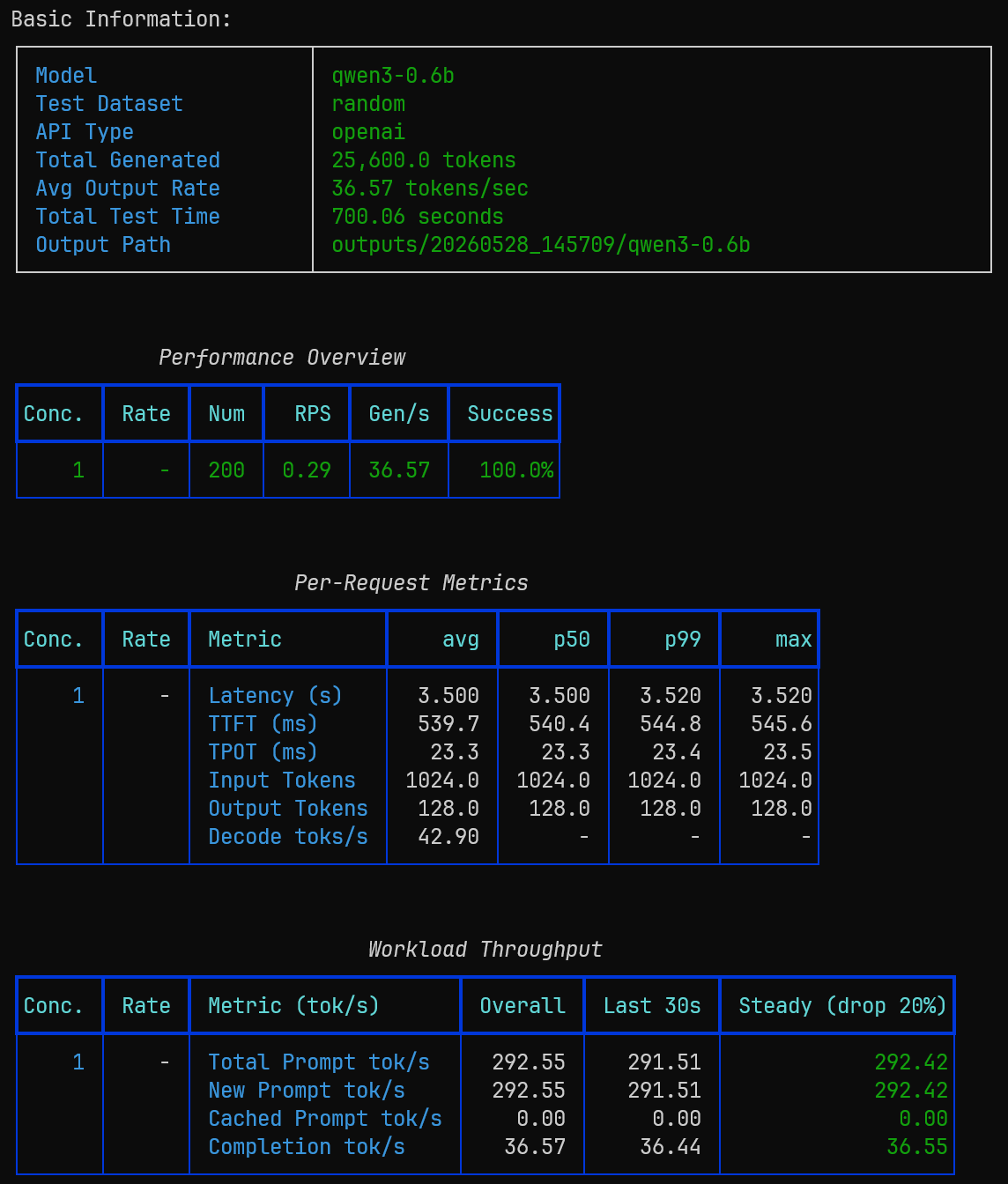
vLLM-CPU 在高性能 CPU 环境下能够稳定完成完整压测:
| 指标 | 数值 |
|---|---|
| Avg Output Rate | 36.57 tok/s |
| Decode toks/s | 42.90 tok/s |
| Avg Latency | 3.50s |
| TTFT | 539ms |
| TPOT | 23.3ms |
| Success Rate | 100% |
整体来看:
- 推理过程较稳定
- TTFT 控制在约
0.5s - 全程无失败请求
- CPU 利用率明显高于低配置环境
不过这里也有一个比较有意思的现象:
单并发实测中,vLLM-CPU 可以达到 40+ tok/s,但在长上下文压测场景下,整体吞吐反而下降到了约 36 tok/s。
这也说明,在纯 CPU 推理环境下:
- 长 Prompt Prefill 开销依然明显
- KV Cache 与内存带宽压力较大
- 高并发调度收益并不像 GPU 场景那样明显
尤其当前测试使用:
1024输入 tokens128输出 tokens
属于典型的长输入短输出场景,这类 workload 对 CPU 推理并不算友好。
相比前面的 2C4T 环境:
- CPU 资源瓶颈明显缓解
- 调度线程竞争减少
- vLLM 的 Continuous Batching 开始逐渐体现效果
llama.cpp 测试结果
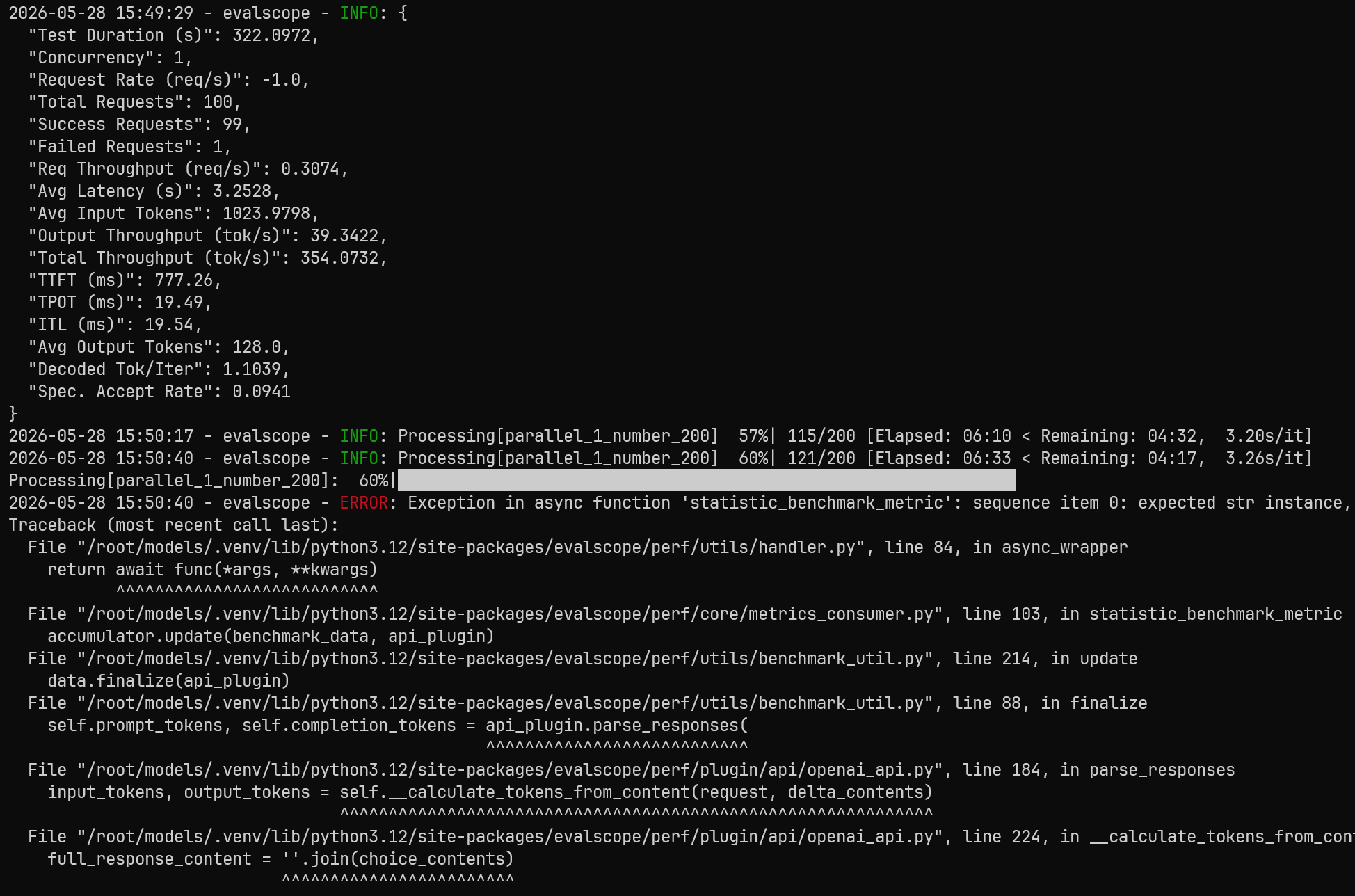
llama.cpp 在多次测试过程中均出现了异常中断,最终压测未能完整结束。
日志中主要出现了:
ServerDisconnectedError
以及:
TypeError: sequence item 0: expected str instance, NoneType found
不过虽然完整压测失败,中间阶段依然输出了部分有效数据:
| 指标 | 数值 |
|---|---|
| Output Throughput | 39.34 tok/s |
| Avg Latency | 3.25s |
| TTFT | 777ms |
| TPOT | 19.49ms |
| Success Requests | 99/100 |
从已有结果来看:
- llama.cpp 的 Decode 阶段速度依然略高
- TPOT 更低
- 平均延迟也略低
但与此同时:
- TTFT 明显高于 vLLM-CPU
- 长时间压测稳定性略差
- 与部分 OpenAI Benchmark 工具链仍存在兼容性问题
这里的异常更像是:
Benchmark 工具链与 llama.cpp OpenAI 接口之间的兼容性问题。
因为从中间日志来看:
- llama.cpp 实际仍在持续生成
- 推理吞吐没有明显异常
- 更像是流式响应中返回了空内容,导致 evalscope 统计失败
初步结论
在高性能 CPU 环境下,两者相比低配置环境都有明显提升。
整体来看:
| 项目 | vLLM-CPU | llama.cpp |
|---|---|---|
| 吞吐稳定性 | 更稳定 | 略有波动 |
| TTFT | 更低 | 略高 |
| Decode 速度 | 略低 | 略高 |
| 长时间压测 | 更稳定 | 存在兼容性异常 |
| OpenAI 兼容性 | 更完整 | 部分接口存在差异 |
| 多模态支持 | 原生支持较完善 | 需要额外配置 |
注意:文中提到的 TTFT(Time To First Token) 均为压测场景下的整体调度平均值。实际上,在单请求或低并发场景中,相同条件下的 llama.cpp 往往能够获得更低的 TTFT。
本文测试中出现的 “vLLM-CPU TTFT 优于 llama.cpp” 现象,主要是因为在高并发压测下,vLLM-CPU 的整体调度与吞吐能力更强,从而拉低了整体平均 TTFT;而 llama.cpp 在并发压力增加后,平均等待时间会更加明显。
从实际体验来看:
- llama.cpp 依然非常适合纯 CPU 本地推理
- 小模型低并发场景表现优秀
- Decode 性能很强
而 vLLM-CPU 的优势则更多体现在:
- 更完整的 OpenAI API 兼容
- 更统一的 GPU / CPU 推理生态
- Benchmark 与 SDK 适配更成熟
- 多模态模型支持更加统一
在 CPU 与 GPU 环境之间保持一致,其实非常重要。
尤其后续如果需要:
- 从 CPU Demo 平滑迁移 GPU
- 接入 OpenAI SDK
- 部署多模态模型
- 统一 API 网关
vLLM-CPU 的兼容性优势会更加明显。
小结
总体来看:
- llama.cpp 更像一个“极致优化的 CPU 推理引擎”
- vLLM-CPU 更偏向“面向服务化与高并发”的推理后端
两者的定位并不完全相同。对于 CPU 推理场景来说:
- llama.cpp 更适合轻量、本地、边缘设备部署
- vLLM-CPU 更适合高并发、统一 API 与后续 GPU 扩展场景
而对于 GPUStack 这类统一推理平台来说,其核心价值则在于统一纳管与集群调度能力。
特别是在算力碎片化越来越普遍的今天——如果你手头有多个、甚至大量闲置的 CPU 节点、消费级显卡或边缘小设备,GPUStack 就能将这些零散设备真正组织起来。
它可以把分散的异构设备聚合成一个标准化算力池,并为上层业务提供:
- 统一的部署方式
- 统一的 OpenAI 兼容 API
- 统一的模型管理逻辑
- 统一的调度与运维体系
这样一来,无论底层算力环境中混杂着什么:
- 纯 CPU 节点
- NVIDIA GPU
- 国产 GPU / NPU
- 边缘侧低功耗设备
GPUStack 都能够对其进行统一纳管与全局调度。
对于实际生产环境而言,这种“将零散设备集群化”的能力,可以显著降低:
- 异构硬件适配成本
- 多节点 API 接入复杂度
- 海量边缘设备的运维门槛
在异构算力逐渐成为常态的背景下,借助 vLLM-CPU、llama.cpp 等推理后端的生态兼容能力,GPUStack 让“蚂蚁搬家”式的部署真正具备了可行性——即使是再零碎的小型设备集群,也能够被快速整合为标准化 AI 推理服务,让边缘与闲置算力真正发挥出规模化价值。
【开源地址】:github.com/gpustack/gpustack

 浙公网安备 33010602011771号
浙公网安备 33010602011771号