AI Max 395 实战记录:从零部署 AgentCPM,一键集成 DeepResearch 能力
笔者最近在开发一个产业研究分析的 DeepResearch 智能体,正好看到最近 OpenBMB 开源社区刚刚发布了一款仅 4B 参数的智能体大模型 AgentCPM-Explore 和 8B 参数的 Deep Research 模型 AgentCPM-Report。
今天就以这两个小参数开源模型为例,完整记录一下在 AI Max 395 上从模型部署到调用的全流程,也算是给大家提供一个本地算力有限的条件下实现联网搜索问答以及 Deep Research 两个业务场景本地实现的技术方案。
AgentCPM-Explore
AgentCPM-Explore 的亮点包括:
- 首个以 4B 全量参数登上 GAIA、HLE、BrowseComp 等 8 个长程复杂智能体任务榜单的端侧智能体模型。
- 可实现超过 100 轮的连续环境交互,支持多源信息交叉验证、搜索策略动态调整、实时核验最新信息,持续深度探索直至任务完成。
- 全流程开源,包括智能体全异步强化学习训练框架 AgentRL、工具沙盒统一管理调度平台 AgentDock、智能体工具学习能力一键测评平台 AgentToLeaP,支持社区共建与自定义扩展。
- 在 Xbench-DeepResearch 上 AgentCPM-Explore 的表现超越了 OpenAI-o3,Claude-4.5-Sonnet 等闭源大模型,显著超越了不同量级 SOTA 模型的表现趋势线,展现出了更高的能力密度。
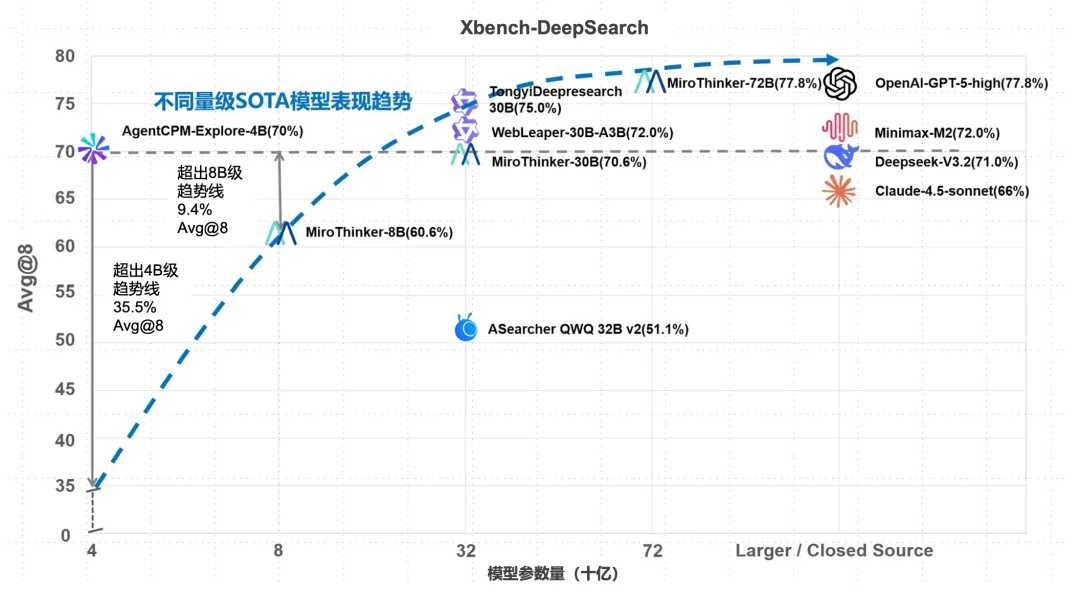
AgentCPM-Report
OpenBMB 开源社区发布了一款 8B 参数大小的 Deep Research 场景专业模型。实现了比肩顶级闭源系统的报告写作能力。 在 DeepResearch Bench、Deep Consult 以及 DeepResearch Gym 三大主流深度调研评测基准中,AgentCPM-Report 展现了惊人的越级战斗力,综合评分达到甚至超越顶级闭源系统。在最考验深度的洞察性指标上,AgentCPM-Report 力压群雄,排名第一;而在全面性指标上,也仅次于基于 Claude 的复杂写作框架,位居第一梯队。
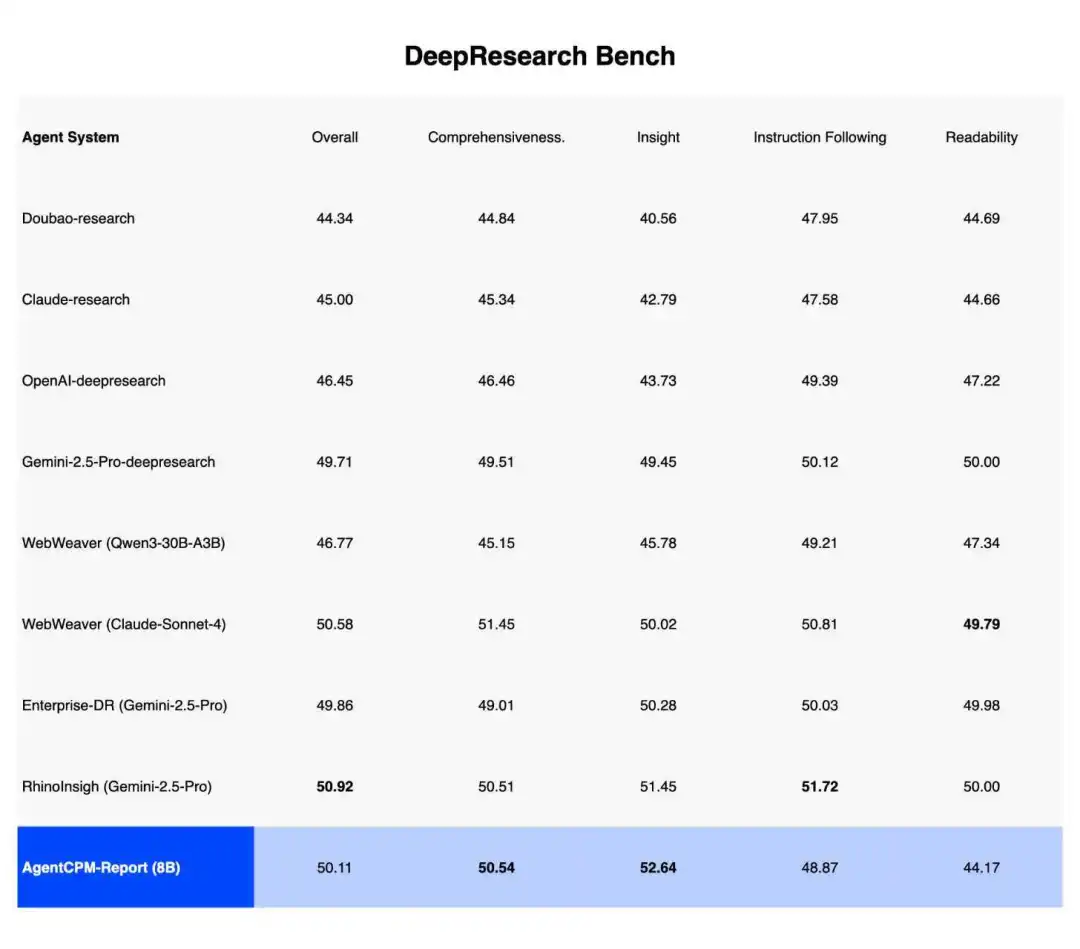
AI Max+ 395
正好我手上最近刚刚入手了搭载了在 2025 年 CES 上 AMD 发布的最新的 AI Max+ 395(代号 Strix Halo)的旗舰级处理器的 mini 主机 GTR9 Pro。
AI Max+ 395是基于 RDNA 3.5 架构打造的 AMD Radeon 8060S 集成显卡。40 个计算单元,显存带宽高达 256GB/s,性能媲美移动版 RTX 4060 独显。
零刻 GTR9 Pro 搭载了频率高达 8000MT/s 的 128GB LPDDR5X 内存,以及出厂标配 2T 容量的固态硬盘。因为 AI Max+ 395 是统一内存架构(致敬 Apple 的 M 系列芯片?),可以在 BIOS 中将 128G 内存中的 96G 分配给显存。
这么大的显存无疑最适合用来本地跑 AI 项目,那么本篇教程就将向各位介绍如何使用 AI Max 395 在本地运行 AgentCPM + DeepResearch 智能体项目。


安装驱动和 ROCm
如果你是刚刚拿到的新机,建议直接放弃 Windows 系统,改用 Ubuntu 系统。因为目前要运行一些 AI 组件依赖,还是 Linux 系统编译安装更为友好,如果实在需要 Windows 系统,那么也建议在 WSL 环境下部署 AI 项目。
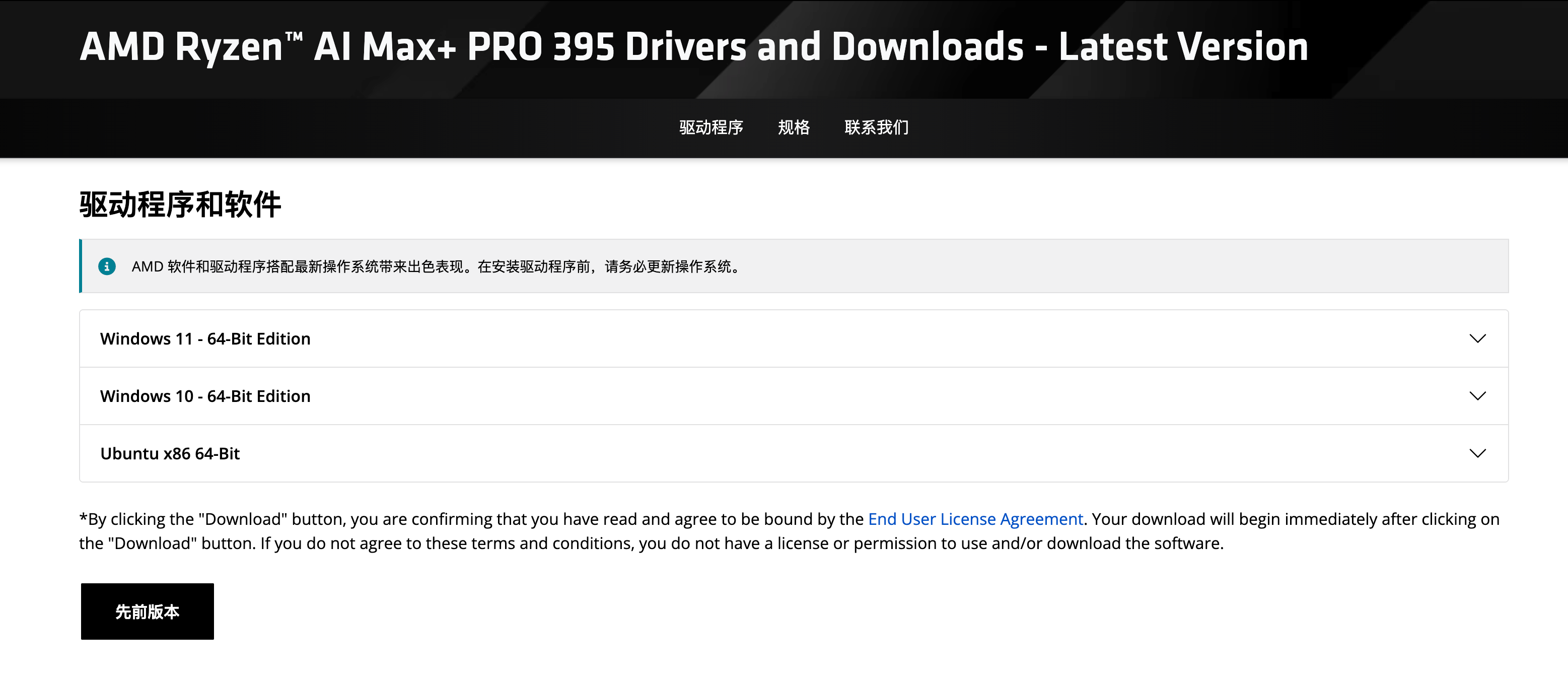
首先第一步,我们需要去官网下载驱动:
https://www.amd.com/zh-cn/support/downloads/drivers.html/processors/ryzen-pro/ryzen-ai-max-pro-300-series/amd-ryzen-ai-max-plus-pro-395.html
如图所示,官网目前提供 Win11,Win10 和 Ubuntu 三个系统版本:
我手上这台零刻 AI Max 395 从入手后就直接重置系统删除了自带的 Win11,改成 Ubuntu 24.04 了。因此本篇文章完全是基于 Ubuntu 24.04 来实现的。
根据 AMD 官网的介绍,在使用 Ubuntu 内核 6.12.0-1018 在 AMD Ryzen AI Max 395 系列处理器(gfx1151)上运行 LLM 推理工作负载时,可能会观察到间歇性应用程序崩溃或脚本失败,因此为了避免此类情况出现,我们第一步需要先升级 Linux 内核版本,直接在终端中输入升级命令:
sudo apt update && sudo apt install linux-image-6.14.0-1017-oem
安装完成后,重启系统并启动到 6.14 OEM 内核:
uname -r
然后开始更新系统:
sudo apt upgrade -y
接下来开始下载并安装 amdgpu-install 运行脚本:
sudo apt update
wget https://repo.radeon.com/amdgpu-install/7.1.1/ubuntu/noble/amdgpu-install_7.1.1.70101-1_all.deb
sudo apt install ./amdgpu-install_7.1.1.70101-1_all.deb
运行以下命令来安装 ROCm:
amdgpu-install -y --usecase=rocm --no-dkms
安装完成后设置权限组:
groups
使用下面命令将用户添加到渲染和视频权限组:
sudo usermod -a -G render,video $LOGNAME
添加完成后重启系统:
sudo reboot
重启之后,我们来验证是否安装成功:
groups
输出结果: magicyang adm cdrom sudo dip video plugdev users lpadmin docker render
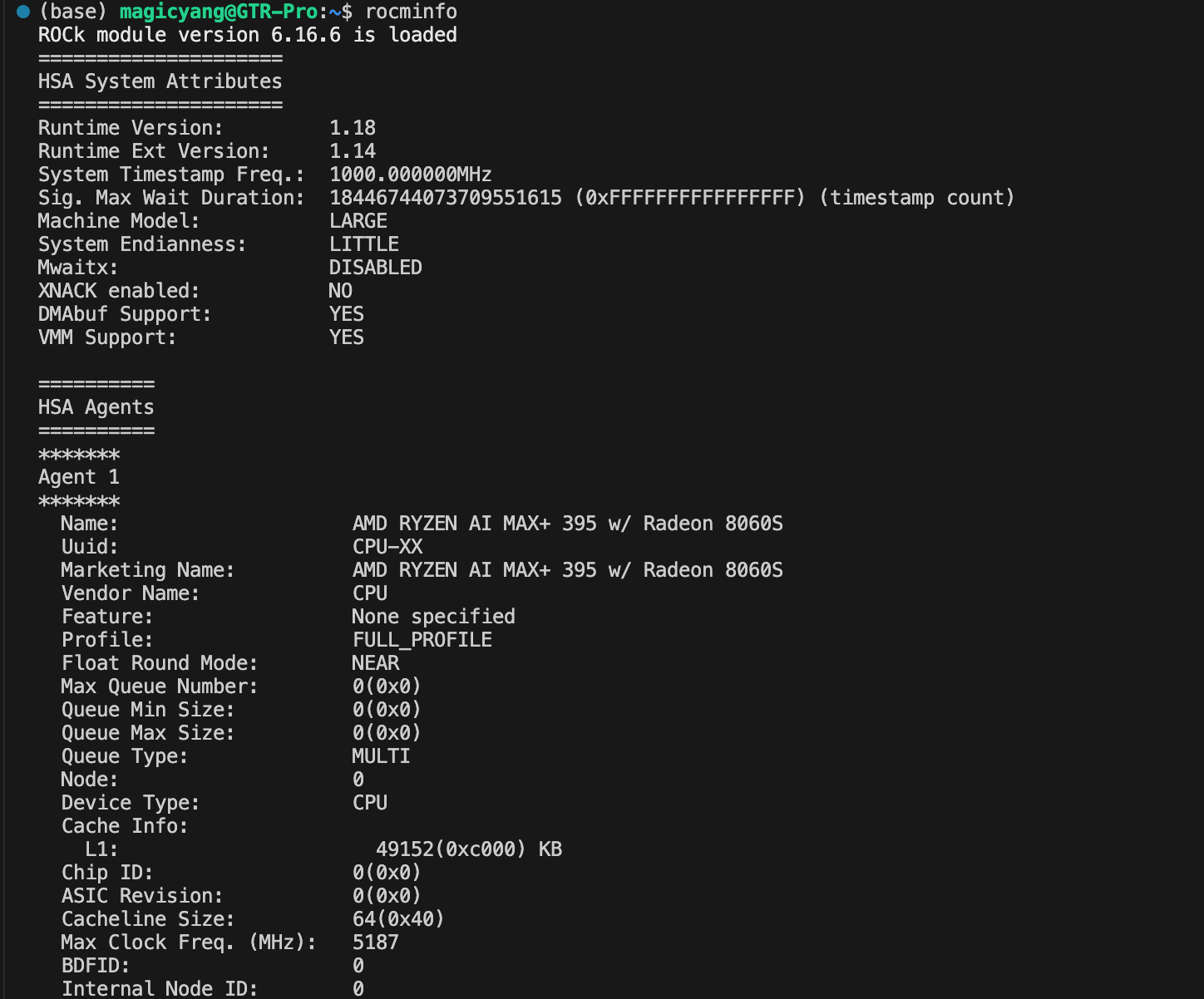
执行命令验证:
rocminfo
类似 NVIDIA 的 nvidia-smi 命令,AMD 的 GPU 可以使用如下命令来监控显卡运行状态:
rocm-smi

显存扩容
AI Max 395 分配显存大小有 2 种方案,最简单的方式是通过开机 BIOS 分配显存大小。另外一种则是通过修改 GTT 内存池参数大小。首先来看第一种:
通过 BIOS 进行分配
对于支持该处理器的设备(如 Framework 或特定 AI 工作站),步骤如下:
- 进入 BIOS:开机时反复按 F2 或 Delete 键进入。
- 进入高级菜单:使用方向键选择 Advanced 或 AMD CBS。
- 找到显存配置:路径通常为
iGPU Memory Configuration或GFX Configuration->UMA Frame buffer Size。 - 设置数值:
- 将配置模式设为 Custom(自定义)。
- 在
iGPU Memory Size中选择所需的显存大小。AI Max+ 395 配合 128GB 内存时,BIOS 通常允许分配最高 96GB 作为固定显存。
通过修改内核参数进行分配
实际上 AMD APU 的 GPU 并没有“固定显存”(CPU + GPU + NPU 被封装在同一个 SOC 上),本质上用的是系统内存 (UMA) 。GPU 显存其实就是系统内存的一部分。因此只要有足够的系统内存(例如 128GB、192GB), 理论上就可以让 GPU 直接用到非常大的“显存”。
而 Linux 上的 AMD GPU 驱动支持 GTT(Graphics Translation Table)内存池,这个扩显存的操作其实就是在扩大 GTT 池,而不是 VRAM。GPU 通过 IOMMU /内存映射直接访问系统 RAM 就像把系统内存当作“显存”使用。
因此除了 BIOS 设置外,还可以通过修改内核参数(如 amdttm.pages_limit)来实现超过 96GB 的极端分配(如 100GB+),需要需要通过 GRUB 命令行工具(如 grubby)进行配置。
sudo nano /etc/default/grub
找到 GRUB_CMDLINE_LINUX_DEFAULT 这一行,改成:
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash ttm.pages_limit=27648000 ttm.page_pool_size=27648000 amdttm.pages_limit=27648000 amdttm.page_pool_size=27648000 apparmor=0 amd_iommu=off"

这里通过修改内核参数可分配的显存大小不要超过 108G,根据 Jeff Geerling 测试的结果,目前 Linux 内核对 AMD 的兼容性并没有特别好,目前分配大小建议按照 27648000 来设置即可,不宜放得过大。
修改完成后 Ctrl+O 保存,并重启系统:
sudo update-grub
sudo grub-install
sudo reboot
重启后先执行以下命令检查,确认是否生效:
cat /proc/cmdline
设置共享内存大小(可选)
ROCm 使用共享系统内存池,默认配置为系统内存的一半。可以通过更改内核的转换表管理器(TTM)页面设置来增加此数量
安装 pipx:
sudo apt install pipx
将 pipx 安装的 wheels 路径添加到系统搜索路径中:
pipx ensurepath
从 PyPi 安装 amd-debug-tools:
pipx install amd-debug-tools
运行 amd-ttm 工具查询当前共享内存设置:
amd-ttm

使用 --set 参数重新配置共享内存设置(单位为 GB):
amd-ttm --set 16
注意:这里要共享的内存需要根据你分配给显存之后剩余的内存大小来设置。
重启系统以使更改生效:
sudo reboot
部署 GPUStack
GPUStack 是一个开源的 GPU 集群管理器,专为高效的 AI 模型部署而设计。它通过选择最佳推理引擎、调度 GPU 资源、分析模型架构以及自动配置部署参数,能够在自己的 GPU 硬件上高效运行大模型。

GPUStack 内置支持的后端推理引擎包括:
- vLLM
- SGLang
- MindIE
- VoxBox
并且可以通过添加自定义推理引擎的方式增加对 llama.cpp 的支持。
安装 Toolkit 和 Docker
- 在安装之前需要确保至少配备一个 AMD AI Max 395 GPU 节点。
- 确保工作节点上安装了 ROCm 驱动程序、Docker 和 AMD Container Toolkit 容器工具。
其中 Docker 版本 ≥ 28.3.0,Docker 的安装方法,请自行查阅教程,这里只给出 AMD Container Toolkit 的安装教程。
首先更新系统:
sudo apt update
添加当前用户到所需的 GPU 设备访问组:
sudo usermod -a -G render,video $LOGNAME
安装所需依赖项:
sudo apt update
sudo apt install vim wget nano gpg
创建密钥目录:
sudo mkdir --parents --mode=0755 /etc/apt/keyrings
安装 GPG 密钥和仓库链接:
wget https://repo.radeon.com/rocm/rocm.gpg.key -O - | gpg --dearmor | sudo tee /etc/apt/keyrings/rocm.gpg > /dev/null
添加 AMD Container Toolkit 仓库:
- Ubuntu 22.04:
echo "deb [arch=amd64 signed-by=/etc/apt/keyrings/rocm.gpg] https://repo.radeon.com/amd-container-toolkit/apt/ jammy main" | sudo tee /etc/apt/sources.list.d/amd-container-toolkit.list
- Ubuntu 24.04:
echo "deb [arch=amd64 signed-by=/etc/apt/keyrings/rocm.gpg] https://repo.radeon.com/amd-container-toolkit/apt/ noble main" | sudo tee /etc/apt/sources.list.d/amd-container-toolkit.list
更新软件包索引并安装工具包:
sudo apt update
安装 Toolkit:
sudo apt install amd-container-toolkit
注册 AMD 容器运行时并重启 Docker 守护进程:
sudo amd-ctk runtime configure
sudo systemctl restart docker
安装 GPUStack
使用 Docker 安装并启动 GPUStack Server 的命令如下:
sudo docker run -d --name gpustack \
--restart unless-stopped \
-p 80:80 \
--volume gpustack-data:/var/lib/gpustack \
gpustack/gpustack
注意:如果你想把 GPUStack 部署到其他端口(默认为 80 端口)可以修改为 xx:80,xx 即为你想部署的端口号
检查 GPUStack 启动日志:
sudo docker logs -f gpustack
GPUStack 启动后,运行以下命令获取默认管理员密码:
sudo docker exec gpustack cat /var/lib/gpustack/initial_admin_password
在浏览器中打开 http://your_host_ip 访问 GPUStack UI。使用默认用户名 admin 和上面获取的密码登录,登录完成后需要修改登录密码。
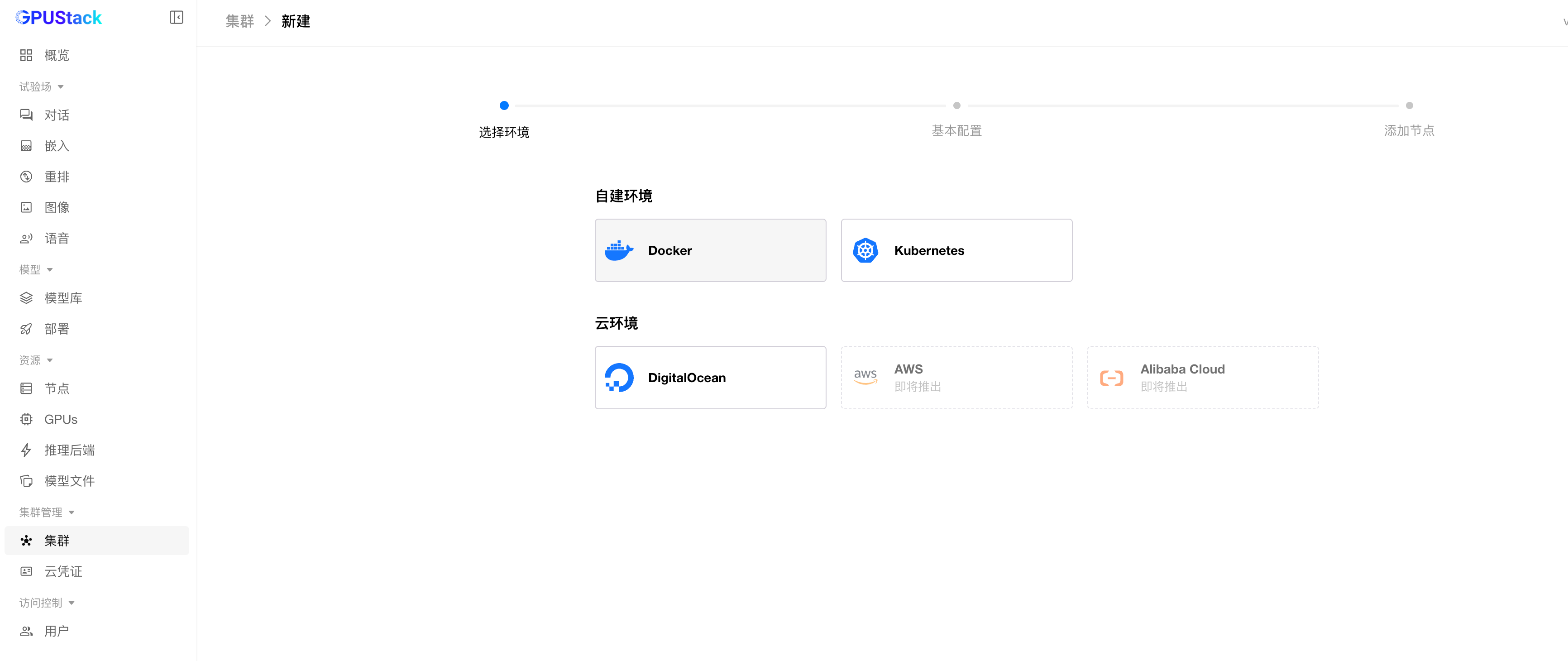
登录后还需要添加集群和节点信息,在集群管理页面点击集群,选择添加集群。自建环境选择 Docker:
基本配置页面填写一个集群名称,然后保存:
在添加节点页面的 GPU 厂商中选择 AMD,然后点击下一步:
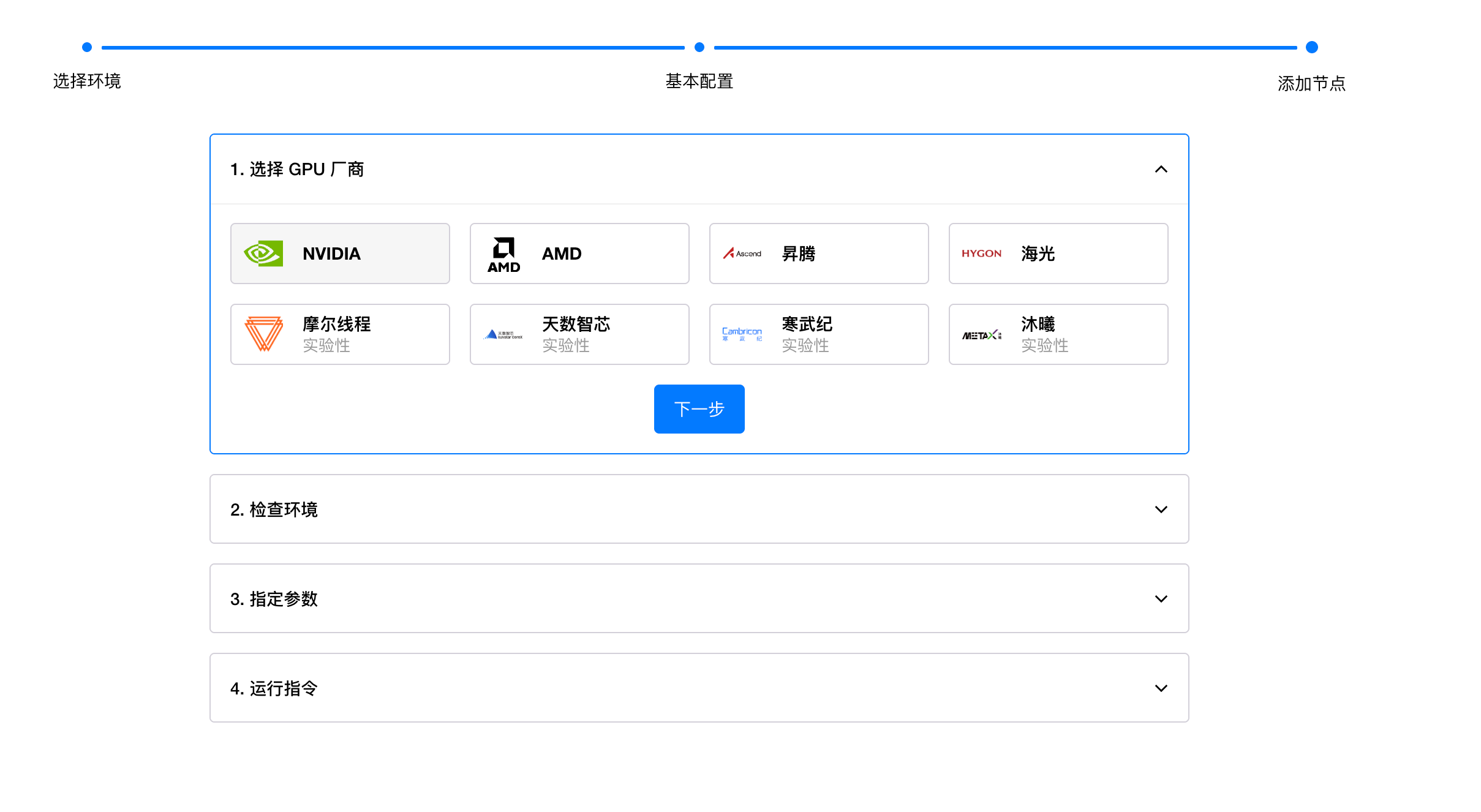
在这个页面会给出一个环境检查的命令,这里主要是需要检查前面已经安装好的 ROCm 驱动和 Docker 还有 AMD Container Toolkit:
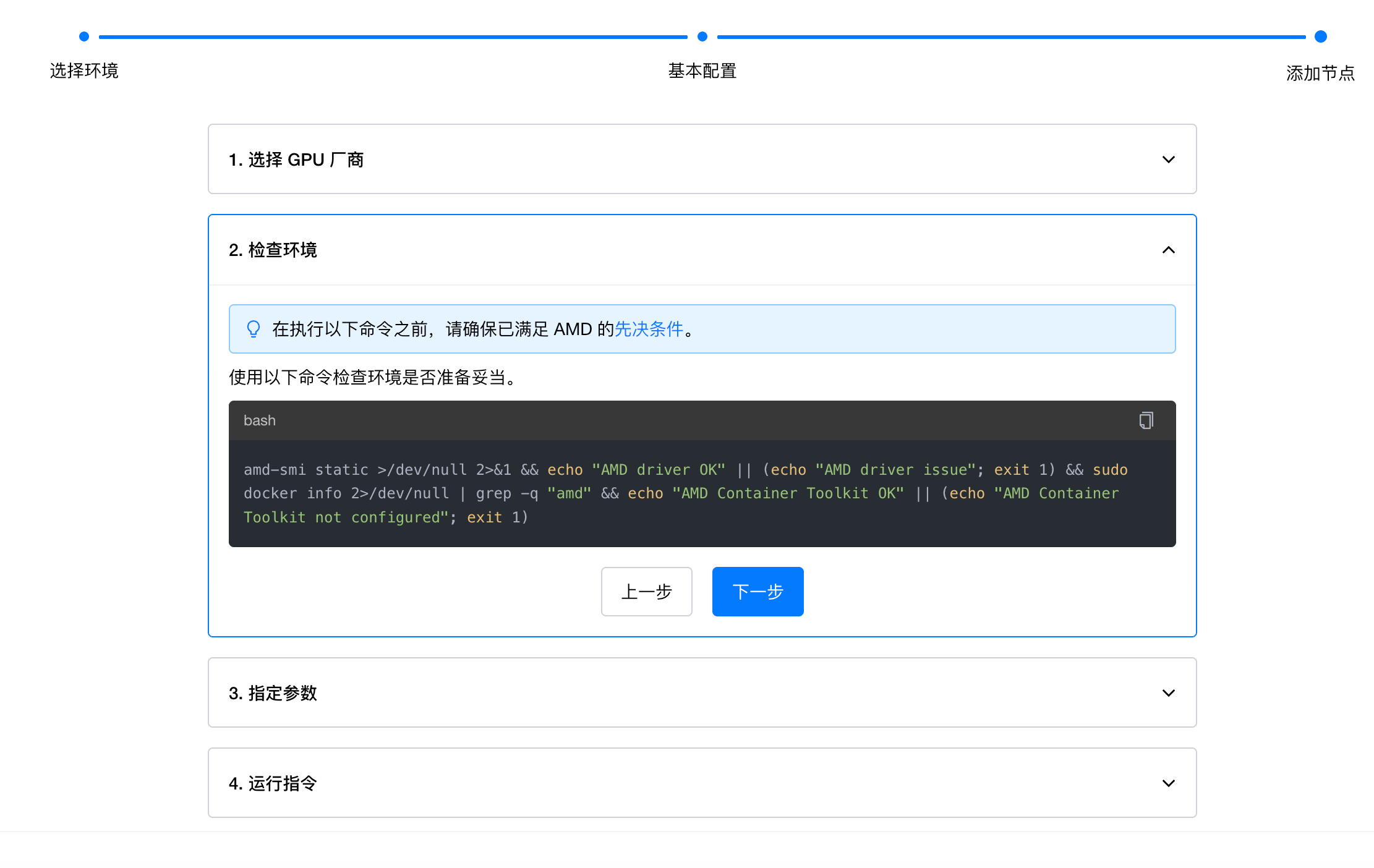
在终端中输入提示中的命令:
amd-smi static >/dev/null 2>&1 && echo "AMD driver OK" || (echo "AMD driver issue"; exit 1) && sudo docker info 2>/dev/null | grep -q "amd" && echo "AMD Container Toolkit OK" || (echo "AMD Container Toolkit not configured"; exit 1)
正常情况会输出两个 OK,如果没有,请检查 ROCm,Docker 和 amd-container-toolkit 是否成功安装。

然后在节点 IP 中输入本机的局域网 IP 地址:
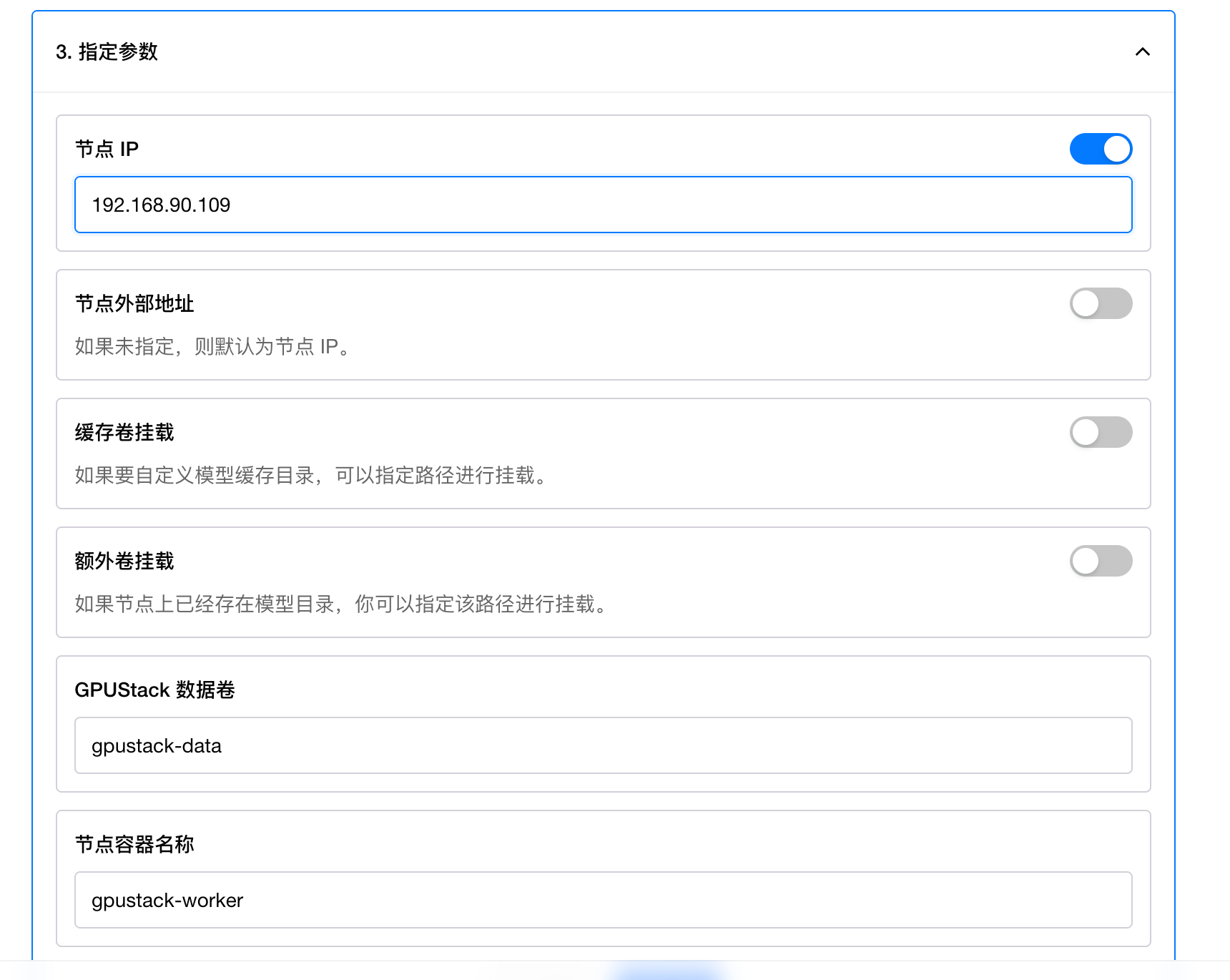
然后点击完成。会出现添加节点的命令:
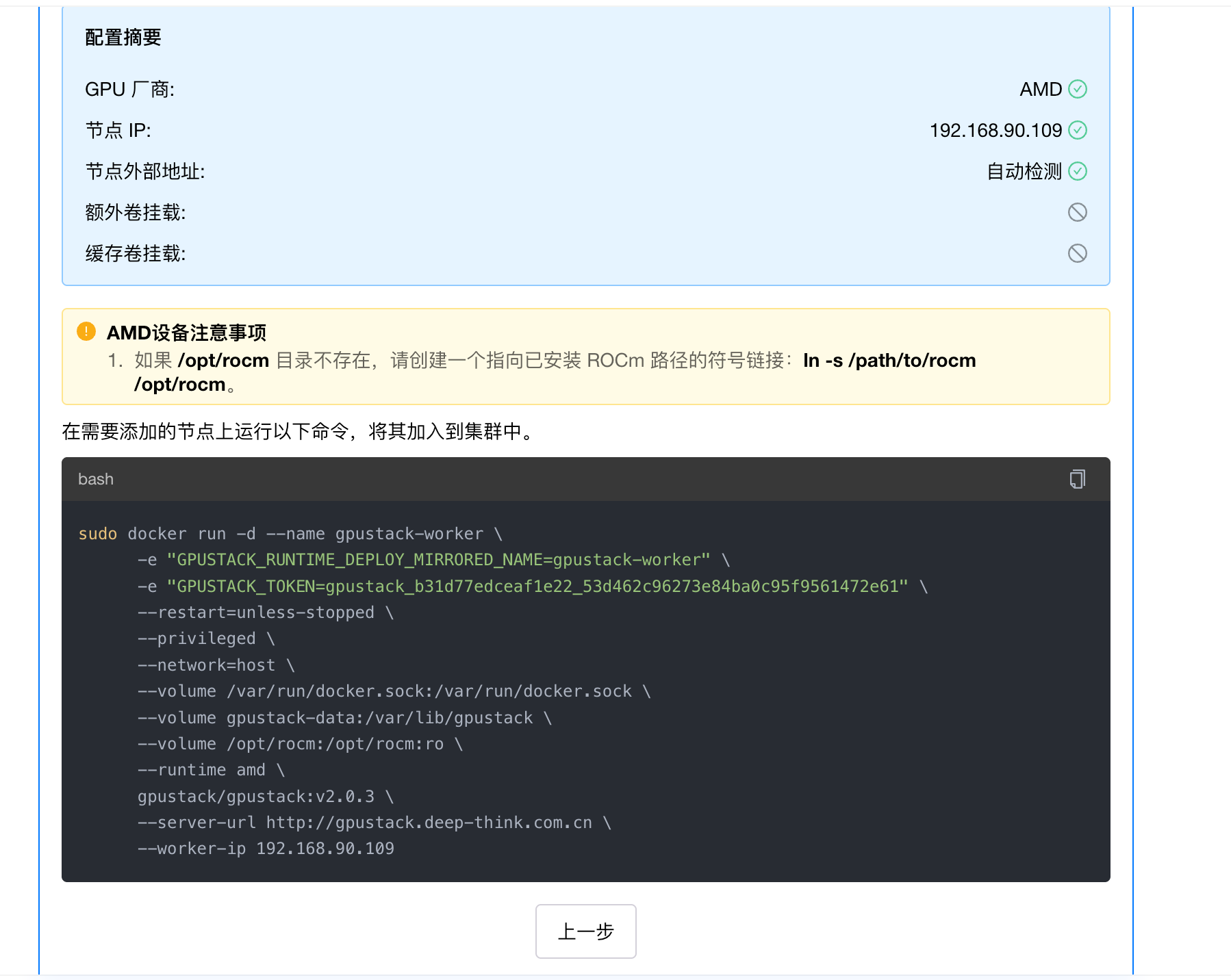
复制该命令,在终端中运行,后台会自动拉取 Docker 镜像,启动一个名为 gpustack-worker 的容器。
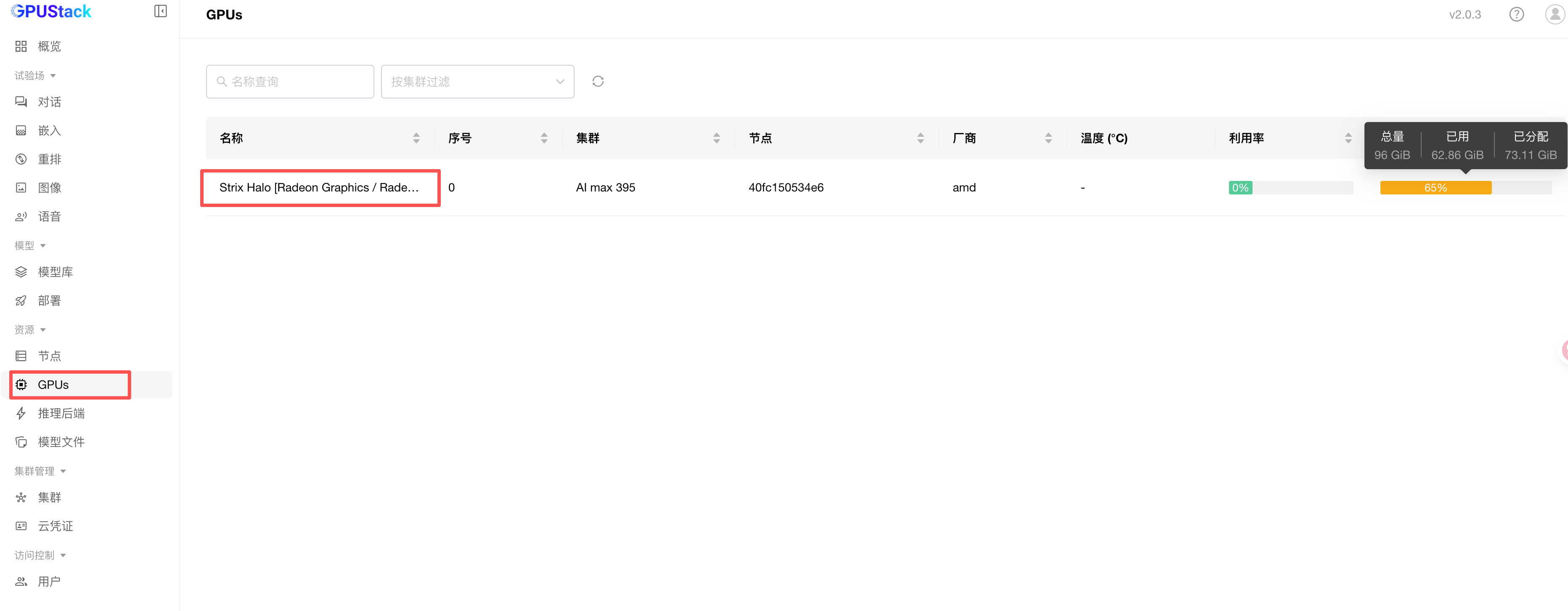
如果容器启动成功没有报错,回到资源下的 GPUs 页面,就可以看到 AI Max 395 被 GPUStack 成功识别了。
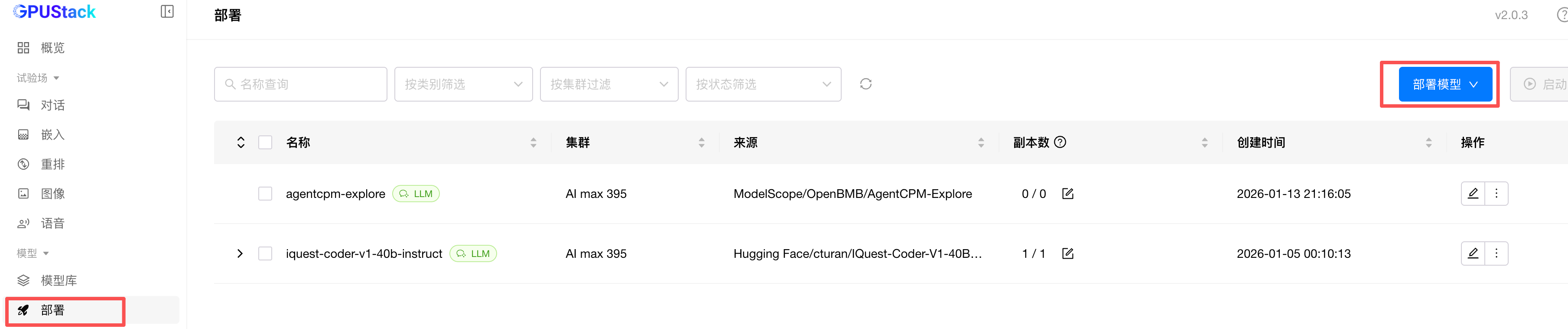
部署 AgentCMP-Explore 模型 API 服务
GPU 被成功识别之后,点击模型下面的部署,点击部署模型:
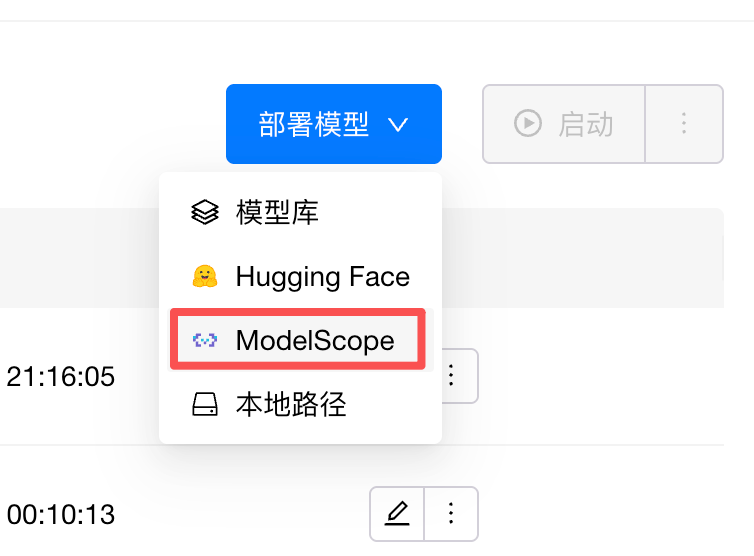
在部署模型下拉选框中选择 ModelScope:
在搜索框中输入 AgentCPM,选择第一个 AgentCPM-Explore:
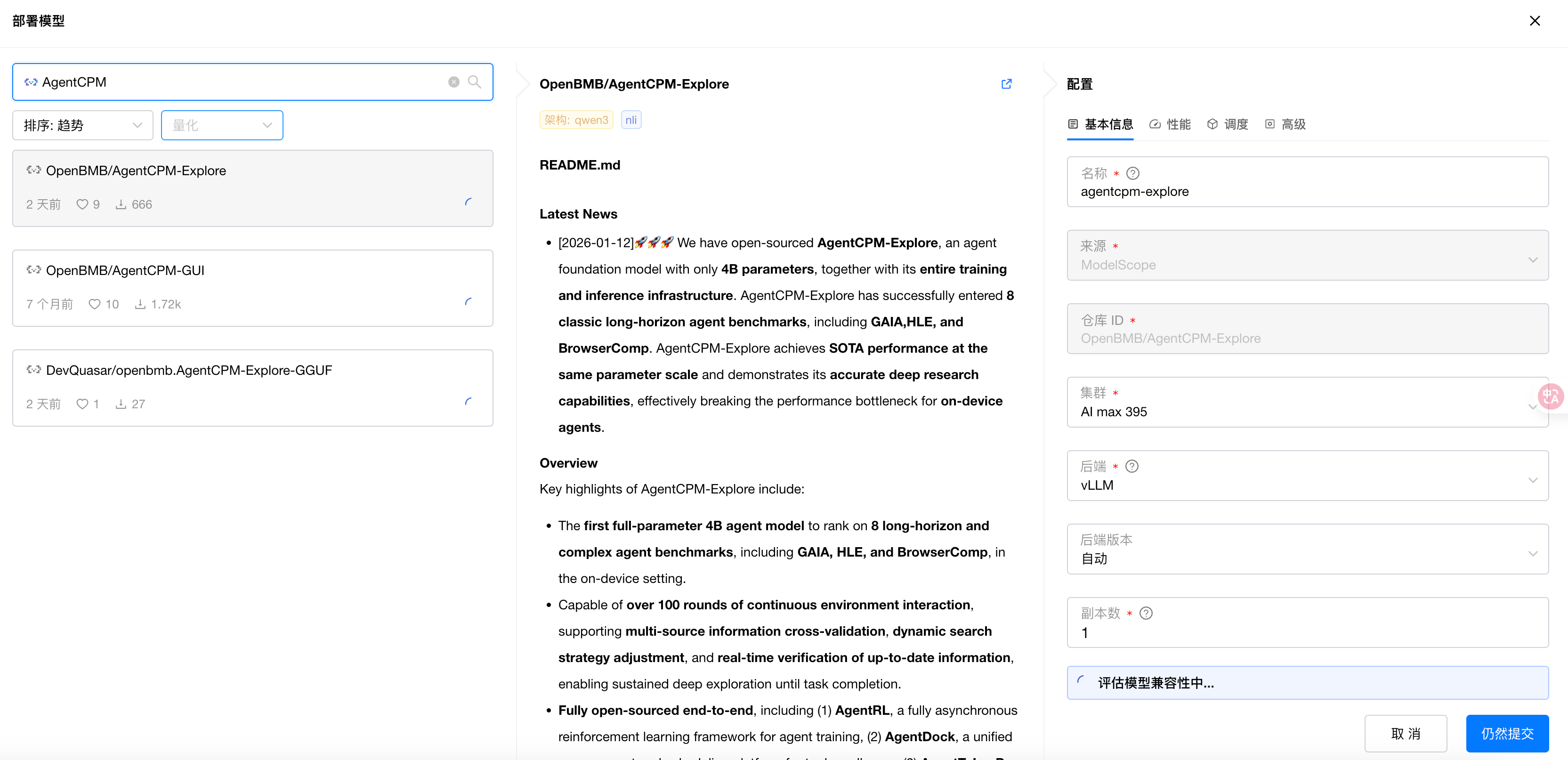
在右侧弹出的配置信息中后端选择 vLLM,版本选择 0.13.0:
然后在高级中,添加两个参数:
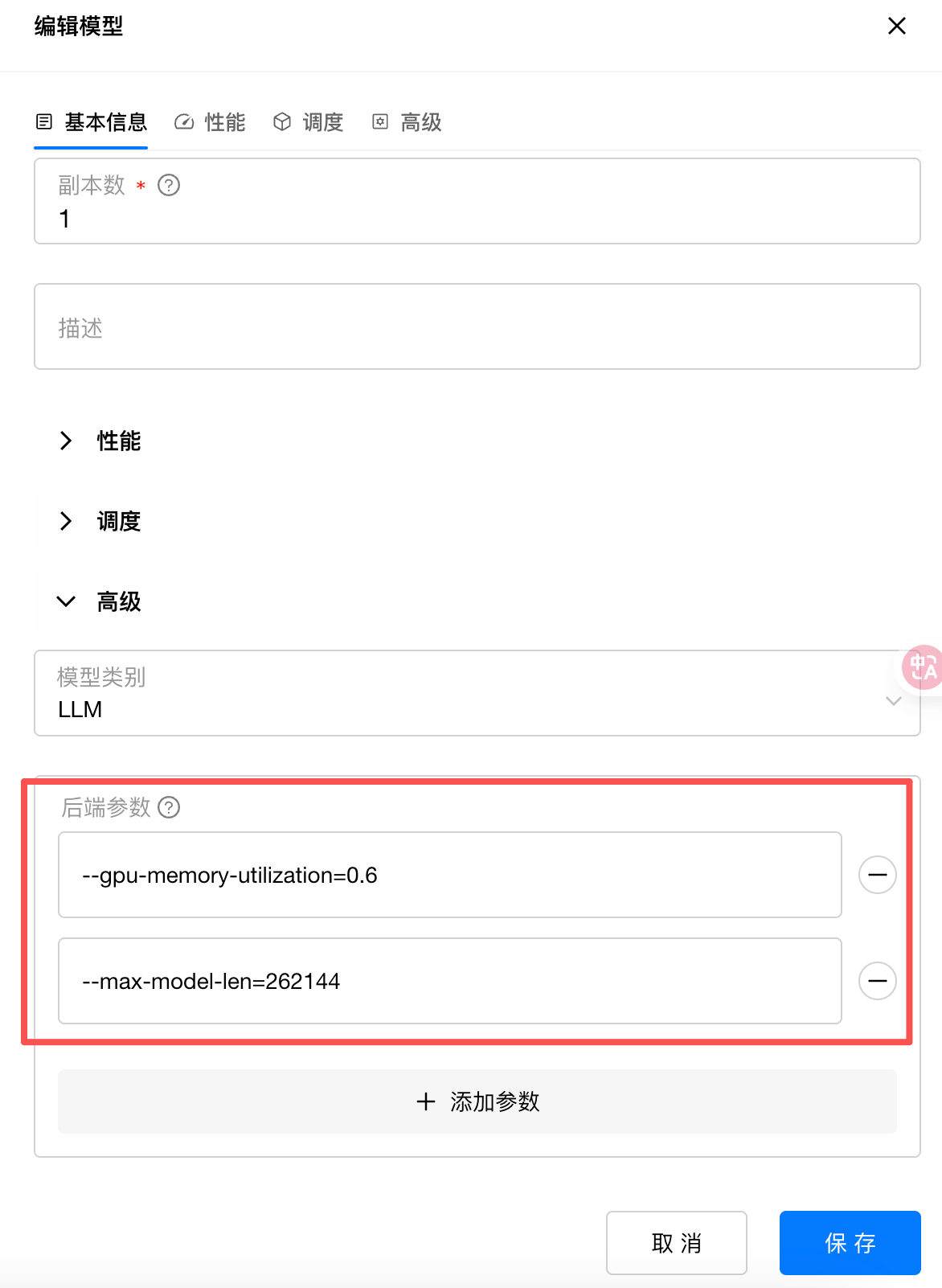
其中:
--gpu-memory-utilization=0.6 是分配给 AgentCPM-Explore 这个模型 60% 显存资源,大概为60G。
--max-model-len=262144 是设置的模型最大上下文长度,我这里设置了 256k 的最大上下文,如果你不需要这么大的上下文,可以调整这个大小,这样可以显著节省显存开销。
设置完成后点击保存,后台会自动从 ModelScope 拉取模型权重,并且拉取 vLLM 的镜像,用于启动模型。这个过程会比较漫长,需要静静等待,启动时可以打开查看日志按钮来查看启动情况:
当日志出现如下接口信息时,代表模型已经启动成功了:
当模型完全启动成功之后显示 Running 时,代表模型 API 服务启动成功了!

那我们要如何获取接入 AgentCPM 的 API Key ,URL 和模型名称等信息呢?点击右侧的三个点会出现 API 接入信息:
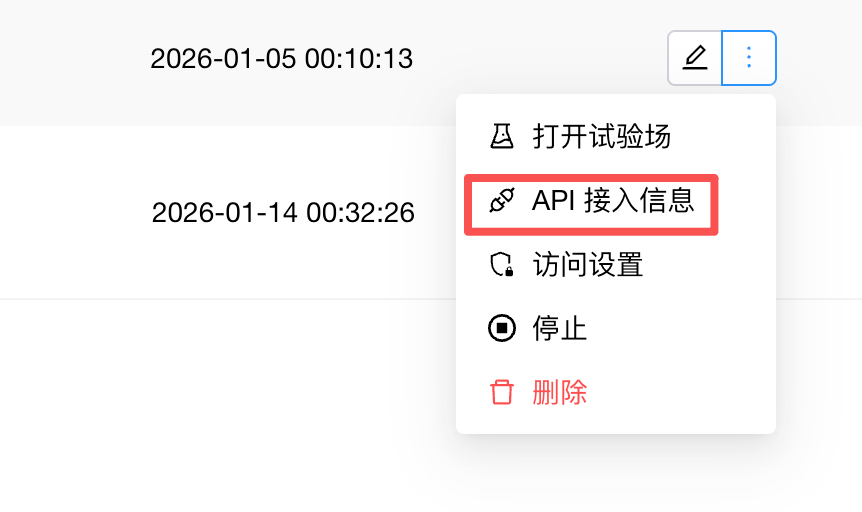
在这里会显示接入模型 API 需要填写的参数信息,包括 URL 地址,模型名称:
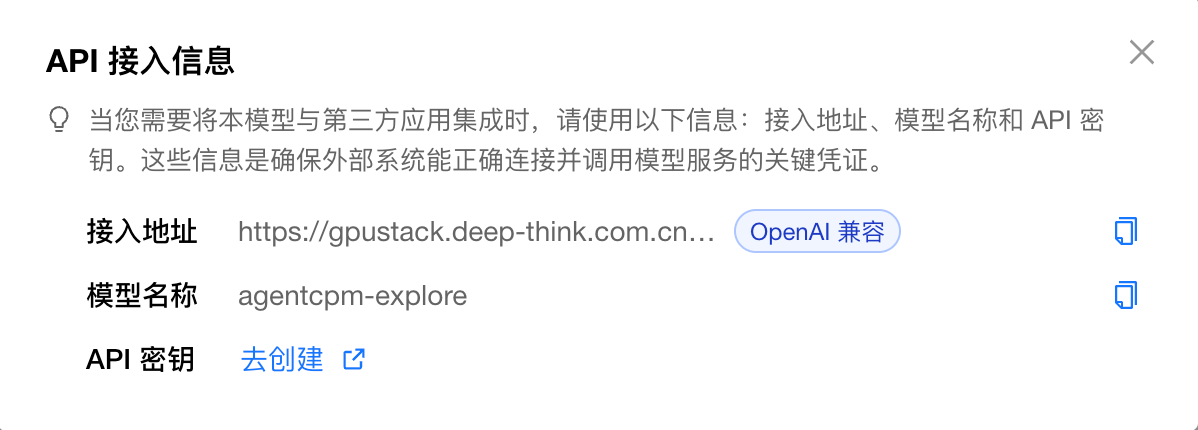
最后我们还需要创建一个 API Key 进行认证,以防止别人盗用模型接口,按照提示点击去创建:
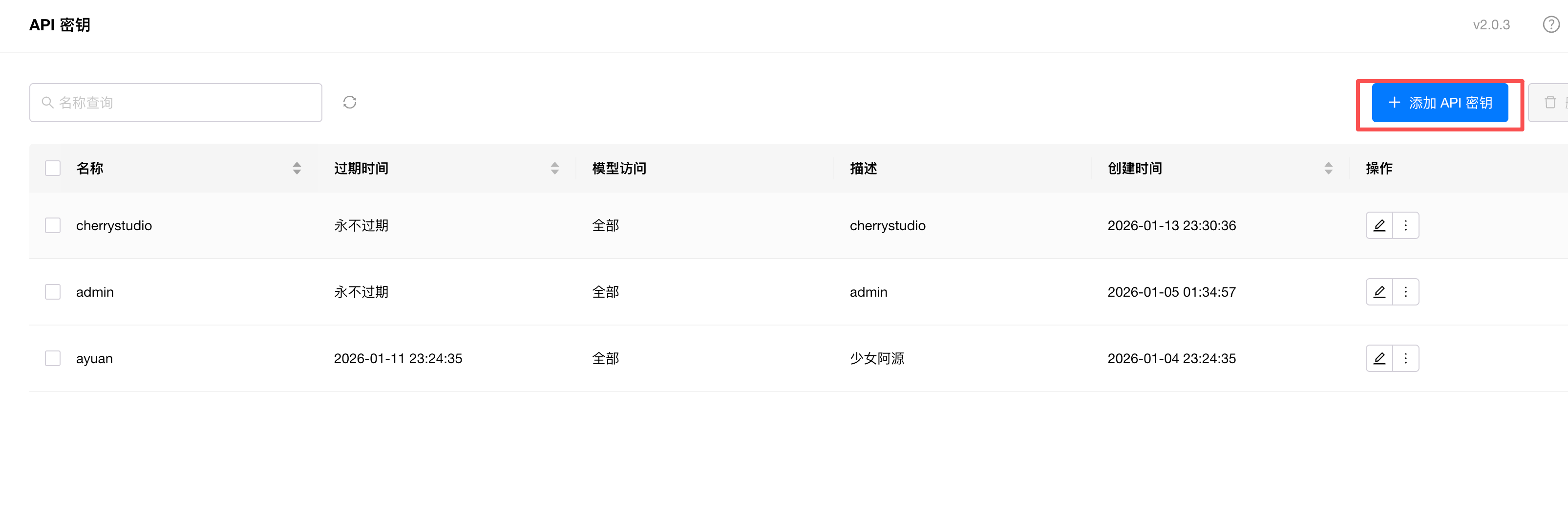
然后在 API 密钥添加页面添加一个 API Key 即可:
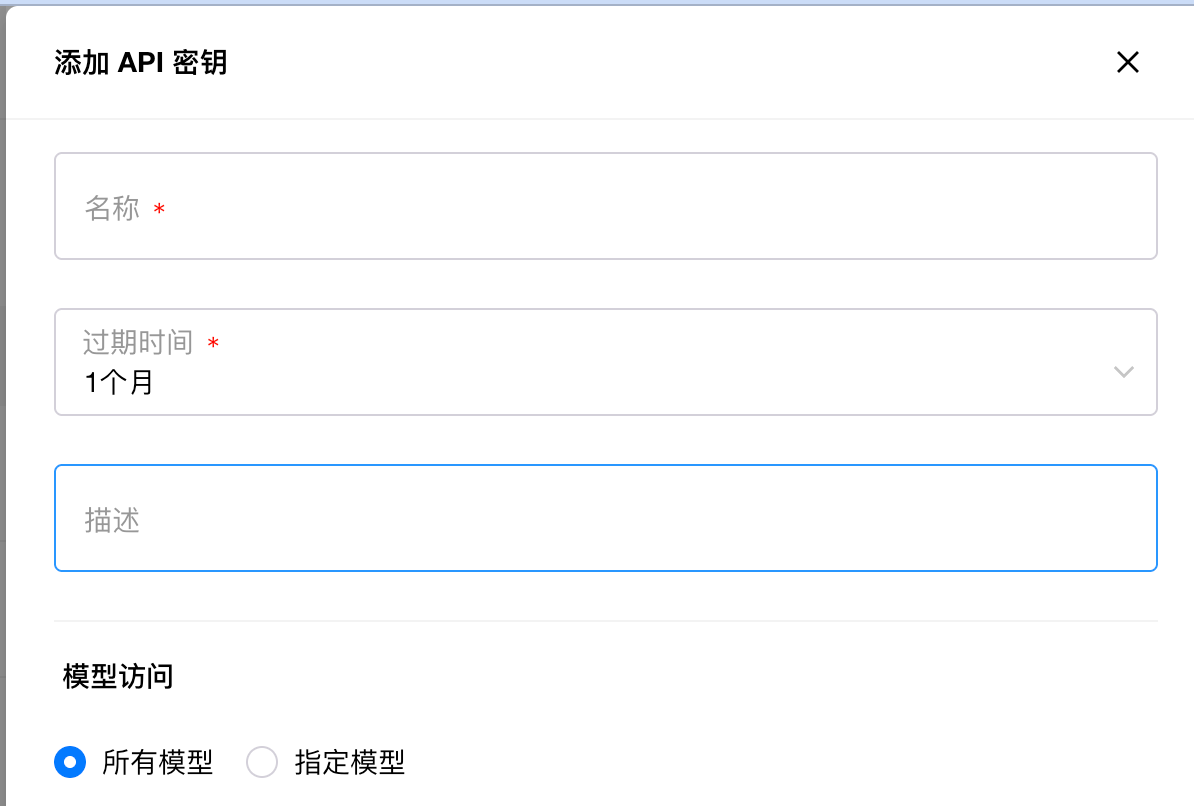
这样我们的模型部署就全部完成了。
使用 AgentCPM-Explore 进行联网搜索任务
在 Cherry Studio 客户端中,在模型服务中找到 GPUStack,然后将刚刚部署好的模型接口信息填入。
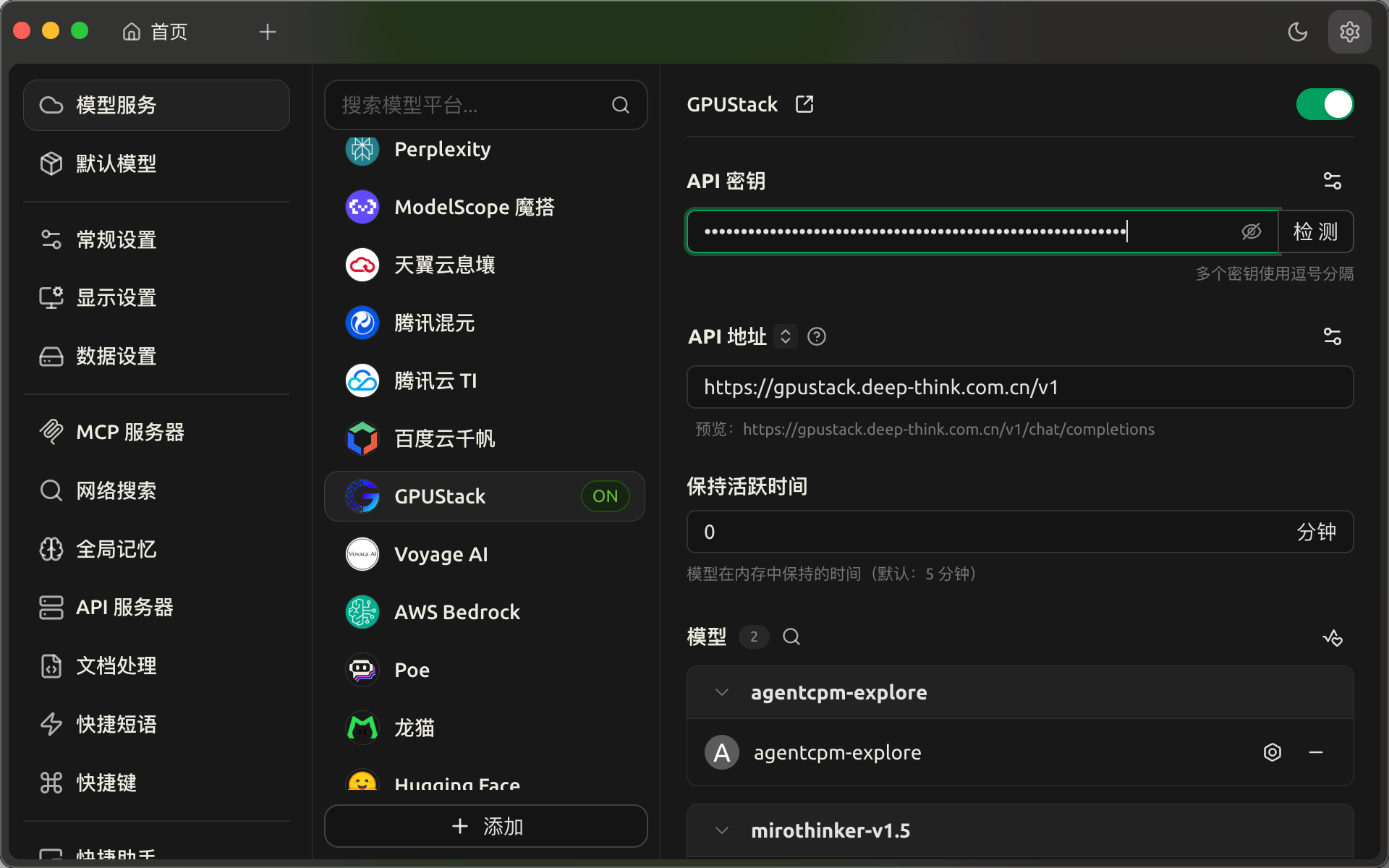
添加完成之后可以点击检测,如果通过会显示一个✅,这就代表模型接入成功了。
然后回到助手页面,就可以实现问答了:
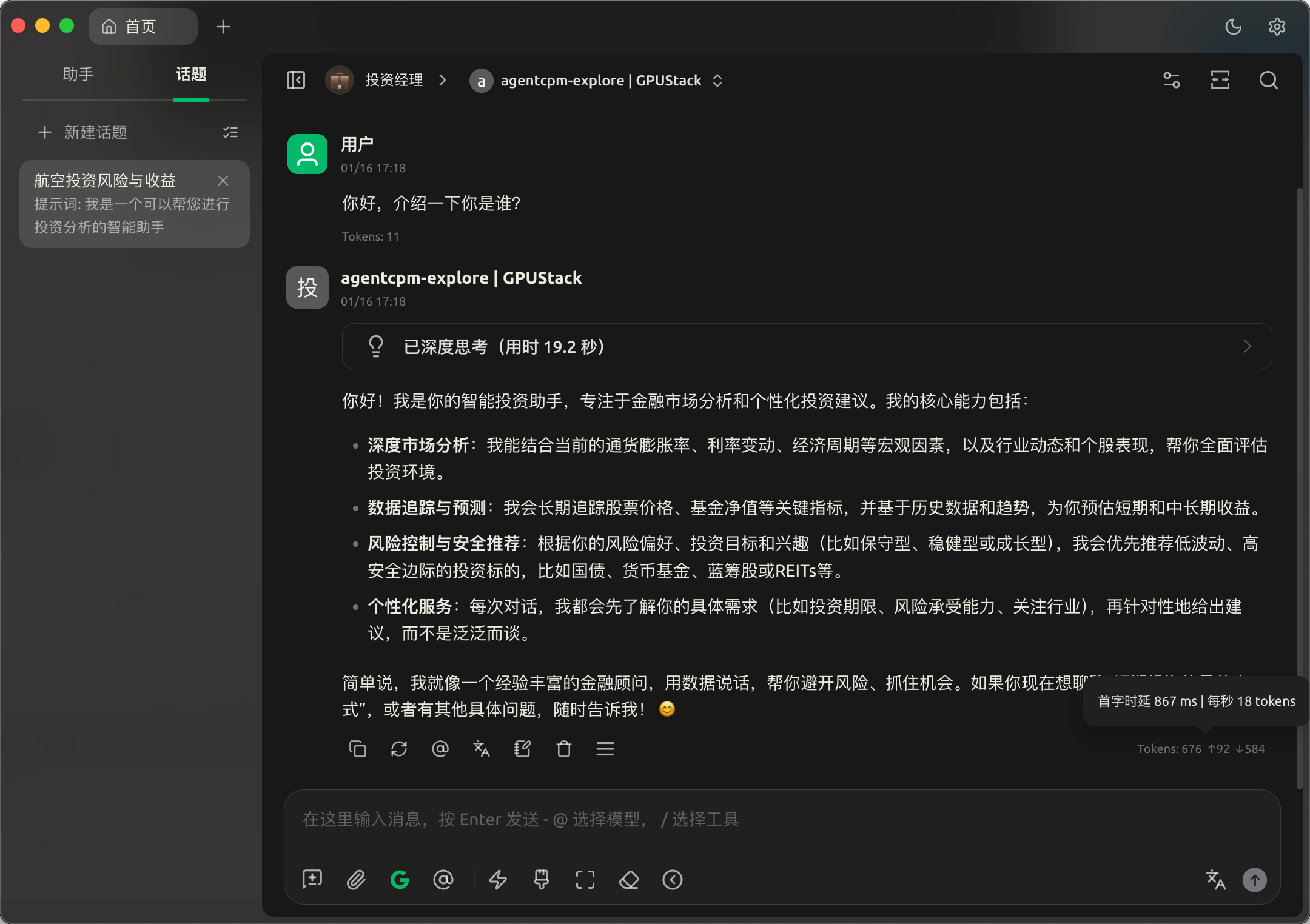
我这里之前有配置了一个投资分析助手的提示词,通过 Cherry Studio 的 Google 搜索插件,就可以实现用 AgentCPM-Explore 结合 Google 搜索,完成类似 DeepResearch 的联网搜索问答任务。
这里只是测试了 Agent 调用搜索引擎的能力,如果要实现完整的 DeepResearch 功能,建议使用 AgentCPM-Report 通过接入开源的 Deep Research 框架项目即可。
从测试的 case 可以看到 AI Max 395 的 AgentCPM-Explore 吞吐速度为首 token prefill 867ms,生成速度大概为 18 tks/s,这个速度对于单用户本群请求完全够用了,以上就是全部内容了。
使用 AgentCPM-Report 进行 DeepResearch 任务
AgentCPM-Report 核心亮点
- 极致效能,以小博大:通过平均 40 轮的深度检索与近 100 轮的思维链推演,实现对信息的全方位挖掘与重组,让端侧模型也能产出逻辑严密、洞察深刻的万字长文,在深度调研任务上以 8B 参数规模达成与顶级闭源系统的性能对标。
- 物理隔绝,本地安全:专为高隐私场景设计,支持完全离线的本地化敏捷部署,彻底杜绝云端泄密风险。基于我们的 UltraRAG 框架,它能高效挂载并理解本地私有知识库,让核心机密数据在“不出域”的前提下,安全地转化为极具价值的专业决策报告。
接下来我们先在 AI Max 395 上实现用 llama.cpp 来部署 AgentCPM-Report 模型服务。
部署 AgentCPM-Report 模型 API 服务
目前 OpenBMB 开源了 2 个格式的 AgentCPM-Report 模型,一个是标准的 safetensors 格式模型,推理框架可以选择使用 vLLM 进行推理,部署方式和上文中的 AgentCPM-Explore 模型相同,这里不再重复。
另外一个则是 GGUF 格式的模型,这种格式适合在 GPU 资源受限的情况下,使用 CPU+GPU 一起进行推理,特别适合类似 AI Max 395 这种统一内存架构的核显 mini 主机设备。
和 AgentCPM-Explore 部署方式类似,我们仍然选择使用 GPUStack 来完成 AgentCPM-Report 模型服务的部署,和前面的差别是 GGUF 格式需要使用 llama.cpp 的后端推理框架。
因为目前最新的 2.0.3 版本的 GPUStack 已经不再默认内置 llama.cpp,因此我们需要通过配置自定义后端推理框架的方式来实现 llama.cpp 后端的支持。
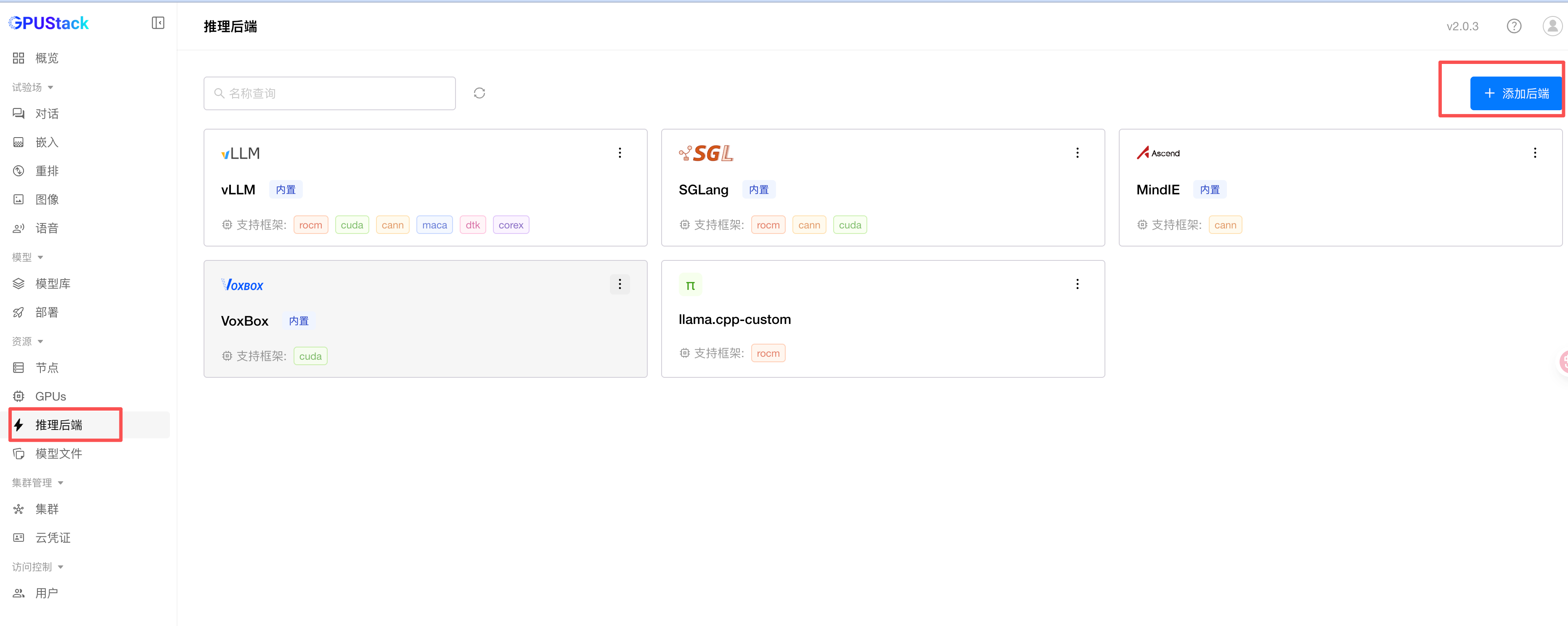
添加和使用推理后端的操作步骤如下:
如下图所示在推理后端页面,选择添加后端:
在添加后端页面选择 YAML 模式。示例:
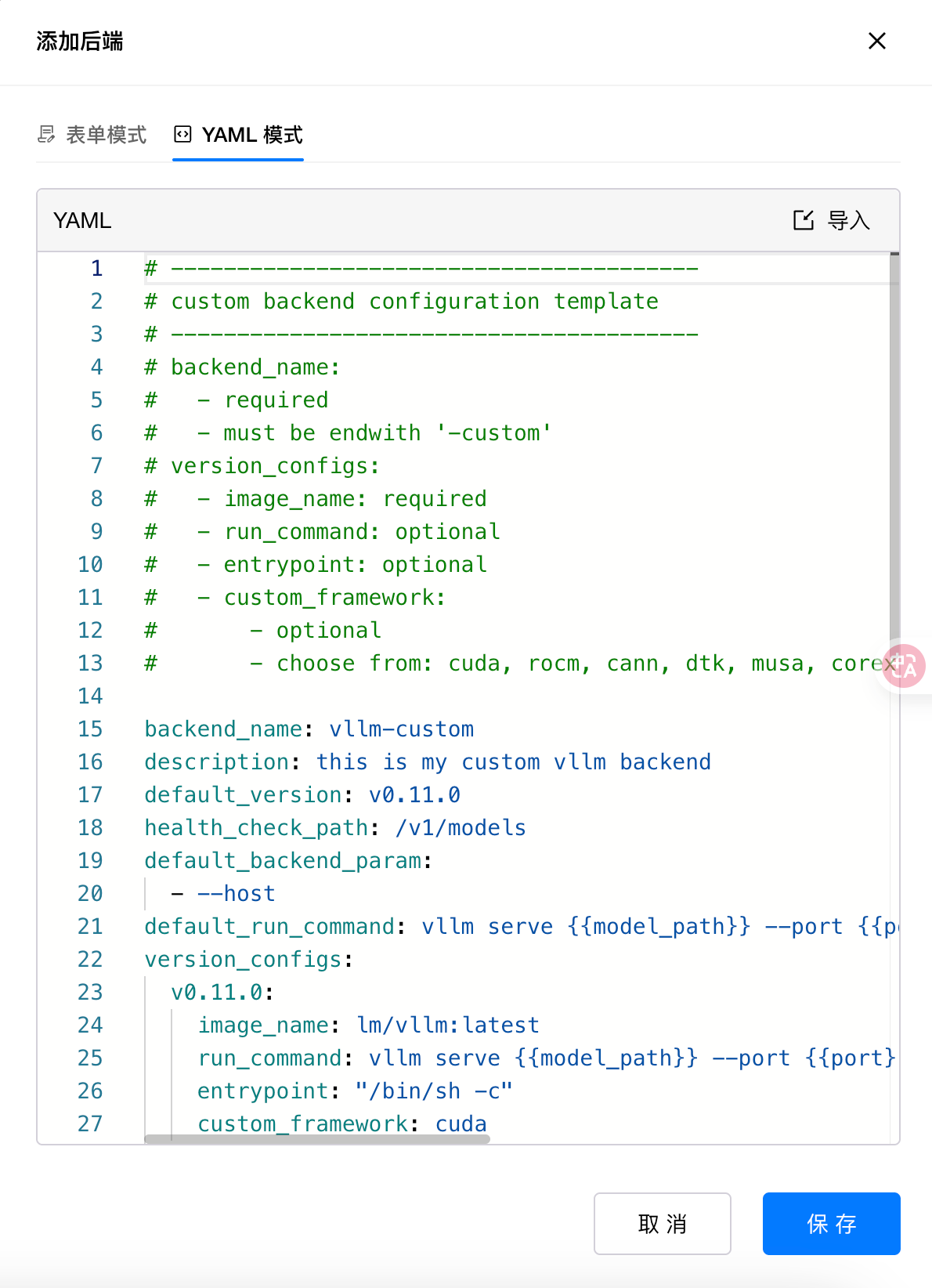
使用如下 YAML 配置文件信息替换为如下代码:
backend_name: llama.cpp-custom
version_configs:
v1:
image_name: ghcr.io/ggml-org/llama.cpp:server-vulkan
run_command: null
entrypoint: null
custom_framework: rocm
default_version: v1
default_backend_param: []
default_run_command: '-m {{model_path}} --host 0.0.0.0 --port {{port}}'
default_entrypoint: ''
is_built_in: false
description: null
health_check_path: null
built_in_version_configs: {}
framework_index_map:
rocm:
- v1
然后保存,接着在部署页面输入 agentcpm-report,找到 GGUF 格式的模型,然后在后端中选择用户定义分类下的 llama.cpp ,然后部署。
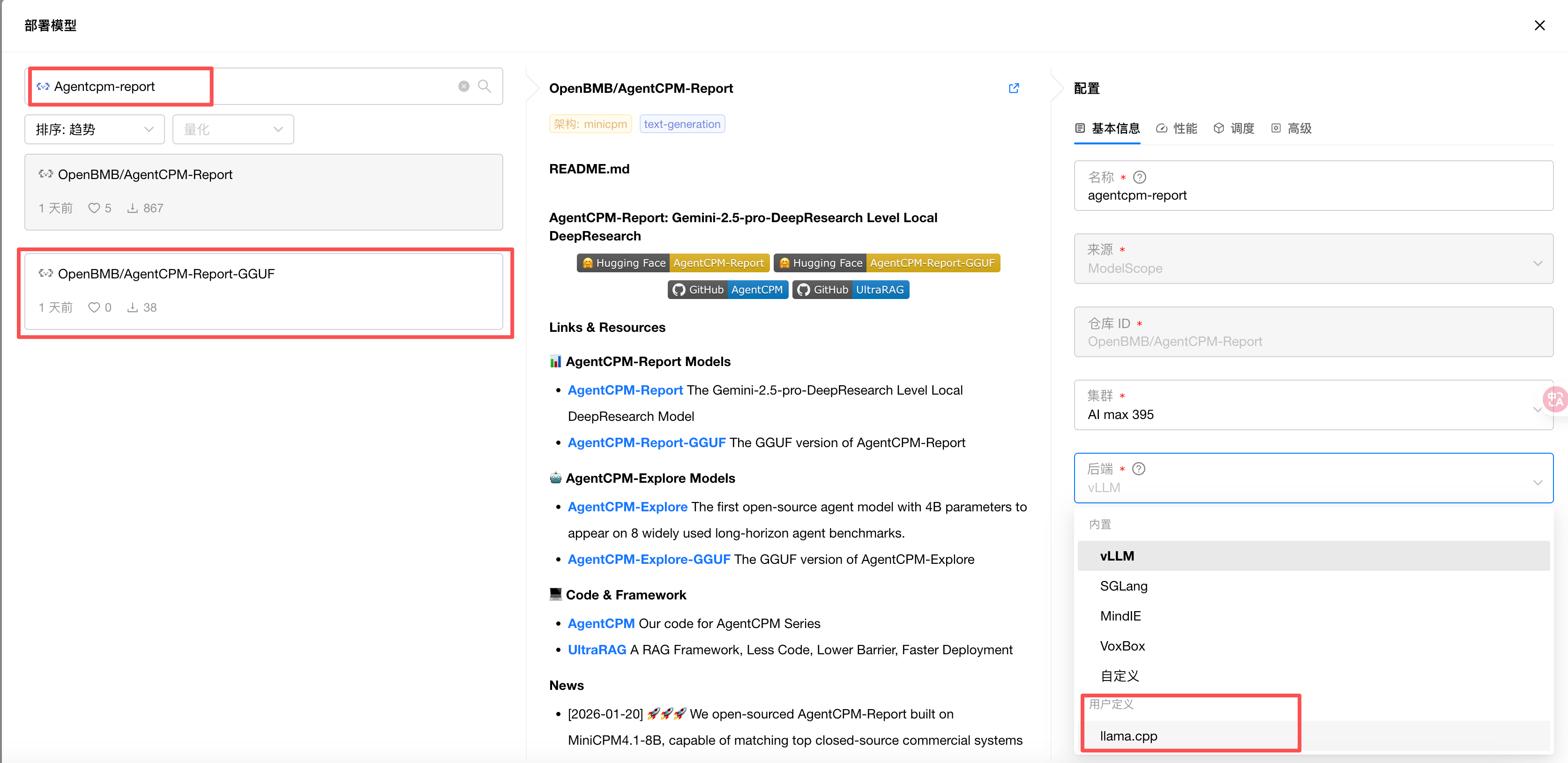
然后在高级中配置环境变量与命令行启动参数,详细的环境变量与命令行参数信息可以参考下表:
核心环境变量一览表
| 环境变量 | 对应参数 | 默认值 | 描述 |
|---|---|---|---|
| LLAMA_ARG_THREADS | -t, --threads | -1 | 生成线程数 |
| LLAMA_ARG_CTX_SIZE | -c, --ctx-size | 4096 | 上下文大小 |
| LLAMA_ARG_N_PREDICT | -n, --n-predict | -1 | 预测token数 |
| LLAMA_ARG_N_GPU_LAYERS | -ngl, --n-gpu-layers | 0 | GPU层数 |
| LLAMA_ARG_MODEL | -m, --model | - | 模型路径 |
| HF_TOKEN | -hft, --hf-token | - | HuggingFace令牌 |
配置参数系统化分类
性能调优参数
# CPU配置
LLAMA_ARG_THREADS=8 # 使用 8 个线程
LLAMA_ARG_THREADS_BATCH=4 # 批处理线程数
# 内存管理
LLAMA_ARG_MLOCK=1 # 锁定模型在内存中
LLAMA_ARG_NO_MMAP=0 # 启用内存映射
# GPU卸载
LLAMA_ARG_N_GPU_LAYERS=24 # 24 层卸载到 GPU
LLAMA_ARG_SPLIT_MODE=layer # 分层拆分模式
模型加载参数
# 本地模型加载
LLAMA_ARG_MODEL="/path/to/model.gguf"
# 远程模型下载
LLAMA_ARG_HF_REPO="ggml-org/gemma-3-1b-it-GGUF"
HF_TOKEN="your_hf_token_here"
# 多模态支持
LLAMA_ARG_MMPROJ="/path/to/mmproj.bin"
生成控制参数
# 上下文管理
LLAMA_ARG_CTX_SIZE=8192 # 8K 上下文
LLAMA_ARG_KEEP=512 # 保留 512 个初始 token
# 生成限制
LLAMA_ARG_N_PREDICT=256 # 最大生成 256 token
LLAMA_ARG_TEMP=0.7 # 温度 0.7
# 重复控制
LLAMA_ARG_REPEAT_PENALTY=1.1
LLAMA_ARG_REPEAT_LAST_N=64
介绍完以上参数含义后,根据 AI Max 395 的性能,这里推荐的环境变量参数为:
LLAMA_ARG_THREADS=16
LLAMA_ARG_CTX_SIZE=65536
LLAMA_ARG_N_PREDICT=512
LLAMA_ARG_TEMP=0.1
LLAMA_ARG_MLOCK=1
在 GPUStack 中环境变量和命令行启动参数配置方法,如下图所示:
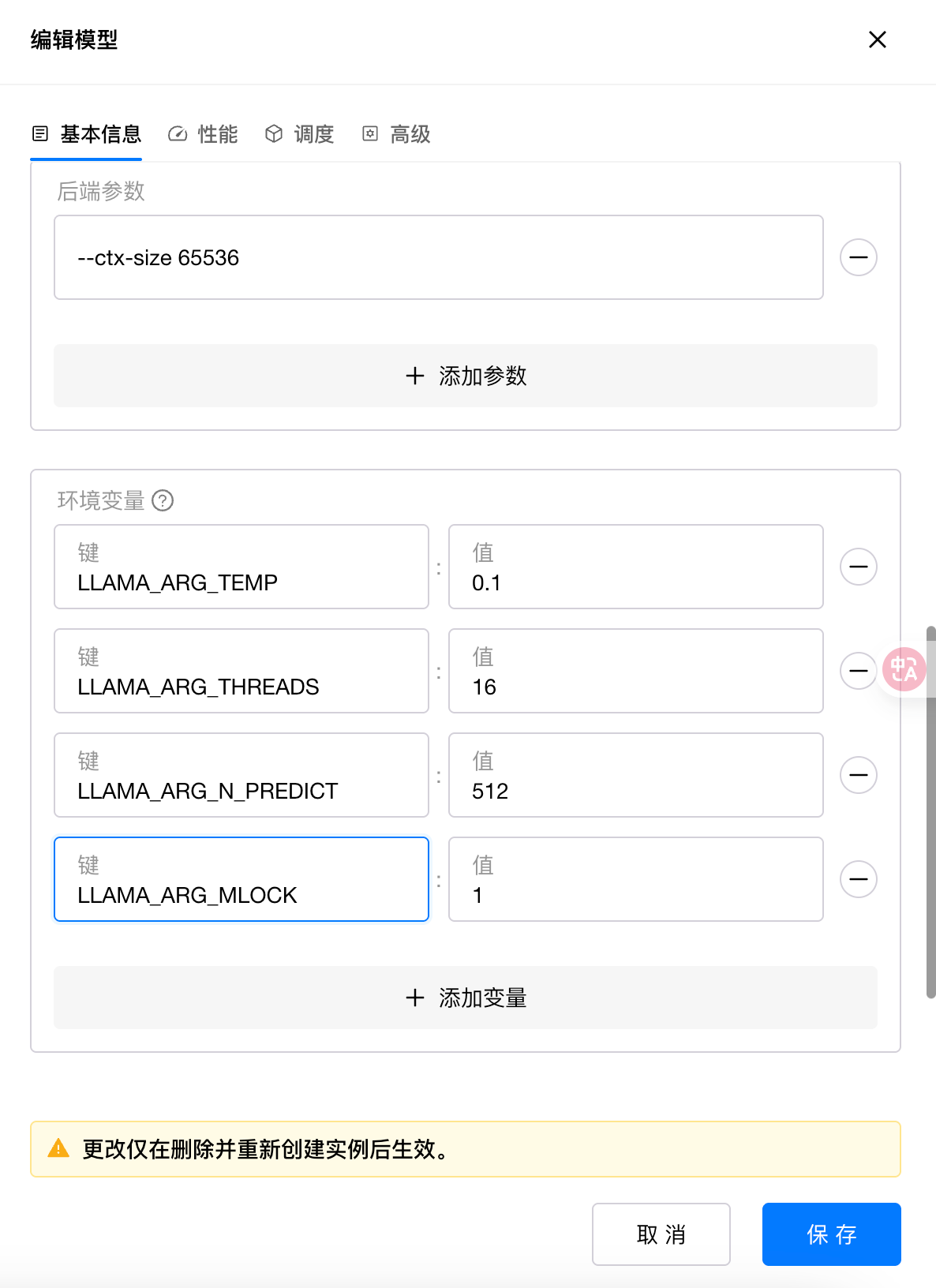
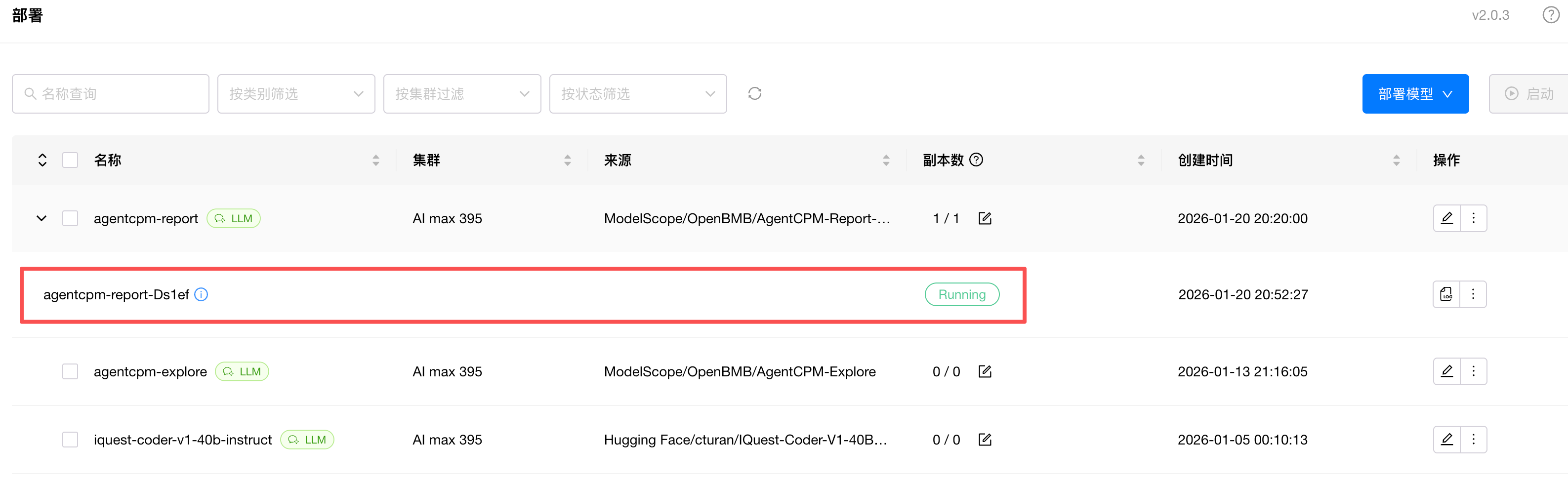
需要注意的是 --ctx-size 65536 这个参数我设置为 64K,也是 AgentCPM-Report 支持的最大上下文长度,实际的参数可以根据你的实际需要来灵活调整。保存完成后,模型后台会自动下载模型文件并启动 API 服务,当出现绿色 Running 图标时,则代表模型启动成功了。
部署完成后,就可以将 agentcpm-report 接入到任意的 Deep Research 框架下了。以下为我接入 Dify 构建的 Deep Research 框架测试的效果,后续大家觉得有必要的话欢迎留言,我会更新接入 mirothinker 的效果测试:
加入 GPUStack 社区
GPUStack 社区是一个围绕 AI 基础设施与大模型推理实践展开的技术交流空间。
在这里,你可以看到真实环境下的 AI Infra 与大模型推理的部署经验、问题排查过程,以及围绕推理引擎、算力管理和系统架构的持续讨论。
无论你正处于模型基础设施的评估、试用还是规模化部署阶段,都可以在社区中找到有参考价值的信息。
欢迎扫码加入 GPUStack 社区,与更多关注 AI Infra 与大模型推理实践的伙伴一起交流、学习与分享。

若群聊已满或二维码失效,请访问以下页面查看最新群二维码:
https://github.com/gpustack/gpustack/blob/main/docs/assets/wechat-group-qrcode.jpg
【文章来源: https://my.feishu.cn/wiki/ABm9w1j0Bie6eOk1zDtcrocdnRe 】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号