从模型推理到开源 AI 基础设施平台:GPUStack v2.1 的关键演进
随着大模型应用进入生产环境,AI 推理基础设施复杂度快速上升。
模型规模扩大、迭代加速、多模态增加,以及企业私有化需求,使统一算力管理、模型服务治理与工程运维成为关键。
早期,团队多通过推理框架直接提供 API,但随着模型与业务规模增长,问题逐渐显现:
- 部署方式碎片化
- 推理引擎生态不统一
- 模型调用缺乏治理
- 异构算力难以统一管理
AI 推理服务正从单模型部署工具演进为 AI 基础设施平台。
在此背景下,GPUStack v2.1 重点增强模型生态、异构算力、推理统一、模型治理、推理引擎生态与运维能力,并优化离线部署体验。
本文将从 AI 基础设施视角,介绍 GPUStack v2.1 的主要技术变化。
AI 推理基础设施的复杂性正在快速上升
在企业实践中,大模型服务通常呈现以下特点:
- 同时运行多种模型类型(LLM / VLM / Embedding / Reranker / Image / ASR / TTS / OCR 等)
- 不同团队使用不同推理框架
- GPU、NPU 及国产 AI 加速芯片共存
- 公有模型 API 与私有模型混合调用
这些变化带来三个核心挑战:
算力统一:异构芯片需统一调度,屏蔽底层差异。
模型治理:提供稳定接口,且支持治理而非绑定具体模型。
工程运维:部署、升级、测试与监控需标准化。
GPUStack 旨在解决这些问题,构建统一高性能 AI 模型服务平台(MaaS),并提供异构算力调度管理能力。
模型生态扩展:加速跟进主流模型迭代
大模型生态快速发展,多模态与各类任务模型不断更新。
AI 平台需持续跟进主流模型,为用户提供稳定、标准化的部署入口,降低适配与运维成本。
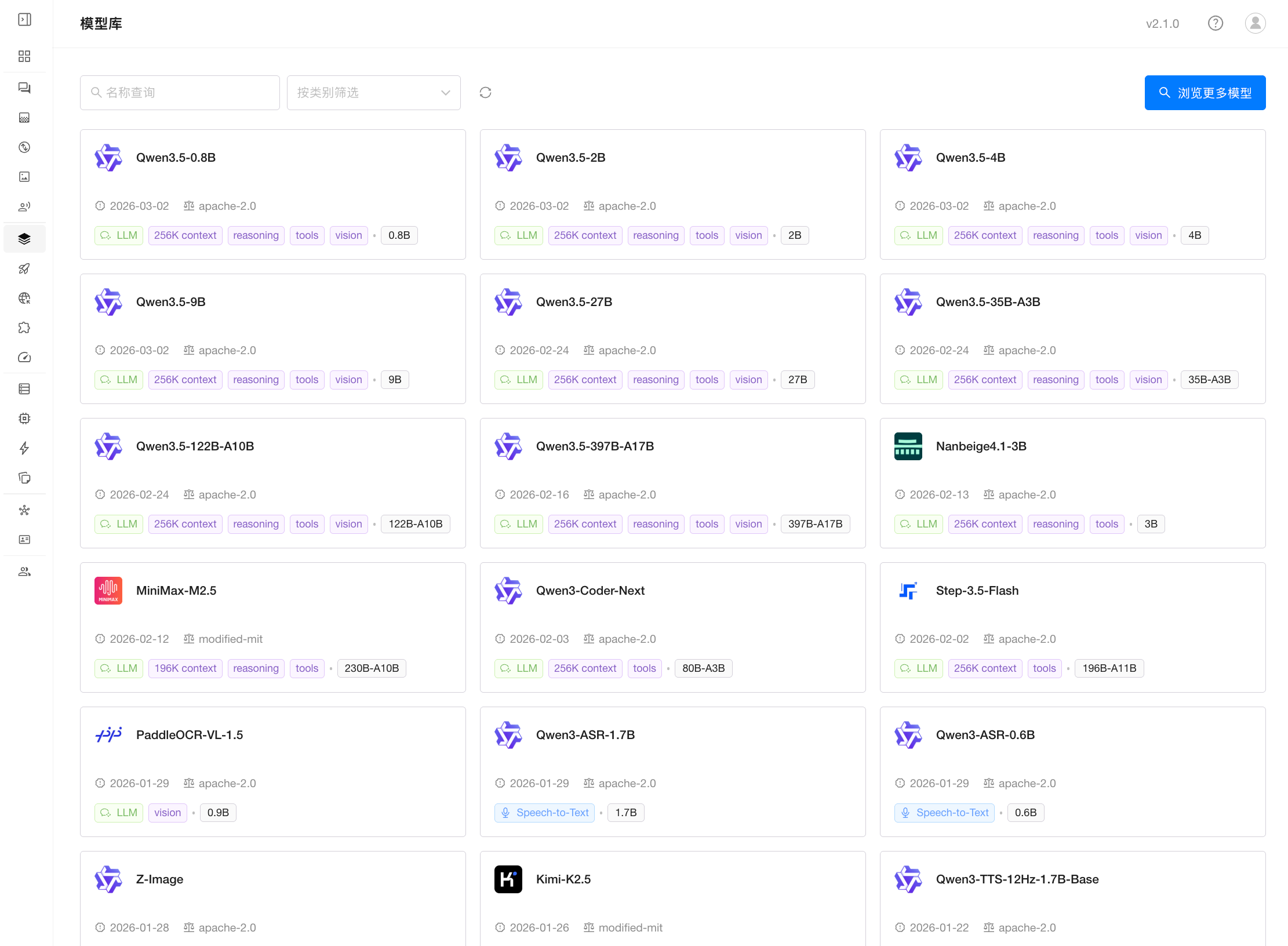
GPUStack 2.1 模型库加速支持最新发布的各类主流模型,使用户能够在统一平台中快速部署并调用最新 AI 能力。
大语言模型与多模态模型:Qwen3.5、Qwen3-Coder-Next、MiniMax-M2.5、Kimi-K2.5 等
Embedding 与 Reranker 模型:Qwen3-VL-Embedding、Qwen3-VL-Reranker 等
语音模型:Qwen3-ASR、Qwen3-TTS 等
图像模型:FLUX.2-Klein、Qwen-Image-2512 等
GPUStack 将持续验证更多主流模型,将最佳实践纳入内置库,帮助用户快速尝试并应用最新模型能力。
异构算力扩展:新增阿里 PPU 支持
AI 基础设施的长期趋势是算力逐渐多元化。
除 NVIDIA GPU 外,越来越多企业深入使用国产 AI 芯片以降低成本并提升供应链稳定性。
GPUStack 2.1 进一步扩展异构算力支持版图,新增支持阿里 PPU(平头哥)。
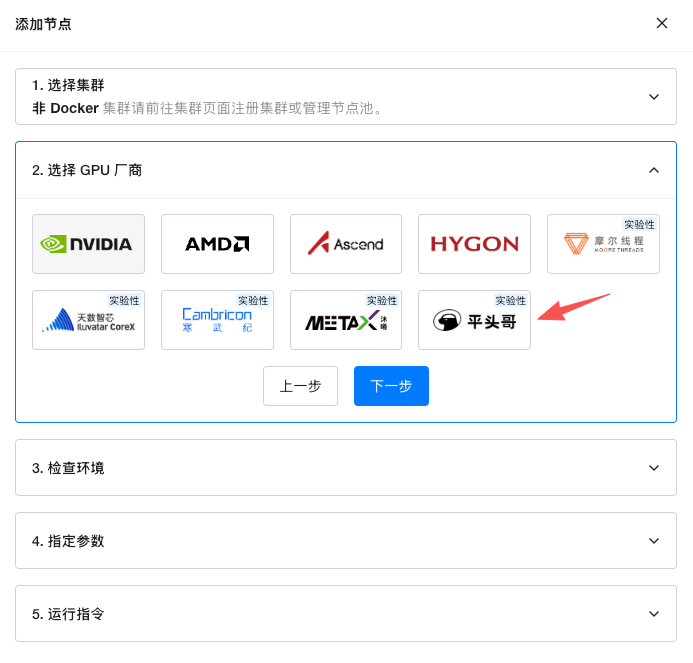
当前支持:
- vLLM
- SGLang
PPU 设备可直接接入 GPUStack 模型服务体系,实现:
- 异构算力统一调度
- 推理框架与硬件解耦
- 应用无需感知底层芯片差异
在国产算力生态发展下,这类能力愈发关键。
推理能力统一:vLLM-Omni 集成
多模态模型的发展,也带来了推理框架分散的问题,不同模态往往依赖不同推理组件,例如文本、视觉、语音以及图像或视频生成。
继 2.0 集成 SGLang Diffusion 之后,GPUStack 2.1 将 vLLM-Omni 集成进 vLLM Runner 镜像,用于统一多模态推理能力。
这一整合带来了几个变化:
-
多模态模型统一推理入口
-
更一致的部署路径与技术栈
-
更标准化的推理框架管理
从而减少多模态模型部署时的组件复杂度,也简化了推理环境的维护与升级。
模型服务治理:公共模型统一接入与模型路由
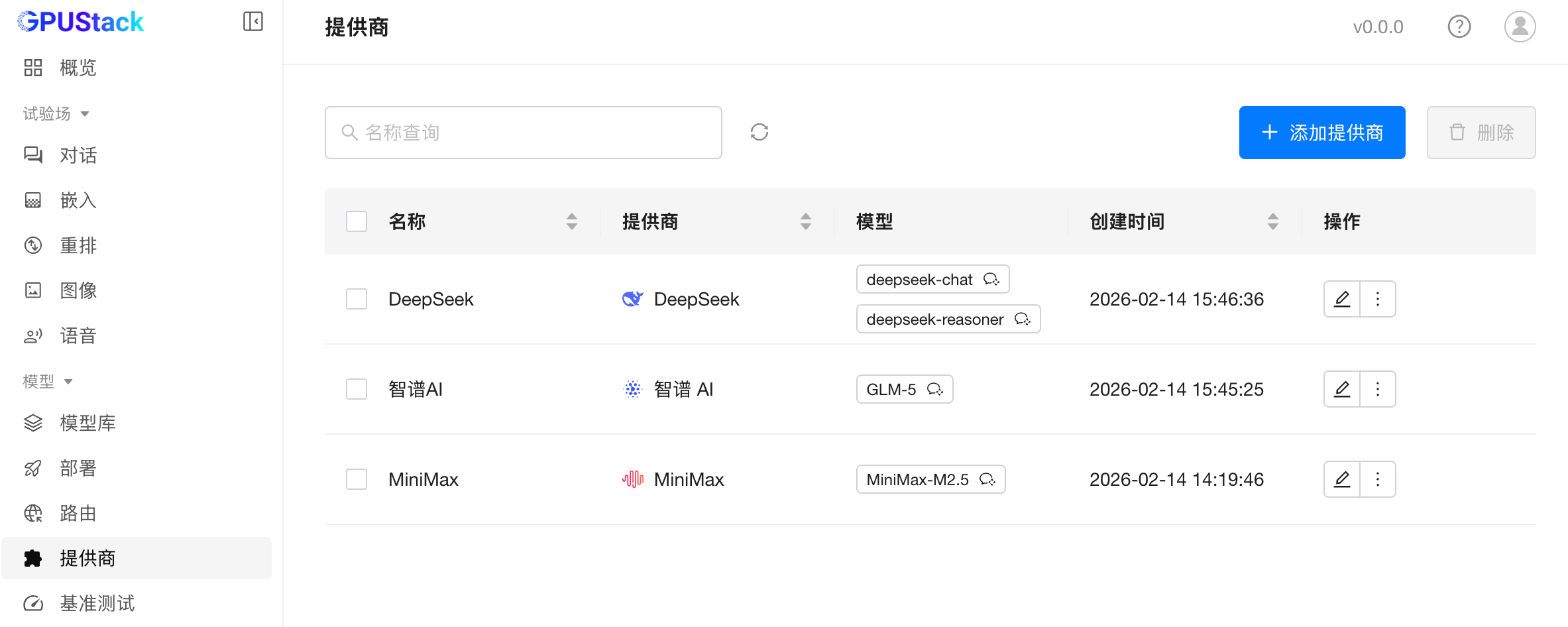
公共模型提供商统一接入
在很多实际项目中,企业往往同时使用本地部署模型、云厂商 API 和第三方模型服务。
GPUStack 2.1 提供了统一的公共模型提供商接入能力,当前已支持 OpenAI、Anthropic、DeepSeek、豆包、通义千问等数十种模型服务,并兼容自定义 OpenAI 协议接口。
通过这一能力,GPUStack 可以作为统一模型网关使用。应用侧只需调用一个 API,即可访问私有部署模型、云端模型服务和第三方平台。
平台同时提供统一的调用计量、访问控制和路由策略管理,从而简化多模型环境下的接入与治理。
模型路由策略控制
在企业环境中,模型版本升级和切换是常见需求。
如果应用直接绑定具体模型,每次升级往往需要修改代码或重启服务。
GPUStack 2.1 引入模型路由机制,核心能力包括:
-
虚拟模型名:应用侧仅调用逻辑模型名
-
流量权重分配:支持灰度发布
-
Fallback 容灾:主模型异常自动切换
-
自动重试策略
例如,应用只需调用一个逻辑模型名,平台即可在后台灵活切换不同模型(如 Qwen、DeepSeek 或私有微调模型)。
这一机制类似于服务网关的流量治理能力,能够实现模型的平滑升级、流量控制和高可用保障。

推理引擎生态:社区推理后端市场
推理框架生态非常活跃,不同模型往往依赖不同推理引擎。
GPUStack 2.1 引入社区推理后端市场,支持一键启用 llama.cpp 等多种社区推理框架,并为第三方推理引擎提供统一接入方式。
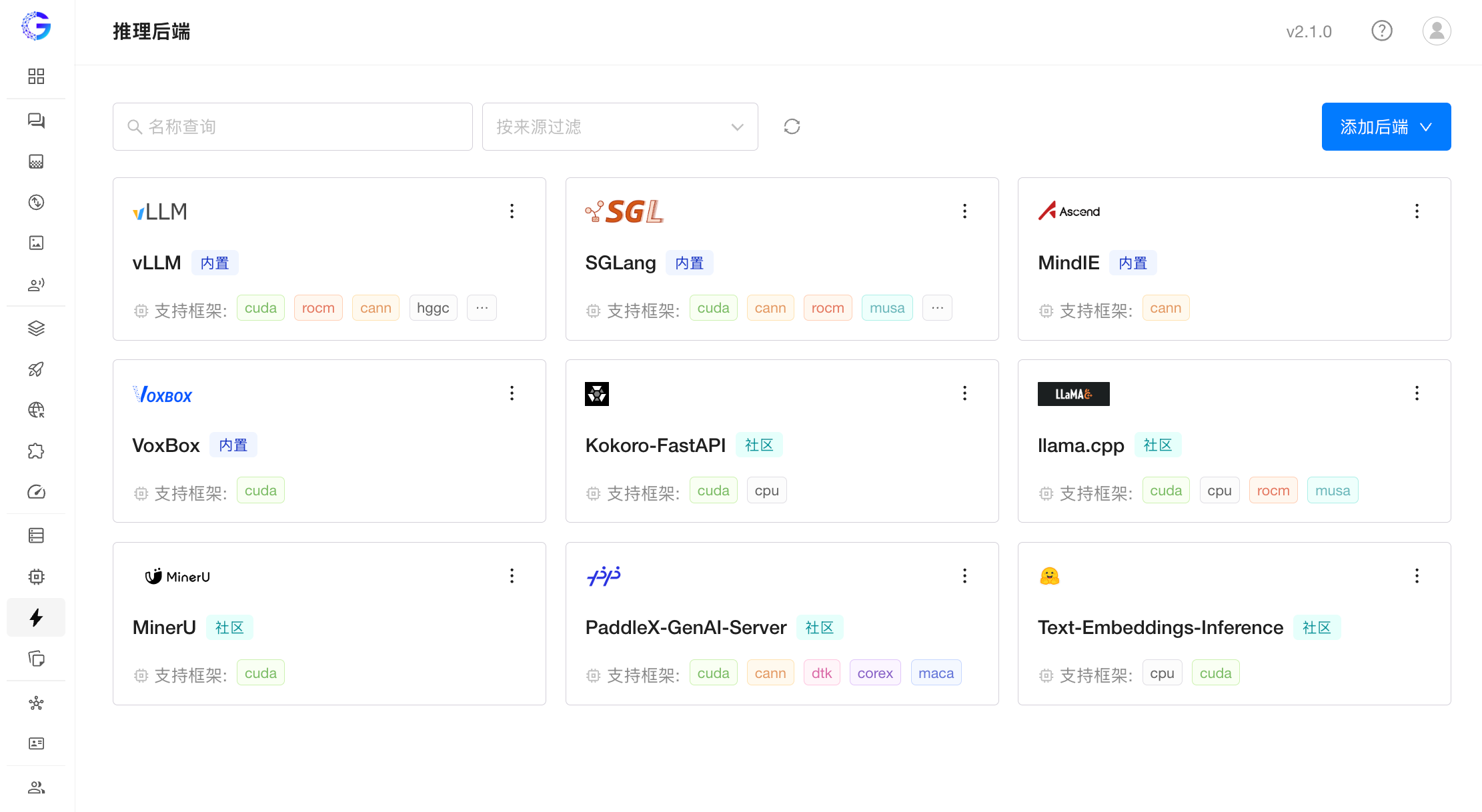
通过可插拔的推理后端机制,GPUStack 可以快速接入新的推理框架,而无需对平台本身进行大量适配。
用户可以在统一平台中根据模型类型、硬件环境或性能需求选择合适的推理引擎,而无需分别搭建和维护多个独立推理服务。
随着社区生态的发展,社区推理后端市场也将持续扩展更多后端,逐步形成开放、可扩展的推理引擎生态。
运维能力增强:全流程管理与性能治理
在 AI 推理平台的早期阶段,运维主要关注模型部署和服务可用性。
随着模型数量和推理流量增长,运维需求升级:不仅要保证服务稳定,还需要能够量化性能、统一可观测,并支持多节点、多模型的高效管理。
AI 推理运维的全流程
一个完整的 AI 推理运维流程通常包括:
-
部署前检查:硬件资源、推理框架兼容性、资源评估
-
模型部署与初始化:权重准备、资源分配、实例创建、容器启动
-
运行中管理:实例健康检查、资源监控、日志收集
-
性能评估与优化:推理速度、吞吐量、延迟监控,负载分析
-
版本迭代与扩展:模型升级、副本扩容、部署策略优化
这一流程构成了 AI 推理平台运维的核心闭环:
部署 → 运行 → 监控 → 评估 → 优化。
GPUStack 之前的运维能力
在 2.0 及以前版本,GPUStack 已构建较为完整的 AI 推理运维体系,覆盖算力管理、模型接入与部署、运行监控、性能调优与使用管理,为企业模型服务提供稳定基础。
GPUStack 2.1 的运维增强
GPUStack 2.1 在此基础上增强了性能评估、可观测与部署效率:
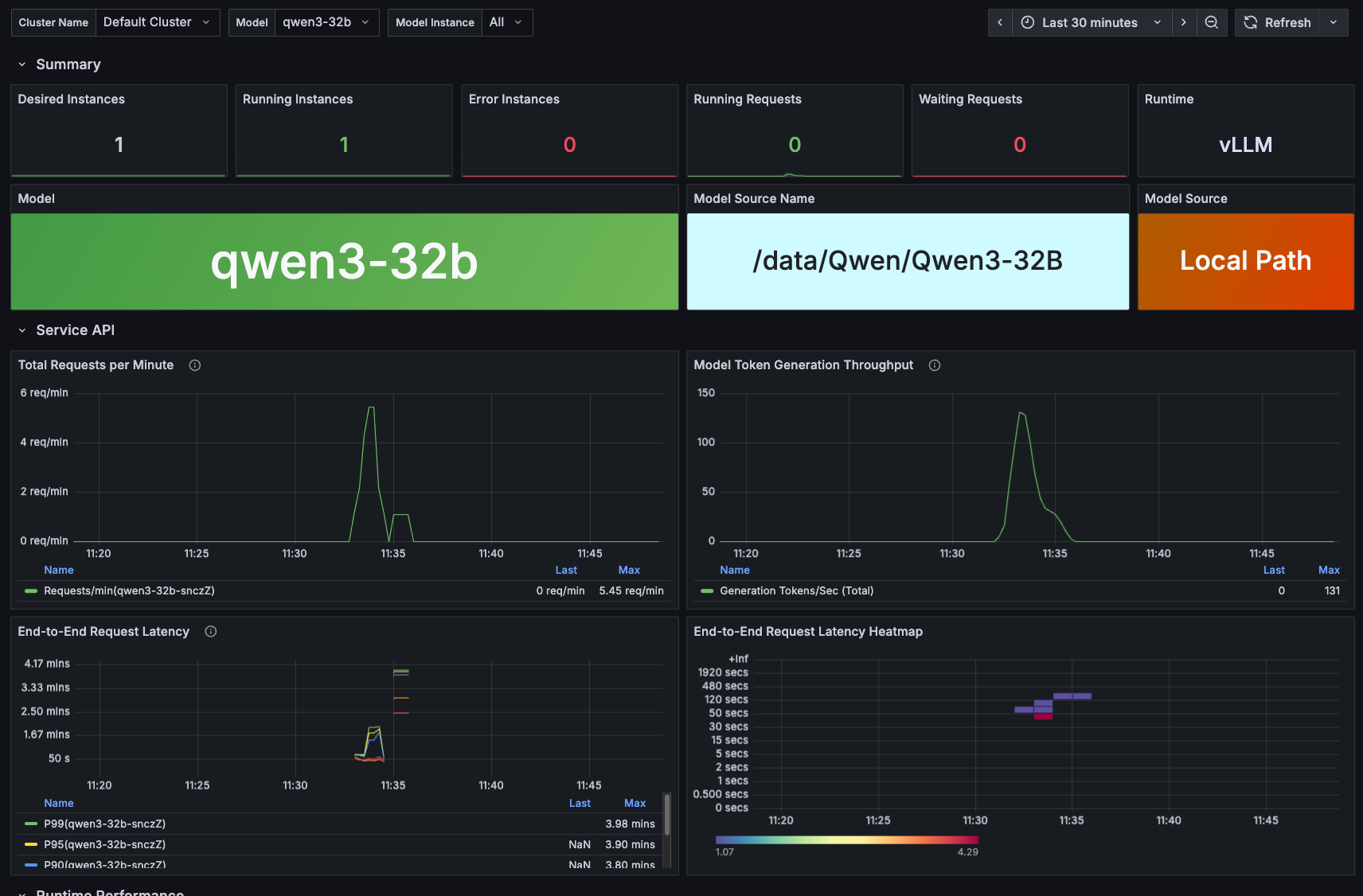
1. 内置 Benchmark 基准测试
支持不同模型版本、硬件、推理框架及参数配置的标准化性能评估,为部署、升级和参数调整提供依据。
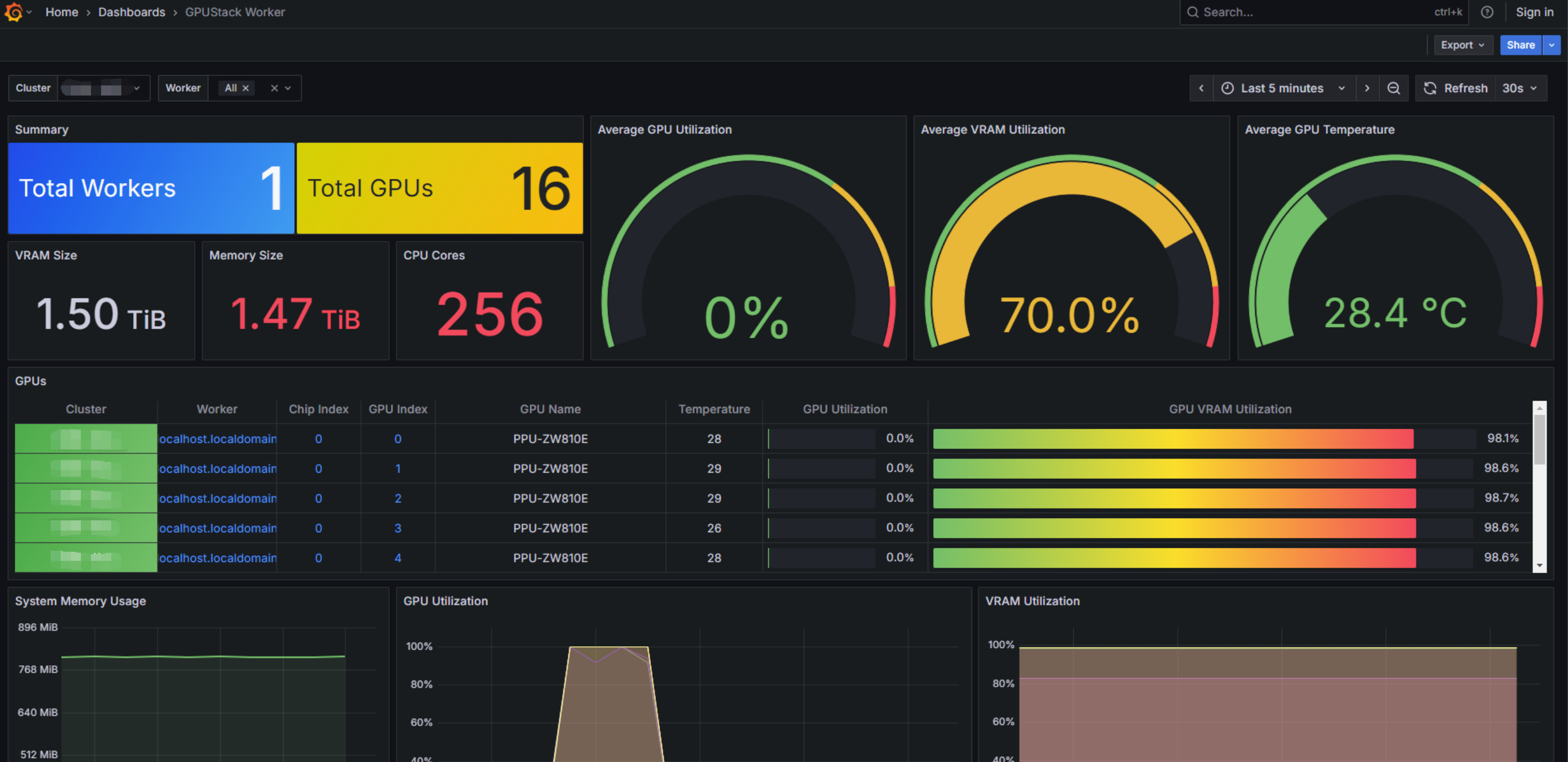
2. 开箱即用的可观测能力
UI 集成 Grafana 面板,无需额外部署即可监控:
- GPU / NPU 与系统资源利用率
- 模型实例运行状态
- 推理指标(TTFT / TPOT / ITL、延迟分布、缓存命中率等)
推理服务运行状态更加直观,同时可与企业监控体系集成。
3. 部署体验优化
GPUStack 2.1 对模型部署与实例管理进行了优化:
- 模型克隆部署
- 跨节点兼容性检查
- 显存分配可视化
- 指定容器运行用户
- 启动命令变量覆盖
显著提升了多模型、多部署环境下运维效率。
未来发展方向
随着企业 AI 应用扩大,运维体系将持续演进:
- 跨集群/跨地域算力调度
- 智能运维与自动优化
- 更完善的性能治理
- 运维数据分析与资源运营
GPUStack 将从模型服务运维平台,逐步演进为企业级 AI 基础设施的大规模模型服务治理与算力运营体系。
增强离线环境支持:容器镜像选择器
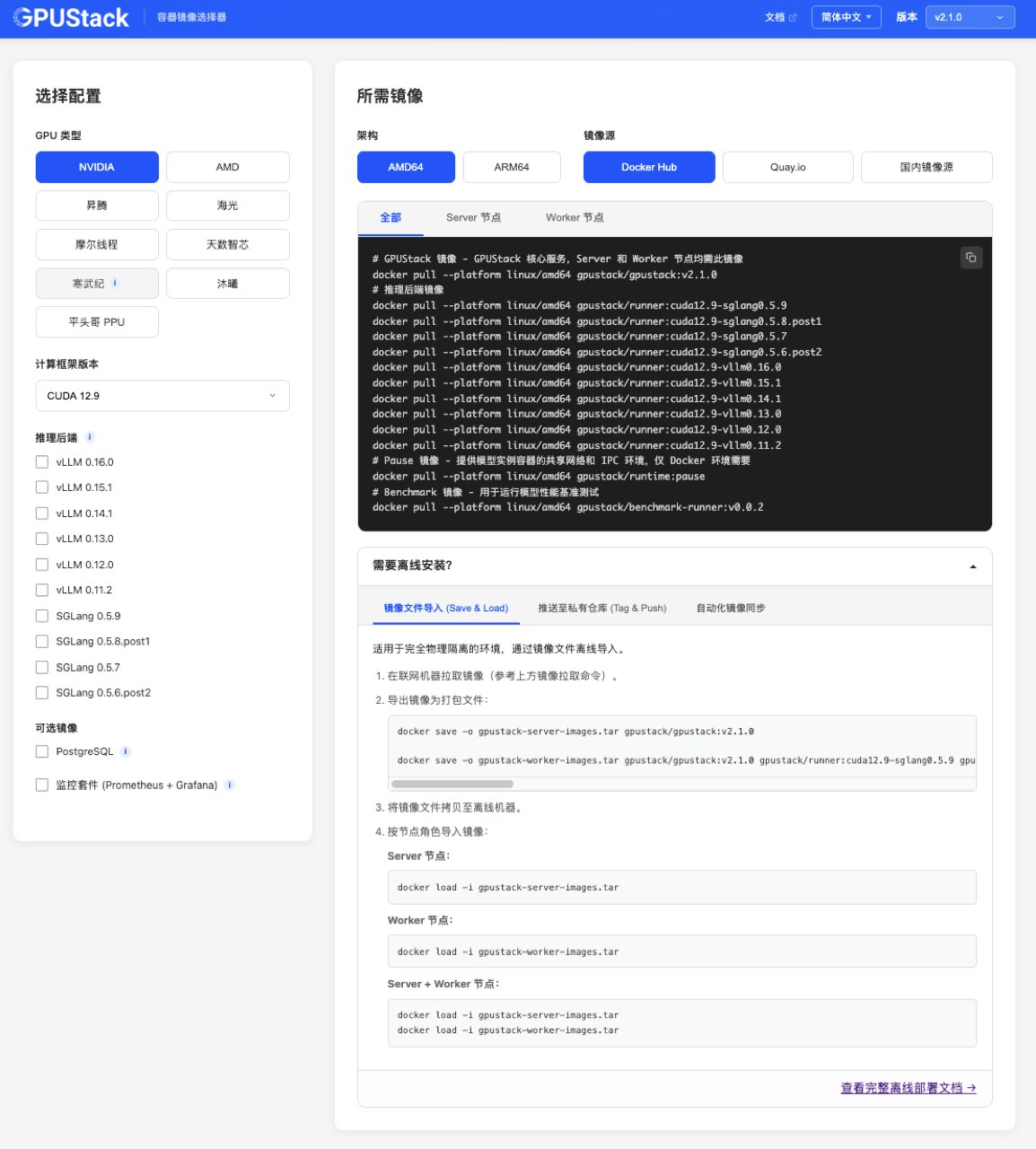
在内网或离线环境部署 GPUStack 时,不同硬件环境的容器镜像准备往往较为复杂。
为此,GPUStack 官方提供了离线镜像选择器:
https://docs.gpustack.ai/latest/image-selector
用户只需选择对应的硬件环境,即可生成所需镜像及下载命令。
AI 推理平台的下一阶段
AI 基础设施正在经历一个清晰的演进路径:
- 早期:单模型推理服务
- 中期:模型服务平台(MaaS)
- 进一步:AI 基础设施平台
此阶段通常具备:异构算力管理、推理框架生态、模型治理与运维可观测能力。
GPUStack 2.1 围绕这些核心能力持续演进。
随着模型规模与企业应用增长,基础设施在 AI 技术栈中作用愈发关键。
GPUStack 将持续探索落地场景,构建面向企业的可靠 AI 基础设施底座。
加入 GPUStack 社区
GPUStack 社区聚焦 AI 基础设施与大模型实践。
社区中持续分享真实环境下的部署经验、问题排查案例,以及推理引擎、算力管理和系统架构相关讨论。
欢迎扫码加入 GPUStack 社区,与更多关注 AI Infra 的伙伴交流分享。

二维码失效?获取最新群二维码:
https://github.com/gpustack/gpustack/blob/main/docs/assets/wechat-group-qrcode.jpg

 浙公网安备 33010602011771号
浙公网安备 33010602011771号