


图像A和B
条件1:同一个区域 不同光照和视角
网络: 无
图像A 不经过网络 图像A本身就是描述子
图像B 不经过网络 图像B本身就是描述子
判定函数: L2余数
结果:差别很大
条件2:同一个区域 不同光照和视角
网络: 初步网络没有训练,例如单纯降分辨率
图像A 经过网络 特征向量A
图像B 经过网络 特征向量B
判定函数: L2余数
结果:没有针对性特征,没有区分度和相似性
条件3:同一个区域 不同光照和视角
网络: 网络训练,A和B是一张图,自动调整权重
图像A 经过网络 特征向量A
图像B 经过网络 特征向量B
判定函数: L2余数
结果:有针对性区分,学习A和B在光照和视角变化下,公有的特征。
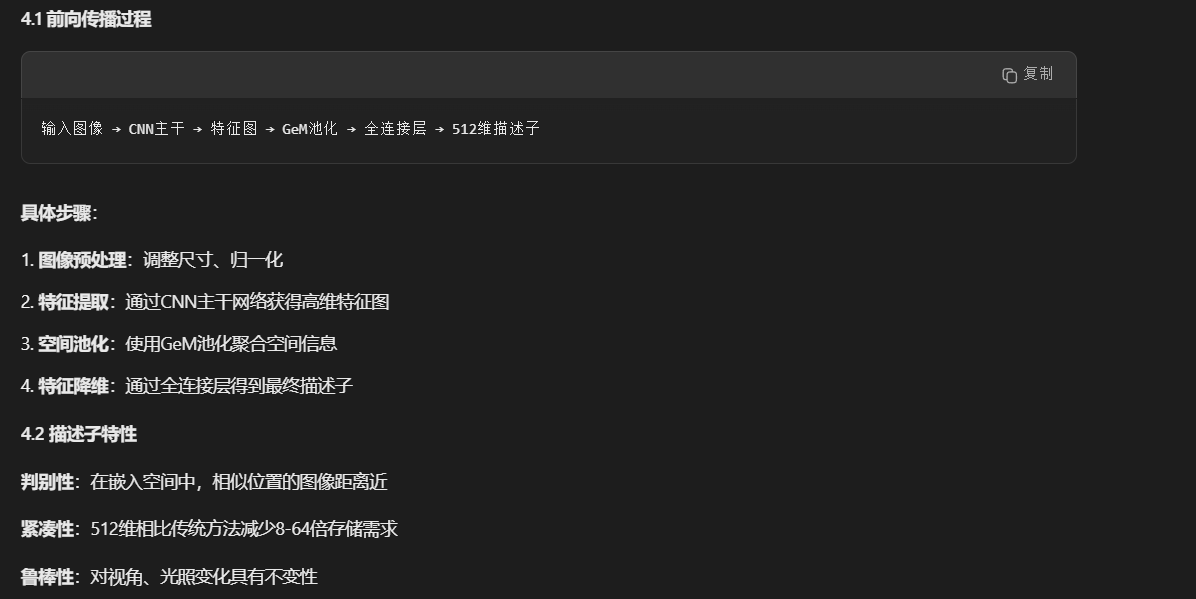
CosPlace使用的图像描述子架构详解
1. 核心描述子架构
根据论文第4.2节和第5.1节的描述,CosPlace使用的主要图像描述子架构如下: 基础架构组成:
- 主干网络(Backbone):标准CNN架构(如VGG-16、ResNet等)
- 池化层:GeM(Generalized Mean)池化
- 特征降维层:全连接层,输出维度为512
2. 具体架构细节
2.1 主干网络选择
论文中主要使用了两种主干网络: VGG-16:用于与现有方法的公平比较
- 输入尺寸:512×512像素
- 特征提取:使用预训练的ImageNet权重
- 输出特征图:在最后一个卷积层后提取
ResNet系列:用于消融实验和性能优化
- 包括ResNet-18、ResNet-50、ResNet-101
- 更快的训练速度和更低的内存需求
- 达到与VGG-16相当或更好的性能
图5展示了不同主干网络的性能比较:
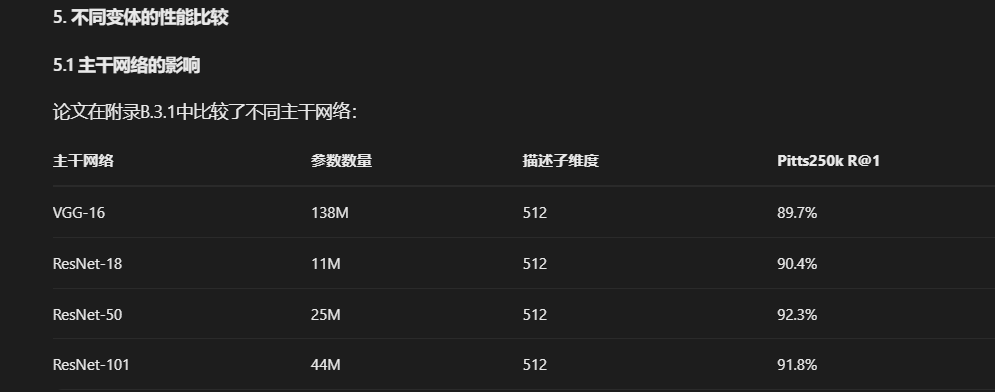
5.2 描述子维度的影响
图11展示了不同维度下的性能: 结果显示,即使使用128维描述子,CosPlace也能超越某些高维方法。
2.2 GeM池化层的关键作用
GeM池化是CosPlace描述子的核心组件: 数学表达式:
f(g)=(∣X∣1x∈X∑xp)1/p
参数设置:
- p参数:可学习的幂次参数
- 自适应调整:根据训练数据自动优化
- 优势:比平均池化或最大池化更具表达力
. 池化层的基本功能
池化层是CNN架构中的关键组件,在CosPlace中主要承担以下作用:
空间维度降维
- 输入特征图:从ResNet-50主干网络输出的特征图通常具有空间维度(如7×7或14×14)
- 池化操作:将空间维度降为1×1,保留通道信息
- 输出结果:固定长度的特征向量,与输入图像尺寸无关
2.3 全连接降维层
输出维度:512维
- 相比传统方法的32,768维(NetVLAD)或4,096维(SARE)大幅减少
- 保持高判别性的同时提高计算效率
- 适合大规模图像检索应用

7. 推理阶段的应用
7.1 描述子提取
# 伪代码示例
def extract_descriptor(image):
features = backbone(image) # CNN特征提取
pooled = gem_pooling(features) # GeM池化
descriptor = fc_layer(pooled) # 降维到512维
return descriptor


每个CosPlace组:
- 有独立的分类层(输出维度=该组类别数)
- 共享相同的特征提取主干网络
- 使用LMCL损失进行优化
顺序训练流程:
- 在组G₁上训练一个epoch,使用LMCL优化
- 切换到组G₂,继续使用LMCL优化
- 循环所有组,实现知识积累
5. 损失函数的可视化效果
LMCL的优势:
- 无需复杂挖掘:直接基于分类目标优化
- 训练更稳定:避免难例样本的干扰
- 更好的收敛性:在大型数据集上表现更可靠







A组都是红色有门房子,B组有一部分是红色有门有窗另一部分大多数是蓝色有门有窗,C组都是蓝色有窗
训练A组,学习了红色有门特征
训练C组,学习了蓝色有窗特征
训练B组,有门有窗特征
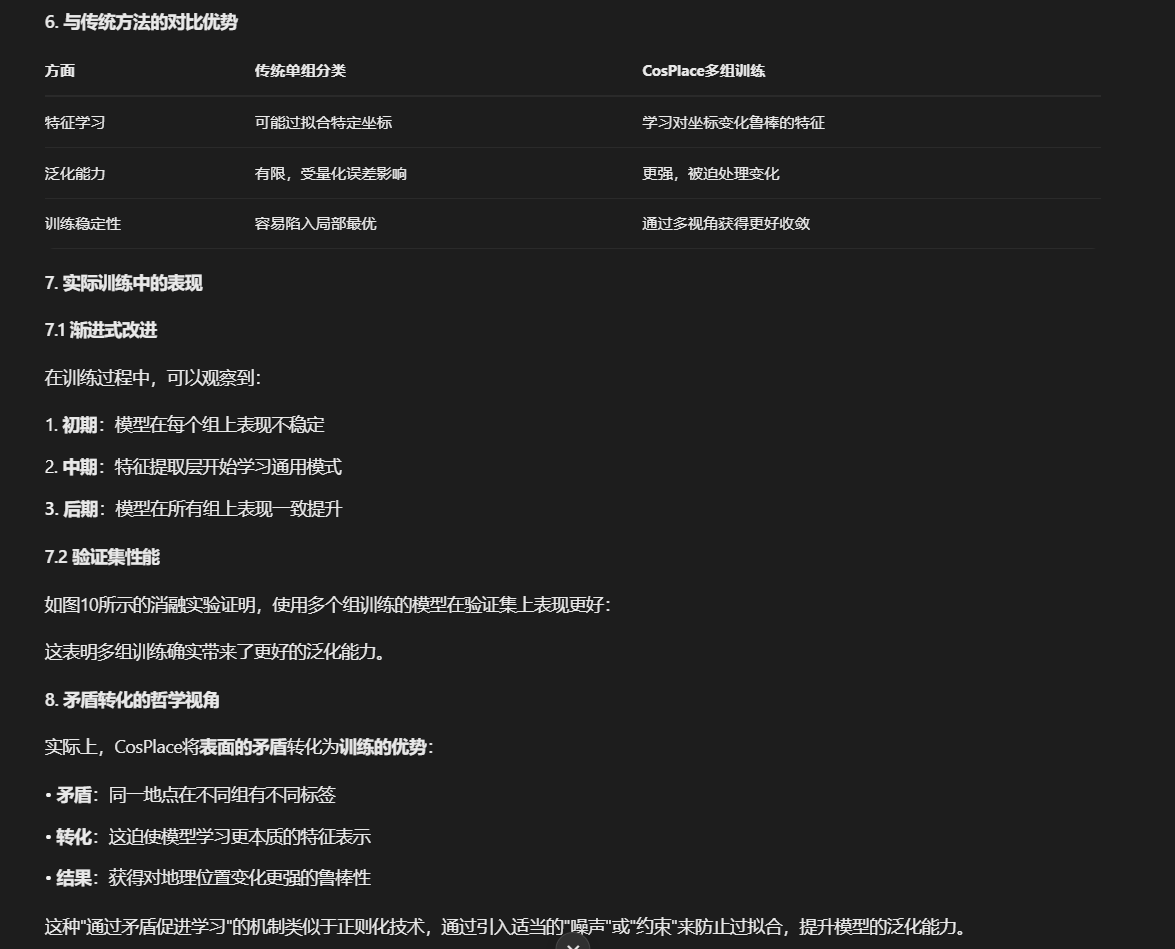
1. 问题的本质:表面矛盾与实际优势
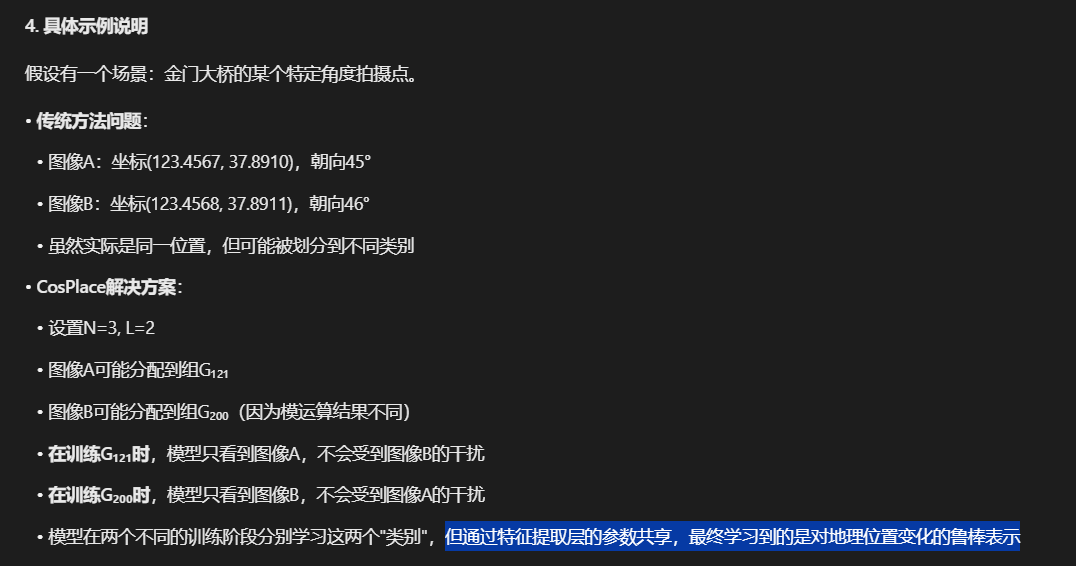
您指出的确实是一个关键问题:图像A和图像B拍摄的是同一地理位置,但在不同训练阶段被分配到了不同的类别标签。这表面上看起来是矛盾的,但实际上这正是CosPlace设计的精妙之处。
2. 参数共享机制的核心作用
2.1 特征提取层的统一性
在整个训练过程中,特征提取层(CNN主干网络)是共享的,无论当前训练哪个组,所有组都使用相同的特征提取参数。这意味着:
- 当训练G₁₂₁组时,特征提取层学习如何从图像A提取有意义的特征
- 当训练G₂₀₀组时,相同的特征提取层需要处理图像B
- 由于图像A和B内容相似,特征提取层被迫学习对微小地理位置变化不敏感的特征表示
2.2 分类层的临时性
每个CosPlace组有自己独立的分类层(全连接层),但这些分类层在训练完成后会被丢弃。如图5所示,推理时只使用特征提取层: 这种设计使得分类层只是训练过程中的临时工具,而真正重要的是特征提取层学到的通用表示。
3. 矛盾解决的详细机理
3.1 特征一致性约束
虽然图像A和B在不同组被赋予不同类别标签,但特征提取层看到的是几乎相同的内容。这产生了以下效果:
- 特征提取层的"困惑":当处理图像B时,特征提取层"记得"之前处理相似图像A时的特征模式
- 参数调整压力:为了同时适应两个组的训练目标,特征提取层必须学习对微小坐标变化鲁棒的特征
- 通用特征学习:最终,特征提取层学会忽略微小的坐标差异,专注于场景的视觉内容
3.2 类比理解
这类似于人类学习地理识别:
- 初期:我们可能将同一栋建筑的不同角度照片视为不同物体
- 随着经验积累:我们学会识别这是同一栋建筑,只是拍摄角度略有不同
- 最终能力:我们能够识别建筑的本质特征,而不受微小视角变化的影响
4. 具体训练过程分析
4.1 前向传播的一致性
无论当前训练哪个组,输入图像都通过相同的特征提取路径:
图像 → 共享CNN主干 → 共享GeM池化 → 组特定分类层
CosPlace如何通过参数共享解决分组训练中的矛盾
1. 问题的本质:表面矛盾与实际优势
您指出的确实是一个关键问题:图像A和图像B拍摄的是同一地理位置,但在不同训练阶段被分配到了不同的类别标签。这表面上看起来是矛盾的,但实际上这正是CosPlace设计的精妙之处。
2. 参数共享机制的核心作用
2.1 特征提取层的统一性
在整个训练过程中,特征提取层(CNN主干网络)是共享的,无论当前训练哪个组,所有组都使用相同的特征提取参数。这意味着:
- 当训练G₁₂₁组时,特征提取层学习如何从图像A提取有意义的特征
- 当训练G₂₀₀组时,相同的特征提取层需要处理图像B
- 由于图像A和B内容相似,特征提取层被迫学习对微小地理位置变化不敏感的特征表示
2.2 分类层的临时性
每个CosPlace组有自己独立的分类层(全连接层),但这些分类层在训练完成后会被丢弃。如图5所示,推理时只使用特征提取层: 这种设计使得分类层只是训练过程中的临时工具,而真正重要的是特征提取层学到的通用表示。
3. 矛盾解决的详细机理
3.1 特征一致性约束
虽然图像A和B在不同组被赋予不同类别标签,但特征提取层看到的是几乎相同的内容。这产生了以下效果:
- 特征提取层的"困惑":当处理图像B时,特征提取层"记得"之前处理相似图像A时的特征模式
- 参数调整压力:为了同时适应两个组的训练目标,特征提取层必须学习对微小坐标变化鲁棒的特征
- 通用特征学习:最终,特征提取层学会忽略微小的坐标差异,专注于场景的视觉内容
3.2 类比理解
这类似于人类学习地理识别:
- 初期:我们可能将同一栋建筑的不同角度照片视为不同物体
- 随着经验积累:我们学会识别这是同一栋建筑,只是拍摄角度略有不同
- 最终能力:我们能够识别建筑的本质特征,而不受微小视角变化的影响
4. 具体训练过程分析
4.1 前向传播的一致性
无论当前训练哪个组,输入图像都通过相同的特征提取路径:
特征提取层无法"知道"当前是哪个组在训练,它只能尽力提取对所有组都有用的特征。
4.2 梯度反向传播的影响
当训练不同组时,梯度通过分类层反向传播到共享的特征提取层:
- G₁₂₁组训练:梯度告诉特征提取层"要为图像A学习区分性特征"
- G₂₀₀组训练:梯度告诉特征提取层"要为图像B学习区分性特征"
- 特征提取层的响应:由于A和B相似,特征提取层学会"提取对A和B都有效的通用特征"
CosPlace如何通过参数共享解决分组训练中的矛盾
1. 问题的本质:表面矛盾与实际优势
您指出的确实是一个关键问题:图像A和图像B拍摄的是同一地理位置,但在不同训练阶段被分配到了不同的类别标签。这表面上看起来是矛盾的,但实际上这正是CosPlace设计的精妙之处。
2. 参数共享机制的核心作用
2.1 特征提取层的统一性
在整个训练过程中,特征提取层(CNN主干网络)是共享的,无论当前训练哪个组,所有组都使用相同的特征提取参数。这意味着:
- 当训练G₁₂₁组时,特征提取层学习如何从图像A提取有意义的特征
- 当训练G₂₀₀组时,相同的特征提取层需要处理图像B
- 由于图像A和B内容相似,特征提取层被迫学习对微小地理位置变化不敏感的特征表示
2.2 分类层的临时性
每个CosPlace组有自己独立的分类层(全连接层),但这些分类层在训练完成后会被丢弃。如图5所示,推理时只使用特征提取层: 这种设计使得分类层只是训练过程中的临时工具,而真正重要的是特征提取层学到的通用表示。
3. 矛盾解决的详细机理
3.1 特征一致性约束
虽然图像A和B在不同组被赋予不同类别标签,但特征提取层看到的是几乎相同的内容。这产生了以下效果:
- 特征提取层的"困惑":当处理图像B时,特征提取层"记得"之前处理相似图像A时的特征模式
- 参数调整压力:为了同时适应两个组的训练目标,特征提取层必须学习对微小坐标变化鲁棒的特征
- 通用特征学习:最终,特征提取层学会忽略微小的坐标差异,专注于场景的视觉内容
3.2 类比理解
这类似于人类学习地理识别:
- 初期:我们可能将同一栋建筑的不同角度照片视为不同物体
- 随着经验积累:我们学会识别这是同一栋建筑,只是拍摄角度略有不同
- 最终能力:我们能够识别建筑的本质特征,而不受微小视角变化的影响
4. 具体训练过程分析
4.1 前向传播的一致性
无论当前训练哪个组,输入图像都通过相同的特征提取路径:
特征提取层无法"知道"当前是哪个组在训练,它只能尽力提取对所有组都有用的特征。
4.2 梯度反向传播的影响
当训练不同组时,梯度通过分类层反向传播到共享的特征提取层:
- G₁₂₁组训练:梯度告诉特征提取层"要为图像A学习区分性特征"
- G₂₀₀组训练:梯度告诉特征提取层"要为图像B学习区分性特征"
- 特征提取层的响应:由于A和B相似,特征提取层学会"提取对A和B都有效的通用特征"
5. 数学层面的解释
5.1 损失函数的作用
每个组的损失函数为:
其中L_lmcl是大间隔余弦损失,它要求:
- 同一类别的特征在嵌入空间中聚集
- 不同类别的特征相互远离
当相似图像在不同组被不同对待时,特征提取层被迫学习更宽裕的决策边界。
5.2 特征空间的优化
最终目标是最小化整体损失:
其中θ是共享参数。优化过程自然引导特征提取层学习对组间差异不敏感的特征。
例子1
第一组,类别A红色有门有窗房子100%,类别B黄色有楼梯有烟囱房子100%。
第二组,类别A红色有门有窗房子10%,蓝色有门有窗房子90%。类别B黄色有楼梯有烟囱房子100%。 用这个例子说明每次训练学习到的特征以及调整过程
结构特征的泛化:
- 门窗检测器:从专门检测"红色房子的门窗"泛化为检测"任何颜色房子的门窗"
- 学习到颜色不变的门窗特征表示
4. 梯度反向传播的详细机制
4.1 第一组训练的梯度信号
- ∂L/∂θ_color_red:正值,强化红色特征检测
- ∂L/∂θ_door_window:正值,强化门窗特征检测
- ∂L/∂θ_color_blue:接近零,蓝色特征未被激活
- 对于类别A(红色房子):颜色通道强烈响应红色,结构通道响应门窗
- 对于类别B(黄色房子):颜色通道响应黄色,结构通道响应楼梯烟囱
-
- 类别A的决策边界:主要依赖红色+门窗特征组合
- 类别B的决策边界:主要依赖黄色+楼梯烟囱特征组合
4.2 第二组训练的梯度调整
当处理蓝色有门有窗房子时:
- ∂L/∂θ_color_blue:变为强正值,激活蓝色检测
- ∂L/∂θ_color_red:小幅负值,适度抑制红色过度依赖
- ∂L/∂θ_door_window:保持正值,进一步强化结构特征
特征提取层的冲突检测
当切换到第二组训练时,特征提取层面临新的模式: 遇到的矛盾情况:
- 相同的"有门有窗"特征现在出现在红色和蓝色房子中
- 颜色特征与结构特征的对应关系被打破
- 需要重新评估特征的重要性权重
3.2 特征权重重新校准过程
颜色特征的处理:
# 第一组学到的颜色权重
color_weights = [红色: 0.8, 黄色: 0.7, 蓝色: 0.1]
# 第二组训练后的调整
color_weights = [红色: 0.6, 黄色: 0.7, 蓝色: 0.5]
# 蓝色权重显著提升,红色权重相对下降
结构特征的泛化:
- 门窗检测器:从专门检测"红色房子的门窗"泛化为检测"任何颜色房子的门窗"
- 学习到颜色不变的门窗特征表示
9. 总结
CosPlace通过巧妙的参数共享和分组训练设计,将看似矛盾的不同组别分配转化为模型学习的驱动力。
特征提取层在应对不同组的训练目标时,被迫学习对微小地理位置变化不敏感的鲁棒特征,最终在推理阶段能够产生高质量的地理位置描述符。
这种设计体现了"分而治之"的智慧,既避免了量化误差的直接冲突,又充分利用了所有训练数据。
文档标题:重新思考大规模应用中的视觉地理定位
日期: 2022年4月7日 arXiv编号: arXiv:2204.02287v2 作者: Gabriele Berton(都灵理工大学) Carlo Masone(CINI) Barbara Caputo(都灵理工大学) 摘要 视觉地理定位(VG)是通过将给定照片与已知位置的大型图像数据库进行比较,估计其拍摄位置的任务。为研究现有技术在实际城市级VG应用中的表现,我们构建了San Francisco eXtra Large(SF-XL)数据集,覆盖整个城市并提供广泛挑战性案例,其规模比先前最大VG数据集大30倍。我们发现当前方法难以扩展至此类大规模数据集,因此设计了新型高可扩展训练技术CosPlace,将训练视为分类问题,避免常用对比学习所需的昂贵负例挖掘。我们在多个数据集上实现了最先进性能,并发现CosPlace对严重领域变化具有鲁棒性。此外,与先前最先进方法相比,CosPlace训练时GPU内存需求减少约80%,且使用8倍小的描述符可获得更好结果,为城市级实际视觉地理定位铺平道路。数据集、代码和训练模型可在以下网址获取:
1. 引言
视觉地理定位(VG),也称为视觉地点识别[1]或图像定位[32],是计算机视觉[1,15,21,46-48,54]和机器人研究[9-11,17,22,26]的基础任务,其定义为以几米容错度粗略识别照片拍摄地理位置的任务[1,5,18,24,27,32,50]。该任务通常被视为图像检索问题,即将待定位查询与地理标记图像数据库进行比较:从数据库检索的最相似图像及其元数据代表查询地理位置的假设。特别是,所有近期VG方法均基于学习,使用神经网络将图像投影到能很好表示其位置相似性的嵌入空间,并可用于检索。 迄今为止,VG研究集中于中等规模地理区域(如社区)的图像定位。然而,该技术的实际应用(如自动驾驶[15]和辅助设备[12])需要在更大尺度(如城市或大都市区)上操作,因此需要海量地理标记图像数据库执行检索。拥有此类海量数据库时,建议将其用于模型训练而非仅用于检索(推理)。这一想法要求我们重新思考VG,解决以下两个限制: 非代表性数据集:当前VG数据集无法代表实际大规模应用,因其地理覆盖范围过小[1,7,19,34,46]或过稀疏[2,13,33,50](示例见图1)。此外,当前数据集遵循将收集图像按地理不相交划分训练集和测试集的常见做法,但这与实际应用不符(在实际应用中可能使用目标地理区域的图像训练模型)。考虑到图像收集成本,建议将整个数据库用于训练。 训练可扩展性:海量数据访问引发如何有效用于训练的问题。所有近期最先进VG方法使用对比学习[1,5,18,21,24,27,32,36,37,50](主要依赖三元组损失),其严重依赖在整个训练数据库中进行负例挖掘[1]。该操作昂贵,且在大规模数据库下不可行。仅探索小样本池的轻量挖掘策略可缩短挖掘时间[50],但仍导致收敛缓慢且可能数据利用不足。 贡献:本文通过以下贡献解决上述限制:- 新型大规模密集数据集San Francisco eXtra Large(SF-XL),规模约为当前可用数据集的30倍(见图1)。该数据集包含众包(即多领域)查询,构成挑战性问题。
- 使用分类任务作为代理训练模型的流程,该模型在推理时用于提取判别性描述符进行检索。我们称此方法为CosPlace。CosPlace非常简単,无需挖掘负例,且能有效从海量数据中学习。

文档标题:重新思考大规模应用中的视觉地理定位
日期: 2022年4月7日 arXiv编号: arXiv:2204.02287v2 作者: Gabriele Berton(都灵理工大学) Carlo Masone(CINI) Barbara Caputo(都灵理工大学) 摘要 视觉地理定位(VG)是通过将给定照片与已知位置的大型图像数据库进行比较,估计其拍摄位置的任务。为研究现有技术在实际城市级VG应用中的表现,我们构建了San Francisco eXtra Large(SF-XL)数据集,覆盖整个城市并提供广泛挑战性案例,其规模比先前最大VG数据集大30倍。我们发现当前方法难以扩展至此类大规模数据集,因此设计了新型高可扩展训练技术CosPlace,将训练视为分类问题,避免常用对比学习所需的昂贵负例挖掘。我们在多个数据集上实现了最先进性能,并发现CosPlace对严重领域变化具有鲁棒性。此外,与先前最先进方法相比,CosPlace训练时GPU内存需求减少约80%,且使用8倍小的描述符可获得更好结果,为城市级实际视觉地理定位铺平道路。数据集、代码和训练模型可在以下网址获取:1. 引言
视觉地理定位(VG),也称为视觉地点识别[1]或图像定位[32],是计算机视觉[1,15,21,46-48,54]和机器人研究[9-11,17,22,26]的基础任务,其定义为以几米容错度粗略识别照片拍摄地理位置的任务[1,5,18,24,27,32,50]。该任务通常被视为图像检索问题,即将待定位查询与地理标记图像数据库进行比较:从数据库检索的最相似图像及其元数据代表查询地理位置的假设。特别是,所有近期VG方法均基于学习,使用神经网络将图像投影到能很好表示其位置相似性的嵌入空间,并可用于检索。 迄今为止,VG研究集中于中等规模地理区域(如社区)的图像定位。然而,该技术的实际应用(如自动驾驶[15]和辅助设备[12])需要在更大尺度(如城市或大都市区)上操作,因此需要海量地理标记图像数据库执行检索。拥有此类海量数据库时,建议将其用于模型训练而非仅用于检索(推理)。这一想法要求我们重新思考VG,解决以下两个限制: 非代表性数据集:当前VG数据集无法代表实际大规模应用,因其地理覆盖范围过小[1,7,19,34,46]或过稀疏[2,13,33,50](示例见图1)。此外,当前数据集遵循将收集图像按地理不相交划分训练集和测试集的常见做法,但这与实际应用不符(在实际应用中可能使用目标地理区域的图像训练模型)。考虑到图像收集成本,建议将整个数据库用于训练。 训练可扩展性:海量数据访问引发如何有效用于训练的问题。所有近期最先进VG方法使用对比学习[1,5,18,21,24,27,32,36,37,50](主要依赖三元组损失),其严重依赖在整个训练数据库中进行负例挖掘[1]。该操作昂贵,且在大规模数据库下不可行。仅探索小样本池的轻量挖掘策略可缩短挖掘时间[50],但仍导致收敛缓慢且可能数据利用不足。 贡献:本文通过以下贡献解决上述限制:- 新型大规模密集数据集San Francisco eXtra Large(SF-XL),规模约为当前可用数据集的30倍(见图1)。该数据集包含众包(即多领域)查询,构成挑战性问题。
- 使用分类任务作为代理训练模型的流程,该模型在推理时用于提取判别性描述符进行检索。我们称此方法为CosPlace。CosPlace非常简単,无需挖掘负例,且能有效从海量数据中学习。
2. 相关工作
视觉地理定位作为图像检索:视觉地理定位通常被视为图像检索问题,当检索图像位于查询真实位置预设范围(通常25米)内时视为正确[1,5,18,27,32,50]。所有近期VG方法使用学习嵌入进行检索,这些嵌入由配备实现某种聚合或池化头的特征提取主干产生,最著名的是NetVLAD[1]。这些架构通过对比学习训练,通常使用三元组损失[1,5,21,24,27,36,37,50]并利用数据库图像地理标签作为弱监督挖掘负例[1]。该方案有多个变体,如随机吸引-排斥嵌入(SARE)损失[32],允许高效使用多个负例,同时保持[1]的训练方法。另一解决方案见[18],通过不仅在完整图像上计算损失,还在智能挖掘的裁剪区域上计算损失,实现新最先进结果。尽管有这些变体,所有方法均受昂贵挖掘技术导致的训练可扩展性差影响。可扩展性问题在测试时也存在,涉及描述符大小(影响所需内存和检索时间)。尽管NetVLAD描述符维度可通过PCA降低,但这会导致结果退化[1],因此[18,32]等工作偏好保持4096高维度。其他工作放弃NetVLAD,改用池化[40]构建更小嵌入。 视觉地理定位作为分类:视觉地理定位的另一种方法是将其视为分类问题[25,30,35,42,52]。这些工作基于以下思想:来自相同地理区域的两张图像,尽管表示不同场景,可能共享相似语义(如建筑风格、车辆类型、植被等)。实践中,这些方法将感兴趣地理区域划分为单元格,并根据单元格将数据库图像分组为类别。该公式允许将问题扩展至全球范围,但代价是估计精度降低(因每个类别可能跨越数公里)。因此,当估计要求几米容错度时,这些方法不用于执行地理定位。 与先前工作的关系:本文提出结合检索(几米容错度)和分类(高可扩展性)优势的新VG方法。我们的方法使用分类任务作为代理训练模型,无需任何挖掘。这使得能够使用海量数据集进行训练,不同于使用对比学习的解决方案[1,5,21,24,27,36,37,50]。测试时,训练模型用于提取图像描述符并执行经典检索。尽管CosPlace可能看似类似先前基于分类的工作[25,30,35,42,52](因为它们也将地图划分为类别),但存在实质差异。这些先前工作处理全局分类任务,将图像分组到非常大的单元格(宽达数百公里),基于更近场景具有相似语义的思想(如两张图像均来自中国,可能均描绘汉字)。另一方面,我们的分区策略旨在利用密集数据的可用性,并确保如果两张图像来自相同类别,它们可视化相同场景。此外,与[25,30,35,42,52]不同,一旦训练完成,我们的方法可用于通过图像检索在任何给定地理区域执行地理定位。
3. SF-XL数据集
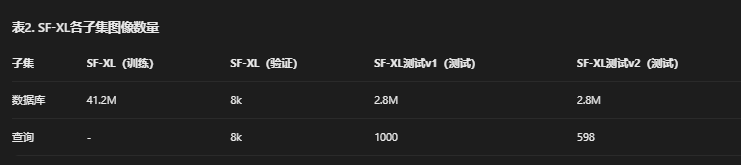
存在许多VG数据集(见表1),但无一反映必须在大环境中以几米容错度执行地理定位的场景:部分数据集限于小地理区域[1,5,7,46],而其他未密集覆盖区域[2,13,19,33,41,50]。San Francisco Landmark数据集[8]部分克服这些限制,但未覆盖整个城市,且缺乏长期时间变化(这对鲁棒训练神经网络至关重要[1])。我们提出首个城市级、密集且具时间变化的数据集:San Francisco eXtra Large(SF-XL)。 数据库:与此任务中其他数据集类似[1,5,29,46,55,56],SF-XL的数据库从Google StreetView图像创建。我们收集343万张等距柱状投影全景图(360°图像)并按水平方向分为12个裁剪区域,遵循[1,46]。这产生总计4120万张图像(部分示例见图9)。每个裁剪区域标注6自由度信息(包括GPS和朝向)。图像拍摄于2009年至2021年间,因此提供丰富长期时间变化。 除规模和密度外,SF-XL与先前数据集[1,5,46,50]的不同之处在于:数据库未按地理非重叠子集划分为训练、验证和测试集。我们认为此类数据库划分不反映可能使用VG的应用现实。实际上,当为大规模地理区域构建VG应用时,可能选择在该区域图像上训练神经网络,而非额外从不相交(可能相邻)区域收集图像。 为此,我们使用4120万张图像作为训练集,因此覆盖旧金山整个区域。测试时,虽然可使用整个4120万张图像数据库进行检索,但这对于研究目的不可行(因为在单GPU上提取所有图像描述符需数天)。因此,我们仅使用2013年的280万张图像作为测试时数据库,这些图像仍覆盖整个SF-XL地理区域。我们发现此选择是良好解决方案,因为图像集足够小以成为可行研究选项,又足够大以模拟真实场景并防止在测试集上验证或调整超参数的坏习惯(因为每个epoch验证耗时过长)。 最后,对于验证,我们使用散布整个城市的小图像集,包含8000张数据库图像和8000张查询。 查询:虽然先前方法要求训练集划分为数据库和查询,但CosPlace无需此区分。因此,我们整体发布训练集,并相信依赖数据库/查询划分进行训练的方法(如[1,18,27,32,36,37,53])应选择最适合其需求的划分,因为此选择可能严重影响结果(见表3第三行和第四行结果差异作为此现象示例)。关于测试查询,我们认为它们不应与数据库来自相同领域,因为在大多数真实场景中,测试时查询可能来自未见领域。这也与San Francisco Landmark数据集[8]和Tokyo 24/7[46]的做法一致。因此,在SF-XL中我们包含两个不同测试查询集:
- 测试集v1:从Flickr收集的1000张图像集(类似Oxford5k[38]、Paris6k[39]、Sfm120k[40])。鉴于Flickr图像GPS坐标不精确,该集中所有图像均经手动挑选,其位置经人工验证。我们还确保模糊人脸和车牌以匿名化图片。这些图像非常多样,具有广泛视角和照明(昼夜)变化(见图2);
- 测试集v2:来自San Francisco Landmark数据集[8]查询的598张图像集,其6自由度坐标由[48]生成。因提供6自由度标签,该集也可用于大规模姿态估计。
表2总结SF-XL,更多信息见附录A。
3. SF-XL数据集
存在许多VG数据集(见表1),但无一反映必须在大环境中以几米容错度执行地理定位的场景:部分数据集限于小地理区域[1,5,7,46],而其他未密集覆盖区域[2,13,19,33,41,50]。San Francisco Landmark数据集[8]部分克服这些限制,但未覆盖整个城市,且缺乏长期时间变化(这对鲁棒训练神经网络至关重要[1])。我们提出首个城市级、密集且具时间变化的数据集:San Francisco eXtra Large(SF-XL)。 数据库:与此任务中其他数据集类似[1,5,29,46,55,56],SF-XL的数据库从Google StreetView图像创建。我们收集343万张等距柱状投影全景图(360°图像)并按水平方向分为12个裁剪区域,遵循[1,46]。这产生总计4120万张图像(部分示例见图9)。每个裁剪区域标注6自由度信息(包括GPS和朝向)。图像拍摄于2009年至2021年间,因此提供丰富长期时间变化。 除规模和密度外,SF-XL与先前数据集[1,5,46,50]的不同之处在于:数据库未按地理非重叠子集划分为训练、验证和测试集。我们认为此类数据库划分不反映可能使用VG的应用现实。实际上,当为大规模地理区域构建VG应用时,可能选择在该区域图像上训练神经网络,而非额外从不相交(可能相邻)区域收集图像。 为此,我们使用4120万张图像作为训练集,因此覆盖旧金山整个区域。测试时,虽然可使用整个4120万张图像数据库进行检索,但这对于研究目的不可行(因为在单GPU上提取所有图像描述符需数天)。因此,我们仅使用2013年的280万张图像作为测试时数据库,这些图像仍覆盖整个SF-XL地理区域。我们发现此选择是良好解决方案,因为图像集足够小以成为可行研究选项,又足够大以模拟真实场景并防止在测试集上验证或调整超参数的坏习惯(因为每个epoch验证耗时过长)。 最后,对于验证,我们使用散布整个城市的小图像集,包含8000张数据库图像和8000张查询。 查询:虽然先前方法要求训练集划分为数据库和查询,但CosPlace无需此区分。因此,我们整体发布训练集,并相信依赖数据库/查询划分进行训练的方法(如[1,18,27,32,36,37,53])应选择最适合其需求的划分,因为此选择可能严重影响结果(见表3第三行和第四行结果差异作为此现象示例)。关于测试查询,我们认为它们不应与数据库来自相同领域,因为在大多数真实场景中,测试时查询可能来自未见领域。这也与San Francisco Landmark数据集[8]和Tokyo 24/7[46]的做法一致。因此,在SF-XL中我们包含两个不同测试查询集:
- 测试集v1:从Flickr收集的1000张图像集(类似Oxford5k[38]、Paris6k[39]、Sfm120k[40])。鉴于Flickr图像GPS坐标不精确,该集中所有图像均经手动挑选,其位置经人工验证。我们还确保模糊人脸和车牌以匿名化图片。这些图像非常多样,具有广泛视角和照明(昼夜)变化(见图2);
- 测试集v2:来自San Francisco Landmark数据集[8]查询的598张图像集,其6自由度坐标由[48]生成。因提供6自由度标签,该集也可用于大规模姿态估计。
表2总结SF-XL,更多信息见附录A。

4. 方法
鉴于城市级数据集需要数百万图像(第3节)且视觉地理定位本质是大规模任务,我们认为正确的VG方法应具有高可扩展性(训练和测试时均如此)。我们发现当前(及先前)最先进方法[1,18,27,32]缺乏这些重要品质:
- 训练时,它们需要定期计算所有数据库图像特征并保存在缓存中:这导致空间和时间复杂度为O(n),仅适用于小数据集;
- 这些方法[1,18,27,32]依赖NetVLAD层[1]或其变体[27],产生高维向量且推理需要大量内存(因为数据库描述符应保存在内存中以实现高效检索)。例如,带NetVLAD的VGG-16产生维度32k的向量,对于10M数据库需要32k·10M·4B=1220GB内存。更小嵌入通常通过PCA等降维技术获得,但使用低于4096的维度会导致结果快速下降[1,36,37,57]。
为降低训练时间复杂度,我们受人脸识别领域启发,其中cosFace[49]和arcFace[14]是实现最先进结果的关键[44]。这些损失要求训练集划分为类别;然而,在VG中标签空间是连续的(GPS坐标及可选的朝向/方向信息),使其不直接适用于离散类别划分。
4.1 将数据集划分为类别
将数据库划分为类别的朴素方法是使用UTM坐标{东, 北}¹将其划分为正方形地理单元格(见图3),并根据每个图像的朝向/方向{朝向}进一步将每个单元格切片为一组类别。形式上,分配给类别Cei,nj,hk的图像集为:
{x:⌊Meast⌋=ei,⌊Mnorth⌋=nj,⌊αheading⌋=hk}(1)
其中M和α是两个参数(分别以米和度为单位),决定每个类别在位置和朝向上的范围。虽然此解决方案从VG数据集创建一组类别,但它有重大限制:几乎相同的图像(如相同朝向但相距几厘米拍摄)可能因量化误差被分配到不同类别(见图3),这会混淆基于分类的训练算法。 为克服此限制,我们建议不一次性使用所有类别训练模型,而仅使用非相邻类别组(如果位置或朝向上的无穷小差异可将图像从一个类别带到另一个类别,则两个类别相邻)。直观上,这些组(我们称为CosPlace组)类似于单独的数据集,我们提出的训练流程(第4.2节说明)迭代处理它们(一次一组)。我们通过固定同一组中两个类别应具有的最小空间分离(平移或旋转方面)生成组。为此,我们引入两个超参数:N控制同一组中两个类别之间的最小单元格数,L是朝向的等效参数(视觉描述见图4)。形式上,我们将CosPlace组Guvw定义为以下类别集:
Guvw={Ceinjhk:(eimodN=u)∧∧(njmodN=v)∧(hkmodL=w)}
通过构造,CosPlace组是不相交的类别集(来自公式(1)),具有以下属性:
- 属性1:每个类别属于恰好一个组。
- 属性2:在给定组内,如果两个图像属于不同类别,它们至少相距M⋅(N−1)米或α⋅(L−1)度(见图4);
- 属性3:CosPlace组的总数为N×N×L。
- 属性4:除非N=1或L=1,否则没有两个相邻类别可属于同一组。


¹ UTM坐标是用于以米标识地球上位置的系统,1 UTM单位对应1米。它们可从GPS坐标(即纬度和经度)提取,并允许在平面上近似地球表面受限区域。

4.2 训练网络
我们现在描述如何使用CosPlace组训练模型。我们受大间隔余弦损失(LCML)[49](也称为cosFace[44,49,51])启发,该损失在人脸识别[44]和地标检索[51]中显示出显著结果。然而,原始LCML不能直接应用于任何VG数据集,因为图像未划分为有限数量的类别。但是,通过提出的数据集划分,我们可以顺序在每个CosPlace组上执行LCML(每个组可视为单独的数据集)并迭代多个组。我们称此训练流程为CosPlace。由于LCML依赖输出维度等于类别数的全连接层,CosPlace需要每个组一个全连接层:这些层在验证/测试时被丢弃。注意,并非必须使用所有组进行训练,因为可以仅使用单个组而忽略其他;但图10的完整消融显示使用多于一个组有助于获得更好结果。因此,我们顺序在组上训练。形式上,对于每个组:
LcosPlace=Llmcl(Guvw)(3)
其中Llmcl是[49]中定义的LCML损失,u∈{0,…,N},v∈{0,…,N},W∈{0,…,L}。实践中,我们在G000上训练一个epoch,下一个在G001上,依此类推,迭代所有组。此流程相对于视觉地理定位中常用对比学习方法(基于对比损失)的显著优势是无需挖掘或缓存,使其成为更可扩展的选项。验证和测试时,我们使用模型不是对查询进行分类,而是如[49]中提取图像描述符,用于在数据库上进行经典检索。这使得模型也可用于未见地理区域的其他数据集(见表3)。
5. 实验
5.1 实现细节
架构:CosPlace与架构无关,即可应用于几乎任何基于图像的模型。
大多数实验中,我们依赖由标准CNN主干后接GeM池化和输出维度512的全连接层组成的简单网络。注意,这种简单架构与过去五年视觉地理定位研究趋势[1,18,27,32,36,37,53]形成对比,其中架构依赖更复杂(相对于我们的架构)的NetVLAD层[1],部分甚至在顶部添加多个块[27,36,37],导致更重更慢的架构。鉴于先前方法依赖VGG-16主干[1,18,27,32,36,37,53,57],我们在第5.2节为公平比较其他方法使用VGG-16。对于消融和初步实验,我们依赖ResNet-18,它以更少训练时间和内存需求达到与VGG-16相似结果。在第5.4节和附录B.3.1中,我们研究使用更新主干(ResNet[23]和基于Transformer的[16,20])与不同输出维度,发现CosPlace在多种架构下获得鼓舞人心的结果,因此展示巨大灵活性。例如,我们发现使用ResNet-101主干和128维描述符的CosPlace优于当前SOTA(后者使用4096维描述符)。
训练:关于超参数,我们设M=10米, α=30∘,N=5和L=2。
我们将一个epoch定义为在一个组上10k次迭代。我们在第一个组上执行一个epoch,然后在第二个组上执行一个epoch,依此类推,总共50个epoch(即批量大小32下500k次迭代)。为确保训练期间同一组被多次看到,我们仅使用N×N×L(即5×5×2=50)个组中的8个。每个epoch后执行验证,训练完成后,使用在验证集上获得最佳性能的模型进行测试。附录B.2提供进一步实现细节,并讨论CosPlace不仅相比先前VG方法减少超参数数量,而且其引入的超参数具有直观含义(见图4)。相对于基于NetVLAD的方法[1,18,27,32,36,37,53](代表过去五年全部最先进技术),我们的方法无需多步骤,而NetVLAD层要求在网络开始训练前计算特征聚类,并可选择之后计算PCA。
5.2 与其他方法比较
本节我们比较CosPlace与先前视觉地理定位方法。为正确评估结果,我们在7个数据集上测试:Pitts250k[1]、Pitts30k[1]、Tokyo 24/7[46]、St Lucia[34]、Mapillary Street Level Sequences(MSLS)[50]以及我们提出的SF-XL测试v1和SF-XL测试v2。这些数据集中,MSLS和St Lucia由车辆拍摄的前视图图像组成,其余依赖Google StreetView图像构建数据库。对于MSLS,鉴于测试集标签尚未公开发布,我们如[4,21]在验证集上测试。作为度量,我们使用25米阈值下的召回率@N(即前N个预测中至少有一个在查询25米范围内的查询百分比),遵循标准流程[1,3,5,18,21,27,32,50]。 我们使用NetVLAD[1]、CRN[27]、GeM[40]、SARE[32]和SFRS[18]进行实验。这些方法在流行的Pitts30k[1]数据集上训练,并如SFRS应用颜色抖动。尽管对部分方法而言,在MSLS或SF-XL等大规模数据集上训练难以处理(如SFRS的代码²依赖特征空间中任何查询-数据库图像对之间的成对距离计算,导致空间和时间复杂度随图像数量平方增长),我们能够使用[50]中的部分挖掘在MSLS和SF-XL上训练GeM和NetVLAD,该技术可扩展至更大数据集。使用此挖掘技术,我们使用SF-XL的两个不同数据库/查询划分进行训练(注意先前方法不同于CosPlace,要求数据集划分):SF-XL使用2010年后的图像作为查询,其余作为数据库,而SF-XL*使用2015年后的图像作为查询,2015年前的作为数据库(导致更密集数据库)。我们还报告其他方法的结果,如SPE-VLAD[53]、SRALNet[36]、APPSVR[37]和APANet[57],尽管这些工作的代码未公开,我们无法独立复现结果。 结果讨论:结果报告在表3和表4中,所有结果依赖基于VGG-16的架构。结果可总结为以下几点:
- CosPlace平均取得最佳结果,在五个数据集上平均R@1比第二名方法高8.5%。
- CosPlace对来自其他源的数据集显示强鲁棒性。另一方面,其他方法要么在具有StreetView源数据库的数据集(即Pitts30k、Pitts250k、Tokyo 24/7)上表现良好,要么在具有前视图图像的数据集(即MSLS和St Lucia)上表现良好。例如,在MSLS和St Lucia上表现最佳的方法(即在MSLS上训练的NetVLAD)在Pitts250k上R@1比CosPlace低10.0%;类似地,在Pitts30k上表现最佳的方法(即在Pitts30k上训练的SFRS)在St Lucia上比CosPlace低21.8%。
- 虽然其他方法无法在使用紧凑描述符时达到竞争性结果,但我们发现CosPlace使用512维输出达到最先进水平,为可扩展、鲁棒且高效的实际应用铺平道路。附录B.3.2中,我们通过将PCA应用于高维描述符提供额外结果。
- 除CosPlace外的方法无法从在SF-XL上训练受益。这可能归因于部分挖掘[50](因为标准挖掘[1]在大规模下不可行)。
- 对于CosPlace之外的方法,训练集中数据库和查询的划分方式产生巨大差异:在SF-XL与SF-XL*上训练(使用不同数据库/查询划分)获得相当不同的结果。这对CosPlace不是问题,因为它无需数据库/查询划分进行训练。
比较公平性:虽然可能认为表3和表4中的比较不公平(因为大多数其他方法在Pitts30k上训练,而CosPlace在更大数据集上训练),但我们想指出:i) CosPlace无法在Pitts30k或MSLS上训练(因为它们缺乏朝向标签),且ii) 在SF-XL上训练先前
5.3 计算效率
训练时内存占用:与使用三元组损失并需要保存每个图像描述符[1,18,32](或大量描述符[50])在缓存中的先前方法相比,CosPlace通过将问题视为分类任务而无需挖掘/缓存来规避此问题。这有效地意味着它可以扩展到非常大的数据集,而先前的工作[1,18,32,36,37,53]将需要大量内存来训练大规模数据集。请注意,大型数据集的缓存可能非常耗费内存:NetVLAD描述符对于一张图像大约重32k·4B = 128KB,而尺寸为480x640的JPEG图像大约为70KB;因此,整个数据集的缓存几乎比数据集本身重两倍。 GPU需求:虽然先前的state of the art(即SFRS[18])需要四个11GB GPU进行训练,但CosPlace要轻得多。使用相同的主干网络(VGG-16[43]),我们只需要单个GPU上的7.5 GB即可获得表3和表4中显示的结果。 描述符维度:自从开创性的NetVLAD论文[1]问世以来,state of the art依赖于NetVLAD层[1,18,27,32],它产生高维描述符。考虑到描述符的紧凑性可能是现实世界中选择算法时最重要的因素之一(因为为了高效检索,所有数据库描述符都应保存在内存中),我们生成的向量相对于先前的方法要紧凑得多。例如,虽然[1,27]使用完整的NetVLAD维度32k,而[18,32]将其减少到4k,但CosPlace仅使用512的维度就达到了SOTA结果。此外,在第5.4节和附录B.3.1中,我们研究了结果如何依赖于描述符的维度(和基础主干网络),表明使用ResNet-101和128维描述符的CosPlace优于先前的SOTA。 训练和测试速度:网络在SF-XL上训练大约需要一天,与SFRS[18]在Pitts30k上的训练时间相似。在测试时,对于基于VGG-16的模型,V100 GPU能够每秒提取80张图像的描述符,尽管我们发现速度在很大程度上取决于主干网络,并且在表3的方法中非常相似,因为它们都依赖于VGG-16。然而,对于大规模数据集,k-最近邻搜索所需的时间远远超过提取时间(考虑到在现实世界场景中数据库描述符是离线提取的)。鉴于穷举kNN的执行时间线性依赖于描述符的维度,我们的512维网络在大规模数据集上的推理速度比4096维的SFRS快8倍,比32k维的NetVLAD快64倍。
5.4 消融实验
超参数:为了更好地理解第4节中所做选择对结果的影响,我们进行了一系列实验,报告在表5中。结果表明,任何将数据集幼稚地划分为类别的尝试都无法达到有竞争力的结果。最后一行(代表唯一在没有组内相邻类别的情况下计算的实验)明显比其他行获得更好的结果,这清楚地证明了使用CosPlace组的好处。 主干网络和描述符维度:在图5中,我们探索了使用不同的主干网络,如ResNets[23]和Transformers[16,20]。我们发现CosPlace在各种主干网络下都表现良好,无需对超参数或层进行任何更改。这与基于NetVLAD的架构形成对比(例如,后接NetVLAD的ResNets在主干网络截断到第四个残差层而不是最后一层时表现最佳[4])。鉴于在使用CosPlace时,ResNets的性能优于VGG-16,同时通常更快且需要更少的内存,我们认为未来的工作应该从过时的VGG-16主干网络转向更高效的ResNets。关于不同主干网络和描述符维度的更多细节和结果在附录B.3.1中。 表5. 消融实验。使用不同超参数值M、α、N和L的Recall@1。最后一行代表CosPlace,其他行代表缺少某些组件的CosPlace:例如,使用α=360°意味着不使用朝向标签(即,任何给定单元格内的所有图像属于同一类别);类似地,使用N=1和L=1意味着所有类别属于同一组(并且只存在一个组,导致没有组分离)。更彻底的消融在附录中。
5.5 局限性
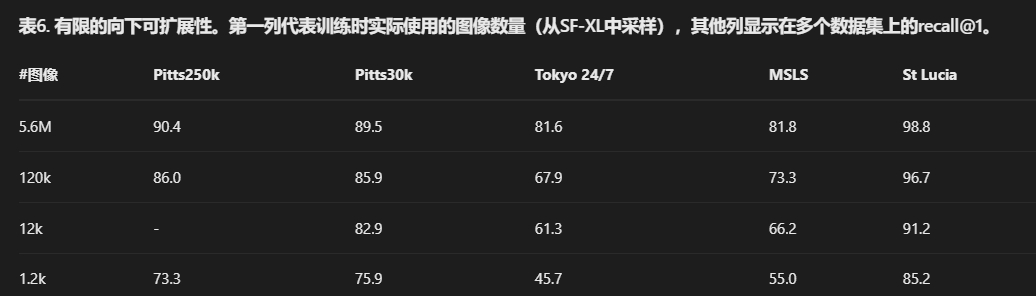
朝向标签:与仅依赖GPS/UTM坐标的先前VG方法不同,我们还利用了朝向标签。这是CosPlace的一个缺点,尽管我们认为朝向标签确实非常廉价,并且就像GPS坐标一样,可以通过传感器收集,无需任何手动标注。然而,一些常用数据集,如Pitts30k和MSLS,没有为其图像提供朝向标签,使得CosPlace无法在此类数据集上训练。 有限的向下可扩展性:尽管CosPlace是为大规模数据集设计的,但本节我们研究了使用较小的训练数据集如何影响结果。在表6中,我们展示了训练数据集大小对数递减时召回率的变化。我们发现CosPlace需要大量的训练图像才能达到SOTA性能,因此不适合用于训练小型数据集。
6. 结论
在这项工作中,我们研究了大规模应用中的视觉地理定位(VG)任务。使用新提出的San Francisco eXtra Large(SF-XL)数据集,我们发现当前基于对比学习的方法很难扩展到大量数据上进行训练。为了解决这个问题,我们提出了一种新方法CosPlace,它使我们能够高效地训练大量数据。我们证明,使用CosPlace在SF-XL上训练的非常简单架构的模型可以超越当前的state of the art,同时使用8倍小的描述符。最重要的是,CosPlace非常简単,比基于对比学习的方法需要更少的训练资源,并且能够很好地泛化到其他领域。尽管CosPlace有一些局限性,即它不适合训练小型数据集或没有方向标签的数据集,但它为在大规模应用中处理VG的新策略铺平了道路。
致谢
我们感谢CINECA在ISCRA计划下的奖项,提供了高性能计算资源。这项工作得到了CINI的支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号