


https://mp.weixin.qq.com/s/8hDUSwCioOWkh-pGG91EpA
背景与动机:告别“事后平均”
想象一下,你在一个陌生的地方迷路了,想通过问路来确定位置。你是选择问一个人,让他告诉你东边怎么走,再问另一个人西边怎么走,最后自己脑补出一个大概位置?还是同时问几个人,让他们一起帮你比划着指出地标,你在脑中立刻形成一幅立体地图?
显然,后者的信息整合效率和准确性远高于前者。
传统的视觉重定位方法,很多就类似于第一种问路方式。它们通常采用一种“成对位姿回归+后期融合(late fusion)”的策略,如下图上半部分所示。模型先计算查询图像(Query Image)和数据库中每一张参考图像(DB Image)之间的相对位姿,得到多个独立的估计结果,最后通过一个简单的“运动平均”来得到查询图像的绝对位姿。
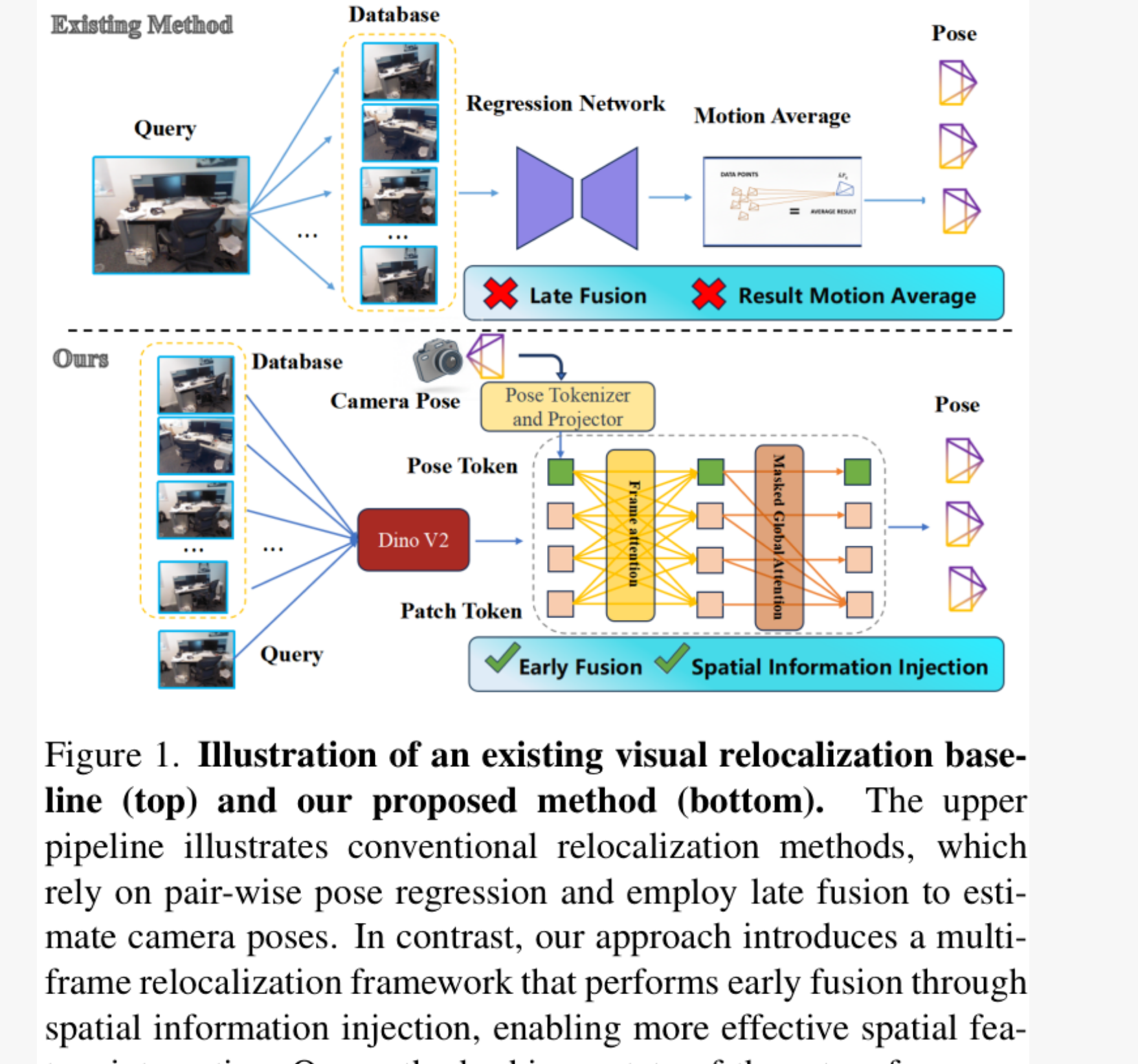
这种后期融合策略的弊端很明显:在融合阶段,宝贵的多视角空间几何信息并没有被充分利用,导致精度在复杂或大规模场景中表现不佳。
Reloc-VGGT则采用了第二种问路方式,也就是早期融合(early fusion)。如上图下半部分所示,它在模型的推理初期,就将多张参考图像的空间信息“注入”到Transformer中,让模型能够在一个更全局、更立体的视角下进行端到端的位姿推理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号