

0树莓派
Python 使用 mpg123 播放声音
安装 mpg123
执行命令:sudo apt-get install mpg123
播放声音
import os
os.system('mpg123 test.mp3')
备注 2:树莓派设置音频输出
- 执行命令:
sudo raspi-config -
选中 Advanced Options
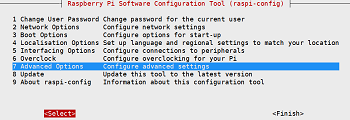
-
选中 Audio
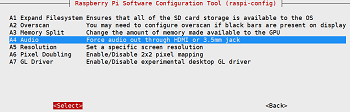
-
选中对应的输出方式
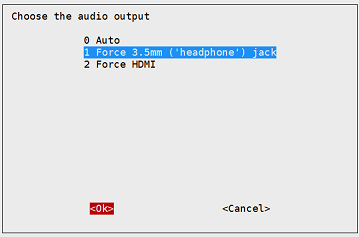
#from func import speak
# -*- coding: utf-8 -*-
#如果系统默认pytho路径不是 python3 我认为修改成3了
#import sys
#sys.path.append("/home/pi/.local/lib/python2.7/site-packages")
import click
import os
from urllib.parse import quote
import urllib.request
def speak(text):
#文字编码后结果
text_encoded = quote(text.encode('utf8'))
#获取密钥 这个网站自己获取了密钥 如果是自己的帐号需要自己替换
url = "https://ilangbd.azurewebsites.net/token.txt"
get_token=urllib.request.urlopen(url).read()
token = str(get_token)
token=token.split('\'' )[1]
#token='24.cec28b1805703b84010325a0d08fdb25.2592000.1587258841.282335-10778068'
print(token)
voice_url = "http://tsn.baidu.com/text2audio?tex=" + text_encoded + "&lan=zh&per=0&cuid=784f436aa242&ctp=1&tok=" + str(token)
print("Now read: ")
print(text)
os.system('mpg123 -q "%s"'% voice_url)
if __name__ == '__main__':
#当作方法直接调用 语音播报
speak('车牌识别成功!号码是京G6386. ')
1文字生成语音
#!/usr/bin/python3
import urllib.request
import requests#导入requests库
import urllib
import json
import base64
class BaiduRest:
def __init__(self, cu_id, api_key, api_secert):
# token认证的url
self.token_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s"
# 语音合成的resturl
self.getvoice_url = "http://tsn.baidu.com/text2audio?tex=%s&lan=zh&cuid=%s&ctp=1&tok=%s"
# 语音识别的resturl
self.upvoice_url = 'http://vop.baidu.com/server_api'
self.cu_id = cu_id
self.getToken(api_key, api_secert)
return
def getToken(self, api_key, api_secert):
# 1.获取token
token_url = self.token_url % (api_key,api_secert)
r_str = requests.get(token_url).text
token_data = json.loads(r_str)
self.token_str = token_data['access_token']
pass
def getVoice(self, text, filename):
# 2. 向Rest接口提交数据
get_url = self.getvoice_url % (urllib.parse.quote(text), self.cu_id, self.token_str)
voice_data = urllib.request.urlopen(get_url).read()
# 3.处理返回数据
voice_fp = open(filename,'wb+')
voice_fp.write(voice_data)
voice_fp.close()
pass
def getText(self, filename):
# 2. 向Rest接口提交数据
data = {}
# 语音的一些参数
data['format'] = 'wav'
data['rate'] = 8000
data['channel'] = 1
data['cuid'] = self.cu_id
data['token'] = self.token_str
wav_fp = open(filename,'rb')
voice_data = wav_fp.read()
data['len'] = len(voice_data)
data['speech'] = base64.b64encode(voice_data).decode('utf-8')
post_data = json.dumps(data)
# data=bytes(post_data,encoding="utf-8")
url=self.upvoice_url+post_data
r_data = requests.get(url).text
# 3.处理返回数据
return json.loads(r_data)['result']
if __name__ == "__main__":
# 我的api_key,供大家测试用,在实际工程中请换成自己申请的应用的key和secert
api_key = "SrhYKqzl3SE1URnAEuZ0FKdT"
api_secert = "hGqeCkaMPb0ELMqtRGc2VjWdmjo7T89d"
# 初始化
bdr = BaiduRest("test_python", api_key, api_secert)
# 将字符串语音合成并保存为out.mp3
bdr.getVoice("你好北京邮电大学!我是瑶瑶", "out.mp3")
# 识别test.wav语音内容并显示
print(bdr.getText("1.wav"))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号