阿里 PPU 加入 GPUStack 国产算力版图:异构算力统一调度的重磅里程碑
GPUStack 2.1.0 正式新增对阿里 PPU(平头哥)的支持,在 PPU 平台上实现 vLLM / SGLang 多版本切换、高性能模型推理、AI 网关访问控制、监控运营等企业级 MaaS 平台能力。
在 NVIDIA、AMD、华为昇腾、海光、摩尔线程、天数智芯、寒武纪、沐曦等多种算力平台的基础上,此次 PPU 的加入,使 GPUStack 的国产算力支持版图进一步扩展,也让平台在跨架构算力管理与统一调度方面迈出新的一步。
过去几年,大模型技术快速发展,算力正逐渐从单一硬件资源演变为企业 AI 基础设施的重要组成部分。与此同时,数据中心的算力形态也在不断丰富 —— 不同厂商、不同架构的加速器开始在同一环境中并存运行。如何在这样的环境下实现统一管理、稳定运行与高效利用,逐渐成为企业 AI 基础设施建设中的现实问题。
GPUStack 持续围绕这一方向推进平台能力建设。随着阿里平头哥 PPU 纳入支持范围,企业在部署 GPUStack 时,可以在既有 GPU 与国产算力基础之上,进一步引入新的算力类型,使更多异构计算资源能够在同一平台中被统一管理、统一调度,并服务于大模型推理等实际业务场景。
从更长远的视角看,越来越多国产算力平台的成熟与落地,也正在推动国内 AI 基础设施走向更加多元与开放的生态格局。PPU 的加入,是这一演进过程中的一个新节点,也为企业构建面向未来的异构算力体系提供了更多选择。
从“支持更多硬件”到“构建统一算力层”
企业 AI 基础设施正在经历一轮明显的结构变化。
在早期的 AI 系统中,平台往往围绕单一 GPU 生态构建,软件栈、运行环境与调度体系都高度依赖特定厂商。随着国产 AI 芯片的发展,以及多种加速架构逐渐成熟,企业数据中心开始进入一个新的阶段:NVIDIA 与多种国产算力平台并行存在,异构环境逐渐成为常态。
算力类型的增加也带来了新的现实挑战:不同芯片拥有不同驱动体系与运行时环境,推理框架适配复杂度提升,资源利用率难以统一评估,运维与调度体系也随之变得更加复杂。许多企业不得不为不同算力分别维护独立的软件环境与管理体系,导致 AI 基础设施逐渐碎片化。
GPUStack 的设计目标正是应对这一变化。平台通过对不同硬件架构进行统一抽象,使异构算力能够以一致方式完成资源管理、模型部署与推理调度,从而为企业构建可持续扩展的算力基础设施。
阿里 PPU 的加入,使这一统一算力体系进一步向前延伸。
阿里 PPU 纳入平台体系,国产算力生态持续扩展
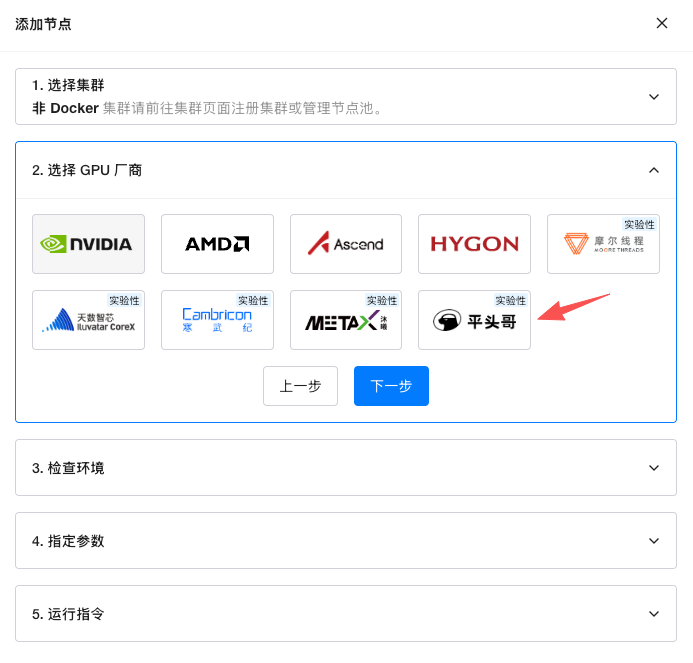
在 GPUStack 2.1.0 版本中,阿里平头哥 PPU 被纳入平台支持范围,并能够在 GPUStack 中运行主流大模型推理工作负载。企业可以在同一套平台中,对 PPU 与既有算力资源进行统一管理与统一调度。
至此,GPUStack 已覆盖 NVIDIA、AMD 以及多家国产 AI 加速平台,形成跨多种算力架构的统一管理能力。PPU 的加入不仅扩展了平台支持的硬件范围,也进一步验证了 GPUStack 在跨架构算力抽象与资源调度方面的通用性。
对于企业而言,这意味着算力资源不再被不同厂商生态所割裂,而能够以统一资源池的形式进行管理与调度,从而提升整体算力利用效率,并降低 AI 基础设施的运维复杂度。

从算力管理到模型服务:完整的大模型运行平台
GPUStack 不仅解决算力管理问题,也围绕AI 模型全生命周期管理构建了一套完整的平台能力,使企业能够在统一系统中完成模型部署、运行、推理服务化与运营管理。
平台支持多种类型 AI 模型的部署与运行,包括 LLM、Embedding、Reranker、图像、语音模型等多类模型服务。不同模型可以根据算力类型与业务需求部署在 GPU、NPU、PPU 等不同加速设备上,并通过统一 API 服务对外提供推理能力。
在模型管理方面,GPUStack 提供公共模型注册、模型推理部署与运行监控等能力,使企业能够在平台中统一管理公共模型服务与私有部署模型。
PPU 上的高性能推理:vLLM 与 SGLang
在 AI 模型推理落地场景中,除了硬件性能,推理框架的兼容性与工程一致性同样是新算力平台能否被实际采用的重要因素。

阿里 PPU SDK 提供由应用层、接口层与 SDK 层组成的软件体系,并支持 CUDA 生态兼容。基于 CUDA 开发的应用可以通过 PPU 编译器重新编译运行在 PPU 平台上,实现源代码级兼容,从而显著降低现有 AI 框架的迁移成本。
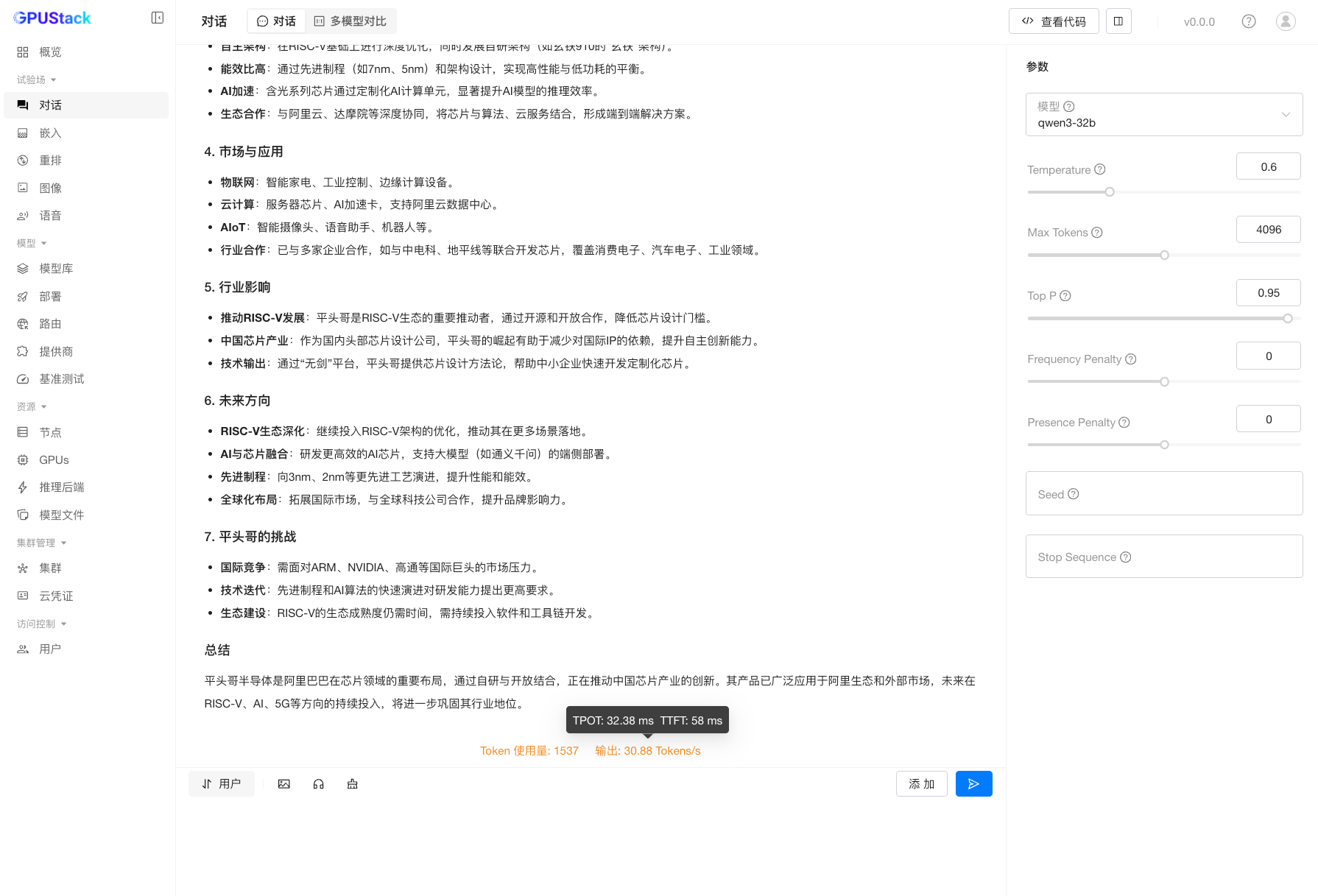
在此基础上,GPUStack 支持在 PPU 环境中使用 vLLM 与 SGLang 两种主流推理引擎部署 DeepSeek、Qwen3 等主流大模型,并提供多版本推理引擎切换、统一参数配置与服务化能力。
平台还提供推理引擎参数调优与模型压测功能,方便工程团队针对不同算力环境优化推理性能。
测试数据显示,在长上下文与多并发场景下,PPU 集群能够维持稳定吞吐与可控时延,满足生产环境对 TTFT 与 TPOT 的性能约束。在 W8A8 等量化配置下,系统吞吐进一步提升,同时在 MMLU-Pro、GSM8K 与 CEval 等评测中保持与对比平台接近的精度表现。
通过 GPUStack,企业能够在统一平台中完成推理引擎管理、模型推理运行与服务发布,使 PPU 算力能够更高效地融入现有 AI 推理体系。
API 服务与 AI 网关:统一接入企业应用
在企业环境中,大模型往往需要以标准化 API 服务的形式被业务系统调用。GPUStack 提供统一 API 代理与 AI 网关能力,支持 OpenAI / Anthropic 兼容接口与通用 API 代理,使应用可以在不修改代码的情况下接入模型服务。
通过 AI 网关,企业可以实现:
- 公共模型服务与私有部署模型统一管理
- 统一认证与访问控制
- 无感模型升级切换
- 服务路由与模型调度
- 负载均衡与容灾切换
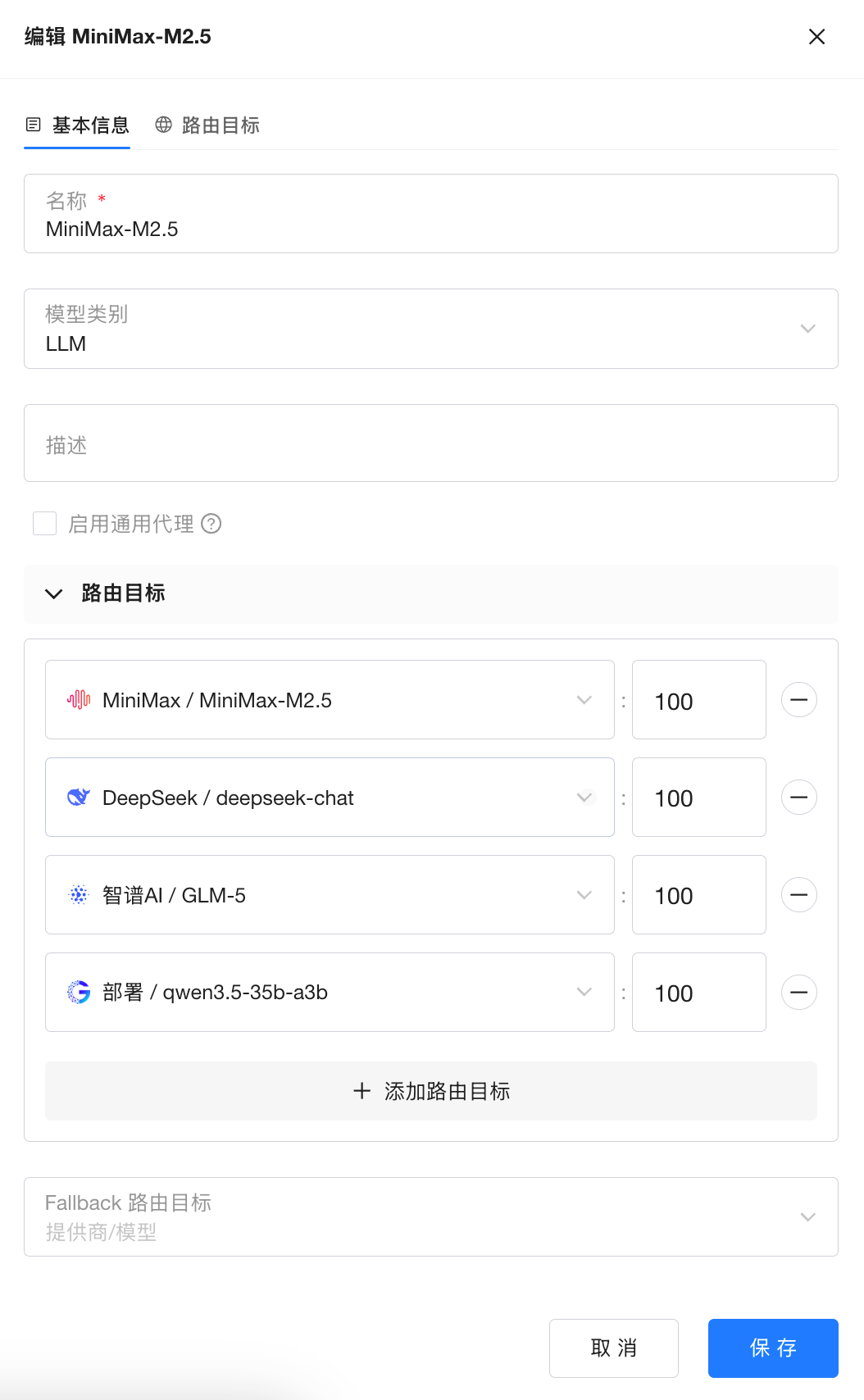
GPUStack 的统一 API 层使不同模型服务能够以一致方式对外提供能力,减少业务系统与底层模型之间的耦合。
统一监控与算力运营
随着模型数量与算力规模增长,可观测性与运营能力也成为 AI 平台的重要组成部分。
GPUStack 提供完整的监控与运营能力,包括:
- 算力资源使用监控
- 模型推理性能指标(TTFT / TPOT / TPS 等)
- 服务调用统计与使用计量
- GPU / PPU / NPU 设备运行状态监控
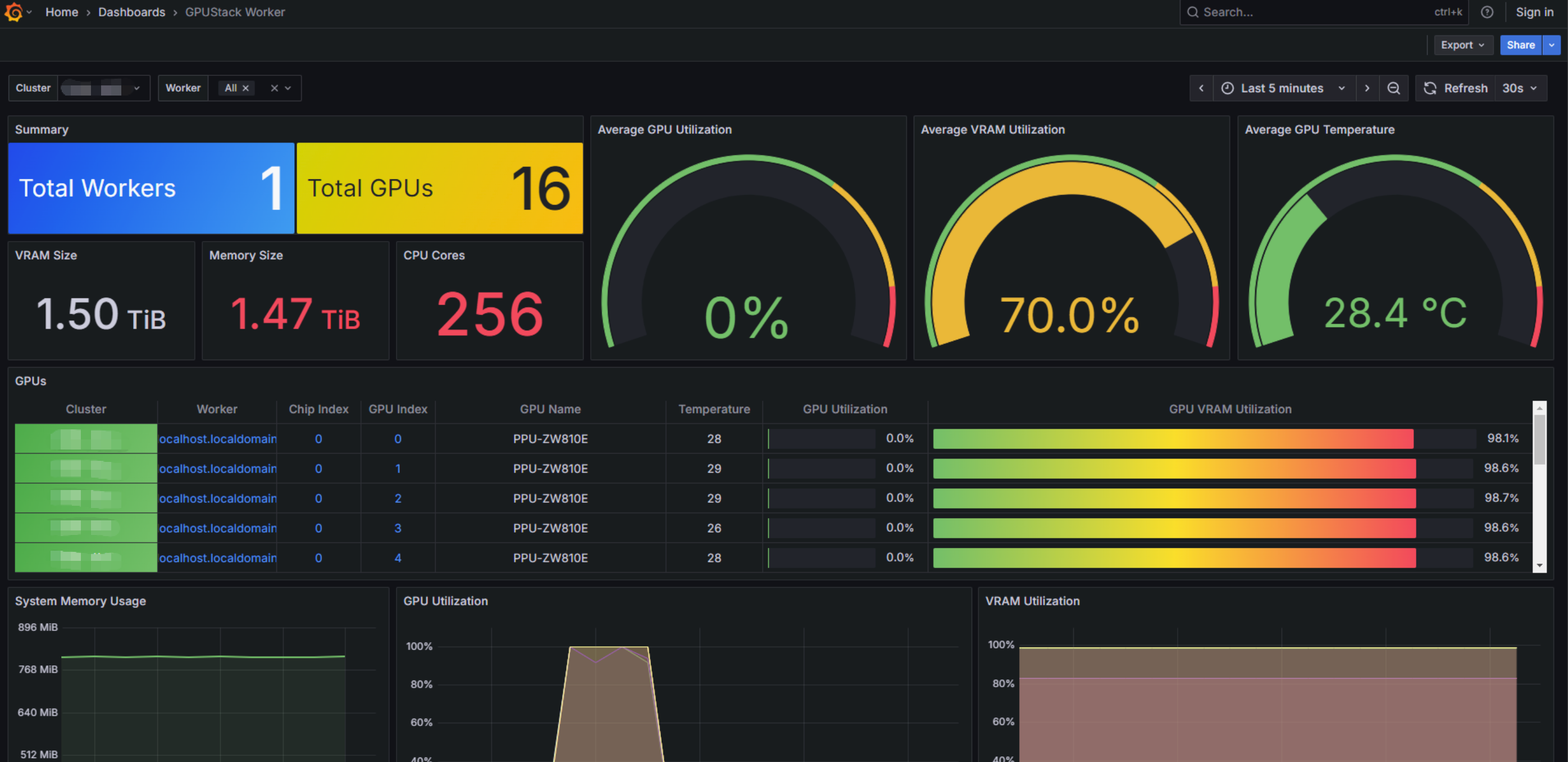
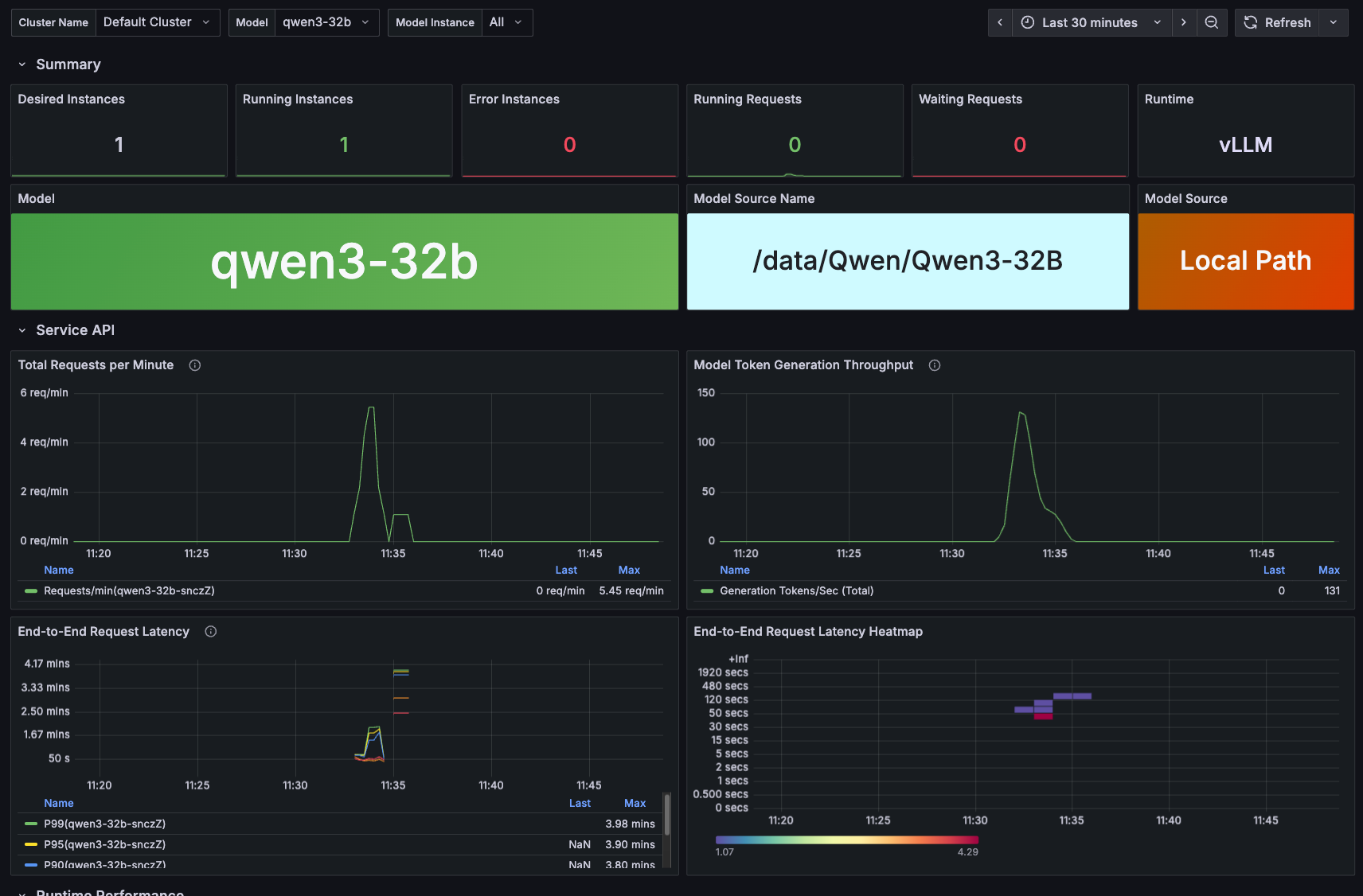
通过统一监控与计量体系,企业可以清晰了解算力资源消耗、模型服务负载以及业务使用情况,从而实现更加精细化的 AI 基础设施运营。
CIO 与架构师视角:算力正在成为可运营资产
在企业层面,算力管理正在从技术问题转变为经营问题。
CIO 与基础架构负责人越来越关注的问题包括:
- 如何避免算力供应链单点依赖
- 如何在国产化推进过程中保持系统连续性
- 如何让新增硬件快速进入生产体系
- 如何在多代、多厂商设备并存情况下维持统一运维
GPUStack 通过持续扩展异构算力支持范围,将不同架构的 AI 加速设备纳入统一调度体系,使企业能够以平台化方式运营算力资源,而非逐设备管理。
PPU 的接入,意味着这类国产算力不再只是“专项部署资源”,而可以成为企业 AI 基础设施中的标准组成部分。
面向未来的 AI 基础设施形态
业界普遍认为,未来的数据中心将不会存在单一算力架构。GPU、NPU、PPU 以及更多专用加速器将长期共存,并针对不同工作负载协同运行。
真正具备竞争力的企业,不是拥有最多算力的企业,而是能够以最低复杂度驾驭多样算力的企业。
GPUStack 正在尝试回答这一时代问题:如何为异构计算建立统一的调度与运行层,让算力像云资源一样被组织和使用。
阿里 PPU 的加入,是这一长期演进过程中的重要节点。它不仅扩展了平台支持矩阵,也进一步反映国产算力生态正在从单点突破走向多元发展与体系协同。
当算力边界被打破,AI 基础设施的形态也正在被重新定义。
而 GPUStack,正在成为这一变革中的关键基础层之一。
如何将阿里 PPU 加入 GPUStack 统一算力管理体系,利用 vLLM 和 SGLang 实现高性能推理,实现 AI 网关访问控制、监控运营等企业级 MaaS 平台能力?教程即将奉上,敬请期待。
加入 GPUStack 社区
GPUStack 社区是一个围绕 AI 基础设施与大模型推理实践展开的技术交流空间。
在这里,你可以看到真实环境下的 AI Infra 与大模型推理的部署经验、问题排查过程,以及围绕推理引擎、算力管理和系统架构的持续讨论。
无论你正处于模型基础设施的评估、试用还是规模化部署阶段,都可以在社区中找到有参考价值的信息。
欢迎扫码加入 GPUStack 社区,与更多关注 AI Infra 与大模型推理实践的伙伴一起交流、学习与分享。
若群聊已满或二维码失效,请访问以下页面查看最新群二维码:
https://github.com/gpustack/gpustack/blob/main/docs/assets/wechat-group-qrcode.jpg

 浙公网安备 33010602011771号
浙公网安备 33010602011771号